
最近业务侧花样提需求,里面涉及到了各种数组的切片、合并、去重、拼接、压平等操作,本来以为需要自己开发很多udf才可以,后来扒了一下源码,发现这些用法sparksql已经帮我们实现了呀~~
太了不起了,我承认是我见识短了,所以就有了这篇......
总结一下sparksql(基于branch3.3) 中 array操作相关的骚气用法,这恐怕是总结的最全的一篇了,哈哈~~
从源码里看到,array相关函数主要分为四类:
- array_funcs(一般的array函数,比如取最大、最小、包含、切片等)
- collection_funcs(集合类的操作,比如数组求size、反转、拼接等)
- map_funcs(从map结构中衍生出来的函数,比如element_at)
- lambda_funcs(这几种函数中当属lambda_funcs最骚气,学起来会比较难,但可真是太灵活了,能帮我们解决很多实现上的问题)
需要注意的点:
- 1、array_funcs、collection_funcs、map_funcs都是支持全代码生成的,而lambda_funcs不支持全代码生成,所以在使用lambda_funcs时,需要注意效率问题
- 2、如果看功能描述看不太明白,可以多看看案例,一看案例就什么都明白了
- 3、在真正使用时,要测试一下对null的兼容性,有的函数对null做了兼容,有的函数没有做,使用前测一下最保险。对于遇到null会抛出异常的函数,我们需要对null提前做一下兼容处理
array_funcs
array
对应的类:CreateArray
功能描述:用sql创建一个数组(原来生成一个数组这么简单,我之前经常用split('1,2,3',',')这种形式来生成数组,现在看来用array函数最方便快捷)
版本:1.1.0
是否支持全代码生成:支持
用法:
--生成一维数组
select array(1, 3, 5) as arr;
+---------+
|arr |
+---------+
|[1, 3, 5]|
+---------+
--生成二维数组
select array(array(1, 2, 3), array(1, 3, 5)) as arr;
+----------------------+
|arr |
+----------------------+
|[[1, 2, 3], [1, 3, 5]]|
+----------------------+
array_contains
对应的类:ArrayContains
功能描述:判断数组是不是包含某个元素,如果包含返回true(这个比较常用)
版本:1.5.0
是否支持全代码生成:支持
用法:
--包含
select array_contains(array(1, 2, 3), 2) as is_contains;
+-----------+
|is_contains|
+-----------+
|true |
+-----------+
--不包含
select array_contains(array(1, 2, 3), 5) as is_contains;
+-----------+
|is_contains|
+-----------+
|false |
+-----------+
arrays_overlap
对应的类:ArraysOverlap
功能描述:
1、两个数组是否有非空元素重叠,如果有返回true
2、如果两个数组的元素都非空,且没有重叠,返回false
3、如果两个数组的元素有空,且没有非空元素重叠,返回null
版本:2.4.0
是否支持全代码生成:支持
用法:
--两个数组不存在null元素,且有重叠元素,返回true
select arrays_overlap(array(1, 2, 3), array(3, 4, 5)) as is_overlap;
+----------+
|is_overlap|
+----------+
|true |
+----------+
--两个数组其中有一个存在null元素,且有重叠元素,返回true
select arrays_overlap(array(1, 2, 3), array(null, 2, 6)) as is_overlap;
+----------+
|is_overlap|
+----------+
|true |
+----------+
--两个数组都存在null元素,且有重叠元素,返回true
select arrays_overlap(array(1, 2, null), array(null, 2, 6)) as is_overlap;
+----------+
|is_overlap|
+----------+
|true |
+----------+
--两个数组都不存在null元素,且无重叠元素,返回false
select arrays_overlap(array(1, 2, 3), array(4, 5, 6)) as is_overlap;
+----------+
|is_overlap|
+----------+
|false |
+----------+
--两个数组其中有一个存在null元素,且无重叠元素,返回null
select arrays_overlap(array(1, 2, 3), array(null, 5, 6)) as is_overlap;
+----------+
|is_overlap|
+----------+
|null |
+----------+
--两个数组都存在null元素,且无重叠元素,返回null
