
作为开发人员,面对堪称科技奇点爆发的ChatGPT,我们如何应对。当然是努力跟进,虽然ChatGPT不开源,但是有诸多不输ChatGPT的各类语言大模型LLM有分享。我们筛选出其中影响力较大的各个开源Github仓库,收录到
类ChatGPT的各种语言大模型开源Github模型集合http://www.webhub123.com/#/home/detail?p=1YRcl-3fpAW
收录后效果如下
登录后可以像Github一样,一键fork所有代码库网址到我的收藏。可以完全自由免费的管理超过20000多个网址,而且层次化视图管理,远比Github混乱的仓库看着效果好。
GitHub - nichtdax/awesome-totally-open-chatgpt: A list of totally open alternatives to ChatGPT 收集LLM开源大语言模型的列表

https://github.com/eugeneyan/open-llms 开源可商用大语言模型列表
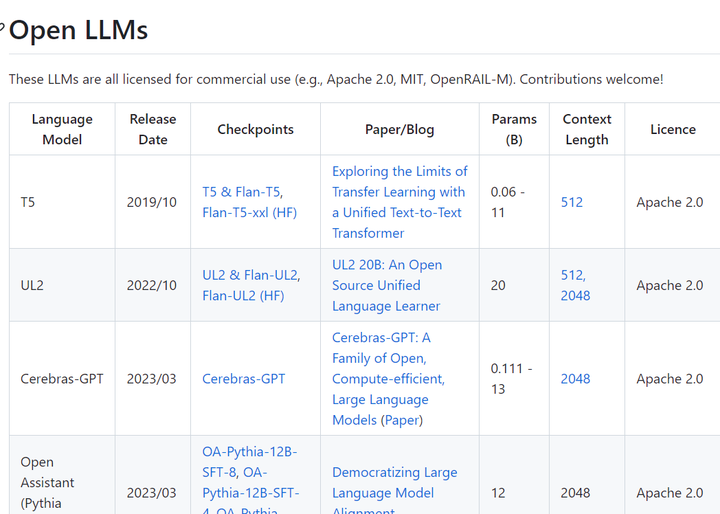
https://github.com/Hannibal046/Awesome-LLM 大型语言模型的论文列表,特别是与 ChatGPT相关的论文,还包含LLM培训框架、部署LLM的工具、关于LLM的课程和教程以及所有公开可用的LLM 权重和 API。

