
By
C
h
e
s
i
u
m
\text{By}\ \mathsf{Chesium}
By Chesium
DPLL 算法,全称为 Davis-Putnam-Logemann-Loveland(戴维斯-普特南-洛吉曼-洛夫兰德)算法,是一种完备的,基于回溯(backtracking)的搜索算法,用于判定命题逻辑公式(为合取范式形式)的可满足性,也就是求解 SAT(布尔可满足性问题)的一种(或者一类)算法。
SAT 问题简介
何为布尔可满足性问题?给定一条真值表达式,包含逻辑变量(又称 变量、命题变号、原子,用小写字母
a
,
b
,
…
a,b,\dots
a,b,… 表示)、**逻辑与**(AND,记为 “
∧
\wedge
∧” )运算符、**逻辑或**(OR,记为 “
∨
\vee
∨” )运算符以及**非**(NOT,否定,记为“
¬
\neg
¬”)运算符,如:
(
a
∧
¬
b
∧
(
¬
(
c
∨
d
∨
¬
a
)
∨
(
b
∧
¬
d
)
)
)
∨
(
¬
(
¬
(
¬
b
∨
a
)
∧
c
)
∧
d
)
(a\wedge\neg b\wedge(\neg(c\vee d\vee\neg a)\vee(b\wedge\neg d)))\vee(\neg(\neg(\neg b\vee a)\wedge c)\wedge d)
(a∧¬b∧(¬(c∨d∨¬a)∨(b∧¬d)))∨(¬(¬(¬b∨a)∧c)∧d)
是否存在一组对这些变量的赋值(如把所有
a
a
a 和
d
d
d 均赋值为
T
r
u
e
\mathrm{True}
True ,将所有
b
b
b 和
c
c
c 赋值为
F
a
l
s
e
\mathrm{False}
False ),使得整条式子最终的运算结果为
T
r
u
e
\mathrm{True}
True ?若可以,那么这个性质被称为这条逻辑公式的**可满足性**(satisfiability),如何快速高效地判断任意指定逻辑公式的可满足性是理论计算机科学中的一个重要的问题,也是第一个被证明为**NP-完全**(NP-complete,NPC)的问题。
暴力方案
对于这个问题,我们能够很容易地想到一种“暴力”的判定方法:测试这些变量赋值的每种可能的排列方式(如全部赋为
T
r
u
e
\mathrm{True}
True 、其一为
T
r
u
e
\mathrm{True}
True 其他全为
F
a
l
s
e
\mathrm{False}
False ……),若存在一种赋值排列使得公式的结果为
T
r
u
e
\mathrm{True}
True ,那么就可以说明这条公式是可满足的。但很显然,最坏情况下这种方法需要我们测试
2
n
2^n
2n 种(
n
n
n 为变量数)赋值排列,而用于检查每种赋值排列最终的运算结果也是不可忽略的。因此,随着公式规模的扩大,这种暴力算法所需的运算量会呈指数级飞快增长,这是我们不可接受的。
算法概述
但是根据现有计算复杂度理论,SAT问题是无法在多项式时间复杂度内解决的,DPLL算法也不例外。
DPLL算法是一种搜索算法,思想与DFS(Depth-first search,深度优先搜索)十分相似,或者说DPLL算法本身就属于DFS的范畴,其类似于上述我们设想的“暴力”算法:搜索所有可能的赋值排列。
具体地说,算法会在公式中选择一个变量(命题变号),将其赋值为
T
r
u
e
\mathrm{True}
True ,化简赋值后的公式,如果简化的公式是可满足的(递归地判断),那么原公式也是可满足的。否则就反过来将该变量赋值为
F
a
l
s
e
\mathrm{False}
False ,再执行一遍递归的判定,若也不能满足,那么原公式便是不可满足的。
这被称为 分离规则 (splitting rule),因为其将原问题分离为了两个更加简单的问题。
概念说明
DPLL算法求解的是合取范式(Conjunctive normal form,CNF),这是指形如下式的逻辑公式:
(
a
∨
b
∨
¬
c
)
∧
(
¬
d
∨
x
1
∨
¬
x
2
∨
⋯
∨
x
7
)
∧
(
¬
r
∨
v
∨
g
)
∧
⋯
∧
(
a
∨
d
∨
¬
d
)