select arrays_overlap(array(1, 2, null), array(null, 5, 6)) as is_overlap;
+----------+
|is_overlap|
+----------+
|null |
+----------+
array_intersect
对应的类****:ArrayIntersect
功能描述:返回两个数组相交的元素数组,并且不重复
版本****:2.4.0
是否支持全代码生成:支持
用法:
--正常情况的案例
select array_intersect(array(1, 2, 3), array(1, 3, 5)) as intersect_arr;
+-------------+
|intersect_arr|
+-------------+
|[1, 3] |
+-------------+
--有重复且有null的案例
select array_intersect(array(1, 2, 3, 3, null), array(1, 3, 5, null)) as intersect_arr;
+-------------+
|intersect_arr|
+-------------+
|[1, 3, null] |
+-------------+
array_join
对应的类:ArrayJoin
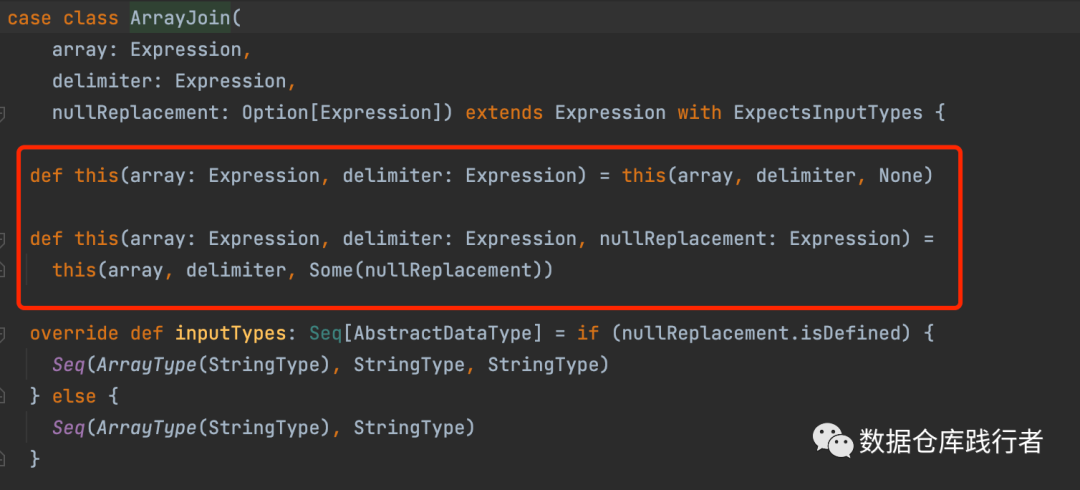
功能描述:
用给定的分隔符和可选字符串替换null,来连接给定数组的元素;如果未设置【可选字符串替换null】,会过滤null值
从代码的构造函数也能看出,我们可以选择输入array(数组), delimiter(分隔符)这两个参数,也可以输入 array(数组), delimiter(分隔符),nullReplacement(如果数组中有null的,替换null的字符串,如果不输入,则默认把null过滤掉)这三个参数
版****本:2.4.0
是否支持全代码生成:支持
用法:
--数组里没有null元素,且分隔符为逗号
select array_join(array('hello', 'world'), ',') as join_str;
+-----------+
|join_str |
+-----------+
|hello,world|
+-----------+
--数组里有null元素,且分隔符为逗号,且不输入【可选字符串替换null】,可以看到null元素被过滤
select array_join(array('hello', null ,'world'), ',') as join_str;
+-----------+
|join_str |
+-----------+
|hello,world|
+-----------+
--数组里有null元素,且分隔符为逗号,且将null替换为++
select array_join(array('hello', null ,'world'), ',', '++') as join_str;
+--------------+
|join_str |
+--------------+
|hello,++,world|
+--------------+
arr****ay_position
对应的类:ArrayPosition
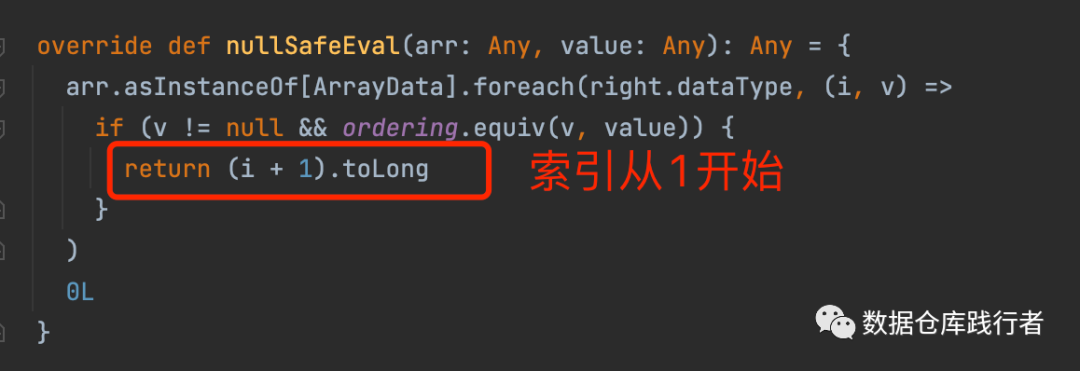
功能描述:返回给定数组中元素第一次出现的位置(索引从1开始)
1、如果在数组中找不到给定值,则返回0
2、如果任一参数为null,则返回null
版本:2.4.0
是否支持全代码生成:支持
用法:
--正常情况的案例
select array_position(array(3, 2, 1), 1) as pos;
+---+
|pos|
+---+
|3 |
+---+
--找不到,返回0
select array_position(array(3, 2, 1), 5) as pos;
+---+
|pos|
+---+
|0 |
+---+
--返回null
select array_position(array(3, 2, 1), null) as pos;
+----+
|pos |
+----+
|null|
+----+
array_except
对应的类:ArrayExcept
功能描述:返回在array1中但不在array2中的元素数组,去重
版本:2.4.0
是否支持全代码生成:支持
用法:
--array1数组里没有null元素
select array_except(array(1, 2, 2, 3), array(1, 3, 5)) as except_arr;
+----------+
|except_arr|
+----------+
|[2] |
+----------+
--array1数组里有null元素
select array_except(array(1, 2, 2, null, 3), array(1, 3, 5)) as except_arr;
+----------+
|except_arr|
+----------+
|[2, null] |
+----------+
array_union
对应的类:ArrayUnion
功能描****述:返回array1和array2并集中的元素数组,去重
版本:2.4.0
是否支持全代码生成:支持
用法:
select array_union(array(1, 2, 2, 3), array(1, 3, 5,null)) as union_arr;
