

目录
OpenAI刚刚宣布了一项重大技术突破,全新扩散模型方法sCM,sCM将开启图像、音频、视频、三维模型AI新时代。

1、扩散模型的烦恼:慢如蜗牛的生成速度
先来回顾一下,扩散模型(Diffusion Models)在生成式AI领域可是风生水起。然而,它们有一个致命缺点——采样速度慢!生成一张图片可能需要几十步甚至几百步,效率低得让人抓狂。虽然市面上有一些蒸馏技术,可以加速采样,但这些方法或是计算成本高,或是训练复杂,甚至有的还牺牲了样本质量。
2、sCM的闪亮登场:两步采样,速度提升50倍!
就在大家为扩散模型的慢速发愁时,OpenAI推出了全新的sCM模型。这位“新晋小哥”只需两步采样,速度就提升了整整50倍,而且性能还直逼甚至超越了传统的扩散模型。sCM作为OpenAI前期一致性模型研究的延续和改进,简化了理论框架,实现了大规模数据集的稳定训练,同时保持了与领先扩散模型相当的样本质量。
3、一致性模型sCM,到底是个啥?
我们先来看看官网,一致性模型sCM是如何解释的:

一致性模型(Consistency Models, CMs)是一类强大的基于扩散的生成模型,专为快速采样优化。
目前大多数现有的CMs使用离散化时间步长进行训练,这引入了额外的超参数,并且容易出现离散化误差。虽然连续时间的形式可以缓解这些问题,但由于训练不稳定性,成功有限。
为了解决这个问题,我们提出了一个简化的理论框架,统一了之前对扩散模型和CMs的参数化方法,并找出了不稳定性的根本原因。基于这一分析,我们在扩散过程的参数化、网络架构和训练目标方面引入了关键改进。
这些变化使我们能够在前所未有的规模上训练连续时间的CMs,在ImageNet 512x512上达到了15亿个参数。我们提出的训练算法仅使用两个采样步骤,在CIFAR-10上取得了2.06的FID分数,在ImageNet 64x64上取得了1.48的FID分数,在ImageNet 512x512上取得了1.88的FID分数,将与现有最佳扩散模型的FID分数差距缩小到10%以内。
4、sCM相比于扩散模型,有哪些改进:
(1)继承与改进
sCM(一致性模型)是在扩散模型基础上的改进版本。它借鉴了扩散模型逐步去噪生成数据的原理,但通过优化算法和架构设计,实现了更高效的生成过程。
(2)显著提升采样速度
传统扩散模型需要几十步甚至几百步才能生成一张图像,速度较慢。相比之下,sCM仅需两步采样即可完成生成,采样速度提升了50倍,大幅度提升了效率。
(3)保持高质量输出
尽管sCM显著加快了生成速度,但它依然能够保持甚至超越扩散模型的图像质量。这得益于其优化的训练方法和先进的网络架构,确保生成结果的清晰度和细节。
(4)理论框架的创新
sCM采用了连续时间框架,避免了扩散模型中离散时间步带来的误差。这一创新使得模型在理论上更加稳健,能够在更大规模的数据集上进行稳定训练和扩展。
(5)网络架构的优化
sCM在网络设计上引入了改进的时间条件、自适应组归一化、新的激活函数和自适应权重等技术。这些优化不仅提升了模型的训练稳定性,还增强了生成样本的多样性和质量。
总的来说,OpenAI的sCM模型凭借其卓越的速度和质量,正在迅速成为生成式AI领域的新宠。它不仅解决了扩散模型的速度瓶颈,还在理论和实践上做出了重大突破。未来,随着sCM的不断优化和应用,相信它将在更多领域展现出强大的潜力,带领我们迈向生成式AI的新纪元!
4、ChatGPT又要过生日啦
下个月就是ChatGPT的两岁生日了!虽然Sora还没落地,连开发主管都悄然离开,搞得外界一片哗然,但OpenAI似乎仍然在憋大招!最近传出的sCM技术发布说明,或许就是他们下一步计划的关键。sCM(Stochastic Convolution Model)不仅被认为是未来生成高质量实时音视频的基础,更可能是为何Sora和新版DALL-E还没推出的原因。

