

文章目录
每篇前言
- 🏆🏆作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6
- 🔥🔥本文已收录于Python全栈系列专栏:《100天精通Python从入门到就业》
- 📝📝此专栏文章是专门针对Python零基础小白所准备的一套完整教学,从0到100的不断进阶深入的学习,各知识点环环相扣
- 🎉🎉订阅专栏后续可以阅读Python从入门到就业100篇文章;还可私聊进两百人Python全栈交流群(手把手教学,问题解答);进群可领取80GPython全栈教程视频 + 300本计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!
一、初始pandas
1. 什么是pandas?
Pandas 是一个开源的第三方 Python 库,从 Numpy 和 Matplotlib 的基础上构建而来,享有数据分析“三剑客之一”的盛名(NumPy、Matplotlib、Pandas)。Pandas 已经成为 Python 数据分析的必备高级工具,它的目标是成为强大、灵活、可以支持任何编程语言的数据分析工具。提供了高级数据结构和数据操作工具,它是使Python成为强大而高效的数据分析环境的重要因素之一。
- 一个强大的分析和操作大型结构化数据集所需的工具集
- 基础是NumPy,提供了高性能矩阵的运算
- 提供了大量能够快速便捷地处理数据的函数和方法
- 应用于数据挖掘,数据分析
- 提供数据清洗功能
2. 为什么要学习pandas?
Pandas是数据分析三剑客之一,是Python的核心数据分析库!
Pandas能够处理的数据类型:
- 与SQL或Excel表类似的数据
- 有序或无序的时间序列数据
- 带行列标签的矩阵数据
- 任意其他形式的观测
3. pandas的优势
- 处理浮点与非浮点数据里的缺失数据,表示为NaN大小可变
- 自动、显示数据对齐
- 强大、灵活的分组统计功能
- 成熟的导入导出工具
- …
4. 下载安装pandas
**1. window电脑点击
win键+ R
,输入:
cmd
**
**2. 安装
pandas
,输入对应的pip命令**:
pip install pandas
,我已经安装过了出现版本就安装成功了

3. 导包
import pandas as pd
注意:Python中看到
pd
那一定是对pandas导包的缩写!!!
二、Pandas的数据类型
Pandas有两个最主要也是最重要的数据结构: Series 和 DataFrame
- Series:一维,带标签数组
- DataFrame:二维,Series容器
import pandas as pd
1. Series
Series是一种类似于一维数组的 对象,由一组数据(各种NumPy数据类型)以及一组与之对应的索引(数据标签)组成。
- 类似一维数组的对象
- 由数据和索引组成 - 索引(index)在左,数据(values)在右- 索引是自动创建的

1)通过list构建Series:
ser_obj = pd.Series(range(10))
>>>import pandas as pd
>>># 通过list构建Series>>> ser_obj = pd.Series(range(10,20))>>>print(ser_obj)010111212313414515616717818919
dtype: int64
>>>print(type(ser_obj))<class'pandas.core.series.Series'>
2)获取数据和索引:
ser_obj.index和
ser_obj.values
>>># 获取数据>>>print(ser_obj.values)[10111213141516171819]>>># 获取索引>>>print(ser_obj.index)
RangeIndex(start=0, stop=10, step=1)
3)通过索引获取数据:
ser_obj[idx]
>>>#通过索引获取数据>>>print(ser_obj[0])10>>>print(ser_obj[8])18
4)索引与数据的对应关系不被运算结果影响
>>># 索引与数据的对应关系不被运算结果影响>>>print(ser_obj *2)020122224326428530632734836938
dtype: int64