+------------------+
|union_arr |
+------------------+
|[1, 2, 3, 5, null]|
+------------------+
slice
对应的类:Slice
功能描述:slice(x, start, length) --从索引开始(数组索引从1开始,如果开始为负,则从结尾开始)获取指定长度length的数组x的子集;如果取长度length超出数组长度,取能取出的最大的长度(挺好用,我们业务侧经常要求取某次搜索下N个商品)
版本:2.4.0
是否支持全代码生成:支持
用法:
--取从第2位开始,长度为2
select slice(array(1, 2, 3, 4), 2, 2) as slice_arr;
+---------+
|slice_arr|
+---------+
|[2, 3] |
+---------+
--取从倒数第2位开始,长度为2
select slice(array(1, 2, 3, 4), -2, 2) as slice_arr;
+---------+
|slice_arr|
+---------+
|[3, 4] |
+---------+
--取从倒数第2位开始,长度为20(长度超限制,取能取出的最大的长度)
select slice(array(1, 2, 3, 4), -2, 20) as slice_arr;
+---------+
|slice_arr|
+---------+
|[3, 4] |
+---------+
arrays_zip
对应的类:ArraysZip
功能描述:arrays_zip(a1,a2,…)-返回结构的合并数组,其中第N个结构包含输入数组的所有第N个值(合并数组中有null数组,整体返回null)
版本:2.4.0
是否支持全代码生成:支持
用法:
--2个数组,无null元素与数组
select arrays_zip(array(1, 2, 3), array(2, 3, 4)) as zip;
+------------------------+
|zip |
+------------------------+
|[{1, 2}, {2, 3}, {3, 4}]|
+------------------------+
--3个数组,无null元素与数组
select arrays_zip(array(1, 2), array(2, 3), array(3, 4)) as zip;
+----------------------+
|zip |
+----------------------+
|[{1, 2, 3}, {2, 3, 4}]|
+----------------------+
--3个数组,有null元素
select arrays_zip(array(1, 2), array(2, 3), array(3, null)) as zip;
+-------------------------+
|zip |
+-------------------------+
|[{1, 2, 3}, {2, 3, null}]|
+-------------------------+
--有null数组,整体返回null
select arrays_zip(array(1, 2), array(2, 3), null) as zip;
+----+
|zip |
+----+
|null|
+----+
sort_array
对应的类:SortArray
功能描述:sort_array(array[,ascendingOrder])--根据数组元素的自然顺序,按升序或降序对输入数组排序
1、对于双/浮点类型,NaN大于任何非NaN元素
2、Null元素将按升序放置在返回数组的开头,或按降序放置在返回数组的末尾
版本:1.5.0
是否支持全代码生成:支持
用法:
--升序
select sort_array(array('b', 'd', null, 'c', 'a'), true) as sort_arr;
+------------------+
|sort_arr |
+------------------+
|[null, a, b, c, d]|
+------------------+
--降序
select sort_array(array('b', 'd', null, 'c', 'a'), false) as sort_arr;
+------------------+
|sort_arr |
+------------------+
|[d, c, b, a, null]|
+------------------+
--null
select sort_array(null, true) as sort_arr;
+--------+
|sort_arr|
+--------+
|null |
+--------+
shuffle
对应的类:Shuffle
功能描述:把给定数组的元素重新洗牌
版本:2.4.0
是否支持全代码生成:支持
用法:
--没null元素
select shuffle(array(1, 20, 3, 5)) as shuffle_arr;
+-------------+
|shuffle_arr |
+-------------+
|[5, 3, 1, 20]|
+-------------+
--有null元素
select shuffle(array(1, 20, null, 3)) as shuffle_arr;
