
第1关:利用python进行语音输入
代码文件
任务描述
本关任务:编写一个能录制音频并读取音频的小程序。
相关知识
为了完成本关任务,你需要掌握:
1.构建一个ASR系统;
2.Python实现音频录制。
构建ASR系统
一个完备的 ASR 系统是要实现纯语音对话聊天,不要文字输入交流。ASR的实现流程如图1所示,大致分4个步骤:
1.我们说一句话,通过录音保存为语音文件;
2.调用百度API实现语音转文本;
3.调用图灵机器人API将文本输入得到图灵机器人的回复;
4.将回复的文本转成语音输出。
python实现语音录制
我们可通过wave包以及pyaudio实现录音。
from pyaudio import PyAudio,paInt16
import wave
channels = 1 ###声道数
framerate = 16000 ###采样率
num_samples = 2000 ###采样点
sampwidth = 2 ###采样宽度
def my_record(rate = 16000):
pa = PyAudio()
stream = pa.open(format=paInt16, channels=channels, rate = framerate, input = True, frames_per_buffer = num_samples)
my_buf = []
t = time.time()
print("Recording...")
####设置录音时间为5s
while time.time() < t + 5:
string_audio_data = stream.read(num_samples)
my_buf.append(string_audio_data)
print("done")
####存储录音
save_file("./myvoice.wav", my_buf)
stream.close()
def save_file(filepath, data):
wf = wave.open(filepath, 'wb')
#### 设置声道数
wf.setnchannels(channels)
#### 设置采样宽度
wf.setsampwidth(sampwidth)
#### 设置采样频率
wf.setframerate(framerate)
#### 将数据以二进制方式写入文件
wf.writeframes(b''.join(data))
wf.close()
函数说明
参数 说明
channel 通道数
format 采样大小以及格式
input 是否为输出流
rate 采样频率
frames_per_buffer 每个buffer的帧数
PA_manager PAAudio的实例
读取录音
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
采用二进制的方式读取文件,并返回。
编程要求
根据提示,在右侧编辑器Begin−End区间补充代码,读取刚刚录制的音频信息。
测试说明
平台会对你编写的代码进行测试:
测试输入:;
预期输出:
b'RIFF$q\x02\x00WAVEfmt \x10\x00\x00\x00'
开始你的任务吧,祝你成功!
题目描述
import time, wave
from pyaudio import PyAudio,paInt16
channels = 1
framerate = 16000
num_samples = 2000
sampwidth = 2
录制音频
def my_record(rate = 16000):
pa = PyAudio()
stream = pa.open(format=paInt16, channels=channels, rate = framerate, input = True,
frames_per_buffer = num_samples)
my_buf = []
t = time.time()
print("Recording...")
while time.time() < t + 5:
string_audio_data = stream.read(num_samples)
my_buf.append(string_audio_data)
print("done")
save_file("./myvoice.wav", my_buf)
stream.close()
保存音频文件
def save_file(filepath, data):
wf = wave.open(filepath, 'wb')
