
前文链接如下:
要点初见:开源AI绘画工具Stable Diffusion代码分析(文本转图像)、论文介绍(上)_BingLiHanShuang的博客-CSDN博客
二、Stable Diffusion代码分析
7、关闭PyTorch内部新参数的自动求导
with torch.no_grad():
根据
【pytorch系列】 with torch.no_grad():用法详解_大黑山修道的博客-CSDN博客_torch.no_grad():
在PyTorch中,tensor有一个requires_grad参数,如果设置为True,则反向传播时,该tensor就会自动求导。tensor的requires_grad的属性默认为False,若一个节点(叶子变量:自己创建的tensor)requires_grad被设置为True,那么所有依赖它的节点requires_grad都为True。
当requires_grad设置为False时,反向传播时就不会自动求导了,因此大大节约了显存或者说内存。
在with torch.no_grad下,所有计算得出的tensor的requires_grad都自动设置为False。即使一个tensor(命名为x)的requires_grad = True,在with torch.no_grad计算,由x得到的新tensor(命名为w-标量)requires_grad也为False,且grad_fn也为None,即不会对w求导。
with precision_scope("cuda"):
该句已在上篇的【二、6、读取输入的文字描述】中解释,此略。
8、权重是否使用指数移动平均?
with model.ema_scope():
该函数在ldm/models/autoencoder.py与ldm/models/diffusion/ddpm.py中都有所实现,实现方法类似,此处以ddpm.py中的ema_scope()为例:
def ema_scope(self, context=None):
if self.use_ema:
self.model_ema.store(self.model.parameters())
self.model_ema.copy_to(self.model)
if context is not None:
print(f"{context}: Switched to EMA weights")
try:
yield None
finally:
if self.use_ema:
self.model_ema.restore(self.model.parameters())
if context is not None:
print(f"{context}: Restored training weights")
表面理解,当定义的use_ema为True的时候存储并拷贝参数与模型,切换至EMA权重。EMA全称Exponential Moving Average,即指数移动平均,根据
指数移动平均(EMA)的原理及PyTorch实现_枫林扬的博客-CSDN博客_指数移动平均
在对以时序排列的数据求平均时,指数移动平均权重会给予近期数据更高权重。
Stable Diffusion开源代码的Readme中专门提了use_ema:
所有Stable Diffusion V1版本的推理配置都设计为用于仅 EMA 检查点(EMA-only checkpoints),因此源码在配置中设置
use_ema=False,否则模型将尝试从非EMA权重切换到 EMA 权重。如果想测试是否使用EMA的影响,我们提供包含两种类型权重的“完整”检查点("full" checkpoints)。对于这些,
use_ema=False将加载和使用非EMA权重。
在Stable Diffusion模型中,除了ddpm模型将use_ema设置为True,其他yaml或代码中都将use_ema设置为False。简单说就是不推荐在Stable Diffusion中使用EMA。
9、模型调用、检查NSFW、添加水印并保存
all_samples = list()
for n in trange(opt.n_iter, desc="Sampling"):
for prompts in tqdm(data, desc="data"):
uc = None
if opt.scale != 1.0:
uc = model.get_learned_conditioning(batch_size * [""])
if isinstance(prompts, tuple):
prompts = list(prompts)
c = model.get_learned_conditioning(prompts)
shape = [opt.C, opt.H // opt.f, opt.W // opt.f]
samples_ddim, _ = sampler.sample(S=opt.ddim_steps,
conditioning=c,
batch_size=opt.n_samples,
shape=shape,
verbose=False,
unconditional_guidance_scale=opt.scale,
unconditional_conditioning=uc,
eta=opt.ddim_eta,
x_T=start_code)
x_samples_ddim = model.decode_first_stage(samples_ddim)
x_samples_ddim = torch.clamp((x_samples_ddim + 1.0) / 2.0, min=0.0, max=1.0)
x_samples_ddim = x_samples_ddim.cpu().permute(0, 2, 3, 1).numpy()
x_checked_image, has_nsfw_concept = check_safety(x_samples_ddim)
x_checked_image_torch = torch.from_numpy(x_checked_image).permute(0, 3, 1, 2)
if not opt.skip_save:
for x_sample in x_checked_image_torch:
x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
img = Image.fromarray(x_sample.astype(np.uint8))