+----------------+
|shuffle_arr |
+----------------+
|[20, null, 3, 1]|
+----------------+
--null
select shuffle(null) as shuffle_arr;
+-----------+
|shuffle_arr|
+-----------+
|null |
+-----------+
array_min
对应的类:ArrayMin
功能描述:返回数组中的最小值
1、对于双/浮点类型,NaN大于任何非NaN元素
2、跳过空值
版本:2.4.0
是否支持全代码生成:支持
用法:
--正常案例
select array_min(array(1, 20, null, 3)) as min_arr;
+-------+
|min_arr|
+-------+
|1 |
+-------+
--空数组
select array_min(null) as min_arr;
+-------+
|min_arr|
+-------+
|null |
+-------+
array_max
对应的类:ArrayMax
功能描述:返回数组中的最大值
1、对于双/浮点类型,NaN大于任何非NaN元素
2、跳过空值
版本:2.4.0
是否支持全代码生成:支持
用法:
--正常案例
select array_max(array(1, 20, null, 3)) as max_arr;
+-------+
|max_arr|
+-------+
|20 |
+-------+
--空数组
select array_max(null) as max_arr;
+-------+
|max_arr|
+-------+
|null |
+-------+
--数组元素都为null
select array_max(array(null, null)) as max_arr;
+-------+
|max_arr|
+-------+
|null |
+-------+
flatten
对应的类:Flatten
功能描述:将多维数组转换为单个数组,不去重
版本:2.4.0
是否支持全代码生成:支持
用法:
--二维数组
select flatten(array(array(1, 2), array(2, 4))) as flatten_arr;
+------------+
|flatten_arr |
+------------+
|[1, 2, 2, 4]|
+------------+
--三维数组
select flatten(array(array(array(1, 2), array(2, 4)))) as flatten_arr;
+----------------+
|flatten_arr |
+----------------+
|[[1, 2], [2, 4]]|
+----------------+
--有数组为null
select flatten(array(array(1, 2), null)) as flatten_arr;
+-----------+
|flatten_arr|
+-----------+
|null |
+-----------+
sequence
对应的类:Sequence
功能描述:sequence(start,stop,step)--从开始到停止(包括)生成元素数组,并逐步递
1、返回元素的类型与参数表达式的类型相同,支持的类型有:byte、short、integer、long、date、timestamp
2、start和stop表达式必须解析为同一类型
3、如果开始和停止表达式解析为“date”或“timestamp”类型,则步骤表达式必须解析为“interval”或“year-month interval”或“day-time interval”类型,否则解析为与开始和停止表达式相同的类型。
版本:2.4.0
是否支持全代码生成:支持
用法:
--话不多说,看效果
select sequence(1, 5) as seq;
+---------------+
|seq |
+---------------+
|[1, 2, 3, 4, 5]|
+---------------+
--话不多说,看效果
select sequence(5, 1) as seq;
+---------------+
|seq |
+---------------+
|[5, 4, 3, 2, 1]|
+---------------+
--话不多说,看效果,自动生成日期列表有救了
select sequence(to_date('2018-01-01'), to_date('2018-03-01'), interval 1 month) as seq;
+------------------------------------+
|seq |
+------------------------------------+
|[2018-01-01, 2018-02-01, 2018-03-01]|
+------------------------------------+
select sequence(to_date('2018-01-01'), to_date('2018-03-01'), interval '0-1' year to month) as seq;
+------------------------------------+
|seq |
