
GPT-SoVITS是一款创新的声音克隆工具,它在很短的时间内就能克隆出别人的声音,并且所需的素材量极少。与此前的SoVITS相比,GPT-SoVITS只需要1分钟的音源就可以实现高质量的声音克隆,而原先的SoVITS则需要半个小时以上的干声音。

功能亮点:
- 零次TTS: 用户仅需输入一段5秒的语音样本,GPT-SoVITS-WebUI就能立即将其转换为文本,实现即时的语音到文本转换。
- 少次TTS: 通过对模型进行微调,即使是1分钟的训练数据也能显著提升语音的相似度和真实感,这对个性化语音合成非常关键。
- 跨语言支持: GPT-SoVITS-WebUI能够处理与训练数据集不同语言的语音,目前支持英语、日语和中文,大大拓宽了应用范围。
- WebUI集成: 集成了多种AI工具,包括语音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,方便用户创建训练数据集和GPT/SoVITS模型。
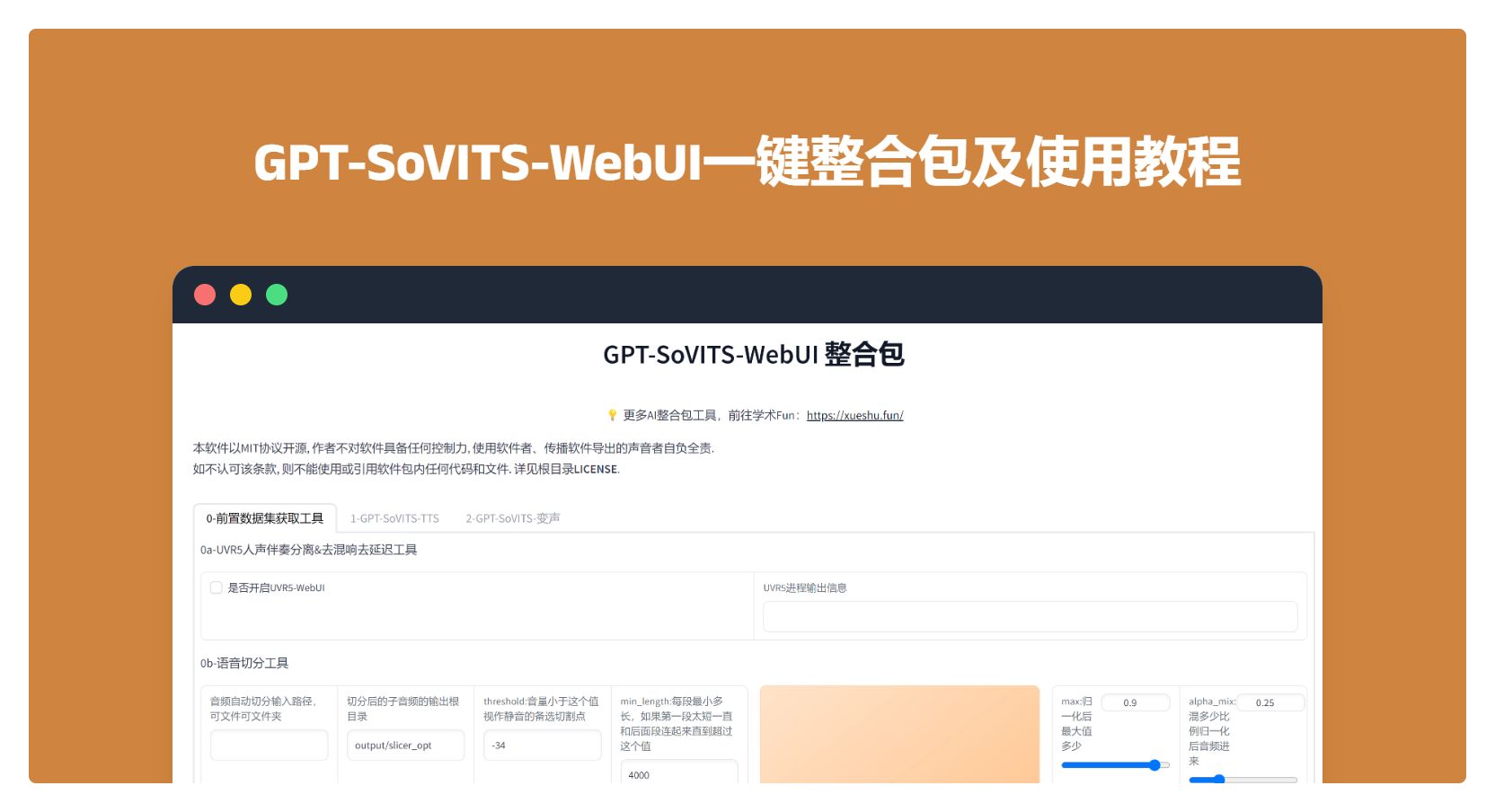
下载安装:
- 下载****一键启动整合包 下载地址: https://www.kjvhh.com/gpt-sovits.html,请在此页面上方链接点击下载!
