
在开始介绍YOLO算法之前,让我们先了解一下什么是目标检测。
好啦,让我们正式开始吧!🚿
🌸 目标检测是什么?
目标检测是人工智能计算机视觉的一种,它主要解决从图像中获取需要的物体类型以及位置的问题,输入一幅图像或者一帧视频,要输出图像中要求物体的类别和位置,其中的位置通常用一个框标记出来。在研究目标检测问题时,通常只考虑感兴趣的物体,比如人脸检测检测人脸,交通检测检测车辆等。
目标检测有两种实现,一种是one-stage,另一种是two-stage,它们的区别如名称所体现的,two-stage有一个region proposal过程,可以理解为网络会先生成目标候选区域,然后把所有的区域放进分类器分类,而one-stage会先把图片分割成一个个的image patch,然后每个image patch都有M个anchor box,把所有的anchor送进分类器输出分类和检测位置。很明显可以看出,后一种方法的速度会比较快。

🌸 YOLO算法发展历程
YOLO算法是把目标检测问题看成了一个回归问题,它是直接通过单个的神经网络来得到和分类概率,也就是说 YOLO 可以同时预测一个图像在所有类中的所有边界框。它的工作流程是缩放图像、让图像可以通过全卷积神经网络,然后利用非极大值抑制(想了解非极大值抑制可参考笔者其他文章)去进行筛选。
YOLO到目前为止总共发布了八个版本(截止笔者发稿),其中YOLOv1奠定了整个YOLO系列的基础,后面的YOLO算法是对其的不断改进创新。
🚿 YOLOv1
YOLOv1发布于2015年,是one-stage detection的开山之作,在此之前的目标检测都是采用two-stage的方法,虽然准确率较高,但是运行速度慢。(YOLO算法的最大优点)