+------------------------------------+
|[2018-01-01, 2018-02-01, 2018-03-01]|
+------------------------------------+
array_repeat
对应的类:ArrayRepeat
功能描述:array_repeat(element,count)-返回包含元素计数次数的数组
版本:2.4.0
是否支持全代码生成:支持
用法:
--话不多说,看效果
select array_repeat('123', 2) as repeat_arr;
+----------+
|repeat_arr|
+----------+
|[123, 123]|
+----------+
--好用,哈哈
select array_repeat(array(1,2,3), 3) as repeat_arr;
+---------------------------------+
|repeat_arr |
+---------------------------------+
|[[1, 2, 3], [1, 2, 3], [1, 2, 3]]|
+---------------------------------+
--元素为null的情况
select array_repeat(null, 3) as repeat_arr;
+------------------+
|repeat_arr |
+------------------+
|[null, null, null]|
+------------------+
--计数次数为null,好用
select array_repeat(123, null) as repeat_arr;
+----------+
|repeat_arr|
+----------+
|null |
+----------+
array_remove
对应的类:ArrayRemove
功能描述:array_remove(array, element)-从数组中删除等于元素的所有元素
版本:2.4.0
是否支持全代码生成:支持
用法:
--话不多说,看效果
select array_remove(array(1, 2, 3, null, 3), 3) as remove_arr;
+------------+
|remove_arr |
+------------+
|[1, 2, null]|
+------------+
array_distinct
对应的类:ArrayDistinct
功能描述:array_distinct(array)-数组去重
版本:2.4.0
是否支持全代码生成:支持
用法:
--话不多说,看效果
select array_distinct(array(1, 2, 3, null, 3)) as distinct_arr;
+---------------+
|distinct_arr |
+---------------+
|[1, 2, 3, null]|
+---------------+
collection_funcs
array_size
对应的类:ArraySize(实际调用的是Size类,参数legacySizeOfNull传入false,也就是说当数组为null时,array_size默认返回null)

功能描述:返回数组的大小
1、对于null输入,函数返回null
2、可对array和map结果求size
版本:3.3.0
是否支持全代码生成:支持
用法:
--正常情况的案例
select array_size(array('b', 'd', 'c', 'a')) as arr_size;
+--------+
|arr_size|
+--------+
|4 |
+--------+
--对于null输入,函数返回null
select array_size(null) as arr_size;
+--------+
|arr_size|
+--------+
|null |
+--------+
size
对应的类:Size(与array_size不同的是,legacySizeOfNull参数由spark.sql.legacy.sizeOfNull和spark.sql.ansi.enabled共同决定,默认返回值为true,即当数组为null时,size返回-1)
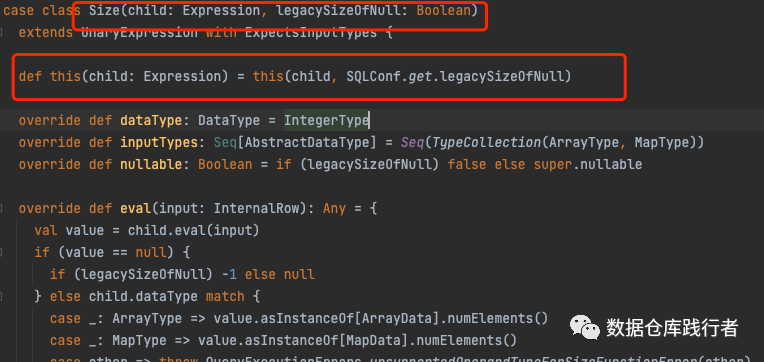
功能描述:返回数组的大小
1、对于null输入,函数返回-1
2、可对array和map结果求size
版本:1.5.0
是否支持全代码生成:支持
用法:
--正常情况的案例
select size(array('b', 'd', 'c', 'a')) as arr_size;
+--------+
|arr_size|
+--------+
|4 |
+--------+
--对于null输入,函数返回-1
select size(null) as arr_size;
+--------+
|arr_size|
+--------+
|-1 |
+--------+
cardinality
对应的类:Size(与size不同的是,legacySizeOfNull参数默认传入true,即当数组为null时,size返回-1;而size的legacySizeOfNull参数是由spark.sql.legacy.sizeOfNull和spark.sql.ansi.enabled共同决定,默认返回值为true,但如果我们改配置参数,会影响legacySizeOfNull的值)