(a\vee b\vee\neg c)\wedge (\neg d\vee x_1\vee\neg x_2\vee\dots\vee x_7)\wedge (\neg r\vee v\vee g)\wedge\dots\wedge (a\vee d\vee\neg d)
(a∨b∨¬c)∧(¬d∨x1∨¬x2∨⋯∨x7)∧(¬r∨v∨g)∧⋯∧(a∨d∨¬d)
其由多个括号括住部分的逻辑与组成,每一个括号内又是许多变量或变量的否定(逻辑非)的逻辑或组成。可以证明,所有只包含逻辑与、逻辑或、逻辑非、逻辑蕴含和括号的逻辑公式均可化为等价的合取范式。下面,我们称整个范式为“公式”,称每个括号里的部分为该公式的子句(clause),每个子句中的每个变量或其否定为文字(literal)。
可以看出,要使整条公式结果为
T
r
u
e
\mathrm{True}
True ,其所有子句都必须为
T
r
u
e
\mathrm{True}
True ,也就是说,每个子句中都至少有一个文字为
T
r
u
e
\mathrm{True}
True ,这个结论下面会用到。
DPLL 算法中的化简步骤实际上就是移除所有在赋值后值为
T
r
u
e
\mathrm{True}
True 的子句,以及所有在赋值后值为
F
a
l
s
e
\mathrm{False}
False 的文字。
化简步骤
这两个化简步骤是 DPLL 算法与我们“暴力”算法的主要区别,它们大大减少了搜索量,亦即加快了算法的运行速度。
第一个化简步骤:单位子句传播(Unit propagation)
我们称只含有一个(未赋值)变量的子句为单位子句(unit clause),根据上面的结论,要想让公式为
T
r
u
e
\mathrm{True}
True ,这个子句必须为
T
r
u
e
\mathrm{True}
True ,即这个变量对应的文字必须被赋值为
T
r
u
e
\mathrm{True}
True 。
比如下面的这条公式:
(
a
∨
b
∨
c
∨
¬
d
)
∧
(
¬
a
∨
c
)
∧
(
¬
c
∨
d
)
∧
(
a
)
(a\vee b\vee c\vee\neg d)\wedge(\neg a\vee c)\wedge(\neg c\vee d)\wedge(a)
(a∨b∨c∨¬d)∧(¬a∨c)∧(¬c∨d)∧(a)
其中最后一个子句就为单位子句,亦即我们要使文字
(
a
)
(a)
(a) 为
T
r
u
e
\mathrm{True}
True 。
然后,我们要依次处理这个变量在其他子句中的出现,如果另一个子句中的一个文字与单位子句中的文字相同,如上面例子中的
(
a
∨
b
∨
c
∨
¬
d
)
(a\vee b\vee c\vee\neg d)
(a∨b∨c∨¬d) 子句,我们知道
(
a
)
(a)
(a) 的值必须为
T
r
u
e
\mathrm{True}
True ,所以这个子句也肯定为
T
r
u
e
\mathrm{True}
True ,这意味着这个子句就不会对整个公式产生额外的约束(即
b
,
c
,
d
b,c,d
b,c,d 的取值不会影响该子句的取值),我们完全可以忽略这个子句,那就删掉它吧。
再考虑上式中第二个子句,其中出现了
(
a
)
(a)
(a) 的否定文字,我们知道它不可能为
T
r
u
e
\mathrm{True}
True 了,要让这个子句的值为
T
r
u
e
\mathrm{True}
True ,只能寄希望于
c
c
c 的取值了,我们完全可以把
¬
a
\neg a
¬a 删除(因为有没有它不影响该子句的取值)。
而第上式中第三个子句不包含
(
a
)
(a)
(a) 或其否定的出现,即
a
a
a 的取值不影响这个子句的取值,我们保持其不变即可。
这样,上述公式便被化简为了:
(
c
)
∧
(
¬
c
∨
d
)
∧
(
a
)
(c)\wedge(\neg c\vee d)\wedge(a)
(c)∧(¬c∨d)∧(a)
这个操作就被称为单位子句传播。
概括:**对于所有只包含一个文字
L
\mathrm{L}
L 的子句,对于公式剩余部分中的每个子句
C
\mathrm{C}
C:**
- 若 C \mathrm{C} C 包含 L \mathrm{L} L(非否定),则删除 C \mathrm{C} C。
