
文章目录
2022-11-26
model_name = ‘rexnet_2_0_imagenet’
训练方式:对飞桨上现有的预训练模型进行迁移学习。
分类模式:4 类,包括 recyclable(可回收垃圾),other(干垃圾),kitchen(厨余垃圾),harmful(有害垃圾)。
1、分类中的问题
错误分类例子
毛巾:recyclable
一包白砂糖:harmful
纸巾:recyclable
乒乓球:kitchen(曾在115分类下被认作鸡蛋)
鞋子:harmful,recyclable
口罩:recyclable
胶带:recyclable
石头:kitchen
牙膏:harmful
拖布:recyclable
常出现的问题
1、经常把有包装,或者写有字的东西就判断为 harmful。例如:包装白砂糖,零食,易拉罐装八宝粥,书籍,桶装方便面······
2、感觉笔不太好分,例如有墨的笔需要二次分类,直接分应作为干垃圾。
3、同样是纺织品,拖布、抹布因为脏了,应该是干垃圾;而衣服却是可回收垃圾。
4、似乎总是不认识纸巾。
分类效果

2、模型问题分析
当前模型问题
可以在训练集上很好得收敛,准确率在 95% 以上;在验证集的准确率也在 90% 以上;而自己拍摄的照片,准确率却只有 50%~60%。
原因猜想
1、图片拍摄条件不同。 数据集中的图片可能是来自集中拍摄,使用某些特定的设备,且可能经过某些预处理,与我手机拍摄后直接上传的条件不同,图片中的噪音就不同,而模型没有处理这种差别的能力。
2、数据集的垃圾覆盖不充分。我验证集是从训练集中随机抽样得到,虽然验证机未用于模型训练,但它与训练集中的垃圾分布相似,验证集准确率可以较高。而我新拍摄的垃圾可能让模型感到很意外。
3、改进设想
针对图片拍摄条件,可在训练时进行数据增强,包括:裁剪、擦除、旋转、翻转、色调、对比度、亮度、噪声。
针对垃圾覆盖不充分,可以多找一些数据集,一起训练同一个模型。
4、还要做的事情
1、怎么部署。 程序最终要在硬件上跑,应当考虑移植和适配的问题。
2、再看一些别人是怎么做垃圾分类的。
图像预处理 API
来自包
paddlehub.vision.transforms
1、RandomHorizontalFlip: 随机水平翻转
2、RandomVerticalFlip:随机垂直翻转
3、ResizeStepScaling:以随机比例调整图像大小
4、RandomBlur:随机模糊
5、RandomRotation:随机角度旋转
6、RandomDistort:随机调整亮度、对比度、饱和度、色调
另外,看到 paddle.vision.transforms 里有个随机裁剪,但 paddlehub.vision.transfroms 里没有,使用可能不太方便。(后面发现 paddle 的可以直接用到 paddlehub 里)
处理效果
1、随机水平翻转 + 随机垂直翻转
(本来挺可爱的猴子,翻转之后怎么看都别扭)

2、随机旋转
如果要对图像进行标准化,建议标准化要在旋转之后,因为旋转后空白位置的填充值默认是值域 [0, 255]下的。
标准化在旋转之前则会出现如下情况,左为未标准化的填充值,右为已标准化的值。
左为正常效果,右为非正常:

3、随机模糊
好像不能指定图像模糊的程度,只能指定 “是否模糊” 的概率。

4、随机调整亮度、对比度、饱和度、色调

5、在随机位置裁剪到指定大小
(先将图片变到指定大小,再裁剪的,因此是扁的)

6、混合效果
(不是案发现场😅)