wf.setnchannels(channels)
wf.setsampwidth(sampwidth)
wf.setframerate(framerate)
wf.writeframes(b''.join(data))
wf.close()
读取文件
def get_file_content(filePath):
########## Begin ##########
with open(filePath, 'rb') as fp:
return fp.read()
########## End ##########
if name == "main":
录制音频
my_record()
读取音频
print(get_file_content("/data/workspace/myshixun/src/step1/myvoice.wav")[:20])
第2关:调用百度API实现语音识别
代码文件
from aip import AipSpeech
"""baidu APPID AK SK """
APP_ID = '李彦宏'
API_KEY = '哈哈哈'
SECRET_KEY = '哈哈哈'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 读取文件
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
def invoke_asr():
########## Begin ##########
# 调用API
result = client.asr(get_file_content('/data/workspace/myshixun/src/step2/myvoice.wav'), 'wav', 16000, {'dev_pid': 1737,})
if result['err_no'] == 0:
# 输出识别结果
result_text = result['result'][0]
print('您好我是小明,是一段测试,')
else:
# 输出错误信息
print("Error: ", result['err_msg'])
########## End ##########
if __name__ == "__main__":
invoke_asr()
题目描述
任务描述
本关任务:编写一个能调用百度API实现语音识别的小程序。
相关知识
为了完成本关任务,你需要掌握: 1.如何接入百度AI平台; 2.如何调用百度API实现语音识别。
接入百度AI平台
如何接入百度API
访问百度智能云-登录 登录百度智能云。
1.成为开发者 三步完成账号的基本注册与认证: STEP1:点击百度AI开放平台导航右侧的控制台,选择需要使用的AI服务项。若为未登录状态,将跳转至登录界面,请您使用百度账号登录。如还未持有百度账户,可以点击此处注册百度账户。 STEP2:首次使用,登录后将会进入开发者认证页面,请填写相关信息完成开发者认证。注:(如您之前已经是百度云用户或百度开发者中心用户,此步可略过。) STEP3:通过控制台左侧导航,选择产品服务-人工智能,进入具体AI服务项的控制面板(如文字识别、人脸识别),进行相关业务操作。
2.创建应用 账号登录成功,您需要创建应用才可正式调用AI能力。应用是您调用API服务的基本操作单元,您可以基于应用创建成功后获取的
API Key
及
Secret Key
,进行接口调用操作,及相关配置。 以人脸识别为例,您可按照下图所示的操作流程,完成创建操作。

填写相关信息
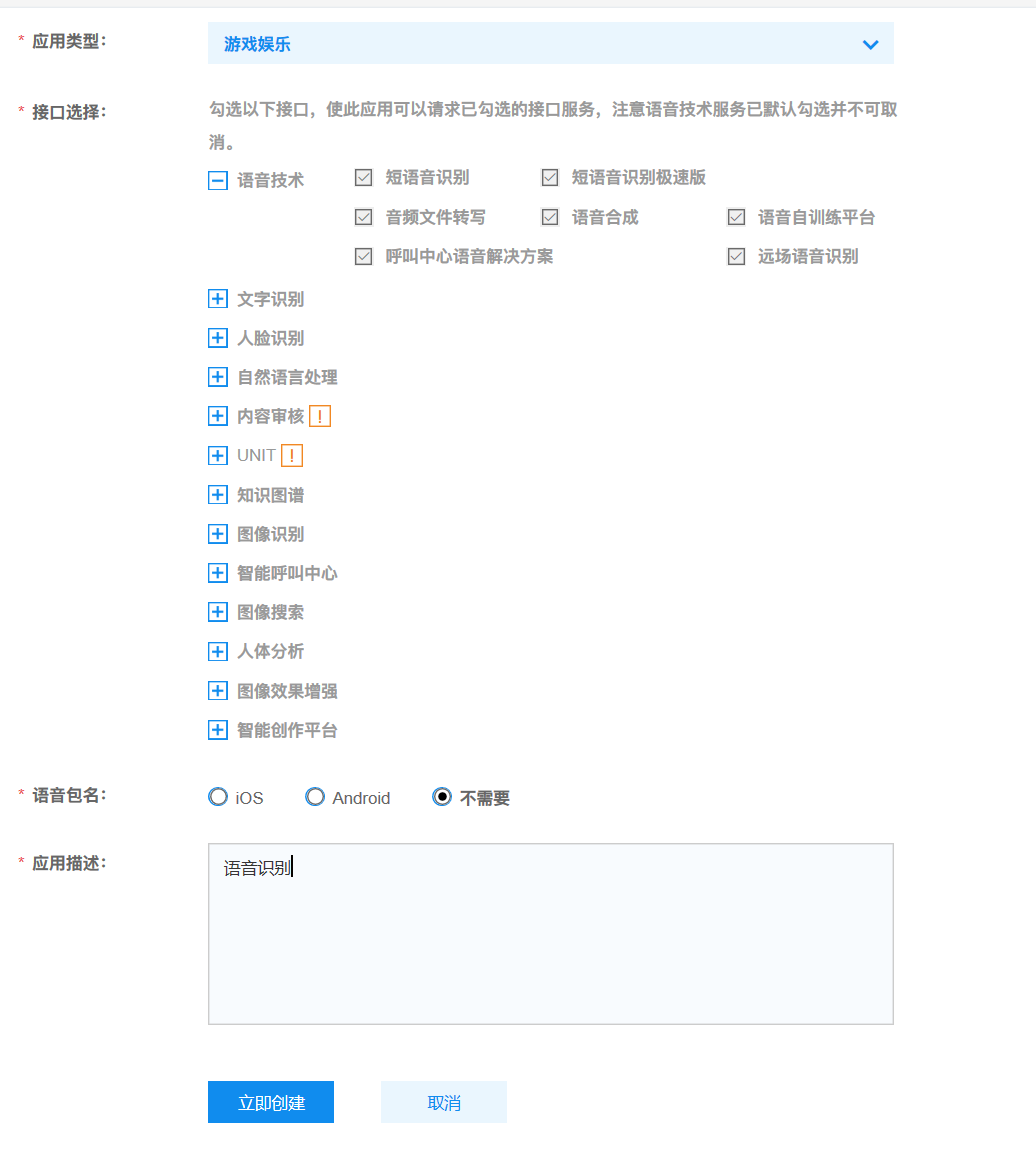
点击左侧的应用列表即可获得对应的
AppId
、
API Key
以及
Secret Key
等信息。
如何调用百度API
"""baidu APPID AK SK """APP_ID = '19379091'API_KEY = 'YkPxDouFfc63GaPXZTTvAEWk'SECRET_KEY = 'TLSftTDguRRUfB80McBiIiugGIYYAq7z'### 创建客户端client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)### 调用APIresult = client.asr(get_file_content('/data/workspace/myshixun/src/step2/myvoice.wav'), 'wav', 16000, {'dev_pid': 1537,})result_text = result["result"][0]# 读取音频文件def get_file_content(filePath):with open(filePath, 'rb') as fp:return fp.read()