- 若 C \mathrm{C} C 包含 ¬ L \neg\mathrm{L} ¬L,则删除这个 ¬ L \neg\mathrm{L} ¬L。
经过一次操作,我们发现公式中又出现了一个新的单位子句
(
c
)
(c)
(c) ,我们可以继续对其实施一遍单位子句传播,一直到整个公式中不存在任何一个单位子句对应的变量在其他子句中出现为止。
上式可被化简为:
(
c
)
∧
(
d
)
∧
(
a
)
(c)\wedge(d)\wedge(a)
(c)∧(d)∧(a)
现在即使公式中每个子句都是单位子句,但是其分别对应的变量
c
,
d
,
a
c,d,a
c,d,a 没有在除单位子句之外的子句中出现了,单位子句传播已经没有用了,我们要实施第二个化简步骤。
第二个化简步骤:孤立文字消去(Pure literal elimination)
如果一个变量在整个公式中只出现了一次,那么我们可以将其进行恰当的赋值,使其所在的子句为
T
r
u
e
\mathrm{True}
True 。具体地说,如果其出现的那一次是以否定形式出现的,那么就将变量赋值为
F
a
l
s
e
\mathrm{False}
False ,这可使其对应文字为
T
r
u
e
\mathrm{True}
True ,即使其所在子句为
T
r
u
e
\mathrm{True}
True ,反正则将变量赋值为
T
r
u
e
\mathrm{True}
True ,最终也能使其所在的子句为
T
r
u
e
\mathrm{True}
True ,接下来就和上述单位子句传播中发现子句为
T
r
u
e
\mathrm{True}
True 时的处理方式相同——删掉这个子句。
一句话概括,就为:删除所有孤立变量所在的子句。
对于以下的公式:
(
¬
r
∨
u
)
∧
(
r
∨
c
∨
¬
u
)
∧
(
¬
k
∨
r
)
∧
(
¬
d
∧
k
)
(\neg r\vee u)\wedge(r\vee \textcolor{red}{c}\vee\neg u)\wedge(\neg k\vee r)\wedge(\textcolor{blue}{\neg d}\wedge k)
(¬r∨u)∧(r∨c∨¬u)∧(¬k∨r)∧(¬d∧k)
其中标红的变量
c
c
c 在整个公式中只出现了一次,我们可以将其赋值为
T
r
u
e
\mathrm{True}
True 使得其所在的子句
(
r
∨
c
∨
¬
u
)
(r\vee \textcolor{red}{c}\vee\neg u)
(r∨c∨¬u) 为
T
r
u
e
\mathrm{True}
True ,我们可以将这个子句删除。同样的,标蓝的变量
d
d
d 在整个公式中只出现了一次,且是以否定形式出现的,我们可以将其赋值为
F
a
l
s
e
\mathrm{False}
False ,使其所在子句为
T
r
u
e
\mathrm{True}
True ,我们也可以将其删除。由此,公式被化简为了:
(
¬
r
∨
u
)
∧
(
¬
k
∨
r
)
(\neg r\vee u)\wedge(\neg k\vee r)
(¬r∨u)∧(¬k∨r)
再来看上面的例子:
(
c
)
∧
(
d
)
∧
(
a
)
(c)\wedge(d)\wedge(a)
(c)∧(d)∧(a)
所有三个变量都是孤立出现的,我们可以把这三个子句全部删除,整个公式就为空了,由此我们能判断出原公式是可满足的。
以上就是这两个化简步骤。
算法流程
下面给出 DPLL 算法的伪代码,先前说过,DPLL 算法实质上是一个深度优先搜索算法,所以两者十分相似。
1
A
l
g
o
r
i
t
h
m
D
P
L
L
(
C
N
F
Φ
)
:
=
2
d
o
UP
(
Φ
)
u
n
t
i
l
It changed nothing
.
3
d
o
PLE
(
Φ
)
u
n
t
i
l
It changed nothing
.
4
i
f
Φ
=
∅
t
h
e
n
5
r
e
t
u
r
n
t
r
u
e
.
6
i
f
∃
L
∈
Φ
,
L
=
∅
t
h
e
n
7
r
e
t
u
r
n
f
a
l
s
e
.