img = put_watermark(img, wm_encoder)
img.save(os.path.join(sample_path, f"{base_count:05}.png"))
base_count += 1
if not opt.skip_grid:
all_samples.append(x_checked_image_torch)
生成的图像结果都存储在all_samples这个list里,而文本描述都存在prompts里,该部分可分为调用模型、解码、检查NSFW、添加水印并保存图像四个部分:
(1)调用模型
uc = None
if opt.scale != 1.0:
uc = model.get_learned_conditioning(batch_size * [""])
if isinstance(prompts, tuple):
prompts = list(prompts)
c = model.get_learned_conditioning(prompts)
shape = [opt.C, opt.H // opt.f, opt.W // opt.f]
samples_ddim, _ = sampler.sample(S=opt.ddim_steps,
conditioning=c,
batch_size=opt.n_samples,
shape=shape,
verbose=False,
unconditional_guidance_scale=opt.scale,
unconditional_conditioning=uc,
eta=opt.ddim_eta,
x_T=start_code)
首先,代码通过get_learned_conditioning函数获取condition、uncondition(当输入参数scale不为1时才读取uncondition),输入的文字描述被包含在了condition中。
这里的condition指的是扩散模型是有条件扩散模型还是无条件扩散模型,按照前文的Stable Diffusion论文分析,Stable Diffusion、DALLE2、谷歌的Imagen模型都是无条件扩散模型,这种无分类器指导(classifier-free guidance)的思想也是当下图像生成神经网络出色完成任务的关键之一。
关于有条件扩散模型、无条件扩散模型的分析可以参考:Guidance: a cheat code for diffusion models – Sander Dieleman
ldm/models/diffusion/ddpm.py中的get_learned_conditioning如下:
def get_learned_conditioning(self, c):
if self.cond_stage_forward is None:
if hasattr(self.cond_stage_model, 'encode') and callable(self.cond_stage_model.encode):
c = self.cond_stage_model.encode(c)
if isinstance(c, DiagonalGaussianDistribution):
c = c.mode()
else:
c = self.cond_stage_model(c)
else:
assert hasattr(self.cond_stage_model, self.cond_stage_forward)
c = getattr(self.cond_stage_model, self.cond_stage_forward)(c)
return c
其中cond_stage_model在DDPM运行__init__时在instantiate_cond_stage函数中初始化:
def instantiate_cond_stage(self, config):
if not self.cond_stage_trainable:
if config == "__is_first_stage__":
print("Using first stage also as cond stage.")
self.cond_stage_model = self.first_stage_model
elif config == "__is_unconditional__":
print(f"Training {self.__class__.__name__} as an unconditional model.")
self.cond_stage_model = None
# self.be_unconditional = True
else:
model = instantiate_from_config(config)
self.cond_stage_model = model.eval()
self.cond_stage_model.train = disabled_train
for param in self.cond_stage_model.parameters():
param.requires_grad = False
else:
assert config != '__is_first_stage__'
assert config != '__is_unconditional__'
model = instantiate_from_config(config)
self.cond_stage_model = model
可见condition是通过model = instantiate_from_config(config)获取model,并运行model.eval()获取的,其中instantiate_from_config、eval都是ldm库中util模块的API。
其次,模型输入shape定为[c, h / f, w / f],其中f是降采样倍数,两个除法都是整除。
最后,调用sample函数:
samples_ddim, _ = sampler.sample(S=opt.ddim_steps,
conditioning=c,
batch_size=opt.n_samples,
shape=shape,
verbose=False,
unconditional_guidance_scale=opt.scale,
unconditional_conditioning=uc,
eta=opt.ddim_eta,
x_T=start_code)
ldm/models/diffusion/ddim.py中的sample函数如下:
def sample(self,
S,
batch_size,
shape,
conditioning=None,
callback=None,
normals_sequence=None,
img_callback=None,
quantize_x0=False,
eta=0.,
mask=None,
x0=None,
temperature=1.,
noise_dropout=0.,
score_corrector=None,
corrector_kwargs=None,
verbose=True,
x_T=None,
log_every_t=100,
unconditional_guidance_scale=1.,
unconditional_conditioning=None,
# this has to come in the same format as the conditioning, # e.g. as encoded tokens, ...
**kwargs
):
if conditioning is not None:
if isinstance(conditioning, dict):
cbs = conditioning[list(conditioning.keys())[0]].shape[0]
if cbs != batch_size:
print(f"Warning: Got {cbs} conditionings but batch-size is {batch_size}")
else:
if conditioning.shape[0] != batch_size:
print(f"Warning: Got {conditioning.shape[0]} conditionings but batch-size is {batch_size}")
self.make_schedule(ddim_num_steps=S, ddim_eta=eta, verbose=verbose)
# sampling
C, H, W = shape
size = (batch_size, C, H, W)
print(f'Data shape for DDIM sampling is {size}, eta {eta}')
samples, intermediates = self.ddim_sampling(conditioning, size,
callback=callback,
img_callback=img_callback,
quantize_denoised=quantize_x0,
mask=mask, x0=x0,
ddim_use_original_steps=False,
noise_dropout=noise_dropout,
temperature=temperature,
score_corrector=score_corrector,
corrector_kwargs=corrector_kwargs,
x_T=x_T,
log_every_t=log_every_t,
unconditional_guidance_scale=unconditional_guidance_scale,
unconditional_conditioning=unconditional_conditioning,
)
return samples, intermediates
sample函数中首先调用了make_schedule函数来获取timestep、计算模型输入参数:
def make_schedule(self, ddim_num_steps, ddim_discretize="uniform", ddim_eta=0., verbose=True):
self.ddim_timesteps = make_ddim_timesteps(ddim_discr_method=ddim_discretize, num_ddim_timesteps=ddim_num_steps,
num_ddpm_timesteps=self.ddpm_num_timesteps,verbose=verbose)
alphas_cumprod = self.model.alphas_cumprod
assert alphas_cumprod.shape[0] == self.ddpm_num_timesteps, 'alphas have to be defined for each timestep'
to_torch = lambda x: x.clone().detach().to(torch.float32).to(self.model.device)
self.register_buffer('betas', to_torch(self.model.betas))
self.register_buffer('alphas_cumprod', to_torch(alphas_cumprod))
self.register_buffer('alphas_cumprod_prev', to_torch(self.model.alphas_cumprod_prev))
# calculations for diffusion q(x_t | x_{t-1}) and others
self.register_buffer('sqrt_alphas_cumprod', to_torch(np.sqrt(alphas_cumprod.cpu())))
self.register_buffer('sqrt_one_minus_alphas_cumprod', to_torch(np.sqrt(1. - alphas_cumprod.cpu())))
self.register_buffer('log_one_minus_alphas_cumprod', to_torch(np.log(1. - alphas_cumprod.cpu())))
self.register_buffer('sqrt_recip_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod.cpu())))
self.register_buffer('sqrt_recipm1_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod.cpu() - 1)))
# ddim sampling parameters
ddim_sigmas, ddim_alphas, ddim_alphas_prev = make_ddim_sampling_parameters(alphacums=alphas_cumprod.cpu(),
ddim_timesteps=self.ddim_timesteps,
eta=ddim_eta,verbose=verbose)
self.register_buffer('ddim_sigmas', ddim_sigmas)
self.register_buffer('ddim_alphas', ddim_alphas)
self.register_buffer('ddim_alphas_prev', ddim_alphas_prev)
self.register_buffer('ddim_sqrt_one_minus_alphas', np.sqrt(1. - ddim_alphas))