其中调用参数说明如下:
参数类型描述是否必须speechBuffer建立包含语音内容的Buffer对象, 语音文件的格式,pcm 或者 wav 或者 amr。不区分大小写是formatString语音文件的格式,pcm 或者 wav 或者 amr。不区分大小写。推荐pcm文件是rateint采样率,16000,固定值是cuidString用户唯一标识,用来区分用户,填写机器 MAC 地址或 IMEI 码,长度为60以内否dev_pidInt不填写lan参数生效,都不填写,默认1537(普通话 输入法模型),dev_pid参数见本节开头的表格否lan(已废弃)String历史兼容参数,请使用dev_pid。如果dev_pid填写,该参数会被覆盖。语种选择,输入法模型,默认中文(zh)。 中文=zh、粤语=ct、英文=en,不区分大小写。否
dev_pid参数列表
dev_pid语言模型是否有标点备注1537普通话输入法模型有标点支持自定义词库1737英语无标点不支持自定义词库1637粤语有标点不支持自定义词库1837四川话有标点不支持自定义词库1936普通话远场远场模型有标点不支持
语音识别返回数据参数详情
参数类型是否一定输出描述err_noint是错误码err_msgint是错误码描述snint是语音数据唯一标识,系统内部产生,用于 debugresultint是识别结果数组,提供1-5 个候选结果,string 类型为识别的字符串, utf-8 编码
返回样例
// 成功返回{"err_no": 0,"err_msg": "success.","corpus_no": "15984125203285346378","sn": "481D633F-73BA-726F-49EF-8659ACCC2F3D","result": ["北京天气"]}// 失败返回{"err_no": 2000,"err_msg": "data empty.","sn": null}
编程要求
根据提示,在右侧编辑器Begin−End区间补充代码,将
wave
文件转化为文字。
测试说明
平台会对你编写的代码进行测试:
测试输入: 预期输出:
您好我是小明,是一段测试,
开始你的任务吧,祝你成功!
第3关:图灵对话实现
代码文件
import requests
import json
# Turing API key and URL
turing_api_key = '1202de25edf0495eab665b684d3a95e8'
api_url = 'http://openapi.tuling123.com/openapi/api/v2'
def turing(text_words):
# Request structure for Turing API
req = {
"reqType": 0,
"perception": {
"inputText": {
"text": "附近的酒店"
},
"inputImage": {
"url": "imageUrl"
},
"selfInfo": {
"location": {
"city": "北京",
"province": "北京",
"street": "信息路"
}
}
},
"userInfo": {
"apiKey": turing_api_key,
"userId": "keda"
}
}
# Updating the text to be sent to Turing API
req['perception']["inputText"]["text"] = text_words
########## Begin ##########
# Sending the request to the Turing API
response = requests.request("post", api_url, json=req)
# Parsing the response
response_dict = json.loads(response.text)
result = response_dict["results"][0]["values"]["text"]
print("Robot said:", result)
########## End ##########
return result
if __name__ == "__main__":
robot_result = turing("你是谁?")