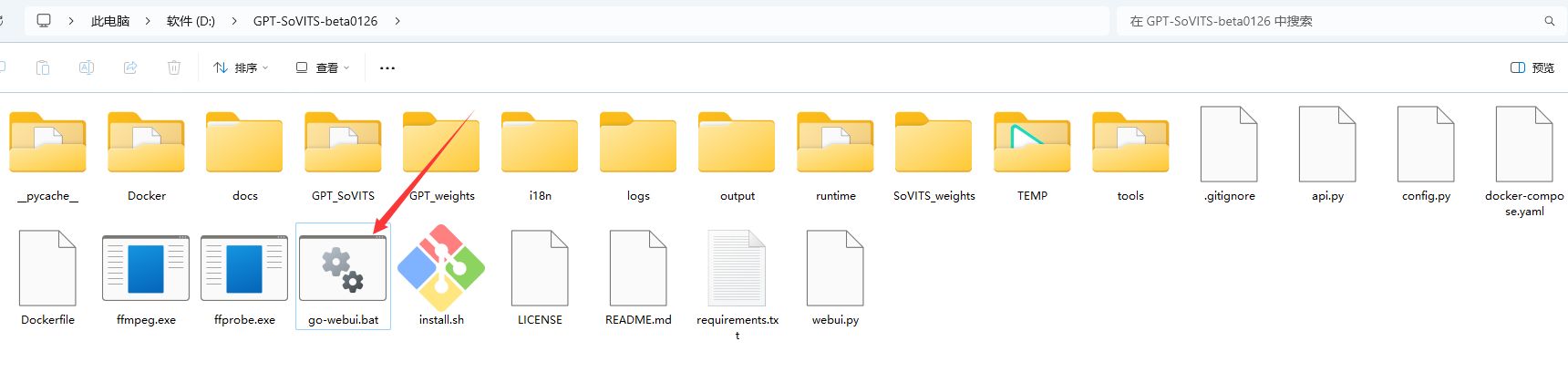
- 解压压缩包 解压后的路径最好不要包含中文。解压完成后,如下图所示,双击go-webui.bat文件运行。
- 启动WebUI 在浏览器中打开相应端口地址,即可在浏览器中使用GPT-SoVITS-WebUI界面。
使用教程
01 前置数据集获取
- 1、人声提取: 选择 "0a-UVR5人声伴奏分离&去混响去延迟工具" 页签。我们需要勾选 "是否开启UVR5-WebUI" 来提取声音,制作干声。
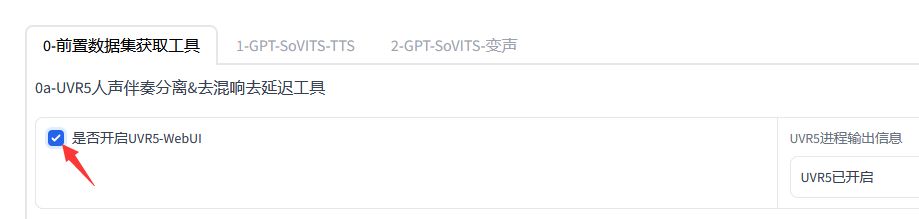
稍等一下,会打开一个新的WebUI界面。
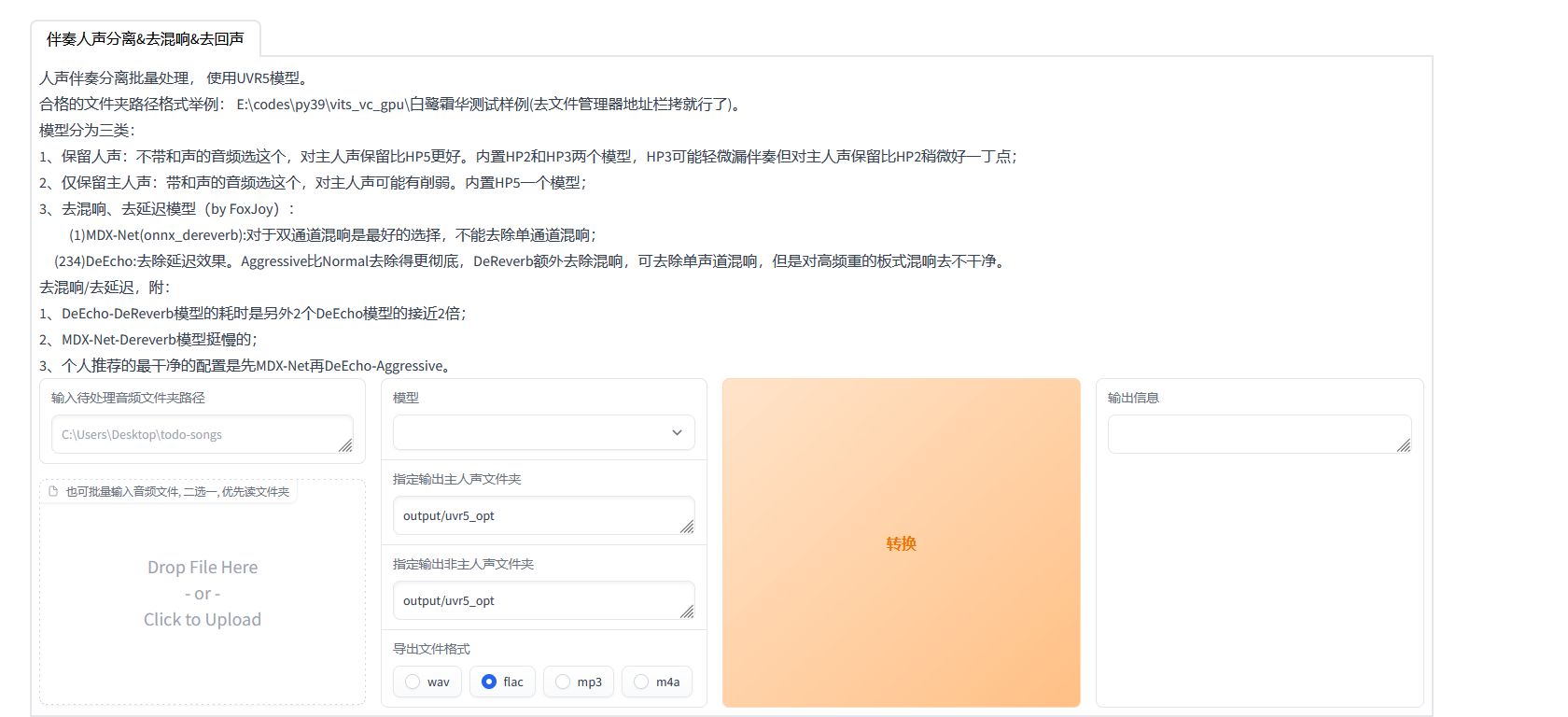