sigmas_for_original_sampling_steps = ddim_eta * torch.sqrt(
(1 - self.alphas_cumprod_prev) / (1 - self.alphas_cumprod) * (
1 - self.alphas_cumprod / self.alphas_cumprod_prev))
self.register_buffer('ddim_sigmas_for_original_num_steps', sigmas_for_original_sampling_steps)
其中register_buffer函数很简单,就是个封装setattr的设置属性值的函数,如下所示:
def register_buffer(self, name, attr):
if type(attr) == torch.Tensor:
if attr.device != torch.device("cuda"):
attr = attr.to(torch.device("cuda"))
setattr(self, name, attr)
而包含在ldm/modules/diffusionmodules/util.py中的make_ddim_sampling_parameters函数则是用于计算DDIM模型sampling参数的函数,计算方法参考这篇论文:https://arxiv.org/pdf/2010.02502.pdf,make_ddim_sampling_parameters函数如下所示:
def make_ddim_sampling_parameters(alphacums, ddim_timesteps, eta, verbose=True):
# select alphas for computing the variance schedule
alphas = alphacums[ddim_timesteps]
alphas_prev = np.asarray([alphacums[0]] + alphacums[ddim_timesteps[:-1]].tolist())
# according the the formula provided in https://arxiv.org/abs/2010.02502
sigmas = eta * np.sqrt((1 - alphas_prev) / (1 - alphas) * (1 - alphas / alphas_prev))
if verbose:
print(f'Selected alphas for ddim sampler: a_t: {alphas}; a_(t-1): {alphas_prev}')
print(f'For the chosen value of eta, which is {eta}, '
f'this results in the following sigma_t schedule for ddim sampler {sigmas}')
return sigmas, alphas, alphas_prev
紧接着,sample函数调用ddim_sampling函数正式开始执行DDIM方法下的图像生成:
samples, intermediates = self.ddim_sampling(conditioning, size,
callback=callback,
img_callback=img_callback,
quantize_denoised=quantize_x0,
mask=mask, x0=x0,
ddim_use_original_steps=False,
noise_dropout=noise_dropout,
temperature=temperature,
score_corrector=score_corrector,
corrector_kwargs=corrector_kwargs,
x_T=x_T,
log_every_t=log_every_t,
unconditional_guidance_scale=unconditional_guidance_scale,
unconditional_conditioning=unconditional_conditioning,
)
ddim_sampling函数内容如下:
@torch.no_grad()
def ddim_sampling(self, cond, shape,
x_T=None, ddim_use_original_steps=False,
callback=None, timesteps=None, quantize_denoised=False,
mask=None, x0=None, img_callback=None, log_every_t=100,
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
unconditional_guidance_scale=1., unconditional_conditioning=None,):
device = self.model.betas.device
b = shape[0]
if x_T is None:
img = torch.randn(shape, device=device)
else:
img = x_T
if timesteps is None:
timesteps = self.ddpm_num_timesteps if ddim_use_original_steps else self.ddim_timesteps
elif timesteps is not None and not ddim_use_original_steps:
subset_end = int(min(timesteps / self.ddim_timesteps.shape[0], 1) * self.ddim_timesteps.shape[0]) - 1
timesteps = self.ddim_timesteps[:subset_end]
intermediates = {'x_inter': [img], 'pred_x0': [img]}
time_range = reversed(range(0,timesteps)) if ddim_use_original_steps else np.flip(timesteps)
total_steps = timesteps if ddim_use_original_steps else timesteps.shape[0]
print(f"Running DDIM Sampling with {total_steps} timesteps")
iterator = tqdm(time_range, desc='DDIM Sampler', total=total_steps)
for i, step in enumerate(iterator):
index = total_steps - i - 1
ts = torch.full((b,), step, device=device, dtype=torch.long)
if mask is not None:
assert x0 is not None
img_orig = self.model.q_sample(x0, ts) # TODO: deterministic forward pass?