功能描述:返回数组的大小
1、对于null输入,函数返回-1
2、可对array和map结果求size
版本:1.5.0
是否支持全代码生成:支持
用法:
--正常情况的案例
select cardinality(array('b', 'd', 'c', 'a')) as arr_size;
+--------+
|arr_size|
+--------+
|4 |
+--------+
--对于null输入,函数返回-1
select cardinality(null) as arr_size;
+--------+
|arr_size|
+--------+
|-1 |
+--------+
reverse
对应的类:Reverse
功能描述:返回反向字符串或元素顺序相反的数组
版本:1.5.0,从2.4.0版本开始支持数组reverse
是否支持全代码生成:支持
用法:
--正常案例
select reverse(array(1, 20, null, 3)) as reverse_arr;
+----------------+
|reverse_arr |
+----------------+
|[3, null, 20, 1]|
+----------------+
--空数组
select reverse(null) as reverse_arr;
+-----------+
|reverse_arr|
+-----------+
|null |
+-----------+
concat
对应的类:Concat
**功能描述: **concat(col1,col2,…,colN)-将字符串或者数组拼接,不去重
版本****:1.5.0,从2.4.0版本开始支持数组concat
是否支持全代码生成:支持
用法:
--正常案例
select concat(array(1, 2, 3), array(3, 4, 5), array(6)) as concat_arr;
+---------------------+
|concat_arr |
+---------------------+
|[1, 2, 3, 3, 4, 5, 6]|
+---------------------+
--空数组
select concat(null) as concat_arr;
+----------+
|concat_arr|
+----------+
|null |
+----------+
--有一个数组为null,会报错
select concat(array(1, 2, 3), array(3, 4, 5), array(6),null) as concat_arr;
cannot resolve 'concat(array(1, 2, 3), array(3, 4, 5), array(6), CAST(NULL AS STRING))' due to data type mismatch: input to function concat should all be the same type, but it's [array<int>, array<int>, array<int>, string]; line 1 pos 7;
'Project [concat(array(1, 2, 3), array(3, 4, 5), array(6), cast(null as string)) AS concat_arr#218]
+- OneRowRelation
map_funcs
element_at
对应的类:ElementAt
功能描述:返回给定(基于1的)索引处的数组元素。
1、如果索引为0,将抛出一个错误
2、如果索引<0,则从最后一个到第一个访问元素
3、如果索引超过数组的长度 且spark.sql.ansi.enabled 参数设置为false ,则函数返回NULL
4、如果索引超过数组的长度 且spark.sql.ansi.enabled 参数设置为true ,则抛出ArrayIndexOutOfBoundsException
版本:2.4.0
是否支持全代码生成:支持
用法:
--输入索引为正
select element_at(array(1, 5, 2, 3), 2) as ele;
+---+
|ele|
+---+
|5 |
+---+
--输入索引为负
select element_at(array(1, 5, 2, 3), -2) as ele;
+---+
|ele|
+---+
|2 |
+---+
--输入索引超过数组的长度
select element_at(array(1, 5, 2, 3), 5) as ele;
+----+
|ele |
+----+
|null|
+----+
lambda_funcs
array_sort
对应的类:ArraySort
功能描述:使用比较器函数对数组中的元素排序
1、输入数组的元素必须是可排序的
2、对于双/浮点类型,NaN大于任何非NaN元素
3、默认比较器,是按升序排序,Null元素将放置在返回的数组的末尾
4、自3.0.0以来,该函数还基于给定的比较器函数对数组进行排序和返回。比较器将采用两个参数,表示数组的两个元素。当第一个元素小于、等于或大于第二个元素时,它返回一个负整数、0或正整数。如果比较器函数返回null,该函数将失败并引发错误