图像预处理代码
代码使用 PaddlePaddle 框架。
实际在图像识别中使用的时候,需要仔细考虑一下各种处理方法的顺序,以防bug。例如,如果将一些图片裁剪为指定大小后再随机角度旋转,得到的图片将是不同大小的(旋转会改变图片的大小)。
import paddlehub.vision.transforms as T
import paddle.vision.transforms as pvt
import matplotlib.pyplot as plt
# ----配置项----# 使用时换上自己的图片路径
im_path ='D:\code_all\code_python\PycharmProject1\mydata\myGarbages\SetGarbage40\\26.jpg'# 预处理效果设置
transforms = T.Compose([
T.RandomRotation(),
T.Resize([300,300]),# T.CenterCrop(224),
pvt.RandomCrop(224),
T.RandomHorizontalFlip(),
T.RandomVerticalFlip(),
T.RandomBlur(),
T.RandomDistort(),
T.Normalize(mean=[0.485,0.456,0.406], std=[0.229,0.224,0.225]),],
to_rgb=True)# 输出原图
im1 = plt.imread(im_path)
plt.subplot(3,6,1)
plt.imshow(im1)# 输出变换后的图像for i inrange(17):
im = transforms(im_path)
im =(im.transpose((1,2,0))+1.)/2
plt.subplot(3,6, i+2)
plt.imshow(im)
plt.show()
训练加处理后的预测效果
预处理添加方式:从数据集读取的每一张图片都经过一次随机的(如前面的混合模式)预处理。
加入预处理后,对自己拍摄照片的预测准确率并没有提高(好像还变低了?),如下。
这有个小问题,鞋子其实通常是作为可回收垃圾,我以为它是干垃圾,就没给它打勾。

扩展数据集
前面添加的随机预处理并没有改善模型的效果,有可能对预处理继续进行一些更精细化的调整会取得一些效果,但我打算先试试扩展数据集。
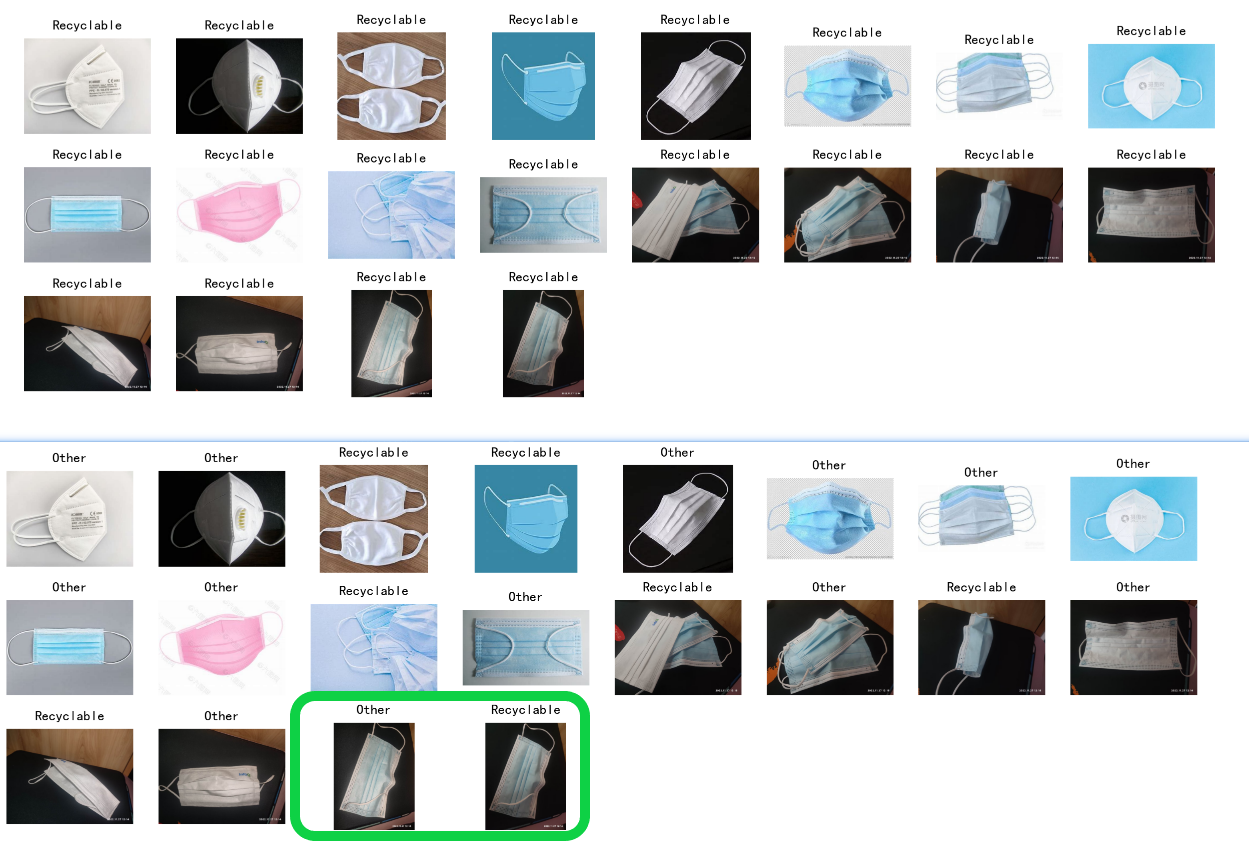
下载的单个数据集可能垃圾种类的覆盖不够充分,以至于我给它一些 ”新奇的垃圾“时,它就不认识了。前面模型经常对口罩识别错误,那我就多给它看看口罩试试。
方案:我找了 108 张口罩的图片,用这些口罩单独对模型进行训练。
结果:口罩成功被分为干垃圾(other),但现在它脑子里只剩下干垃圾了。