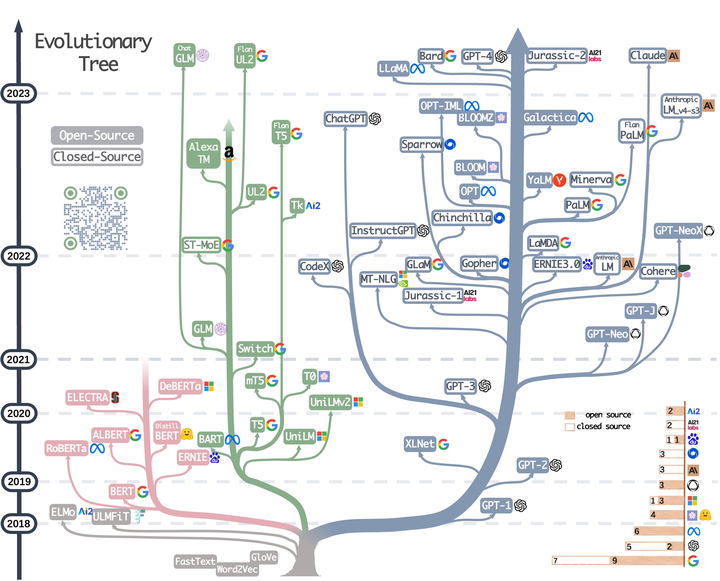
https://github.com/Mooler0410/LLMsPracticalGuide 亚马逊科学家杨靖锋等大佬创建的语言大模型实践指南,收集了许多经典的论文、示例和图表,展现了 GPT 这类大模型的发展历程等
https://github.com/imaurer/awesome-decentralized-llm 能在本地运行的资源 LLM
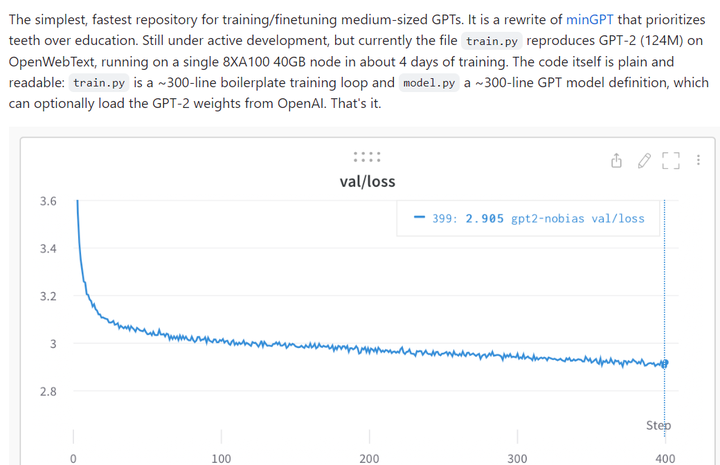
https://github.com/karpathy/nanoGPT karpathy NanoGPT 是用于训练和微调中型尺度 GPT 最简单、最快的库。NanoGPT 代码设计目标是简单易读,其中 train.py 是一个约 300 行的代码;model.py 是一个约 300 行的 GPT 模型定义,它可以选择从 OpenAI 加载 GPT-2 权重。
该项目目前在 1 个 A100 40GB GPU 上一晚上的训练损失约为 3.74,在 4 个 GPU 上训练损失约为 3.60。在 8 x A100 40GB node 上进行 400,000 次迭代(约 1 天)atm 的训练降至 3.1。
至于如何在新文本上微调 GPT,用户可以访问 data/shakespeare 并查看 prepare.py。与 OpenWebText 不同,这将在几秒钟内运行。微调只需要很少的时间,例如在单个 GPU 上只需要几分钟。
https://github.com/togethercomputer/OpenChatKit ChatGPT的开源平替.OpenChatKit是一个由前OpenAI研究员共同打造的开源聊天机器人平台。它包含了训练好的大型语言模型、定制配方和可扩展的检索系统,可以帮助用户快速构建高精度、多功能的聊天机器人应用。
其中,最核心的组件是一个经过微调的、具有200亿参数的语言模型——GPT-NeoXT-Chat-Base-20B。这个模型基于EleutherAI的GPT-NeoX模型,重点调整了多轮对话、问答、分类、提取和摘要等多项任务,并使用了4300万条高质量指令进行训练。这使得OpenChatKit在处理聊天对话时可以提供高精度、流畅的回答。
原文链接:ChatGPT开源平替--OpenChatKit(前OpenAI团队打造)_Chaos_Wang_的博客-CSDN博客

https://github.com/clue-ai/ChatYuan ChatYuan-large-v2是ChatYuan系列中以轻量化实现高质量效果的代表模型,仅仅通过0.7B参数量可以实现业界10B模型的基础效果,并且大大降低了推理成本,提高了使用效率。用户可以在消费级显卡、 PC甚至手机上进行推理(INT4 最低只需 400M

GitHub - tatsu-lab/stanford_alpaca: Code and documentation to train Stanford's Alpaca models, and generate the data. 斯坦福基于 Meta 的 LLaMA 7B 模型微调出一个新模型 Alpaca。该研究让 OpenAI 的 text-davinci-003 模型以 self-instruct 方式生成 52K 指令遵循(instruction-following)样本,以此作为 Alpaca 的训练数据。研究团队已将训练数据、生成训练数据的代码和超参数开源,后续还将发布模型权重和训练代码.
只有 7B 参数的轻量级模型 Alpaca 性能可媲美 GPT-3.5 这样的超大规模语言模型。
https://github.com/nomic-ai/gpt4all 基于 LLaMa 的 LLM 助手,提供训练代码、数据和演示,训练一个自己的 AI 助手。
GPT4All Chat 是一个本地运行的人工智能聊天应用程序,由 GPT4All-J Apache 2 许可的聊天机器人提供支持。该模型在计算机 CPU 上运行,无需联网即可工作,并且不会向外部服务器发送聊天数据(除非您选择使用您的聊天数据来改进未来的 GPT4All 模型)。它允许您与大型语言模型 (LLM) 进行通信,以获得有用的答案、见解和建议。GPT4All Chat 适用于 Windows、Linux 和 macOS。
GitHub - ohmplatform/FreedomGPT: This codebase is for a React and Electron-based app that executes the FreedomGPT LLM locally (offline and private) on Mac and Windows using a chat-based interface (based on Alpaca Lora)
它是一个专注于隐私、中立性和定制化的开源大型语言模型(LLM)聊天机器人。这个AI GPT基于开源模型LLaMA和Alpaca,由CellStrat AI研究实验室开发和托管。根据创建者的说法,这个AI聊天机器人旨在无需任何偏见地回答任何问题,并且不受审查。它是一种技术,使用户能够自由而安全地探索对话型人工智能的广度,同时发现新的使用案例。
FreedomGPT已经被知晓提供了一些主流AI语言模型永远不会涉及的未经审查的问题答案
GitHub - OptimalScale/LMFlow: An Extensible Toolkit for Finetuning and Inference of Large Foundation Models. Large Model for All. 代码库不仅仅是一个简单的模型; 它包括完整的训练流程、模型权重和测试工具。 您可以使用它来构建各种类型的语言模型,包括对话模型、问答模型和文本生成模型等。
此外,我们旨在创建一个开放和民主的大模型共享平台,任何人都可以在这个平台上分享训练模型权重和经验。 我们欢迎任何对大模型感兴趣的人参与进来,与我们一起建设一个开放友好的社区。
https://github.com/lm-sys/FastChat 继草泥马(Alpaca)后,斯坦福联手CMU、UC伯克利等机构的学者再次发布了130亿参数模型骆马(Vicuna),仅需300美元就能实现ChatGPT 90%的性能。FastChat 是Vicuna 的GitHub 开源仓库。
https://github.com/LAION-AI/Open-Assistant 知名 AI 机构 LAION-AI 开源的聊天助手,聊天能力很强,目前中文能力较差。
https://github.com/ggerganov/llama.cpp 可以在Mac上以纯c/c++ 运行 LLaMA推理的模型