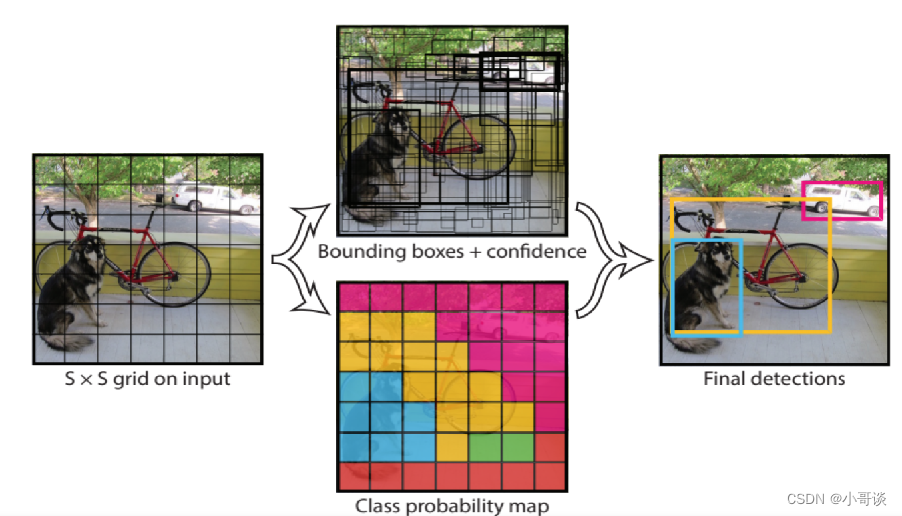
YOLOv1的检测方法如下:
1.将输入图像划分成S*S的网格,如果物体中心落入某个网格内,就由该网格单元负责检测该目标。
2.每个网格预测B个边界框和它们的置信度,置信度是预测框和真实物体IOU和网格是否包含物体01值之积
3.每个边界框都包含5个预测值,x,y,w,h,confidence,分别代表中心坐标,宽高和IOU值,这里的坐标是相对于网格左上角的偏移量,宽高是相对于整幅图像的占比
🚿 YOLOv2
由于YOLOv1存在定位不准确以及与two-stage方法相比召回率低的缺点,2017年提出了YOLOv2算法,从更准确,更快,更多识别三个角度对YOLOv1算法进行了改进,其中识别更多对象也就是扩展到能检测9000种不同对象,被称为YOLO9000。
🚿 YOLOv3
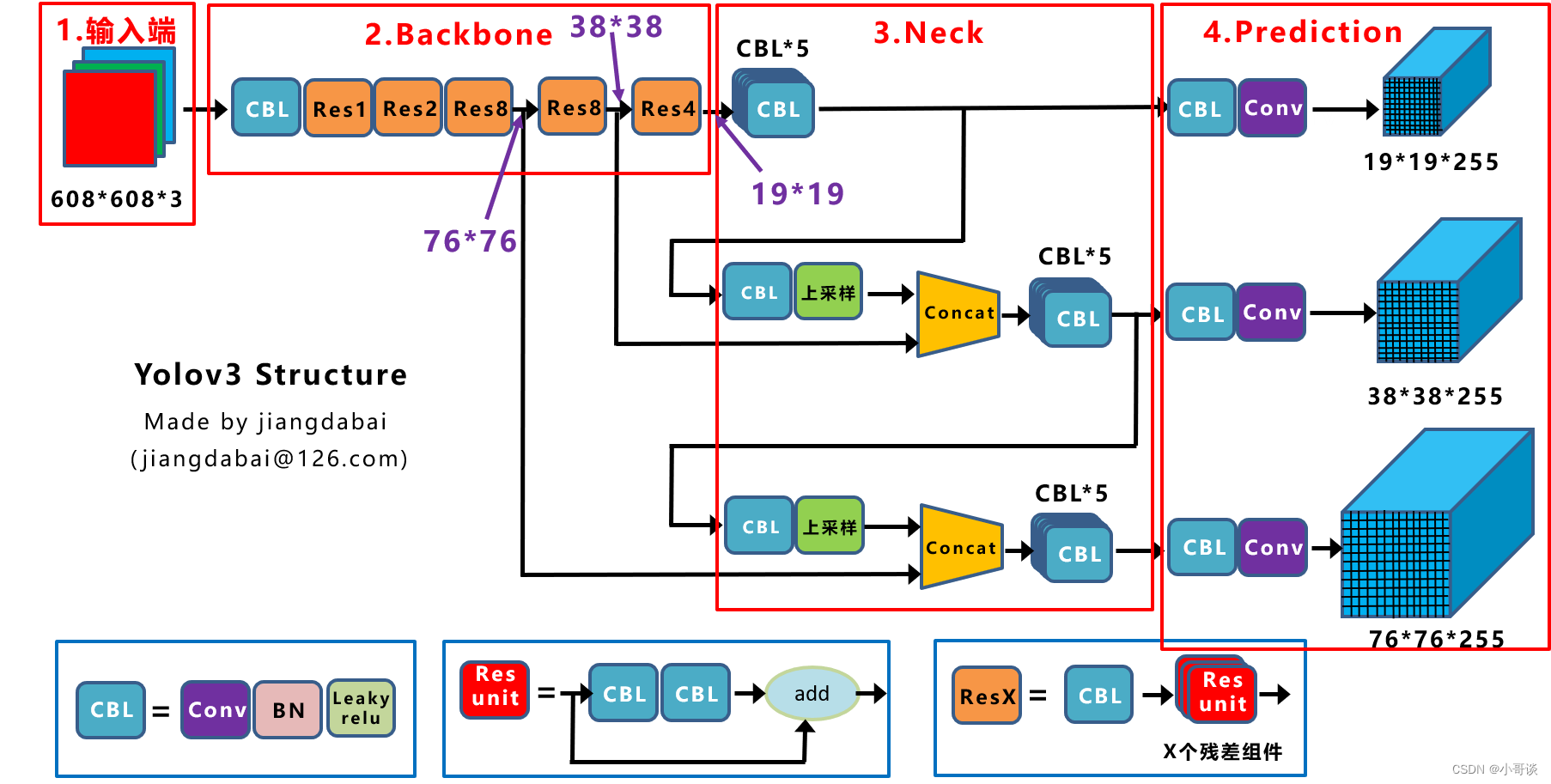
2018年YOLO的作者提出了YOLOv3,它是对前作的改进,最大的改进点包括使用了残差模型Darknet-53,以及为了实现多尺度检测采用了FPN架构。
YOLOv3中只有卷积层,控制特征图的尺寸这一任务由调节卷积步长来实现,同时由于采用了FPN架构,因此总共会输出三个特征图,第一个下采样32倍,第二个下采样16倍,第三个下采样8倍,小尺寸的特征图检测大尺寸物体,大尺寸特征图检测小尺寸物体。类似于YOLOv2,每种特征图对应了多种特征框,这里作者为每种特征图定义了3个先验框,总共有9个先验框,每个框预测五元组(即坐标和置信度)以及80个one-hot向量。这9个先验框同样是根据K-means算法求出来的。
