
源码:
https://github.com/WongKinYiu/yolov7
论文:
https://arxiv.org/abs/2207.02696
这个yolov7是yolov4团队的作品,我等着你yolov100。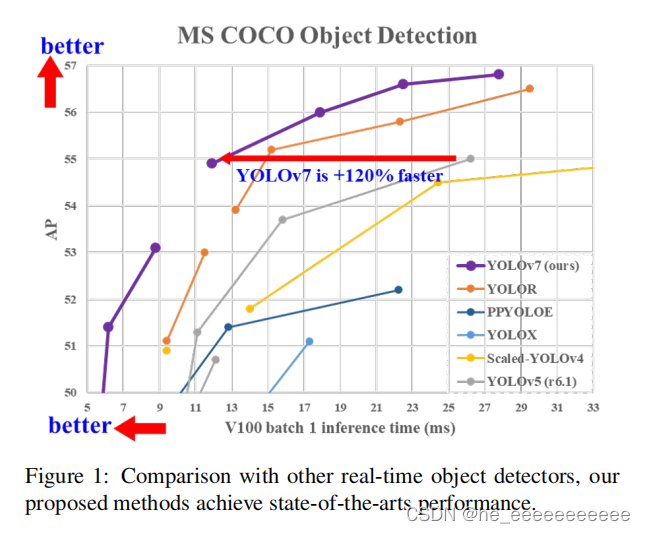

背景
yolo系列已经成了大家学习工作中常用的目标检测网络,果然,yolov7又来了。一般人yolo取名到2亿都可以,但听说这个作者是yolov4的,我就来踩踩坑,试试火
代码
搭建环境,这里直接用conda按照源码requirements.txt安装就行。
(我yolov5环境(python3.7+torch1.8.0)都可以训练,我之前写过一篇几分钟搭建yolov5的文章)
数据准备
- 现成数据(VisDrone)+配置脚本(yolov7.yaml等):
数据集:官方的VisDrone格式和yolov5的不同,要转换一下
这里我有转换好的,下载地址:4euh
- 制作自己数据集(lableme标注自己图片+labelme转yolo的脚本): 强烈建议用labelme
labelme格式标注完就是一张图对应一个json: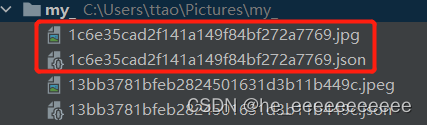
yolo格式是一个图对应一个txt: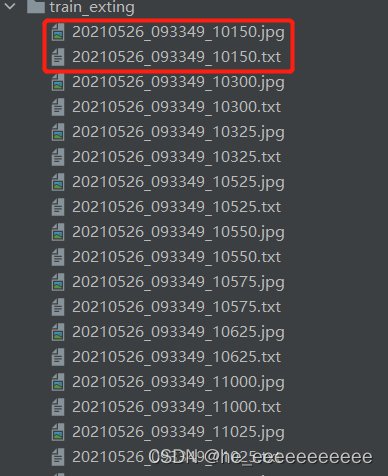
我是把转化完的txt和json都同一个文件夹下
- 标注软件:
labelme就一个exe文件50m左右,下载地址:8q3m,windows上下载后直接执行,非常方便
- labelme转yolov5脚本:
(只写了检测的,labelme的分割、关键点等等脚本有机会写个总的)
import os
import json
import glob
#输入口,就是你图片和json存放的那个文件,输出的txt也在这个文件夹里
labelme_dir=r"C:\Users\ttao\Pictures\my_"defget_labelme_data(labelme_dir):withopen(labelme_dir)as f:
j=json.load(f)
out_data=[]
img_h =j["imageHeight"]
img_w =j["imageWidth"]for shape in j["shapes"]:
label=shape["label"]
points=shape["points"]