我们将在这个界面内完成提取干声的操作。将准备的音频或者视频文件拖放到左下角的框框内。
选择处理的模型。不带和声的音频选HP2,带和声的音频选HP5,然后点击 "转换"。
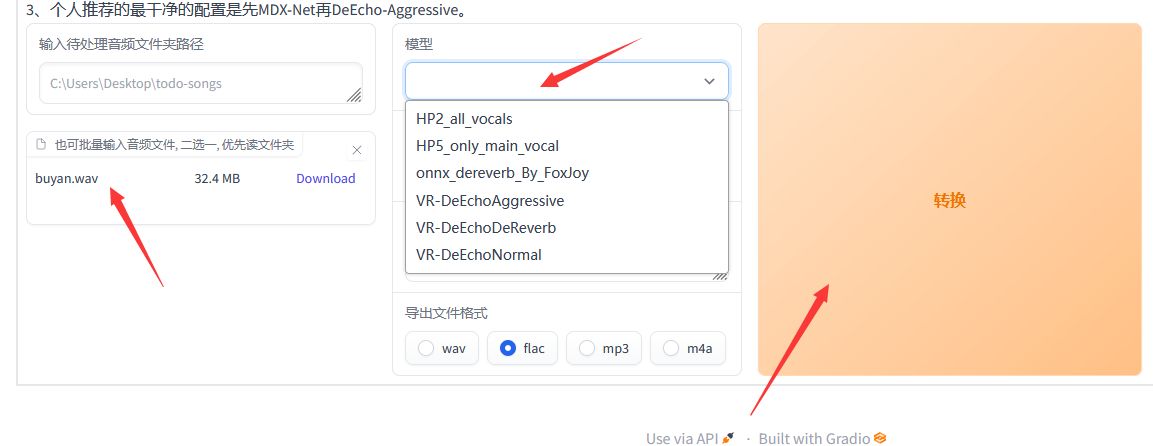
转换成功后,你可以在整合包\output路径下的uvr5输出目录中找到转换结果。
- 2、音频切分: 关闭 "是否开启UVR5-WebUI",以释放显存。
删除刚刚音频分离路径下的背景声音,并将路径复制到下面的输入框里。
选择 "0b-语音切分工具" 页签。点击 "开始语音切割"。
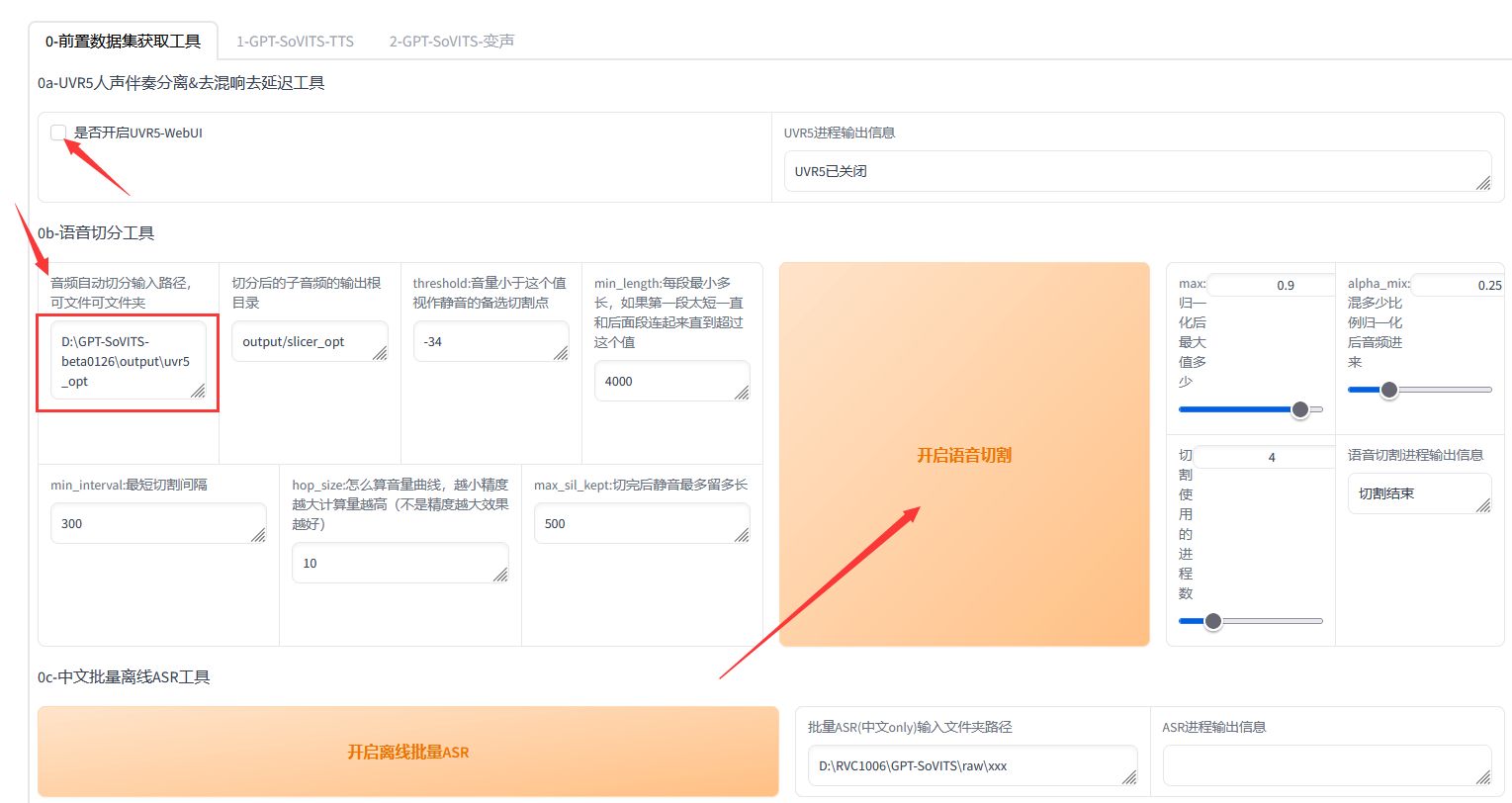