img = img_orig * mask + (1. - mask) * img
outs = self.p_sample_ddim(img, cond, ts, index=index, use_original_steps=ddim_use_original_steps,
quantize_denoised=quantize_denoised, temperature=temperature,
noise_dropout=noise_dropout, score_corrector=score_corrector,
corrector_kwargs=corrector_kwargs,
unconditional_guidance_scale=unconditional_guidance_scale,
unconditional_conditioning=unconditional_conditioning)
img, pred_x0 = outs
if callback: callback(i)
if img_callback: img_callback(pred_x0, i)
if index % log_every_t == 0 or index == total_steps - 1:
intermediates['x_inter'].append(img)
intermediates['pred_x0'].append(pred_x0)
return img, intermediates
该函数根据扩散模型的原理先生成了一个random的img,并开始step步的训练。生成的图像存储于img,训练的中间过程(此轮预测的图像、预测t0时刻的图像)存储于intermediates。训练主要将该噪声图像传给核心处理函数p_sample_ddim来进行:
@torch.no_grad()
def p_sample_ddim(self, x, c, t, index, repeat_noise=False, use_original_steps=False, quantize_denoised=False,
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
unconditional_guidance_scale=1., unconditional_conditioning=None):
b, *_, device = *x.shape, x.device
if unconditional_conditioning is None or unconditional_guidance_scale == 1.:
e_t = self.model.apply_model(x, t, c)
else:
x_in = torch.cat([x] * 2)
t_in = torch.cat([t] * 2)
c_in = torch.cat([unconditional_conditioning, c])
e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)
e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond)
if score_corrector is not None:
assert self.model.parameterization == "eps"
e_t = score_corrector.modify_score(self.model, e_t, x, t, c, **corrector_kwargs)
alphas = self.model.alphas_cumprod if use_original_steps else self.ddim_alphas
alphas_prev = self.model.alphas_cumprod_prev if use_original_steps else self.ddim_alphas_prev
sqrt_one_minus_alphas = self.model.sqrt_one_minus_alphas_cumprod if use_original_steps else self.ddim_sqrt_one_minus_alphas
sigmas = self.model.ddim_sigmas_for_original_num_steps if use_original_steps else self.ddim_sigmas
# select parameters corresponding to the currently considered timestep
a_t = torch.full((b, 1, 1, 1), alphas[index], device=device)
a_prev = torch.full((b, 1, 1, 1), alphas_prev[index], device=device)
sigma_t = torch.full((b, 1, 1, 1), sigmas[index], device=device)
sqrt_one_minus_at = torch.full((b, 1, 1, 1), sqrt_one_minus_alphas[index],device=device)
# current prediction for x_0
pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt()
if quantize_denoised:
pred_x0, _, *_ = self.model.first_stage_model.quantize(pred_x0)
# direction pointing to x_t
dir_xt = (1. - a_prev - sigma_t**2).sqrt() * e_t
noise = sigma_t * noise_like(x.shape, device, repeat_noise) * temperature
if noise_dropout > 0.:
noise = torch.nn.functional.dropout(noise, p=noise_dropout)
x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noise
return x_prev, pred_x0
p_sample_ddim函数首先调用apply_model对输入数据进行了归一化,与向其它神经网络输入数据时的处理方法类似,可以参考ldm/models/diffusion/ddpm.py中的apply_model函数:
def apply_model(self, x_noisy, t, cond, return_ids=False):
if isinstance(cond, dict):
# hybrid case, cond is exptected to be a dict
pass
else:
if not isinstance(cond, list):
cond = [cond]
key = 'c_concat' if self.model.conditioning_key == 'concat' else 'c_crossattn'
cond = {key: cond}
if hasattr(self, "split_input_params"):
assert len(cond) == 1 # todo can only deal with one conditioning atm
assert not return_ids
ks = self.split_input_params["ks"] # eg. (128, 128)
stride = self.split_input_params["stride"] # eg. (64, 64)
h, w = x_noisy.shape[-2:]
