
【论文解读】Attentional Feature Fusion
首先附上论文地址和代码:
论文地址:https://ieeexplore.ieee.org/document/9423114
代码地址:https://github.com/YimianDai/open-aff
一、研究背景
特征融合是提高CNN表达能力的一种手段,它将来自不同层次或分支的特征进行组合。尽管特征融合在现代网络中很流行,但大多数关于特征融合的工作都专注于构建复杂的路径来组合不同核、组或层中的特征,特征融合方法很少被提及。现有的特征融合的方法通常是简单的线性的操作(例如:求和或者拼接),但这仅仅提供了特征映射的固定线性聚合,完全不知道这种组合是否适合特定的对象,所以可能不是最佳的选择。
自SKNet、ResNeSt出现后就出现了非线性的特征融合方法,但他们普遍存在一下三个问题:
1.缺乏一种能够统一不同特征融合场景的通用方法尽管各种特征融合实现的场景不同(同层、short skip connection、long skip connection),但其面临的挑战都是相同的,本质上就是如何将不同规模的特征进行集成以获得更好的性能,然而现在没有一种能够克服语义不一致、有效集成不同规模特征、在各种网络场景中持续提高融合特征的质量的模块。2.简单的特征初始整合方法特征送入注意力模块时往往被直接相加,然而在特征融合中,除了注意力模块的设计之外,特征的初始整合方法作为输入对融合权重的质量有很大的影响。考虑到这些特征在规模、语义上的不一致,简单的整合方法可能会导致初始特征成为好的特征融合的瓶颈。3.上下文信息聚合尺度有偏差图像中的目标在大小上有很大的变化,SKNet和ResNeSt中的融合权重是通过全局通道注意机制生成的,对于分布更全局的信息来说这样的方法会获得更可观的结果,但当目标是小目标时就会削弱小目标的特征。需要一个可以动态自适应地能感知上下文尺度的网络来融合接收到的特征。
- 文章贡献:
1、提出一种多尺度通道注意力模块(MS-CAM)。弥补不同尺度间的特征不一致,实现注意特征融合。
作者观察到:尺度并不是空间注意力的专属问题,通过改变空间池化的尺寸,通道注意力也可以具有除全局外的尺度。MS-CAM通过沿通道维度聚合多尺度上下文信息,可以同时强调分布更全局的大对象和分布更局部的小对象,方便网络在极端尺度变化下识别和检测对象。
2、提出了一种注意力特征融合模块(AFF)。适用于大多数常见场景,并解决上下文聚合和初始特征集成问题。
3、提出了一种迭代注意力特征融合模块(IAFF)。将初始特征融合与另一个注意力模块交替集成。
二、Multi-scale Channel Attention Module (MS-CAM)
核心思想:通过改变空间池化的大小,可以在多个尺度上实现通道注意力
MS-CAM的不同之处:
- 为了让MS-CAM尽可能轻量化,在注意力模块内将局部上下文信息加到全局上下文信息中。
- 通过逐点卷积来关注通道的尺度问题而不是大小不同的卷积核,针对每个空间位置按点计算通道交互。

如图所示为MS-CAM的框图,图中X表示输入特征,X’表示输出特征,由
局部+全局
构成,并使用点卷积
point-wise convolution (PWConv)
。
local channel context:
式中PWConv1的核大小为C×C/r×1×1,PWConv2的核大小为C/r×C×1×1。B表示BN层,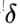 表示ReLU。
表示ReLU。
经MS-CAM细化后的特征:
注意:
上图中的+表示相加操作,由于两个分支的尺寸不同,这里需要广播操作。
代码实现如下:
classMS_CAM(nn.Module):'''
单特征进行通道注意力加权,作用类似SE模块
'''def__init__(self, channels=64, r=4):super(MS_CAM, self).__init__()
inter_channels =int(channels // r)# 局部注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),)# 全局注意力
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),)
self.sigmoid = nn.Sigmoid()defforward(self, x):
xl = self.local_att(x)
xg = self.global_att(x)
xlg = xl + xg
wei = self.sigmoid(xlg)return x * wei
三、Attentional Feature Fusion(AFF)