完成后,你可以在\output\slicer_opt路径下看到切割后的所有音频文件。
- 3、语音文本识别: 选择 "0c-中文批量离线ASR工具" 页签,将刚刚的分类目录路径复制到下面ASR中。
点击 "开启离线批量ASR"。
完成后,识别结果会保存在\output\asr_opt目录下。
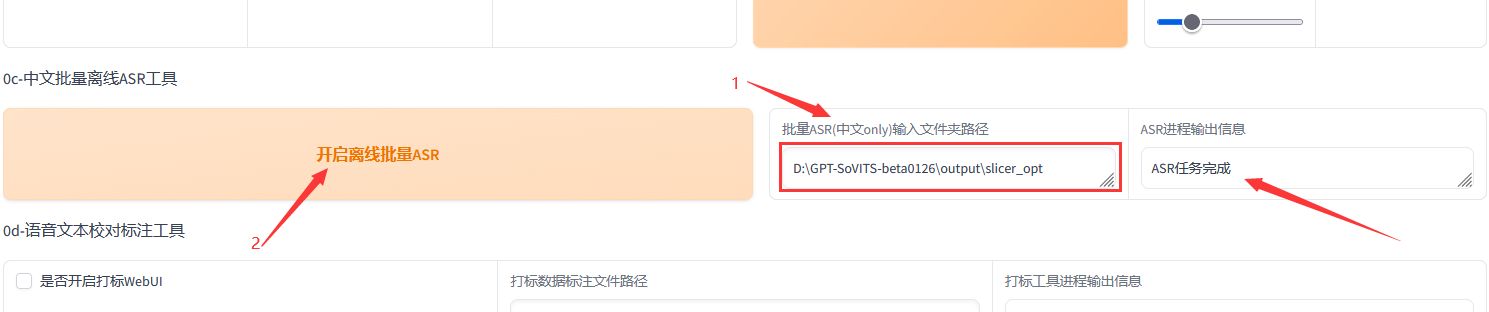
- 4、开启标注工具: 选择 "0d-语音文本校对标注工具" 页签,把上面ASR生成的list文件的完整路径填写到下面的标注文件路径中。
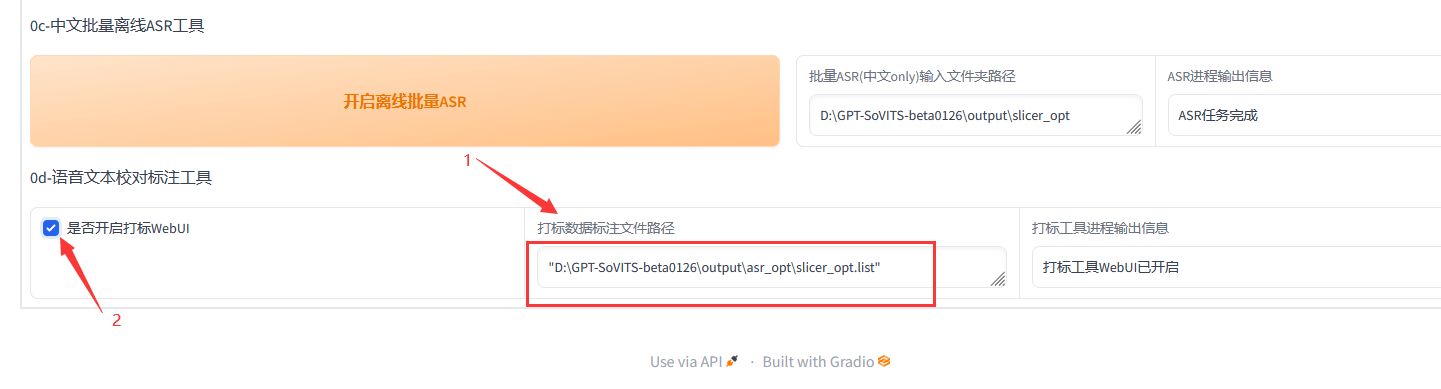