从源码中可以看到,有两个构造函数,用来分别支持输入比较函数和不输入比较函数的情况,而SQLConf.LEGACY_ALLOW_NULL_COMPARISON_RESULT_IN_ARRAY_SORT 参数(默认为false),当设置为false时,如果比较器函数返回null,“array_sort”函数将抛出异常。如果设置为true,将把null处理为零

版本:2.4.0
是否支持全代码生成:不支持
用法:
--用默认比较器
select array_sort(array('b', 'd', null, 'c', 'a')) as sort_arr;
+------------------+
|sort_arr |
+------------------+
|[a, b, c, d, null]|
+------------------+
--自定义比较器,按升序排
select array_sort(array(5, 6, 1), (left, right) -> case when left < right then -1 when left > right then 1 else 0 end) as sort_arr;
+---------+
|sort_arr |
+---------+
|[1, 5, 6]|
+---------+
--自定义比较器,按降序排
select array_sort(array('bc', null,null, 'ab', 'dc'), (left, right) -> case when left is null and right is null then 0 when left is null then -1 when right is null then 1 when left < right then 1 when left > right then -1 else 0 end) as sort_arr;
+------------------------+
|sort_arr |
+------------------------+
|[null, null, dc, bc, ab]|
+------------------------+
transform
对应的类:ArrayTransform
功能描述:transform(expr, func)--使用函数变换数组中的元素
版本:2.4.0
是否支持全代码生成:不支持
用法:
--数组元素+1
select transform(array(1, 2, 3), x -> x + 1) as transform_arr;
+-------------+
|transform_arr|
+-------------+
|[2, 3, 4] |
+-------------+
--相邻相加
select transform(array(1, 2, 3), (x, i) -> x + i) as transform_arr;
+-------------+
|transform_arr|
+-------------+
|[1, 3, 5] |
+-------------+
filter
对应的类:ArrayFilter
功能描述:filter(expr, func)--使用给定谓词过滤输入数组
版本:2.4.0
是否支持全代码生成:不支持
用法:
--话不多说,看效果1
select filter(array(1, 2, 3), x -> x % 2 == 1) as filter_arr;
+----------+
|filter_arr|
+----------+
|[1, 3] |
+----------+
--话不多说,看效果2
select filter(array(0, 2, 3), (x, i) -> x > i) as filter_arr;
+----------+
|filter_arr|
+----------+
|[2, 3] |
+----------+
--话不多说,看效果3
select filter(array(0, null, 2, 3, null), x -> x IS NOT NULL) as filter_arr;
+----------+
|filter_arr|
+----------+
|[0, 2, 3] |
+----------+
exists
对应的类:ArrayExists
功能描述:exists(expr, pred)--测试谓词是否适用于数组中的一个或多个元素
版本:2.4.0
是否支持全代码生成:不支持
用法:
--话不多说,看效果1
select exists(array(1, 2, 3), x -> x % 2 == 0) as exists_flag;
+-----------+
|exists_flag|
+-----------+
|true |
+-----------+
--话不多说,看效果2
select exists(array(1, 2, 3), x -> x % 2 == 10) as exists_flag;
+-----------+
|exists_flag|
+-----------+
|false |
+-----------+
--话不多说,看效果3
select exists(array(1, null, 3), x -> x % 2 == 0) as exists_flag;
+-----------+
|exists_flag|
+-----------+
|null |
+-----------+
--话不多说,看效果4
select exists(array(0, null, 2, 3, null), x -> x IS NULL) as exists_flag;
+-----------+