print("调用成功")
题目描述
任务描述
本关任务:编写一个能实现图灵对话的小程序。
相关知识
为了完成本关任务,你需要掌握: 1.如何接入图灵对话; 2.如何调用图灵对话API。
接入图灵对话
调用图灵API
def turing(text_words):req = {"reqType":0,"perception": {"inputText": {"text": "附近的酒店"},"inputImage": {"url": "imageUrl"},"selfInfo": {"location": {"city": "北京","province": "北京","street": "信息路"}}},"userInfo": {"apiKey": turing_api_key,"userId": "keda"}}req['perception']["inputText"]["text"] = text_wordsresponse = requests.request("post", api_url, json=req)response_dict = json.loads(response.text)result = response_dict["results"][0]["values"]["text"]print("Robot said", result)return result
参数说明
参数说明reqType输入类型:0-文本(默认)、1-图片、2-音频perception输入信息userInfo用户参数
返回参数
参数inputText文本信息inputImage图片信息inputMedia音频信息selfInfo客户端属性
编程要求
根据提示,在右侧编辑器Begin−End区间补充代码,调用图灵API实现对话。
测试说明
平台会对你编写的代码进行测试:
测试输入:; 预期输出:
Robot said 图灵机器人呀调用成功
开始你的任务吧,祝你成功!
第4关:文字转化语音
代码文件
import pyttsx3
def speech_start_way1(text="Hello, I am using pyttsx3 for speech synthesis."):
# 初始化pyttsx3引擎
engine = pyttsx3.init()
# 获取当前语速,并稍微降低它
rate = engine.getProperty('rate')
engine.setProperty('rate', rate - 50)
# 传入要朗读的文本
engine.say(text)
# 运行语音引擎
engine.runAndWait()
if __name__ == "__main__":
speech_start_way1()
题目描述
任务描述
本关任务:编写一个能实现文字语音转换的小程序。
相关知识
为了完成本关任务,你需要掌握: 1.利用
pyttsx3
调用接口实现语音文字转化; 2.如何利用
win32com.client
实现语音文字转化。
利用pyttsx3调用接口实现语音文字转化
import pyttsx3engine = pyttsx3.init()rate = engine.getProperty('rate')engine.setProperty('rate', rate - 50)engine.say(robot_result)engine.runAndWait()
利用win32com.client实现语音文字转化
import win32com.clientspeaker = win32com.client.Dispatch("SAPI.SpVoice")speaker.Speak("我是小明")
编程要求
根据提示,在右侧编辑器 Begin−End 补充代码,计算。
测试说明
平台会对你编写的代码进行测试:
测试输入:; 预期输出:
sh: 1: aplay: not found
开始你的任务吧,祝你成功!
第5关:ASR系统集成
代码文件
from pyaudio import PyAudio,paInt16
from aip import AipSpeech
import time, wave
import requests,json
import pyttsx3
"""baidu APPID AK SK """
APP_ID = '19379091'
API_KEY = 'YkPxDouFfc63GaPXZTTvAEWk'
SECRET_KEY = 'TLSftTDguRRUfB80McBiIiugGIYYAq7z'
"""turing """
turing_api_key = '1202de25edf0495eab665b684d3a95e8'
api_url = 'http://openapi.tuling123.com/openapi/api/v2'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
channels = 1
framerate = 16000
num_samples = 2000
sampwidth = 2
def my_record(rate = 16000):
pa = PyAudio()
stream = pa.open(format=paInt16, channels=channels, rate = framerate, input = True,
frames_per_buffer = num_samples)
my_buf = []
t = time.time()
print("Recording...")