8
x
←
C
h
o
o
s
e
V
a
r
i
a
b
l
e
(
Φ
)
9
r
e
t
u
r
n
D
P
L
L
(
Φ
x
→
t
r
u
e
)
o
r
D
P
L
L
(
Φ
x
→
f
a
l
s
e
)
\begin{aligned} &\mathtt{1}\quad \mathtt{\textcolor{red}{Algorithm}}\ \ \mathrm{DPLL}(\mathtt{CNF}\ \ \textcolor{green}{\Phi}):=\\ &\mathtt{2}\quad\qquad \mathtt{\textcolor{red}{do}}\ \ \text{UP}(\textcolor{green}{\Phi})\ \ \mathtt{\textcolor{red}{until}}\ \ \text{It changed nothing}.\\ &\mathtt{3}\quad\qquad \mathtt{\textcolor{red}{do}}\ \ \text{PLE}(\textcolor{green}{\Phi})\ \ \mathtt{\textcolor{red}{until}}\ \ \text{It changed nothing}.\\ &\mathtt{4}\quad\qquad \mathtt{\textcolor{red}{if}}\ \ \textcolor{green}{\Phi}=\varnothing\ \ \mathtt{\textcolor{red}{then}}\\ &\mathtt{5}\quad\qquad\qquad \mathtt{\textcolor{red}{return}}\ \ \mathrm{\textcolor{blue}{true}}.\\ &\mathtt{6}\quad\qquad \mathtt{\textcolor{red}{if}}\ \ \exists L\in\textcolor{green}{\Phi},L=\varnothing\ \ \mathtt{\textcolor{red}{then}}\\ &\mathtt{7}\quad\qquad\qquad \mathtt{\textcolor{red}{return}}\ \ \mathrm{\textcolor{blue}{false}}.\\ &\mathtt{8}\quad\qquad x\leftarrow\mathrm{ChooseVariable}(\textcolor{green}{\Phi})\\ &\mathtt{9}\quad\qquad \mathtt{\textcolor{red}{return}}\ \ \mathrm{DPLL}(\textcolor{green}{\Phi}_{x\to\mathrm{\textcolor{blue}{true}}}) \ \ \mathtt{\textcolor{red}{or}}\ \ \mathrm{DPLL}(\textcolor{green}{\Phi}_{x\to\mathrm{\textcolor{blue}{false}}}) \end{aligned}