点击 "是否开启打标WebUI",系统会提示打标工具已开启。稍等一会儿,会弹出新的WebUI窗口,这就是标注工具的WebUI界面。
在这个界面里面进行文本校对,修改标点符号与停顿一致。如果听不清,有杂音,语速乱的,建议删除。或者回去进行音源调整。
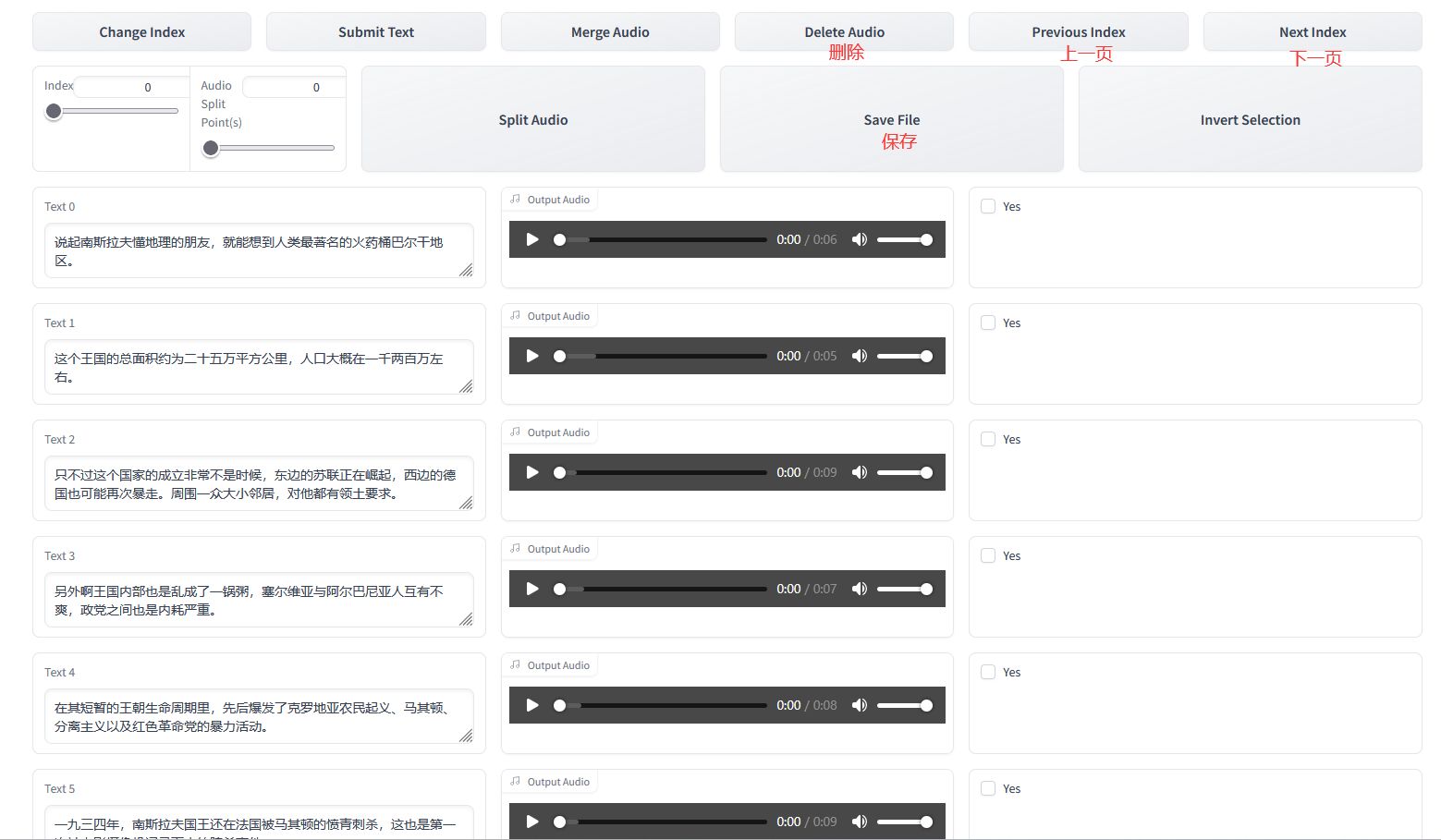
删除方式是先勾选,然后点击 "删除"。一定要点 "上一页" 和 "下一页" 查看全部的,以免漏下。校对无误后点击保存,提交文本。
数据会保存到slicer_opt.list中。至此,我们已经完成了前置获取数据集的工作。
02 训练模型
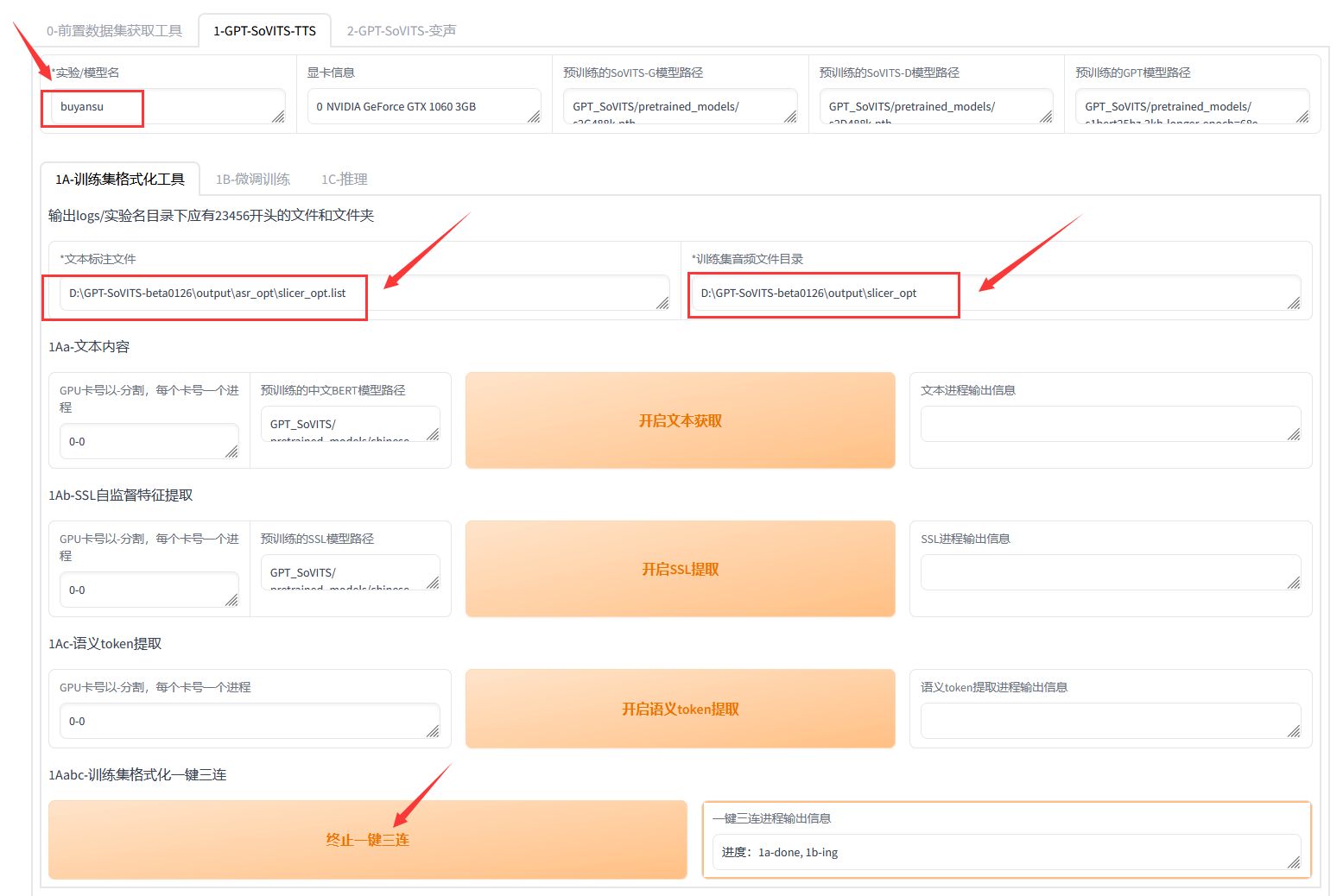