>>>print(ser_obj >15)0False1False2False3False4False5False6True7True8True9True
dtype:bool
5)通过dict构建Series:
ser_obj = pd.Series(python字典)
>>># 通过dict构建Series>>> year_data ={2001:17.8,2002:20.1,2003:16.5}>>> ser_obj2 = pd.Series(year_data)>>>print(ser_obj2.head())200117.8200220.1200316.5
dtype: float64
>>>print(ser_obj2.index)
Int64Index([2001,2002,2003], dtype='int64')
6)name属性
对象名:
ser_obj.name对象索引名:
ser_obj.index.name
>>># name属性>>> ser_obj2.name ='temp'>>> ser_obj2.index.name ='year'>>>print(ser_obj2.head())
year
200117.8200220.1200316.5
Name: temp, dtype: float64
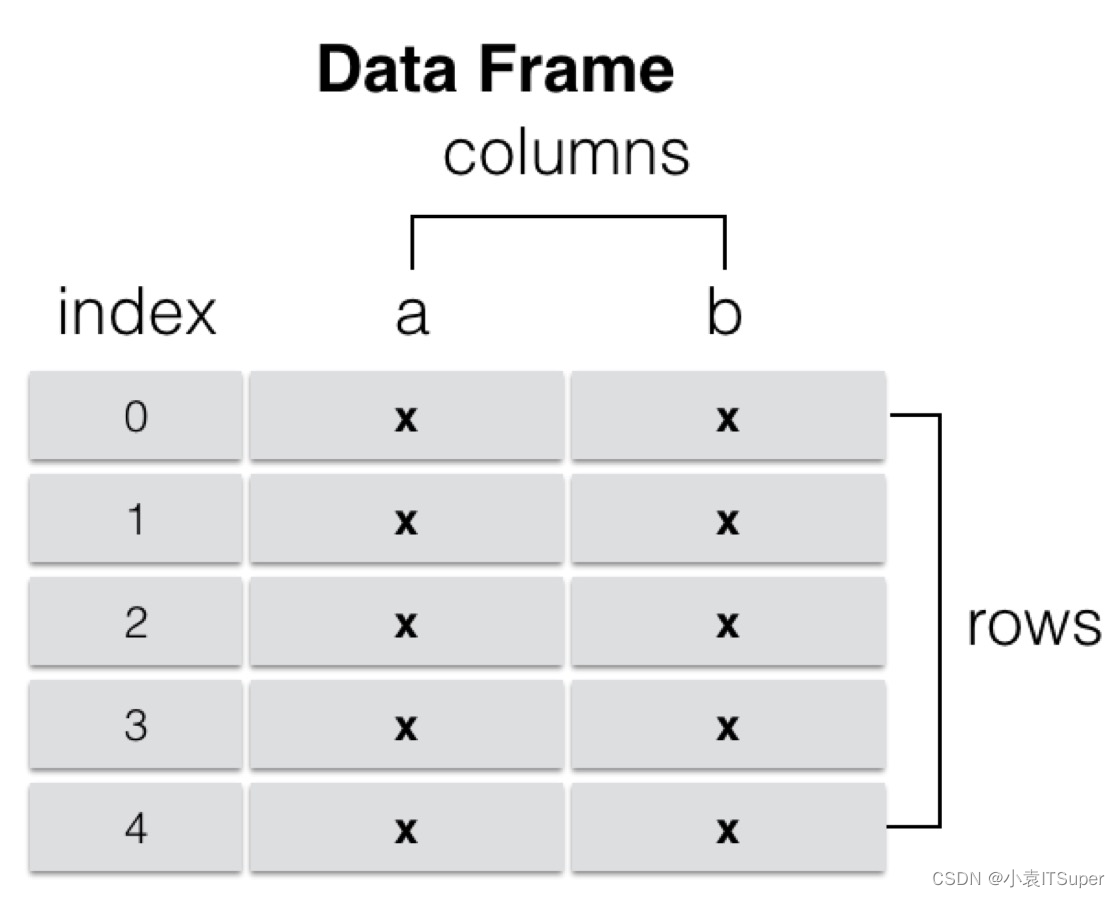
2. DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同类型的值。DataFrame既有行索引也有列索引,它可以被看做是由Series组成的字典(共用同一个索引),数据是以二维结构存放的。
- 类似多维数组/表格数据 (如,excel, R中的data.frame)
- 每列数据可以是不同的类型
- 索引包括列索引和行索引
DataFrame的基础属性:
属性说明
df.shape
行数列数
df.dtypes
列数据类型
df.ndim
数据维度
df.index
行索引
df.columns
列索引
df.values
对象值,二维ndarray数组
DataFrame整体情况查询:
方法说明
df.head(3)
显示头部几行,默认5行
df.tail(3)
显示末尾几行,默认5行
df.info()
相关信息概览:行数,列数,列索引,列非空值个数,列类型,列类型,内存占用
df.describe()
快速综合统计结果:计数,均值,标准差,最大值,四分位数,最小值
1)通过ndarray构建DataFrame:
>>>import pandas as pd
>>>import numpy as np
>>># 通过ndarray构建DataFrame>>> array = np.random.randn(5,4)>>>print(array)[[-0.241629260.406802970.08596954-0.76233872][-0.76604456-0.74271574-0.825542522.35414819][1.664002890.38210026-0.83706262-0.3219765][0.046124240.49754558-1.34472493-0.41849572][0.441907540.52152161-0.992211722.08437141]]>>> df_obj = pd.DataFrame(array)>>>print(df_obj.head())01230-0.2416290.4068030.085970-0.7623391-0.766045-0.742716-0.8255432.35414821.6640030.382100-0.837063-0.32197730.0461240.497546-1.344725-0.41849640.4419080.521522-0.9922122.084371>>>print(type(df_obj))<class'pandas.core.frame.DataFrame'>
 DataFrame对象既有行索引,又有列索引:
DataFrame对象既有行索引,又有列索引:
- 行索引,表明不同行,横向索引,叫index,0轴,axis=0
- 列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
2)通过dict构建DataFrame:
>>># 通过dict构建DataFrame>>> dict_data ={'A':1,...'B': pd.Timestamp('20170426'),...'C': pd.Series(1, index=list(range(4)),dtype='float32'),...'D': np.array([3]*4,dtype='int32'),...'E':["Python","Java","C++","C"],...'F':'ITCast'}# 方式1>>> df_obj2 = pd.DataFrame(dict_data)>>>print(df_obj2)
A B C D E F
012017-04-261.03 Python ITCast
112017-04-261.03 Java ITCast
212017-04-261.03 C++ ITCast
312017-04-261.03 C ITCast
>>>print(type(df_obj2))<class'pandas.core.frame.DataFrame'># 方式2>>> list_data =[{"name":"小白","age":20,"tel":10010},{"name":"小红","tel":10010},{"name":"小黑","age":10}]>>> list_data
[{'name':'小白','age':20,'tel':10010},{'name':'小红','tel':10010},{'name':'小黑','age':10}]>>> df_obj3 = pd.DataFrame(list_data)>>>print(df_obj3)
name age tel
0 小白 20.010010.01 小红 NaN 10010.02 小黑 10.0 NaN
# 可以看出空值用NaN占位了
3)通过Series对象创建DataFrame
>>>import pandas as pd
>>> ser_obj = pd.Series(range(10,20))>>>print(ser_obj)010111212313414515616717818919
dtype: int64
>>> pd = pd.DataFrame(ser_obj)>>> pd
0010111212313414515616717818919
4)通过列索引获取列数据(Series类型):
df_obj[col_idx]或
df_obj.col_idx
>>># 通过列索引获取列数据>>>print(df_obj2['A'])01112131
Name: A, dtype: int64
>>>print(type(df_obj2['A']))<class'pandas.core.series.Series'>>>>print(df_obj2.A)01112131
Name: A, dtype: int64
5)增加列数据:
df_obj[new_col_idx] = data; 类似Python的 dict添加key-value
>>># 增加列>>> df_obj2['G']= df_obj2['D']+4>>>print(df_obj2.head())
A B C D E F G
012017-04-261.03 Python ITCast 7112017-04-261.03 Java ITCast 7212017-04-261.03 C++ ITCast 7312017-04-261.03 C ITCast 7
6)删除列
del(df_obj[col_idx])
>>># 删除列>>>del(df_obj2['G'])>>>print(df_obj2.head())
A B C D E F
012017-04-261.03 Python ITCast
112017-04-261.03 Java ITCast
212017-04-261.03 C++ ITCast
312017-04-261.03 C ITCast
三、书籍推荐
书籍展示:《人工智能技术基础》
【书籍内容简介】
- 本书不但侧重于理论知识的普及,也将技术融合于Python模块进行实验上的操作与演示。本书主要内容包括:人工智能技术概述,人脸识别技术、物体识别技术,视频识别技术、语音识别技术、文本识别技术,区块链技术等。全书综合了各种模块对人工智能技术的实践,将分散的技术点统一起来,并把抽象的原理与适应读者思维的案例相融合,实现知识点的充分理解。 本书适合从事数据科学及AI的读者阅读。
版权归原作者 无 羡ღ 所有, 如有侵权,请联系我们删除。