x,y,x2,y2=points[0][0],points[0][1],points[1][0],points[1][1]
x_c=(x+x2)//2
y_c=(y+y2)//2
w=abs(x-x2)
h=abs(y-y2)
out_data.append([label,x_c,y_c,w,h])return img_h,img_w,out_data
defrename_Suffix(in_,mode=".txt"):
in_=in_.split('.')return in_[0]+mode
defmake_yolo_data(in_dir):
json_list=glob.glob(os.path.join(in_dir,'*.json'))for json_ in json_list:
json_path=os.path.join(in_dir,json_)
json_txt=rename_Suffix(json_)
img_h,img_w,labelme_datas=get_labelme_data(json_path)withopen(os.path.join(in_dir,json_txt),'w+')as f:for labelme_data in labelme_datas:
label=labelme_data[0]
x_c=labelme_data[1]/img_w
y_c=labelme_data[2]/img_h
w=labelme_data[3]/img_w
h=labelme_data[4]/img_h
f.write("{} {} {} {} {}\n".format(label,x_c,y_c,w,h))
f.close()if __name__ =='__main__':
make_yolo_data(labelme_dir)
训练
配置:train.py+数据集配置文件(.yaml)+选择网络的配置文件(默认为yolov7.yaml)
👉Visdrone数据集
数据集是无人机角度拍摄的,中国各城市的,主要是各种汽车、人等数据集
我具体配置情况如下: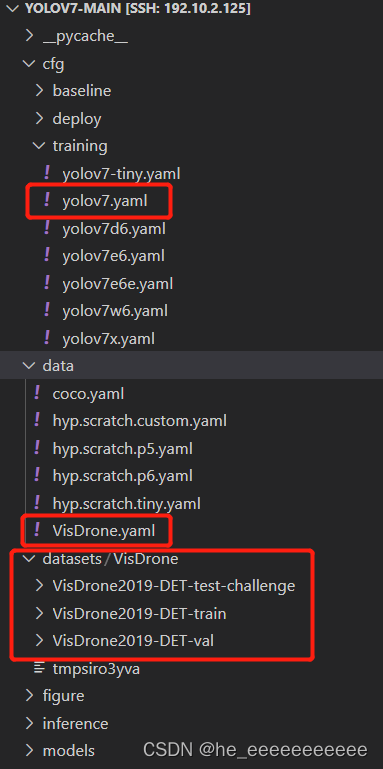
train.py
–cfg 模型选择,这里默认是yolov7
–data 数据格式配置,我这里是自己的VisDrone数据格式,训练yolo的要改,看下面训练自己数据集
–hyp 超参数,先不管