fold, unfold, normalization, weighting = self.get_fold_unfold(x_noisy, ks, stride)
z = unfold(x_noisy) # (bn, nc * prod(**ks), L)
# Reshape to img shape
z = z.view((z.shape[0], -1, ks[0], ks[1], z.shape[-1])) # (bn, nc, ks[0], ks[1], L )
z_list = [z[:, :, :, :, i] for i in range(z.shape[-1])]
if self.cond_stage_key in ["image", "LR_image", "segmentation",
'bbox_img'] and self.model.conditioning_key: # todo check for completeness
c_key = next(iter(cond.keys())) # get key
c = next(iter(cond.values())) # get value
assert (len(c) == 1) # todo extend to list with more than one elem
c = c[0] # get element
c = unfold(c)
c = c.view((c.shape[0], -1, ks[0], ks[1], c.shape[-1])) # (bn, nc, ks[0], ks[1], L )
cond_list = [{c_key: [c[:, :, :, :, i]]} for i in range(c.shape[-1])]
elif self.cond_stage_key == 'coordinates_bbox':
assert 'original_image_size' in self.split_input_params, 'BoudingBoxRescaling is missing original_image_size'
# assuming padding of unfold is always 0 and its dilation is always 1
n_patches_per_row = int((w - ks[0]) / stride[0] + 1)
full_img_h, full_img_w = self.split_input_params['original_image_size']
# as we are operating on latents, we need the factor from the original image size to the
# spatial latent size to properly rescale the crops for regenerating the bbox annotations
num_downs = self.first_stage_model.encoder.num_resolutions - 1
rescale_latent = 2 ** (num_downs)
# get top left postions of patches as conforming for the bbbox tokenizer, therefore we
# need to rescale the tl patch coordinates to be in between (0,1)
tl_patch_coordinates = [(rescale_latent * stride[0] * (patch_nr % n_patches_per_row) / full_img_w,
rescale_latent * stride[1] * (patch_nr // n_patches_per_row) / full_img_h)
for patch_nr in range(z.shape[-1])]
# patch_limits are tl_coord, width and height coordinates as (x_tl, y_tl, h, w)
patch_limits = [(x_tl, y_tl,
rescale_latent * ks[0] / full_img_w,
rescale_latent * ks[1] / full_img_h) for x_tl, y_tl in tl_patch_coordinates]
# patch_values = [(np.arange(x_tl,min(x_tl+ks, 1.)),np.arange(y_tl,min(y_tl+ks, 1.))) for x_tl, y_tl in tl_patch_coordinates]
# tokenize crop coordinates for the bounding boxes of the respective patches
patch_limits_tknzd = [torch.LongTensor(self.bbox_tokenizer._crop_encoder(bbox))[None].to(self.device)
for bbox in patch_limits] # list of length l with tensors of shape (1, 2)
print(patch_limits_tknzd[0].shape)
# cut tknzd crop position from conditioning
assert isinstance(cond, dict), 'cond must be dict to be fed into model'
cut_cond = cond['c_crossattn'][0][..., :-2].to(self.device)
print(cut_cond.shape)
adapted_cond = torch.stack([torch.cat([cut_cond, p], dim=1) for p in patch_limits_tknzd])
adapted_cond = rearrange(adapted_cond, 'l b n -> (l b) n')
print(adapted_cond.shape)
adapted_cond = self.get_learned_conditioning(adapted_cond)
print(adapted_cond.shape)
adapted_cond = rearrange(adapted_cond, '(l b) n d -> l b n d', l=z.shape[-1])
print(adapted_cond.shape)
cond_list = [{'c_crossattn': [e]} for e in adapted_cond]
else:
cond_list = [cond for i in range(z.shape[-1])] # Todo make this more efficient
# apply model by loop over crops
output_list = [self.model(z_list[i], t, **cond_list[i]) for i in range(z.shape[-1])]
assert not isinstance(output_list[0],
tuple) # todo cant deal with multiple model outputs check this never happens
o = torch.stack(output_list, axis=-1)
o = o * weighting
# Reverse reshape to img shape
o = o.view((o.shape[0], -1, o.shape[-1])) # (bn, nc * ks[0] * ks[1], L)