4、Sora即将发布?
Sora在可变持续时间、分辨率和宽高比的视频和图像上联合训练文本条件扩散模型。Sora利用对视频和图像潜在代码的时空补丁进行操作的变压器架构。
Sora能够生成具有多个角色、特定类型的运动以及主体和背景的准确细节的复杂场景。该模型不仅了解用户在提示中提出的要求,还了解这些东西在物理世界中的存在方式。
该模型对语言有深入的理解,使其能够准确地解释提示并生成引人注目的字符来表达充满活力的情感。Sora还可以在单个生成的视频中创建多个镜头,准确地保留角色和视觉风格。
OpenAI的结果表明,扩展视频生成模型是构建物理世界通用模拟器的一条有前途的途径。
比如,一位时尚女性走在充满温暖霓虹灯和动画城市标牌的东京街道上。
她穿着黑色皮夹克、红色长裙和黑色靴子,拎着黑色钱包。她戴着太阳镜,涂着红色口红。她走路自信而随意。街道潮湿且反光,在彩色灯光的照射下形成镜面效果。许多行人走来走去。

比如,几只巨大的毛茸茸的猛犸象正踏着白雪皑皑的草地走近,它们长长的毛茸茸的皮毛在风中轻轻飘动,远处覆盖着积雪的树木和雄伟的雪山,午后的阳光下有缕缕云彩,太阳高挂在天空中。

距离产生了温暖的光芒,低摄像头视角令人惊叹地捕捉到了大型毛茸茸的哺乳动物,具有美丽的摄影和景深。

比如,动画场景的特写镜头是一个毛茸茸的小怪物跪在一根融化的红色蜡烛旁边。艺术风格是3D和现实的,重点是灯光和纹理。这幅画的基调是惊奇和好奇,怪物睁大眼睛、张开嘴巴凝视着火焰。它的姿势和表情传达出一种天真和俏皮的感觉,就好像它第一次探索周围的世界一样。暖色调和戏剧性灯光的使用进一步增强了图像的舒适氛围。

