
1. 起源
**分组卷积(Group Convolution) **起源于2012年的 AlexNet - 《ImageNet Classification with Deep Convolutional Neural Networks》。由于当时硬件资源的限制,因为作者将Feature Maps分给多个GPU进行处理,最后把多个GPU的结果进行融合。如下图:
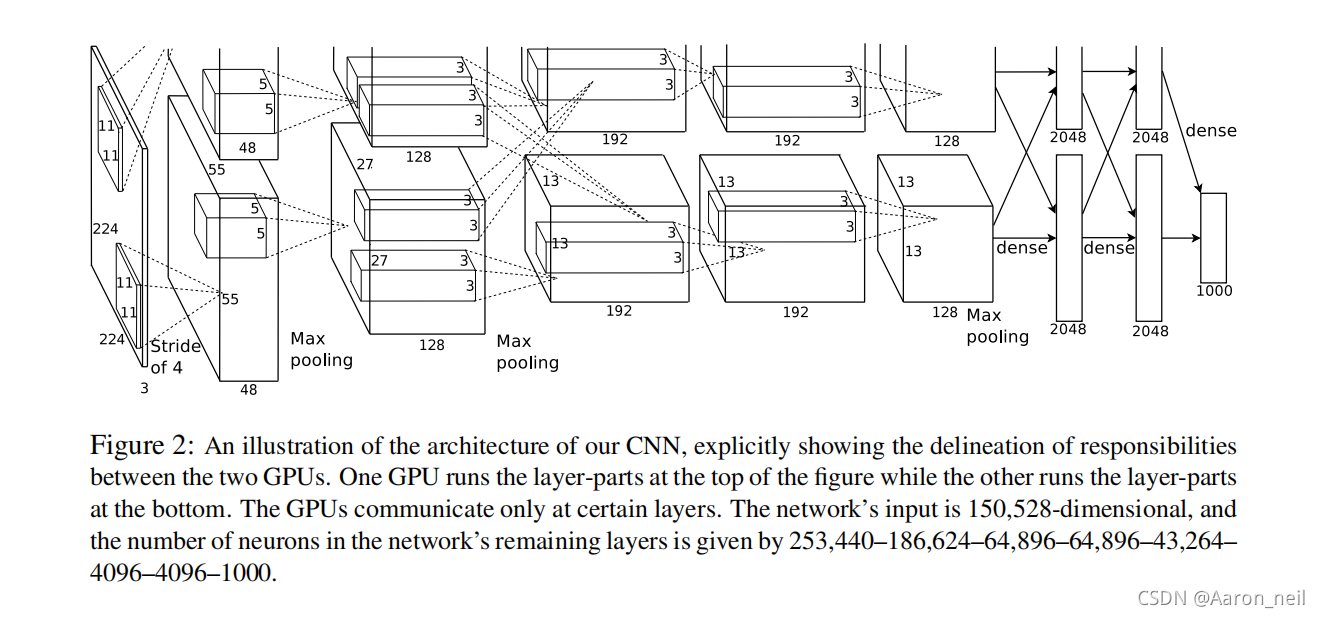
2. 分组卷积 介绍
我接下来用图来直观的展示普通2D卷积 和 分组卷积的区别:
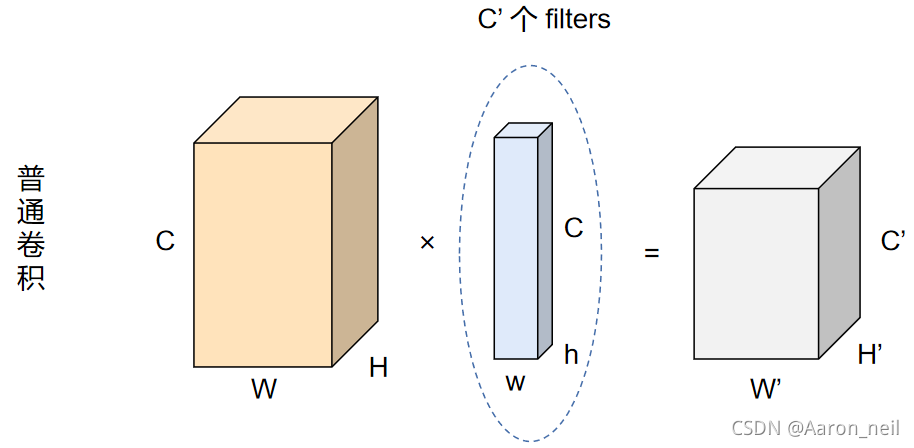
标准的 2D 卷积步骤如下图所示,输入特征为 (H × W × C) ,然后应用 C' 个filters(每个filter的大小为 (h × w × c),输入层被转换为大小为 (H' × W' × C') 的输出特征。
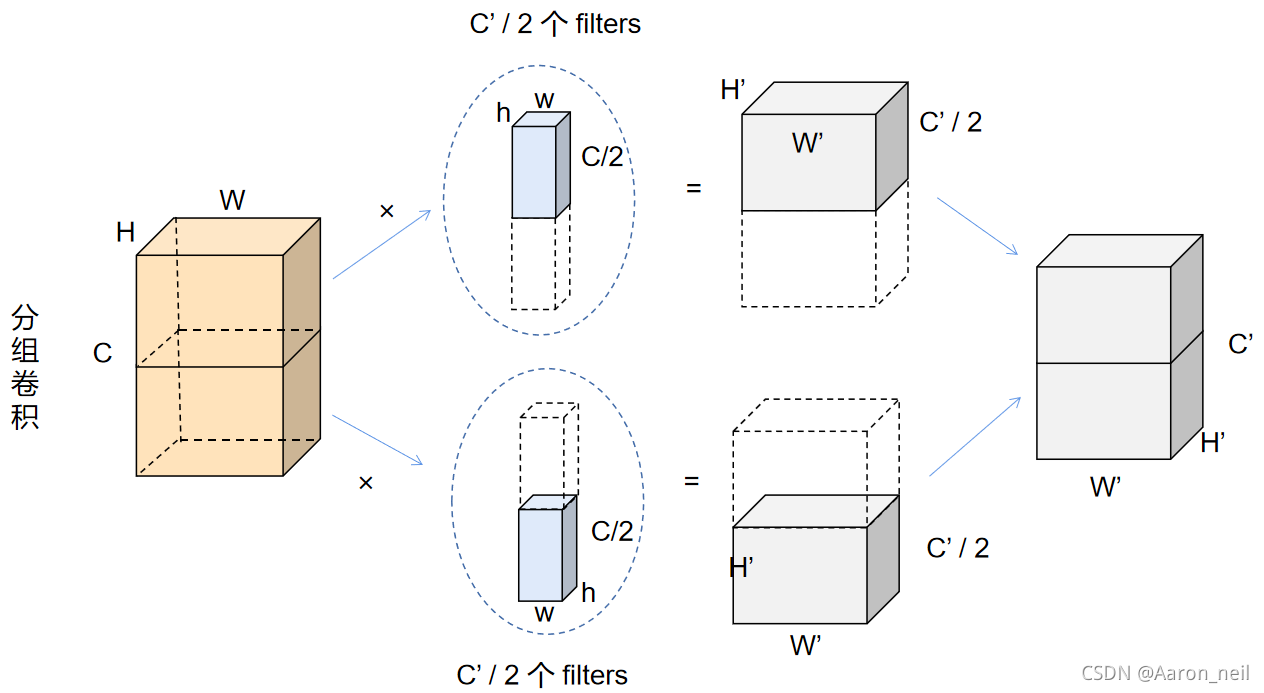
**分组卷积 **的表示如下图(下图表示的是被拆分为 2 个filters组的分组卷积) :
- 首先每个filters组,包含 C'/2个 数量的filter, 每个filter 的通道数为传统2D-卷积filter的一半。
- 每个filters组作用于原来 W × H × C 对应通道数的一半,也就是 W × H × C/2
- 最终每个filters组对应输出输出 C' / 2 个通道的特征。
- 最后将通道堆叠得到了最终的 C'个通道,实现了和上述标准2D 卷积一样的效果。
3. 分组卷积的优势
根据上面的表述,既然能实现和传统卷积一样的效果,那这样做的目的是什么呢?重点来了!
- 我们先计算一下标准2D卷积 和 分组卷积的 参数量:
标准2D卷积:w × h × C × C'
分组卷积:w × h × C/2 × C'/2 × 2