# stitch crops together
x_recon = fold(o) / normalization
else:
x_recon = self.model(x_noisy, t, **cond)
if isinstance(x_recon, tuple) and not return_ids:
return x_recon[0]
else:
return x_recon
此部分主要是通过调用torch.nn.Fold、torch.nn.Unfold对输入图像、文字描述、timestep进行滑动裁剪和还原,并计算weighting、normalization等参数,并将新生成的训练数据进行返回。
接着,p_sample_ddim函数参考Stable Diffusion的论文公式进行了详细计算。根据Stable Diffusion附录B“去噪扩散模型的详细信息”的介绍,去噪扩散模型是一种生成模型,使用类似的马尔可夫结构按时序向后运行。为了简化该模型的证据下界 (evidence lower bound,简称ELBO) 在离散时间步上分解后的剩余项,论文根据真实后验 q(xt−1|xt, x0) 指定参数化后的p(xt−1|xt)。因此使用
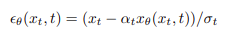
重新参数化,将重建项表示为去噪目标,
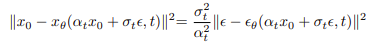
并重新加权,它为Latent Diffusion Models公式中的每个terms分配相同的权重和结果:
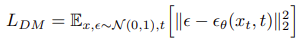
故p_sample_ddim函数在此处先基于t时刻带噪声的图像x预测了t0时刻未添加噪声的图像pred_x0(数据开始样本data sample x0):
pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt()
之后计算获得t时刻图像x的direction pointing、计算噪声、调用了一次模型量化并通过一次Dropout层(torch.nn.functional.dropout是PyTorch中的Dropout层,在 training 模式下,基于伯努利分布抽样,以概率noise_dropout对张量noise的值随机置0,只用剩下的参数进行训练,目的是防止模型过拟合),最后计算出t-1时刻的降噪图像x_prev:
x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noise
x_prev即作为此轮的预测结果进行输出,而pred_x0作为ddim_sampling函数中建立中间体intermediates所需要的list内容,也进行输出。
(2)解码
x_samples_ddim = model.decode_first_stage(samples_ddim)
x_samples_ddim = torch.clamp((x_samples_ddim + 1.0) / 2.0, min=0.0, max=1.0)
x_samples_ddim = x_samples_ddim.cpu().permute(0, 2, 3, 1).numpy()
该部分的功能主要靠调用decode_first_stage函数实现,以ldm/models/diffusion/ddpm.py中的decode_first_stage函数为例:
@torch.no_grad()
def decode_first_stage(self, z, predict_cids=False, force_not_quantize=False):
if predict_cids:
if z.dim() == 4:
z = torch.argmax(z.exp(), dim=1).long()
z = self.first_stage_model.quantize.get_codebook_entry(z, shape=None)
z = rearrange(z, 'b h w c -> b c h w').contiguous()
z = 1. / self.scale_factor * z
if hasattr(self, "split_input_params"):
if self.split_input_params["patch_distributed_vq"]:
ks = self.split_input_params["ks"] # eg. (128, 128)
stride = self.split_input_params["stride"] # eg. (64, 64)
uf = self.split_input_params["vqf"]
bs, nc, h, w = z.shape
if ks[0] > h or ks[1] > w:
ks = (min(ks[0], h), min(ks[1], w))
print("reducing Kernel")
if stride[0] > h or stride[1] > w:
stride = (min(stride[0], h), min(stride[1], w))
print("reducing stride")
fold, unfold, normalization, weighting = self.get_fold_unfold(z, ks, stride, uf=uf)
z = unfold(z) # (bn, nc * prod(**ks), L)
# 1. Reshape to img shape
z = z.view((z.shape[0], -1, ks[0], ks[1], z.shape[-1])) # (bn, nc, ks[0], ks[1], L )
# 2. apply model loop over last dim
if isinstance(self.first_stage_model, VQModelInterface):
output_list = [self.first_stage_model.decode(z[:, :, :, :, i],
force_not_quantize=predict_cids or force_not_quantize)
for i in range(z.shape[-1])]
else:
output_list = [self.first_stage_model.decode(z[:, :, :, :, i])
for i in range(z.shape[-1])]
o = torch.stack(output_list, axis=-1) # # (bn, nc, ks[0], ks[1], L)
o = o * weighting
# Reverse 1. reshape to img shape
o = o.view((o.shape[0], -1, o.shape[-1])) # (bn, nc * ks[0] * ks[1], L)
# stitch crops together
decoded = fold(o)
decoded = decoded / normalization # norm is shape (1, 1, h, w)
return decoded
else:
if isinstance(self.first_stage_model, VQModelInterface):
return self.first_stage_model.decode(z, force_not_quantize=predict_cids or force_not_quantize)
else:
return self.first_stage_model.decode(z)
else:
if isinstance(self.first_stage_model, VQModelInterface):