X、Y是两个感受野大小不同的特征映射,假设Y的感受野更大。
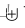 表示像素级求和,作为初始特征。Z表示融合后的特征。上图所示特征融合过程如下公式:
表示像素级求和,作为初始特征。Z表示融合后的特征。上图所示特征融合过程如下公式:
虚线箭头:表示
1-M(X+Y)
,使网络进行soft selection,通过训练确定各自的权重.
除此以外,作者列出了多中特征融合方式,如下图所示:
“soft selection”类型,利用两种特征作为指导,涉及初始特征的集成问题
代码实现如下:
classAFF(nn.Module):'''
多特征融合 AFF
'''def__init__(self, channels=64, r=4):super(AFF, self).__init__()
inter_channels =int(channels // r)# 局部注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),)# 全局注意力
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),)
self.sigmoid = nn.Sigmoid()defforward(self, x, residual):
xa = x + residual
xl = self.local_att(xa)
xg = self.global_att(xa)
xlg = xl + xg
wei = self.sigmoid(xlg)
xo = x * wei + residual *(1- wei)return xo
四、Iterative Attentional Feature Fusion(IAFF)
为了解决了初始特征集成的难题,作者提出迭代注意力特征融合,使用注意力特征融合后的特征作为初始特征的集成。具体过程如下图所示:
特征输出:
与AFF的不同点:
- AFF中:初始特征集成选取了简单的像素级相加的方式
- IAFF中:初始特征继承如下公式所示:通过计算经注意力加权的特征作为初始特征
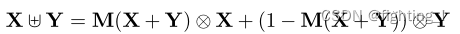
代码实现如下:
classiAFF(nn.Module):'''
多特征融合 iAFF
'''def__init__(self, channels=64, r=4):super(iAFF, self).__init__()
inter_channels =int(channels // r)# 局部注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),)# 全局注意力
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),)# 第二次局部注意力
self.local_att2 = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),)# 第二次全局注意力
self.global_att2 = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),)
self.sigmoid = nn.Sigmoid()defforward(self, x, residual):
xa = x + residual
xl = self.local_att(xa)
xg = self.global_att(xa)
xlg = xl + xg
wei = self.sigmoid(xlg)
xi = x * wei + residual *(1- wei)
xl2 = self.local_att2(xi)
xg2 = self.global_att(xi)
xlg2 = xl2 + xg2
wei2 = self.sigmoid(xlg2)
xo = x * wei2 + residual *(1- wei2)return xo
五、实例:替换ResNet, FPN和InceptionNet中的特征融合
这三种网络分别模拟了不同的融合场景。
网络场景ResNetshort skip connectionFPNlong skip connectionInceptionNetsame layer
替代方式:
网络场景ResNet相加替换为AFF/IAFFFPN相加替换为AFF/IAFFInceptionNet拼接替换为AFF/IAFF
六、实验
1数据集及实验设置
数据集:
图像分类
:CIFAR-100、ImageNet;
语义分割
:StopSign(一个COCO子集)
实验设置:
2 消融实验
1)Multi-Scale Context Aggregation的影响
为验证多尺度上下文聚合的有效性,作者建立了两个消融模块Global+Global和Local+Local,如下图所示,两个上下文聚合分支的尺度设置为相同的,要么是全局的,要么是局部的。作者提出的是Global+Local。
实验结果如下: 可以看出,作者所使用的全局+局部的效果是最好的。
可以看出,作者所使用的全局+局部的效果是最好的。
2)Feature Integration Type的影响
不同的特征融合方式在第三部分介绍过,下边给出作者所设计的对应的模块示意图。
具体的实验结果如下:
从中得到的结论有:
- 与线性方法(相加和拼接)相比,具有注意机制的非线性融合策略具有更好的性能;
- fully上下文感知+selection策略始终优于其他策略,应作为首选;
- 多数情况下IAFF优于其他大多数融合方式。
进而证明了早期的融合质量对注意特征融合有很大的影响,而另一个层次的注意特征融合可以进一步提高性能。
3)对目标定位和小目标识别的影响
作者将将GradCAM应用于ResNet-50、SENet-50和AFF-ResNet-50,获得在ImageNet数据集上的分类结果热图。

从中可以看出:
- AFF-ResNet-50:参与区域与标记对象高度重叠,说明对对象的定位和利用对象区域的特征有很好的学习能力;
- ResNet-50:定位能力相对较差,很多情况下会导致被关注区域的中心位置错位;
- SENet-50:能够定位真实的物体,但参与的区域过大,包括许多背景,SENet-50只利用了全局通道注意力,对全局尺度的上下文有偏差,而MS-CAM还聚合了局部通道上下文,有助于网络关注目标而较少的关注背景,也有利于小目标的识别。
3 对比实验
为了证明所提出的注意特征融合替代原始的融合操作可以提高网络性能,基于相同主干网络比较了AFF和iAFF模块与其他注意模块在不同特征融合场景下的性能。
从中可以看出:
- 集成了AFF或IAFF的网络在所有场景下的性能都更好,表明所提出的(迭代)注意特征融合方法不仅具有优越的性能,而且具有良好的通用性。这种优越的性能来自于所提出的注意力模块内的多尺度通道上下文聚合。
- IAFF比AFF具有更高的性能。
- 使用AFF或iAFF模块取代简单的相加或拼接可以获得更有效的网络。在B中,IAFF-ResNet只需要54%的参数就可以达到ResNet的性能。
版权归原作者 fighting_! 所有, 如有侵权,请联系我们删除。