5、如何直接使用ChatGPT4o、o1、OpenAI Canvas
- GPT-4o知识问答:已同步最新ChatGPT o1、OpenAI Canvas
- 最强代码大模型Code Copilot:代码自动补全、代码优化建议、代码重构等
- DALL-E AI绘画:AI绘画 + 剪辑 = 自媒体新时代
- 私信哪吒,备注ai,直接使用GPT-4o
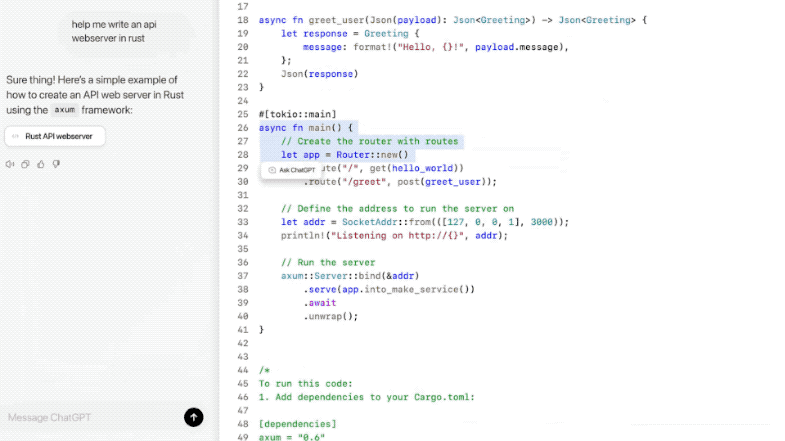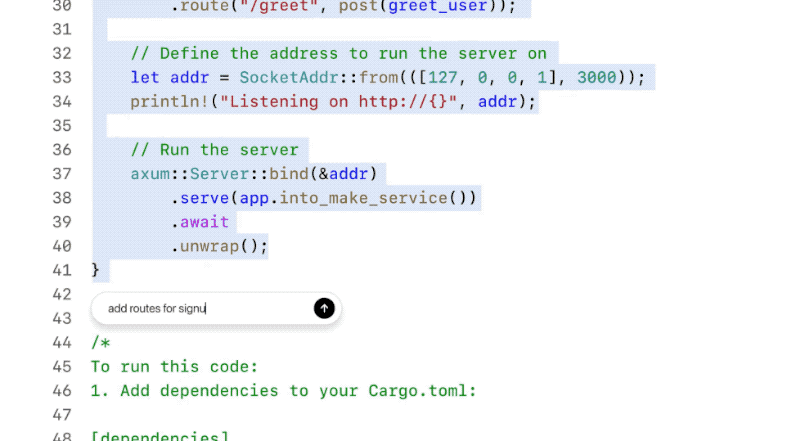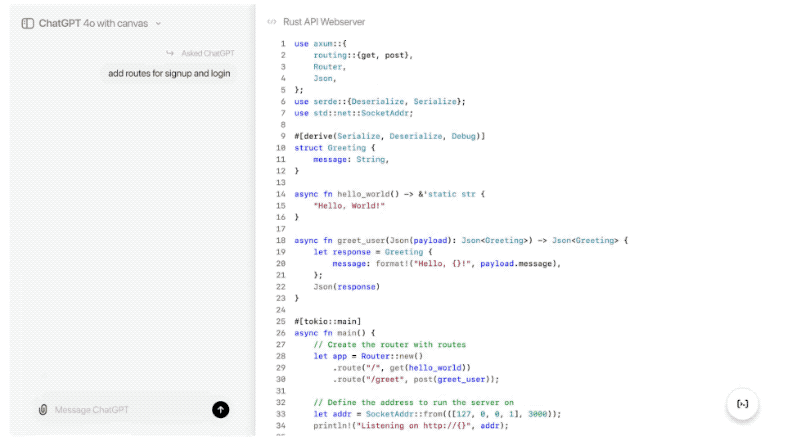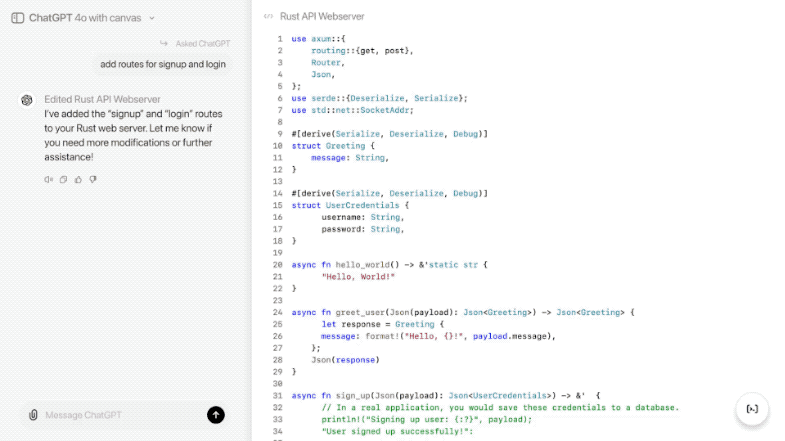
无论是写作、编程,还是两者结合的任务,Canvas 都让我们与 AI 的合作更加高效、灵活。随着功能的进一步完善,这个工具将成为每一个创作者和开发者的必备助手。
6、编程功能的提升
Canvas在编程任务方面也引入了五个高效的快捷功能:
- 代码审查:系统自动提供代码改进的建议,以优化代码质量和性能。
- 添加日志语句:在代码中插入调试信息(如print语句),便于追踪代码执行过程。
- 生成注释:自动生成代码注释,帮助开发者和团队更好地理解代码。
- 修复错误:检测代码中的错误并重写有问题的部分,从而有效修复bug。
- 编程语言转换:支持多种语言(包括JS、TS、Python、Java、C++、PHP等)之间的代码转换,帮助开发者轻松跨语言开发。
版权归原作者 哪 吒 所有, 如有侵权,请联系我们删除。