return self.first_stage_model.decode(z, force_not_quantize=predict_cids or force_not_quantize)
else:
return self.first_stage_model.decode(z)
输入神经网络时如何fold封装数据,decode的时候就怎么unfold还原回来,还是操作图像通道、torch.nn.Unfold、torch.nn.Fold、归一化那一套。
torch.clamp进行限幅,x_samples_ddim.cpu().permute(0, 2, 3, 1).numpy()转换通道。此处用permute(0, 2, 3, 1)将(C0,C1,C2,C3)转为(C0,C2,C3,C1)以适应check_safety的模型,后续check_safety后使用permute(0, 3, 1, 2)就将(C0,C2,C3,C1)转回(C0,C1,C2,C3)。
(3)检查NSFW
如上篇的【二、2、NOT SAFE FOR WORK?】所介绍,此部分就是用于筛除不正经的文本,输出结果存储于x_checked_image中:
x_checked_image, has_nsfw_concept = check_safety(x_samples_ddim)
x_checked_image_torch = torch.from_numpy(x_checked_image).permute(0, 3, 1, 2)
(4)添加水印并保存图像
此处将归一化的数据x255并取整,而后按上篇的【二、5、隐形水印设置】添加隐形水印“StableDiffusionV1”。添加水印部分如下:
if not opt.skip_save:
for x_sample in x_checked_image_torch:
x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
img = Image.fromarray(x_sample.astype(np.uint8))
img = put_watermark(img, wm_encoder)
img.save(os.path.join(sample_path, f"{base_count:05}.png"))
base_count += 1
if not opt.skip_grid:
all_samples.append(x_checked_image_torch)
10、将batch中生成的图像拼接成一张图像
if not opt.skip_grid:
# additionally, save as grid
grid = torch.stack(all_samples, 0)
grid = rearrange(grid, 'n b c h w -> (n b) c h w')
grid = make_grid(grid, nrow=n_rows)
# to image
grid = 255. * rearrange(grid, 'c h w -> h w c').cpu().numpy()
img = Image.fromarray(grid.astype(np.uint8))
img = put_watermark(img, wm_encoder)
img.save(os.path.join(outpath, f'grid-{grid_count:04}.png'))
grid_count += 1
如果玩过NovelAI会有印象,当你设置若干batch完成多张图像生成后,页面会在第一张图放一张所有batch图像的拼接图像,这就是这段代码实现的功能。
本文简单介绍了Stable Diffusion V1开源代码的txt2img.py结构与功能,接下来有机会将写一篇博文介绍img2img.py的功能,以图生成图亦是Stable Diffusion非常出色的功能。
如有理解不对、介绍出入的地方,欢迎多多指正!

Positive prompt:
{{alice}}, alice in wonderland, {{{solo}}},1girl,{{delicate face}},vely long hair,blunt_bangs,{{{full body}}},{floating hair}, {looking_at_viewer},open mouth,{looking_at_viewer},open mouth,blue eyes,Blonde_hair,Beautiful eyes,gradient hair,{{white_frilled_dress}},{{white pantyhose}}, {long sleeves},{juliet_sleeves},{puffy sleeves},white hair bow, Skirt pleats, blue dress bow, blue_large_bow,{{{stading}}},{{{arms behind back}}},sleeves past wrists,sleeves past fingers,{forest}, flowering hedge, scenery,Flowery meadow,clear sky,{delicate grassland},{blooming white roses},flying butterfly,shadow,beautiful sky,cumulonimbus,{{absurdres}},incredibly_absurdres, huge_filesize, {best quality},{masterpiece},delicate details,refined rendering,original,official_art, 10s,
Negative prompt:
lowres,highres, worst quality,low quality,normal quality,artbook, game_cg, duplicate,grossproportions,deformed,out of frame,60s,70s,80s,90s,00s, ugly,morbid,mutation,death, kaijuu,mutation,no hunmans.monster girl,arthropod girl,arthropod limbs,tentacles,blood,size difference,sketch,blurry,blurry face,blurry background,blurry foreground, disfigured,extra,extra_arms,extra_ears,extra_breasts,extra_legs,extra_penises,extra_mouth,multiple_arms,multiple_legs,mutilated,tranny,trans,trannsexual,out of frame,poorly drawnhands,extra fingers,mutated hands, poorly drawn face, bad anatomy,bad proportions, extralimbs,more than 2 nipples,extra limbs,bad anatomy,malformed limbs,missing arms,miss finglegs,mutated hands,fused fingers,too many fingers,long neck,bad finglegs,cropped, bad feet,bad anatomy disfigured,malformed mutated,missing limb,malformed hands,
Steps: 50, Sampler: DDIM, CFG scale: 7, Size: 1024x1024
版权归原作者 BingLiHanShuang 所有, 如有侵权,请联系我们删除。