while time.time() < t + 5:
string_audio_data = stream.read(num_samples)
my_buf.append(string_audio_data)
print("done")
save_file("./myvoice.wav", my_buf)
stream.close()
def save_file(filepath, data):
wf = wave.open(filepath, 'wb')
wf.setnchannels(channels)
wf.setsampwidth(sampwidth)
wf.setframerate(framerate)
wf.writeframes(b''.join(data))
wf.close()
# 读取文件
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
def turing(text_words):
req = {
"reqType":0,
"perception": {
"inputText": {
"text": "附近的酒店"
},
"inputImage": {
"url": "imageUrl"
},
"selfInfo": {
"location": {
"city": "北京",
"province": "北京",
"street": "信息路"
}
}
},
"userInfo": {
"apiKey": turing_api_key,
"userId": "keda"
}
}
req['perception']["inputText"]["text"] = text_words
response = requests.request("post", api_url, json=req)
response_dict = json.loads(response.text)
result = response_dict["results"][0]["values"]["text"]
print("Robot said", result)
return result
if __name__ == "__main__":
# my_record()
# 识别本地文件
########## Begin ##########
print("finished")
########## End ##########
题目描述
任务描述
本关任务:编写一个ASR系统小程序。
相关知识
为了完成本关任务,你需要掌握:
- ASR系统流程;
- ASR代码实现步骤。
ASR系统流程
一个完备的ASR系统是要实现纯语音对话聊天,不要文字输入交流。ASR的实现流程如图1所示,大致分4个步骤: 1.我们说一句话,通过录音保存为语音文件; 2.调用百度API实现语音转文本; 3.调用图灵机器人API将文本输入得到图灵机器人的回复; 4.将回复的文本转成语音输出。
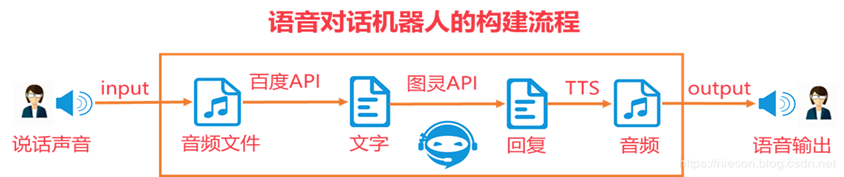
ASR代码实现步骤
from pyaudio import PyAudio,paInt16from aip import AipSpeechimport time, waveimport requests,jsonimport pyttsx3import win32com.client"""baidu APPID AK SK """APP_ID = '19379091'API_KEY = 'YkPxDouFfc63GaPXZTTvAEWk'SECRET_KEY = 'TLSftTDguRRUfB80McBiIiugGIYYAq7z'"""turing """turing_api_key = '1202de25edf0495eab665b684d3a95e8'api_url = 'http://openapi.tuling123.com/openapi/api/v2'client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)channels = 1framerate = 16000num_samples = 2000sampwidth = 2def my_record(rate = 16000):pa = PyAudio()stream = pa.open(format=paInt16, channels=channels, rate = framerate, input = True,frames_per_buffer = num_samples)my_buf = []t = time.time()print("Recording...")while time.time() < t + 5:string_audio_data = stream.read(num_samples)my_buf.append(string_audio_data)print("done")save_file("./myvoice.wav", my_buf)stream.close()def save_file(filepath, data):wf = wave.open(filepath, 'wb')wf.setnchannels(channels)wf.setsampwidth(sampwidth)wf.setframerate(framerate)wf.writeframes(b''.join(data))wf.close()# 读取文件def get_file_content(filePath):with open(filePath, 'rb') as fp:return fp.read()def turing(text_words):req = {"reqType":0,"perception": {"inputText": {"text": "附近的酒店"},"inputImage": {"url": "imageUrl"},"selfInfo": {"location": {"city": "北京","province": "北京","street": "信息路"}}},"userInfo": {"apiKey": turing_api_key,"userId": "keda"}}req['perception']["inputText"]["text"] = text_wordsresponse = requests.request("post", api_url, json=req)response_dict = json.loads(response.text)result = response_dict["results"][0]["values"]["text"]print("Robot said", result)return resultif __name__ == "__main__":# 识别语音并存盘my_record()# 识别本地文件,转化文字result = client.asr(get_file_content('./myvoice.wav'), 'wav', 16000, {'dev_pid': 1837,})result_text = result["result"][0]print(result_text)# 图灵对话robot_result = turing(result_text)# 文字转语音engine = pyttsx3.init()rate = engine.getProperty('rate')engine.setProperty('rate', rate - 50)engine.say(robot_result)engine.runAndWait()
编程要求
根据提示,在右侧编辑器 Begin−End 区间补充代码,编写一个 ASR 系统小程序。
测试说明
平台会对你编写的代码进行测试:
测试输入:; 预期输出:
finished
开始你的任务吧,祝你成功!
版权归原作者 gxmzuai 所有, 如有侵权,请联系我们删除。