GitHub - young-geng/EasyLM: Large language models (LLMs) made easy, EasyLM is a one stop solution for pre-training, finetuning, evaluating and serving LLMs in JAX/Flax.
UC 伯克利的伯克利人工智能研究院(BAIR)发布了一个可以在消费级 GPU 上运行的对话模型 Koala(直译为考拉)。Koala 使用从网络收集的对话数据对 LLaMA 模型进行微调。
Koala 模型在 EasyLM 中使用 JAX/Flax 实现,并在配备 8 个 A100 GPU 的单个 Nvidia DGX 服务器上训练 Koala 模型。完成 2 个 epoch 的训练需要 6 个小时。在公共云计算平台上,进行此类训练的成本通常低于 100 美元。
研究团队将 Koala 与 ChatGPT 和斯坦福大学的 Alpaca 进行了实验比较,结果表明:具有 130 亿参数的 Koala-13B 可以有效地响应各种用户查询,生成的响应通常优于 Alpaca,并且在超过一半的情况下与 ChatGPT 性能相当。

https://github.com/PhoebusSi/Alpaca-CoT 这是Alpaca-CoT项目的存储库,该项目旨在构建一个多接口统一的轻量级指令微调(IFT)平台,该平台具有广泛的指令集合(尤其是CoT数据集)和用于各种大型语言模型以及各种参数效率方法(如LoRA,P-Tuning)的统一接口。我们正在不断扩展我们的指令调整数据收集,并集成更多的LLM。