🚿 YOLOv4
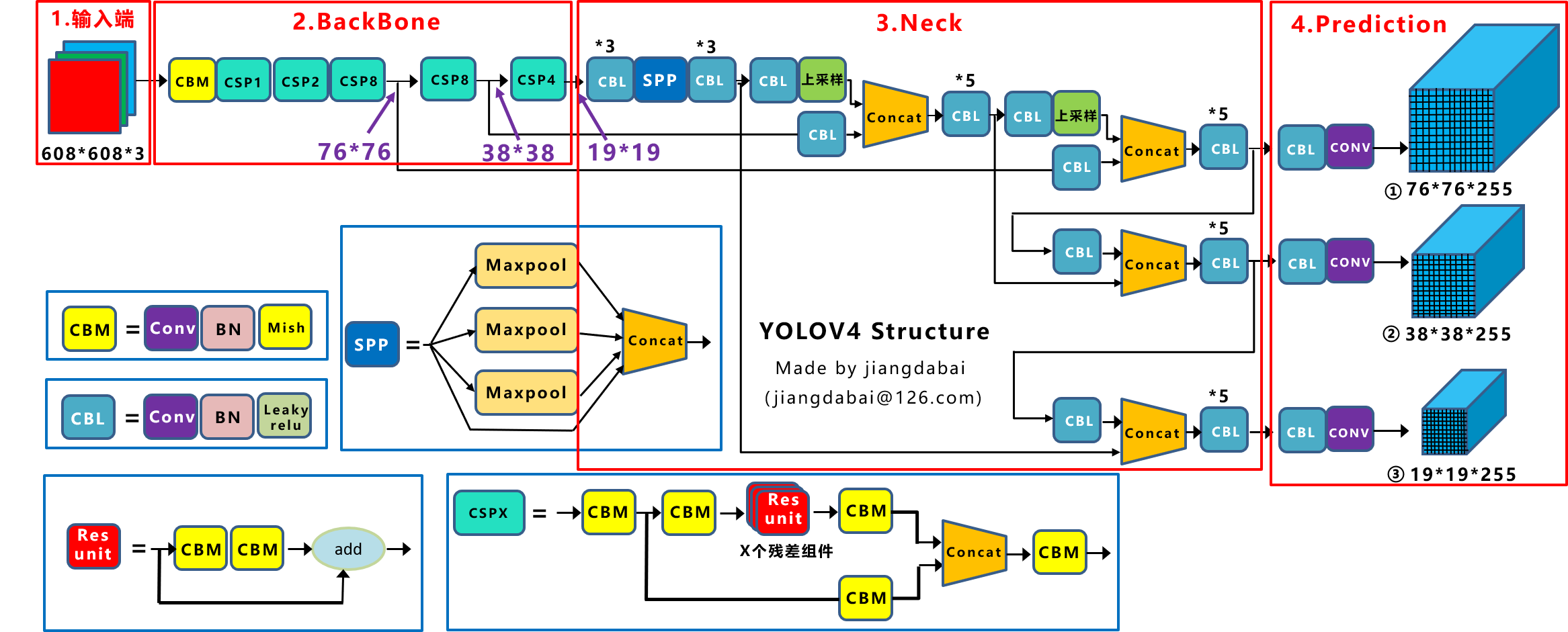
YOLOv4在原来的YOLO目标检测架构的基础上,采用了很多优化策略,在数据处理,主干网络,网络训练,激活函数,损失函数等方面都有不同程度的优化。
YOLOv4的网络结构如下所示,可以看出,他是在YOLOv3的主干网络Darknet-53的基础上增加了backbone结构,其中包含了5个CSP模块,可以有效增强网络的学习能力,降低成本。同时增加了Droblock,缓解过拟合现象。此外很重要的一点是,使用了Mish激活函数。
🚿 YOLOv5
1.网络结构
YOLOv5实际上也是在YOLOv4的基础上进行了一定程度的优化。在YOLOv5中新加入了一个focus框架,其最大的特点是原始608×608×3的图像输入Focus结构,采用切片操作,先变成304×304×12的特征图,再经过一次32个卷积核的卷积操作,最终变成304×304×32的特征图,加速了训练速度。 另外在YOLOv4中使用的CSP模块现在在backone和neck中都有应用。
2.输入和预测
输入部分依然采用了YOLOv4中采用的Mosaic数据增强技术,另外对于anchor box的设置采用了每次训练时自适应生成的方式,以及为了保持正常的长宽比,在填充增强环节自适应增添最少的黑边。预测部份同样采用了CIOU_Loss替换了IOU_Loss,DIOU_nms替换了nms.