方案 2:将这 108 张口罩混到原来的数据集中,一起训练。但是原训练数据有 6 万张图,这点口罩扔进去不知能否翻起点水花。
结果:现实证明 108 张口罩没有翻起水花(也许训练更久会有效果?)
方案 2.1:提高口罩图在数据集中的占比。原训练集随机取 5000 张图,与 108 张口罩图混合,得到新训练集,其中口罩图约占 2%。
结果:将口罩识别为干垃圾的准确率增大了,且其它垃圾识别效果变化不大。下面是在训练集中加入口罩前后的识别效果对比,准确率有所提高,但还不够。
问题:最后两张图片相似但光线条件不同,被识别为了不同类别的垃圾。训练时我像之前一样进行了图像的随机预处理,效果似乎不太行。
是否可能预处理难以达到真实的光线变化的影响?还是我的预处理方案不合理?
多数据集交替训练
在前面简单做了些尝试后,我决定使用下载的多个数据集一起训练。我下载了 3 个数据集,它们原来是 4 分类、40 分类、115 分类,适当改造后就可以投入使用了(主要是改成适配 4 分类的训练模式)。
为什么不直接合并它们,而要交替使用呢?因为后面可能还会要分别使用。
交替训练方案:
每次从数据集中随机取出 400 张图,训练一个 epoch 后就换个数据集,让它不断面对来自不同数据集中的垃圾,最后让模型在不同数据集上都能收敛,增强模型的鲁棒性。
在训练初期,每次更换数据集时模型准确率会明显下降,可见不同数据集中的垃圾在分布上是存在差异的。100 个 epoch 后,模型在三个数据集上的验证集准确率分别为: 90 ~ 95%,85% ~ 90%,85% ~ 90%。
训练效果:虽然最后达到的准确率可以接受,但仍然对自己拍摄照片的识别率偏低,约 60%。对于在数据集中存在相似物品的网络图片,还是有较好的识别效果。但总的来说,该方案并没有带来明显的提升效果。
小结:4 分类还是更多分类?
前面做了一些图像预处理和数据集方面的尝试,都是建立在模型直接输出 4 分类的基础上。
另一种方案是,模型对图片进行细致的分类识别(例如直接识别图片中是苹果、胶带还是电池…),然后将识别结果直接对应到 4 类垃圾中。
未完待续······
14天学习训练营导师课程:
杨鑫《Python 自学编程基础》
杨鑫《 Python 网络爬虫基础》
杨鑫《 Scrapy 爬虫框架实战和项目管理》
版权归原作者 清风莫追 所有, 如有侵权,请联系我们删除。