- 1、训练集格式化: 点击 "1A-训练集格式化工具",进入训练集格式化界面。填写训练的模型名称,填写上面数据集的list目录和音频切分的目录。
点击下面按钮 "开启一键三连"。
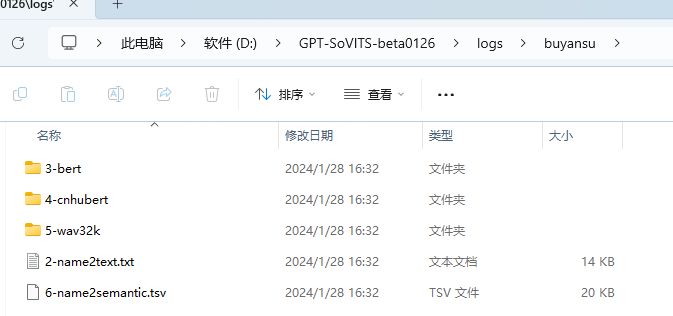
一键三连顺利结束后,我们会在\logs\buyansu(你设置的模型名)文件下看见23456。这里就得到了后面需要训练的特征缓存文件。
- 2、微调训练: 点击 "1B-微调训练" 页签,进入子模型训练界面。
我们需要开启两个微调子模型的训练,参数默认即可。推荐使用20系以上的N卡,8G以上的显存。如果显存不够,可以降低batch_size的数值。
然后依次点击 "开始SoVITS训练" 和 "开始GPT训练"。VITS训练需要一些时间,请耐心等待。