1Algorithm DPLL(CNF Φ):=2do UP(Φ) until It changed nothing.3do PLE(Φ) until It changed nothing.4if Φ=∅ then5return true.6if ∃L∈Φ,L=∅ then7return false.8x←ChooseVariable(Φ)9return DPLL(Φx→true) or DPLL(Φx→false)
其中
U
P
(
Φ
)
\mathrm{UP}(\Phi)
UP(Φ) 与
P
L
E
(
Φ
)
\mathrm{PLE}(\Phi)
PLE(Φ) 分别是指对公式
Φ
\Phi
Φ 进行**单位子句传播**和**孤立文字消去**,
C
h
o
o
s
e
V
a
r
i
a
b
l
e
(
Φ
)
\mathrm{ChooseVariable}(\Phi)
ChooseVariable(Φ) 是指在公式
Φ
\Phi
Φ 中选取一个变量(未赋值),根据现有的研究,这个选取变量的策略(被称为**启发函数**(heuristic function))会大大影响 DPLL 算法的运行效率,根据变量选择策略不同,DPLL 算法也有许多变种,但这不在我们现在的讨论范围内,作为初学者,我们就让
C
h
o
o
s
e
V
a
r
i
a
b
l
e
(
Φ
)
\mathrm{ChooseVariable}(\Phi)
ChooseVariable(Φ) 直接选择变量序列中的第一个变量。
第
9
9
9 行中的
Φ
x
→
t
r
u
e
\Phi_{x\to\mathrm{true}}
Φx→true 是指将公式
Φ
\Phi
Φ 中的变量
x
x
x 赋值为
T
r
u
e
\mathrm{True}
True,并根据在化简规则中描述过的方式处理赋值变量(删除包含其肯定出现的子句,并删除其否定形式的文字)后的公式,
Φ
x
→
f
a
l
s
e
\Phi_{x\to\mathrm{false}}
Φx→false 也如此,只不过将两种操作反过来。
可以看出这是个递归程序,对于输入的非空的原始公式
Φ
0
\Phi_0
Φ0,其在两种情况下中止:
- 公式 Φ \Phi Φ 为空,产生这种情况的原因只可能是:各个子句经过变量的赋值后值必为 T r u e \mathrm{True} True,不对 Φ \Phi Φ 中其他变量的赋值产生约束而全被删除。这意味着原始的 Φ 0 \Phi_0 Φ0 经过一部分(当然也可能是全部)变量的赋值后其所有子句的值都恒为 T r u e \mathrm{True} True, Φ 0 \Phi_0 Φ0 是可满足的。
- 公式 Φ \Phi Φ 包含空子句,产生这种情况的原因只可能是:这个子句中所有文字均在经过赋值后值为 F a l s e \mathrm{False} False,因此这些文字均被删除了,那么这个子句便不可能值为 T r u e \mathrm{True} True,公式 Φ \Phi Φ 是不可满足的。(这并不代表 Φ 0 \Phi_0 Φ0 无法满足,因为这只是一种可能的赋值排列)
具体实现
接下来,我们就开始着手从零实现一个基础款(不带复杂的
C
h
o
o
s
e
V
a
r
i
a
b
l
e
(
Φ
)
\mathrm{ChooseVariable}(\Phi)
ChooseVariable(Φ) 启发函数)的 DPLL 算法。
注意到,算法中涉及到大量的文字删除和子句删除操作,而且可能出现在文字列表和子句列表中间的任意位置(即不是简单地删除头或尾),而且处理各个子句、文字时遍历较多,而无需随机访问。我使用了链表(Linked list)来存储我们处理的公式。具体地说,我们使用一个二维链表来存储合取范式,它可以看作是子句的列表,而每个子句又可看作文字的列表。