–batch-size 这个yolov7我设高了容易爆,小点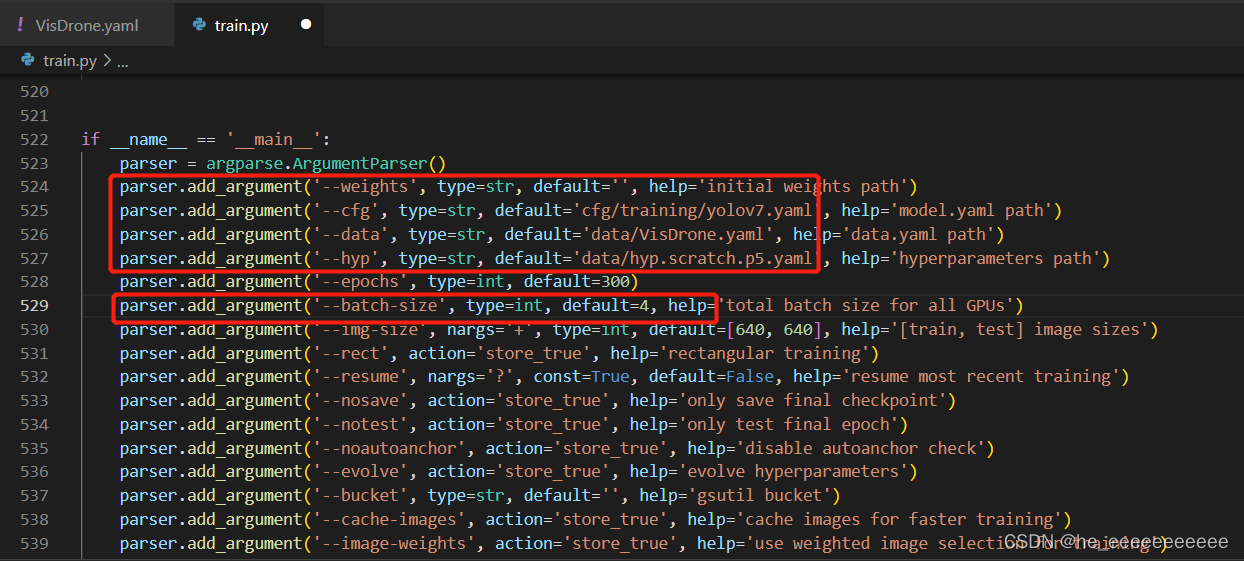
VisDrone.yaml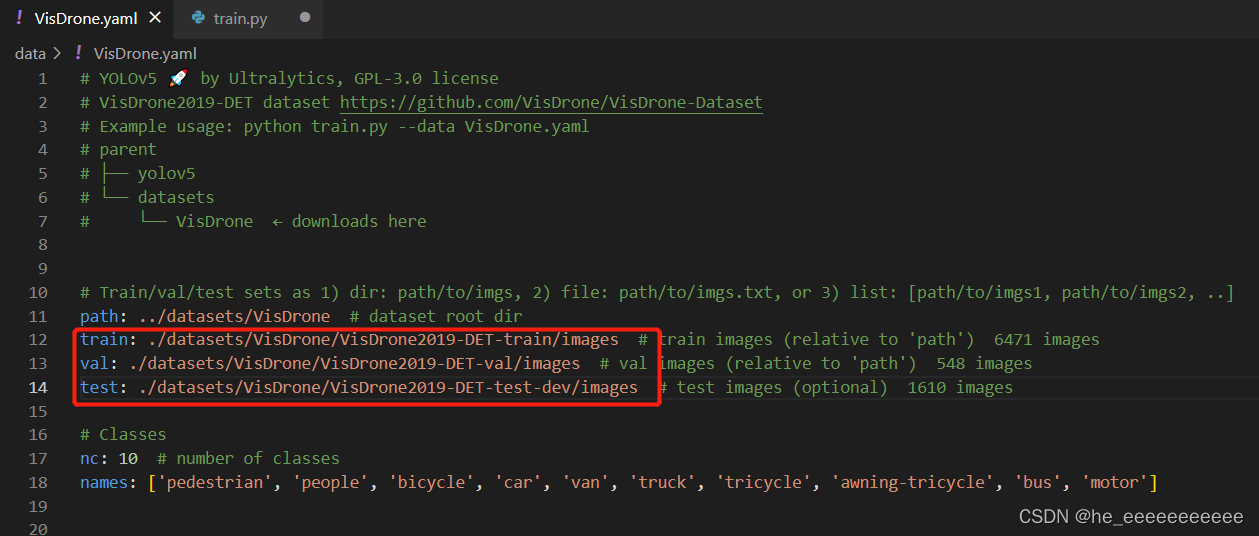
然后就可以训练了
👉自己的数据集
把上面的VisDrone.yaml换成yolo系列格式的yaml,
yolo系列例子:
比如我的灭火器数据集,exting.yaml如下
train: my_data/train_exting
val: my_data/val_exting
nc:2#类别,改成自己的names:['exting_s','exting_m']#类别名称
和VisDrone不同的是,yolo系列数据格式这样放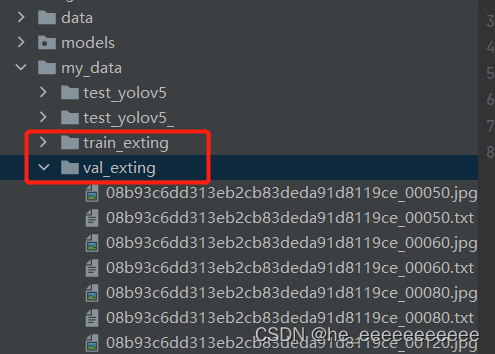
接下来配置train.py就行了。
坑(我遇到的):
1、首先如果中途报错有什么却库和少包,大概率就是torch环境问题,按照我yolov5搭建的方式没什么问题
2、在windows上训练的问题,报错:[WinError 1455] 页面文件太小,无法完成操作
原由:这里dataloader workers数量默认是8,当batch-size大,内存不够,报错
方法:
要么设置dataloader=1,但会降低训练速度,贼慢(但如果显卡本来就弱,那可能不全是cpu问题)
要么使用 FixNvPe.py 脚本,减少 MemoryPerProcess,不会降低训练速度。
具体方法(我也是看简书上大神的)
3、报错如下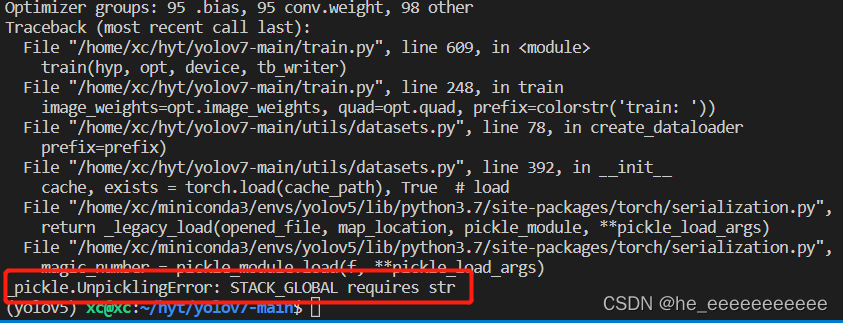
直接把VisDrone训练和测试集的label.cache删除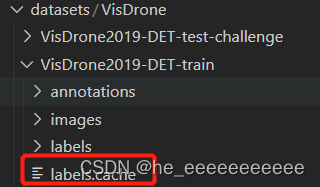
4、这个yolov7我2080ti,8g显存,batch_size=4,结果训练一段就爆显存。参考一下,自己改下batch_size,嫌弃太大的有个yolov7-tiny版本
最后总结:
yolov7是80多m,即使是yolov7-tiny的也是40多m,yolov5s大概17m(目前我jeston nano就是用这个部署的,飞桨的yolov5s可能20多m),yolo-fastest大概1.3m,想比较效果的自己可以去试试yolov5s和yolo-fatest等等。

版权归原作者 he_eeeeeeeeeee 所有, 如有侵权,请联系我们删除。