
缺失数据
准备数据

** 处理方式**
1、丢弃/过滤:DataFrame.na.drop()
2、填充:DataFrame.na.fill()
3、替换:DataFrame.na.replace()
丢弃规则
1、any 一行中有任何一个是NaN/null就丢弃
df.na.drop("any").show() //任何出现NaN/null就丢弃

2、all 只有一行中所有都是NaN/null才丢弃
df.na.drop("all").show() //一行都是NaN/null才丢弃
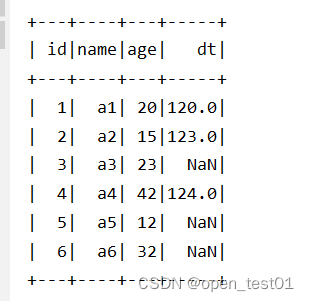
3、某些规则 针对某些列有NaN/null ,是否丢弃该列
df.na.drop("any",List("age","dt")).show() //针对特定列出现NaN/null就丢弃改行

填充规则
1、针对所有列进行默认填充
df.na.fill(0).show() //针对所有列都填充0
2、针对特定的列
df.na.fill(0,List("age","dt")).show() //针对特定列进行填充

异常数据
准备数据

** 方法1:丢弃处理**
df2.where('dt =!= "NaN").show() //只获取dt列 =!=(不为)NaN的数据

** 方法2:替换处理**
如果需要使用when 则需要导入functions的隐式转换操作
import org.apache.spark.sql.functions._
**1、直接替换**
df2.select( //如果dt等于NA就替换为Double类型的NaN(NA是字符串类型 NaN是double类型)
when('age === "NA",Double.NaN)
.otherwise('age cast DoubleType)//还需要统一该列其他的数据类型
.as("ok") //指定为新的列名
).show()

** 2、使用na.repalce替换 **
repalce("指定列",Map("原始数据" -> "替换后的数据")) 进行替换但是Map替换的方式不能变
*注意:Map()转换的时候原类型和转换后的类型必须是一致的 *
df2.na.replace("dt",Map("NaN" -> "NA","Null" -> "null")).show()

**代码: **
def main(args: Array[String]): Unit = {
//创建Session对象
val spark = SparkSession
.builder() //构建器
.appName("sparkSQL") //序名称程
.master("local[*]") //执行方式:本地
.getOrCreate() //创建对象
//导入转换
import spark.implicits._
//因为自定推断字段类型可能识别NAN为String类型,不方便处理,所以这里指定schema
val schema: StructType = StructType(List(
StructField("id", LongType),
StructField("name", StringType),
StructField("age", IntegerType),
StructField("dt", DoubleType)
))
schema
//读取数据
//因为数据中已有表头则设置option("header",true)
val df: DataFrame = spark.read.option("header",true).schema(schema).csv("file:///D:\\spark.test\\datas\\a1.csv")
//数据缺失处理
//方式1:丢弃原则 any、all、自定义
//df.na.drop("any").show() //任何出现NaN/null就丢弃
//df.na.drop("all").show() //一行都是NaN/null才丢弃
//df.na.drop("any",List("age","dt")).show() //针对特定列出现NaN/null就丢弃改行
//方式2:填充
//df.na.fill(0).show() //针对所有列都填充0
//df.na.fill(0,List("age","dt")).show() //针对特定列进行填充
//读取数据
val df2: DataFrame = spark.read.option("header",true).csv("file:///D:\\spark.test\\datas\\a2.csv")
//异常数据处理
//1.丢弃处理
//df2.where('dt =!= "NaN").show() //只获取dt列 =!=(不为)NaN的数据
//2、替换处理
import org.apache.spark.sql.functions._
//直接替换
// df2.select( //如果dt等于NA就替换为Double类型的NaN(NA是字符串类型 NaN是double类型)
// when('age === "NA",Double.NaN)
// .otherwise('age cast DoubleType)//还需要统一该列其他的数据类型
// .as("ok") //指定为新的列名
// ).show()
//df2.na.replace("dt",Map("NaN" -> "NA","Null" -> "null")).show()
}
本文转载自: https://blog.csdn.net/dafsq/article/details/129639783
版权归原作者 open_test01 所有, 如有侵权,请联系我们删除。
版权归原作者 open_test01 所有, 如有侵权,请联系我们删除。