每个文字有两个属性:变量编号(整数)和是否为否定文字(布尔值)。输入时我们将所有变量标识符离散化为变量编号。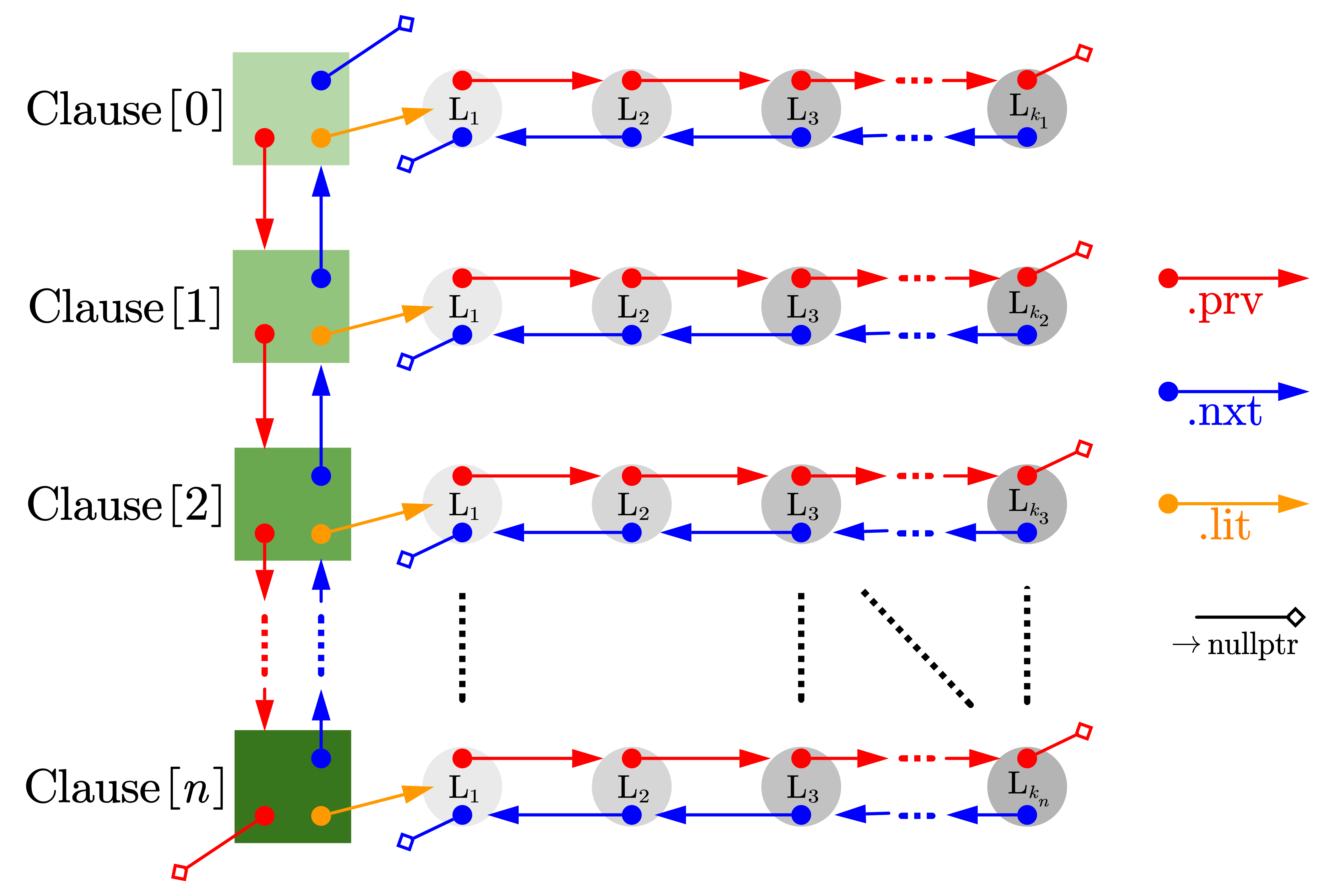
图1:用二维链表来存储合取范式
要删除一个文字时,我们只需将前一个文字的
.
n
x
t
\mathrm{.nxt}
.nxt 指针指向下一个文字,并将下一个文字的
.
p
r
v
\mathrm{.prv}
.prv 指针指向前一个文字即可,删除子句同理。
但是,我们发现算法过程中涉及到 找到特定逻辑变量的所有文字 的操作,如将某个变量赋值时就必须依次处理其所有文字,若只采取上述链表的结构,每次处理时就必须遍历所有子句、文字。我们可以通过再维护一个按变量名索引的二维链表,从而实现高效地遍历任意变量的所有文字。这看上去像是给上面的链表结构增加了许多“跳线”。对于合取范式:
(
a
∨
¬
c
∨
d
)
∧
(
d
∨
¬
b
∨
c
∨
¬
t
)
∧
(
¬
a
∨
b
∨
c
)
(a\vee\neg c\vee d)\wedge(d\vee\neg b\vee c\vee\neg t)\wedge(\neg a\vee b\vee c)
(a∨¬c∨d)∧(d∨¬b∨c∨¬t)∧(¬a∨b∨c)
我们就可以建立如下图的结构来存储:
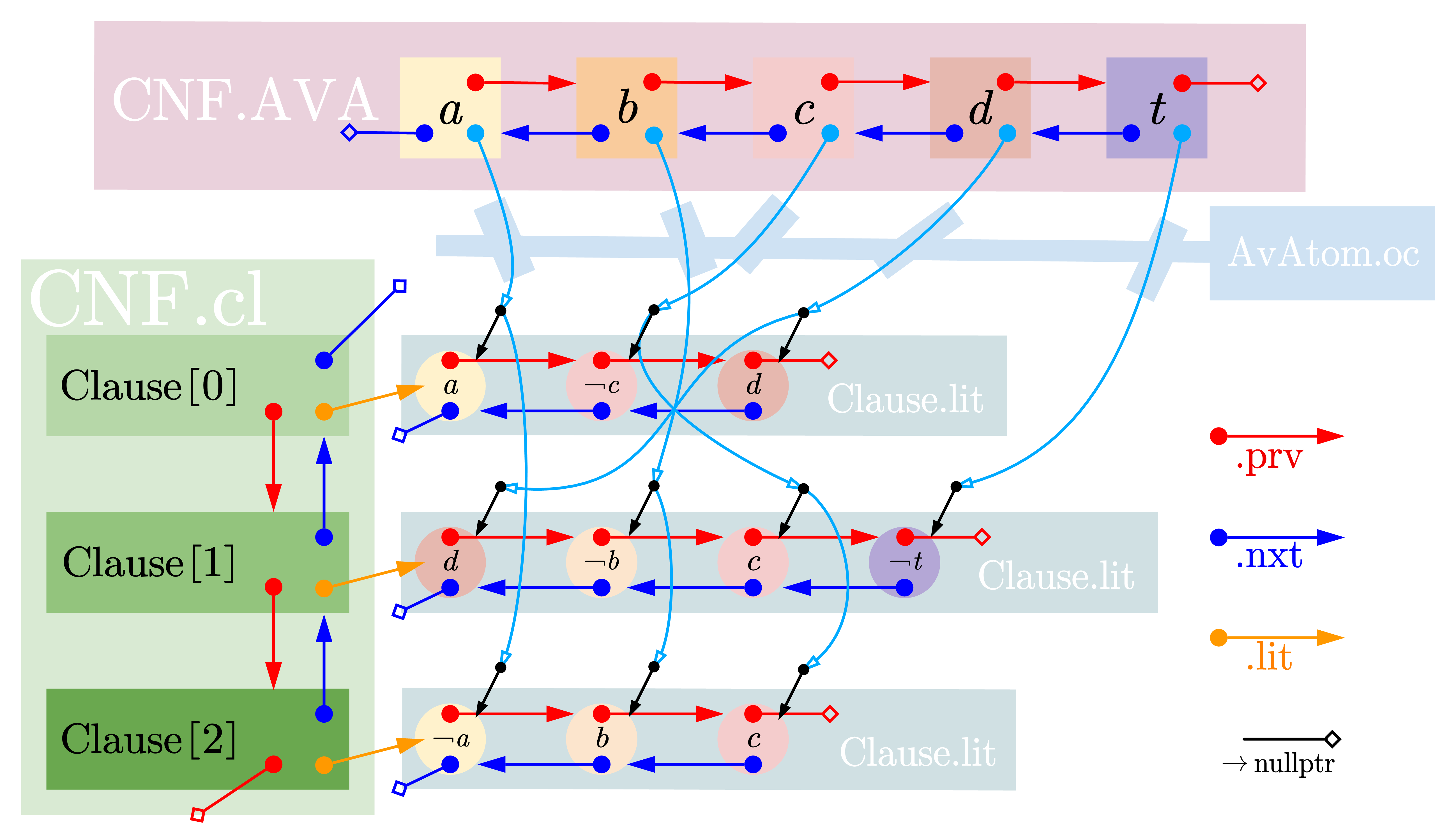
图2:在二维链表的基础上添加“跳线”以实现更高效的遍历
当然,其中仅仅画出了部分关键的指针结构,具体实现中天蓝色的“跳线”也是双向的,我们也可以通过增加一些额外的指针存储实现 通过文字找到其所在子句、通过文字找到其对应的文字列表。
除了图中的结构,通过在文字、子句的删除中维护一个“没有经过单位子句传播的单位子句”集合(或列表),以及一个 只有一个对应文字的变量 集合,我们可以不通过遍历找到所有单位子句和孤立变量以上述两个化简步骤。
但是,难题还在后头:这是个递归算法,涉及到对前几次历史版本的回溯。具体地说,在某种赋值(部分)组合下公式不可能满足,这时我们需要还原刚刚进行的化简操作和赋值操作,检查不同的赋值下公式能否满足,即进入另一个搜索分支。
如何进行回溯呢?最简单的就如伪代码中的,递归时直接通过调用函数中参数的复制传递复制一份整个公式结构的历史版本,这听上去虽然效率不高但实现简单,但事实上对于包含如此多指针的数据结构,要复制出完整、独立的一份必然涉及到大量指针的重定向,而这是十分困难且涉及到许多细节的,何况即使实现了,面对较大的递归层数,程序会占用很多内存,而且包含大量重复的冗余部分。
这里,我采用了一种基于 栈 和 增量存储 思想的数据结构。DPLL 算法可以看作一个在二叉树上进行 DFS 搜索的算法,程序在执行这种递归算法时会在函数(递归时就是自身)的调用中维护一个堆栈,存储每次函数调用中的局部变量。我仿照了这种结构,用栈来存储公式结构在一层层搜索的赋值中改变的部分。
具体地说,上面 图2 中的每一个箭头都是一个“指针栈”,存储着一系列的指针,标识该指针在递归过程中的一系列变化。在每一个搜索到的公式状态节点进行化简、赋值时,我们只访问、修改栈顶的指针,并用一个集合来标识在本次处理(化简、赋值)中修改过的指针栈,这些集合又用一个栈来维护。回溯至上一层时遍历栈顶的集合,将其中所有指针栈的栈顶释出,从而实现对历史公式版本的还原。上述数据结构可以看作一个简单的 部分可持久化链表组 ,当然这其中也有许多可供优化的地方。