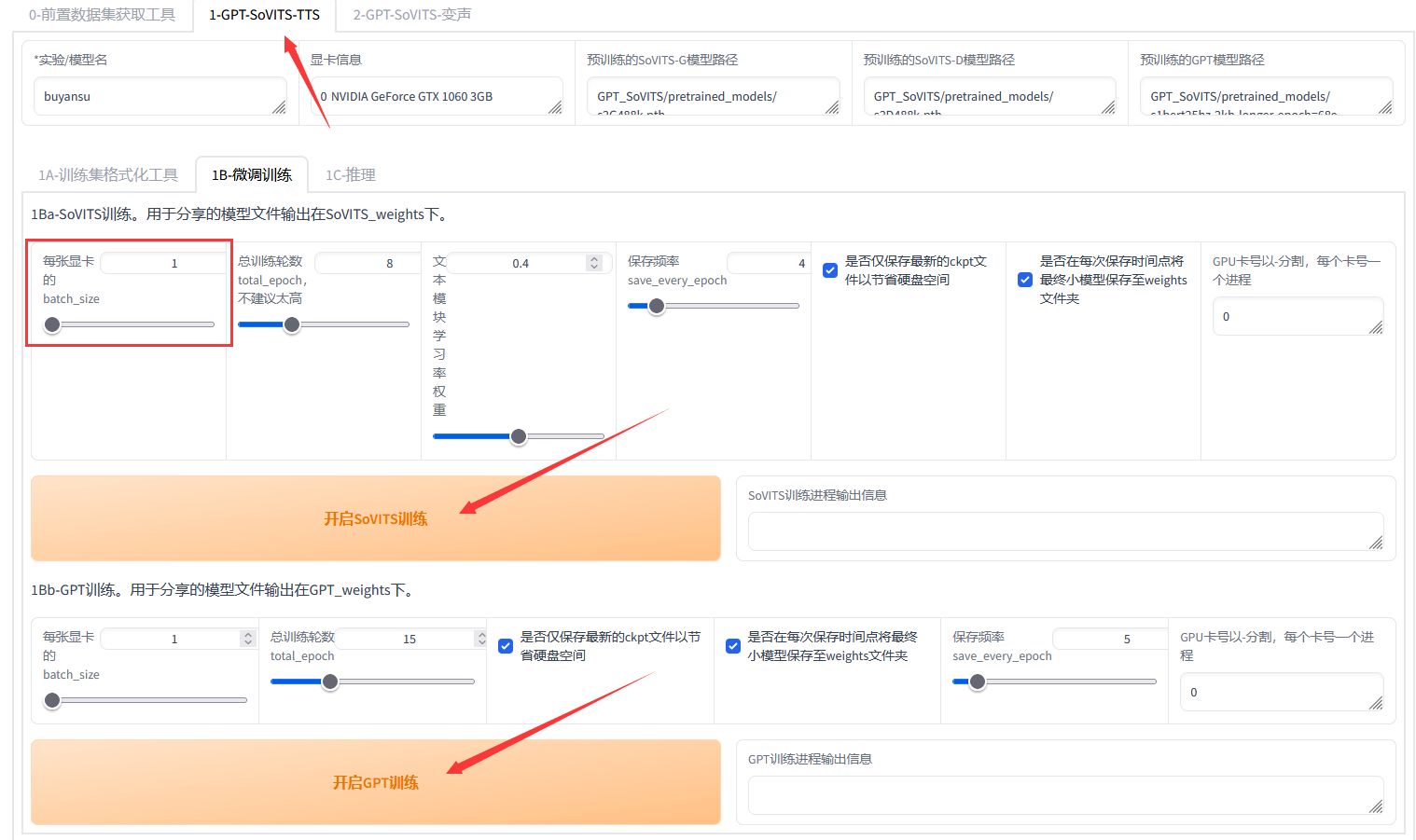
训练完成后,微调模型就已经准备好了。
03 声音合成
- 推理: 点击 "1C-推理" 页签,进入推理界面。首先我们点击 "刷新模型路径按钮",将刚刚训练的子模型拉取进来。
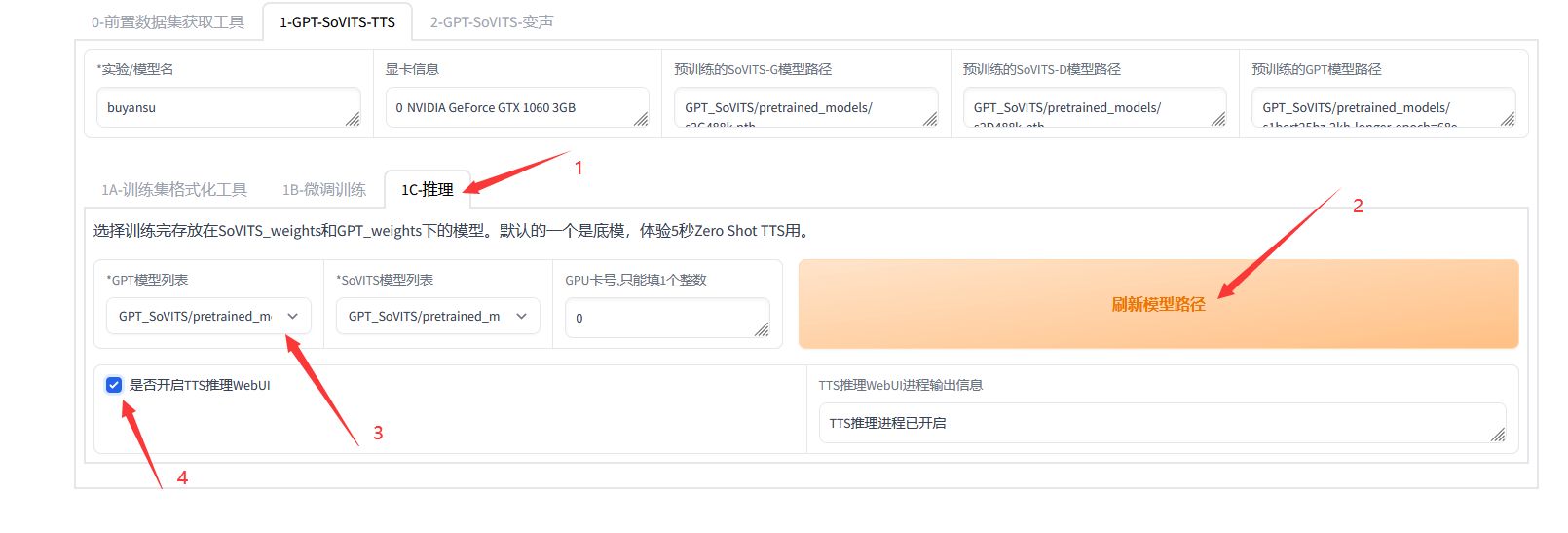
然后点击 "是否开启TTS推理WebUI" 按钮,即可开启推理。稍作等待,会弹出推理WebUI界面。
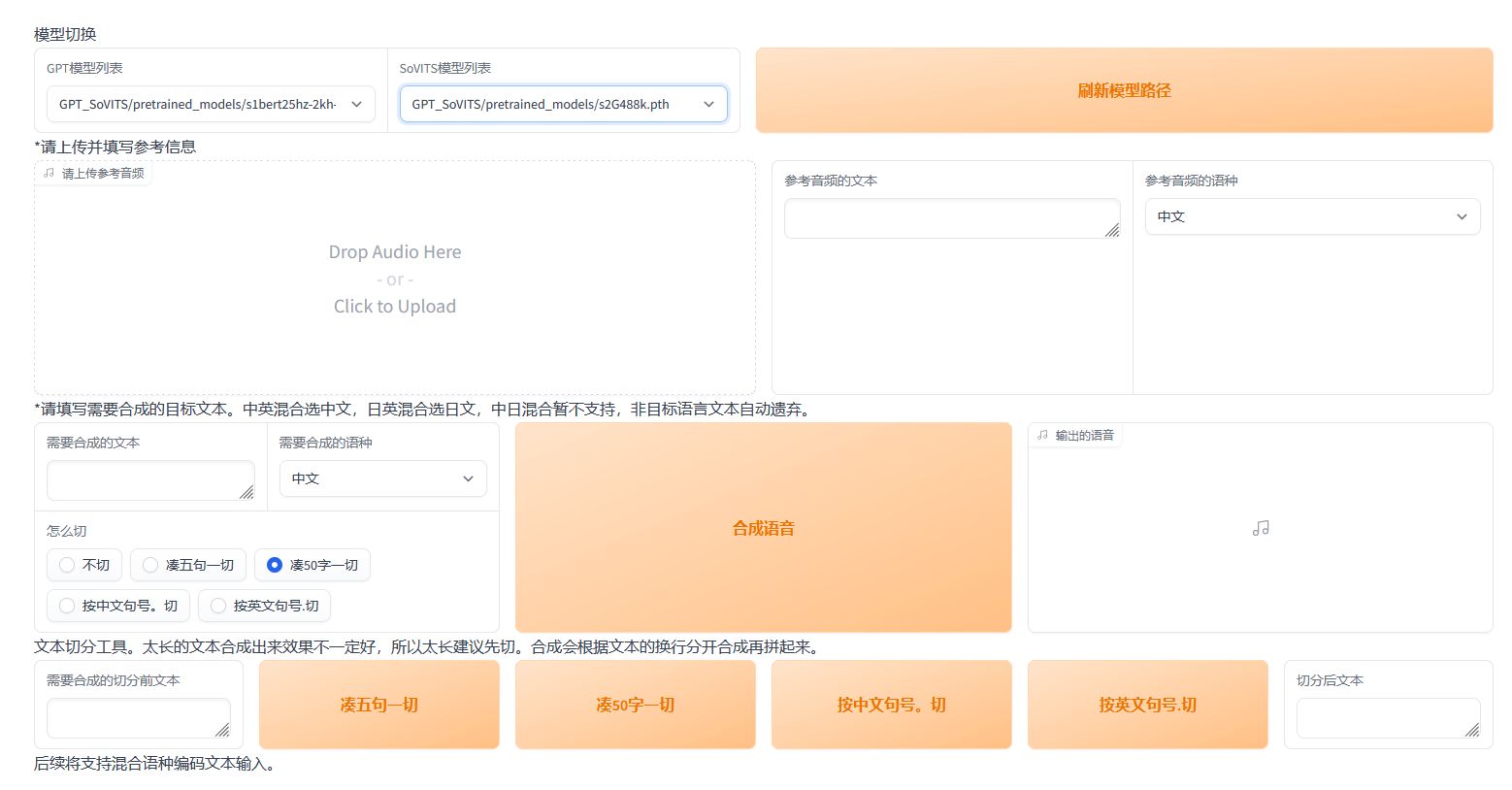
推理前我们需要给它一个目标音色参考音频,可以在之前切分的路径下取一个音频。我们将音频和文字,还有语音填入推理界面相应的位置。