|exists_flag|
+-----------+
|true |
+-----------+
--话不多说,看效果5
select exists(rray(1, 2, 3), x -> x IS NULL) as exists_flag;
+-----------+
|exists_flag|
+-----------+
|false |
+-----------+
forall
对应的类:ArrayForAll
功能描述:forall(expr, pred)--测试谓词是否适用于数组中的所有元素
版本:3.0.0
是否支持全代码生成:不支持
用法(案例3和案列4需要仔细品):
--话不多说,看效果1
select forall(array(1, 2, 3), x -> x % 2 == 0) as forall_flag;
+-----------+
|forall_flag|
+-----------+
|false |
+-----------+
--话不多说,看效果2
select forall(array(2, 4, 8), x -> x % 2 == 0) as forall_flag;
+-----------+
|forall_flag|
+-----------+
|true |
+-----------+
--话不多说,看效果3
select forall(array(1, null, 3), x -> x % 2 == 0) as forall_flag;
+-----------+
|forall_flag|
+-----------+
|false |
+-----------+
--话不多说,看效果4
select forall(array(2, null, 8), x -> x % 2 == 0) as forall_flag;
+-----------+
|forall_flag|
+-----------+
|null |
+-----------+
aggregate
对应的类:ArrayAggregate
功能描述:aggregate(expr, start, merge, finish)--将二进制运算符应用于初始状态和数组中的所有元素,并将其简化为单个状态。通过应用finish函数将最终状态转换为最终结果(好难理解,其实就是按照一定的初始值,一定的规则,把数组的元素聚合成一个值,看案例就懂了,非常灵活)
版本:2.4.0
是否支持全代码生成:不支持
用法:
--初始值为0,累加
select aggregate(array(1, 2, 3), 0, (acc, x) -> acc + x) as agg;
+---+
|agg|
+---+
|6 |
+---+
--初始值为0,*10,累加
select aggregate(array(1, 2, 3), 0, (acc, x) -> acc + x, acc -> acc * 10) as agg;
+---+
|agg|
+---+
|60 |
+---+
zip_with
对应的类:ZipWith
功能描述:zip_with(left, right, func)--使用函数将两个给定数组按元素合并为单个数组;如果一个数组较短,则在应用函数之前,在末尾追加null以匹配较长数组的长度
版本:2.4.0
是否支持全代码生成:不支持
用法:
--话不多说,看效果1
--两个数组长度一样,匹配
select zip_with(array(1, 2, 3), array('a', 'b', 'c'), (x, y) -> (y, x)) as zips;
+------------------------+
|zips |
+------------------------+
|[{a, 1}, {b, 2}, {c, 3}]|
+------------------------+
--两个数组长度不一样,追加null
select zip_with(array(1, 2, 3), array('a', 'b'), (x, y) -> (y, x)) as zips;
+------------------------++---------------------------+
|zips |
+---------------------------+
|[{a, 1}, {b, 2}, {null, 3}]|
+---------------------------+
--话不多说,看效果2
select zip_with(array(1, 2), array(3, 4), (x, y) -> x + y) as zips;
+------+
|zips |
+------+
|[4, 6]|
+------+
--话不多说,看效果3
select zip_with(array('a', 'b', 'c'), array('d', 'e', 'f'), (x, y) -> concat(x, y)) as zips;
+------------+
|zips |
+------------+
|[ad, be, cf]|
+------------+
以上!
推荐阅读:
数仓面试——日期交叉问题
数仓面试——连续登录问题进阶版
数仓面试——连续登录问题
Hey!
我是小萝卜算子
欢迎关注:数据仓库践行者
分享是最好的学习,这里记录我对数据仓库的实践的思考和总结
每天学习一点点
知识增加一点点
思考深入一点点
在成为最厉害最厉害最厉害的道路上
很高兴认识你
版权归原作者 小萝卜算子 所有, 如有侵权,请联系我们删除。