实现代码
下面给出部分核心代码,完整代码可见:
- Chesium/DPLL (github.com)https://github.com/Chesium/DPLL代码使用说明见文末。
“指针栈链表”实现部分:
template <typename T>
struct node {
stack<node<T> *> prvPS, nxtPS;
slist<T> *L;
T *X = nullptr;
node(slist<T> *l, T *x = nullptr, node<T> *_prv = nullptr,
node<T> *_nxt = nullptr) {
this->L = l;
if (x != nullptr) this->X = new T(*x);
this->init_upd(_prv, _nxt);
}
void __upd(node<T> *_prv, node<T> *_nxt) {
if (_prv != nullptr) this->prvPS.push(_prv);
if (_nxt != nullptr) this->nxtPS.push(_nxt);
}
void init_upd(node<T> *_prv, node<T> *_nxt) {
if (_prv != nullptr)
while (!this->prvPS.empty()) this->prvPS.pop();
if (_nxt != nullptr)
while (!this->nxtPS.empty()) this->nxtPS.pop();
this->__upd(_prv, _nxt);
}
void upd(node<T> *_prv, node<T> *_nxt) {
if (_prv != nullptr) {
auto it = this->L->Recorder->ch.top().find(&(this->prvPS));
if (it == this->L->Recorder->ch.top().end())
this->L->Recorder->ch.top().insert(&(this->prvPS));
else
this->prvPS.pop();
this->prvPS.push(_prv);
}
if (_nxt != nullptr) {
auto it = this->L->Recorder->ch.top().find(&(this->nxtPS));
if (it == this->L->Recorder->ch.top().end())
this->L->Recorder->ch.top().insert(&(this->nxtPS));
else
this->nxtPS.pop();
this->nxtPS.push(_nxt);
}
}
bool isHead() { return this->L->begin() == this; }
bool isTail() { return this->L->end() == this; }
node<T> *prev() { return this->prvPS.top(); }
node<T> *next() { return this->nxtPS.top(); }