好!看出来差别了吧!参数量减少到原来的1/2!当Group为4的时候,参数量减少到原来的1/4,这个我觉得是最主要的优势。
- 但是虽然得到了一样size的feature,参数量也降低了。那对于模型来说分组卷积的效果好不好呢?这篇文章给了一个非常满意的答复 https://blog.yani.ai/filter-group-tutorial/ 。
总结来说:在某些情况下,分组卷积能带来的模型效果确实要优于标准的2D 卷积,是因为组卷积的方式能够增加相邻层filter之间的对角相关性,而且能够减少训练参数,不容易过拟合,这类似于正则的效果。
4. 代码
代码的话很简单,就是nn.Conv2d里面的一个参数:group,如下图所示:
import torch
import torch.nn as nn
if __name__ == '__main__':
a = torch.randn([12, 64, 30, 100])
conv2d = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1, stride=1)
conv2d_gruop = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1, stride=1, groups=2)
b_2d = conv2d(a)
b_group = conv2d_gruop(a)
print(b_2d.shape) # torch.Size([12, 128, 30, 100])
print(b_group.shape) # torch.Size([12, 128, 30, 100])
本文转载自: https://blog.csdn.net/Aaron_neil/article/details/121097816
版权归原作者 Aaron_neil 所有, 如有侵权,请联系我们删除。
版权归原作者 Aaron_neil 所有, 如有侵权,请联系我们删除。