然后将我们想说的文本,填写到下面。并且选择一种切分方式,或者自己手动切分。
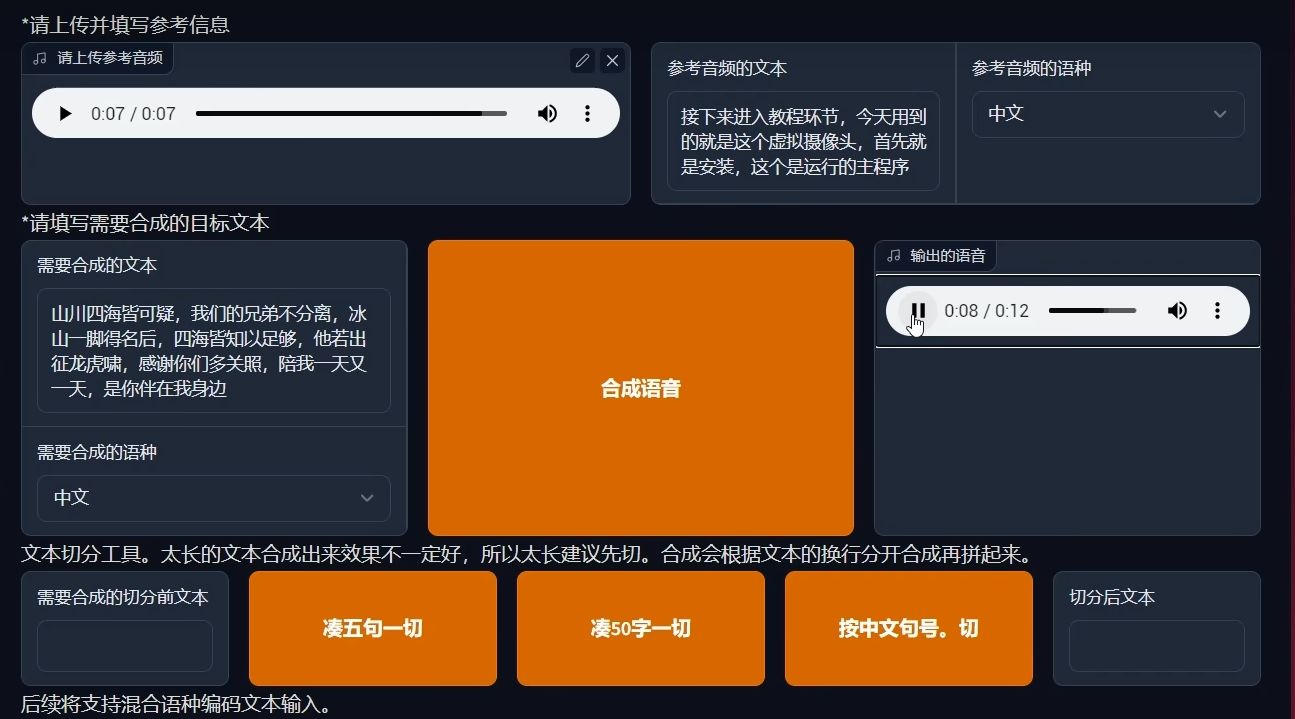
最后点击 "合成语音"。输出完成后可以试听一下效果:
到此,推理部分完。我们现在已经获得了一个训练完成的TTS模型。可以在推理界面输入任何文本,让其进行朗读。
后续的变声部分还在更新当中。
结语:
GPT-SoVITS-WebUI凭借其强大的功能和易用性,为语音技术的爱好者和开发者提供了一个强大的工具。它开创性的加入了GPT模型的机制,并以参考语音做为提示,非常好的解决了语音克隆的声音泄漏问题,生成的语音无论在音质还是真实度上,综合表现都非常不错。
版权归原作者 狠活科技 所有, 如有侵权,请联系我们删除。