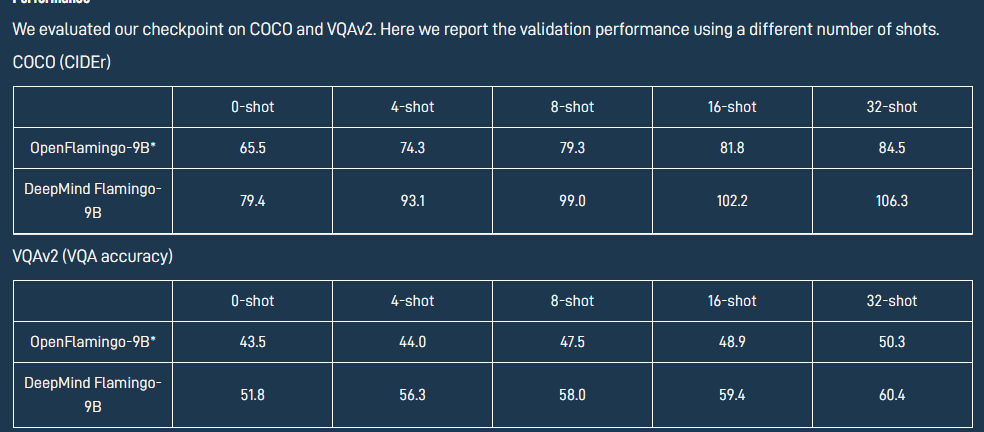
https://github.com/mlfoundations/open_flamingo OpenFlamingo 是一个用于评估和训练大型多模态模型的开源框架,是 DeepMind Flamingo 模型的开源版本,也是 AI 世界关于大模型进展的一大步。
- 它是一个基于Python框架项目,可以用于训练Flamingo风格的大语言模型, 模型框架基于基于Lucidrains的flamingo实现,并依托David Hansmair的flamingo-mini存储库;
- 其次,这个项目包含一个大规模的多模态数据集,其中包含交替的图像和文本序列等多种数据形式;
- 再次,它可以用于视觉-语言任务的上下文学习评估基准,并把你亲自copy训练的模型进行评估,从而可以水更多论文;
- 最后,最最重要的来了,基于LLaMA的OpenFlamingo-9B模型的第一个版本已经出来了,更多更好的模型与权重正在路上。
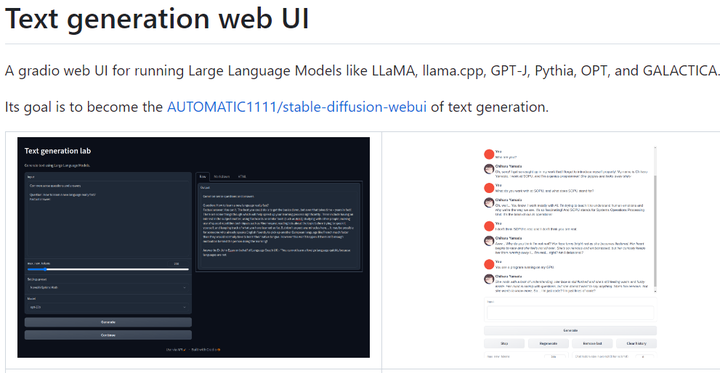
https://github.com/oobabooga/text-generation-webui 一个用于运行大型语言模型(如LLaMA, LLaMA .cpp, GPT-J, Pythia, OPT和GALACTICA)的 web UI。
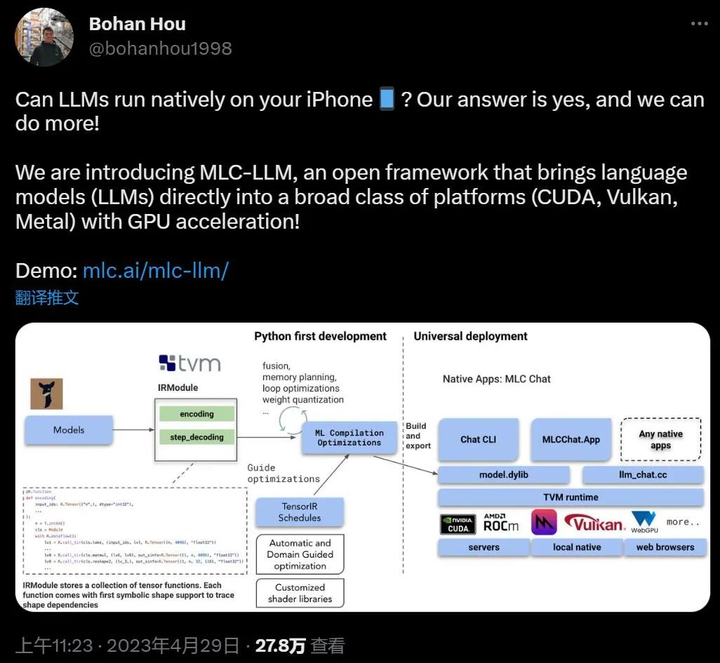
https://github.com/mlc-ai/mlc-llm 陈天奇大佬力作——MLC LLM,在各类硬件上原生部署任意大型语言模型。可将大模型应用于移动端(例如 iPhone)、消费级电脑端(例如 Mac)和 Web 浏览
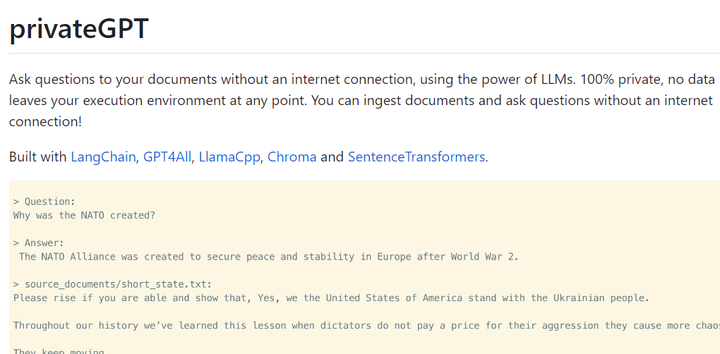
GitHub - imartinez/privateGPT: Interact privately with your documents using the power of GPT, 100% privately, no data leaks 它利用了GPT的强大功能,让你可以在私密环境中与你的文档进行交互。这个项目在GitHub上发布,任何人都可以下载并使用这个应用程序。
https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese 基于中文医学知识的LLaMA微调模型

版权归原作者 春夏秋冬又一年 所有, 如有侵权,请联系我们删除。