🌸 YOLOv5简介
YOLOv5目标检测算法是Ultralytics公司于2020年发布的,根据模型的大小,YOLOv5有5个版本,分别为YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,这5个版本的权重、模型的宽度和深度是依次增加的。YOLOv5自发行以来,一直都在更新迭代版本,本次改进的是v5.0版本,以其为baseline进行模型优化。
YOLOv5的网络模型分为4个部分,包括输入端、主干网络(Backbone)、Neck模块和输出端。
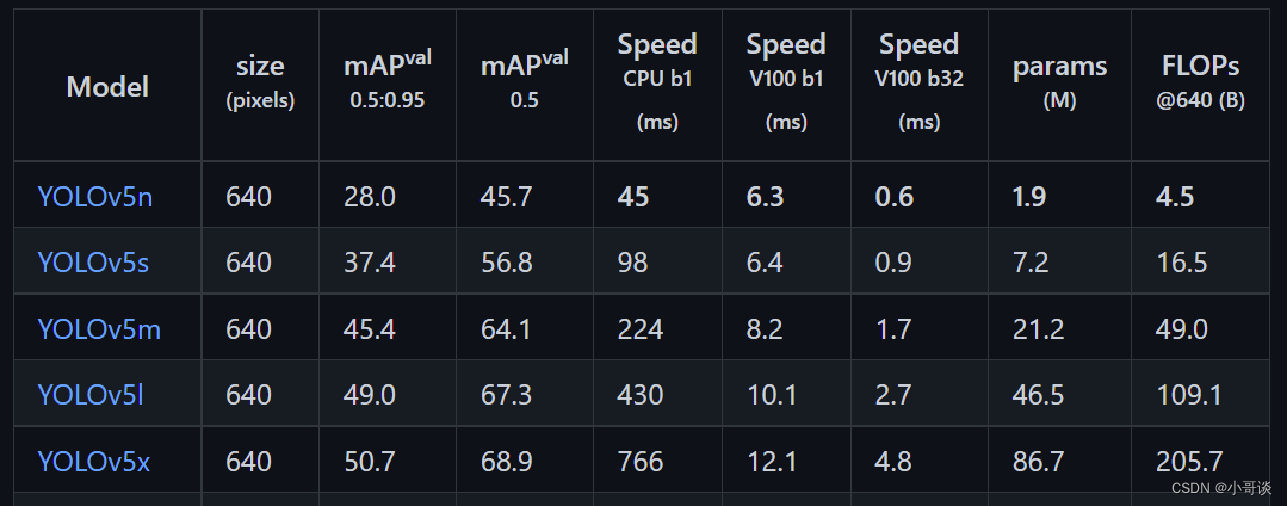
针对YOLOv5网络模型的4个部分,下面分别进行介绍:
1.输入端
YOLOv5的输入端主要包括马赛克(Mosaic)数据增强、自适应计算锚框和自适应缩放图像三个部分。
马赛克数据增强是在模型训练阶段使用的,将四张图片按照随机缩放、随机裁剪和随机排布的方式进行拼接,可以增加数据集中小目标的数量,从而提升模型对小目标物体的检测能力。
YOLOv5会根据参数启动自适应锚框计算功能,自适应的计算不同类别训练集中的最佳锚框值。
2.主干网络(Backbone)
模型的Backbone主要由Focus、C3(改进后的BottleneckCSP)和空间金字塔池化(Spatialpyramidpooling,SPP)模块组成。
3.Neck模块
该模块采用特征金字塔结构(FeaturePyramidNetworks,FPN)+路径聚合网络结构(PathAggregationNetwork,PAN)的结构,可以加强网络对不同缩放尺度对象特征融合的能力。
4.输出端
输出端采用GIOU函数作为边界框的损失函数,在目标检测后处理过程中,使用NMS(NonMaximumSuppression,非极大值抑制)来对多目标框进行筛选,增强了多目标和遮挡目标的检测能力。
讲到这里就接近尾声了,后面将继续重点介绍YOLO算法相关知识点,让我们一起乘风破浪,在知识的汪洋大海里尽情的畅游吧!💞💪🚿
版权归原作者 小哥谈 所有, 如有侵权,请联系我们删除。