};
template <typename T>
struct slist {
stack<node<T> *> beginPS, endPS;
rmRecorder<T> *Recorder = nullptr;
slist() {
auto primNode = new node<T>(this);
this->beginPS.push(primNode);
this->endPS.push(primNode);
}
node<T> *begin() { return this->beginPS.top(); }
node<T> *end() { return this->endPS.top(); }
void regRec(rmRecorder<T> *rec) { this->Recorder = rec; }
bool empty() { return this->begin() == this->end(); }
bool single() {
if (this->empty()) return false;
return this->begin()->next() == this->end();
}
void add(T x) {
if (this->empty()) {
while (!this->beginPS.empty()) this->beginPS.pop();
this->beginPS.push(new node<T>(this, &x, nullptr, this->end()));
this->end()->init_upd(this->begin(), nullptr);
} else {
auto NewNode = new node<T>(this, &x, this->end()->prev(), this->end());
this->end()->prev()->init_upd(nullptr, NewNode);
this->end()->init_upd(NewNode, nullptr);
}
}
void rm(node<T> *nd) {
if (nd->L != this) return;
if (nd == this->end()) return;
if (nd == this->begin()) {
auto it = this->Recorder->ch.top().find(&this->beginPS);
if (it == this->Recorder->ch.top().end())
this->Recorder->ch.top().insert(&this->beginPS);
else
this->beginPS.pop();
this->beginPS.push(nd->next());
} else {
nd->prev()->upd(nullptr, nd->next());
nd->next()->upd(nd->prev(), nullptr);
}
}
T *front() { return this->begin()->X; }
T *back() { return this->end()->prev()->X; }
};
template <typename T>
struct rmRecorder {
stack<set<stack<node<T> *> *>> ch;
int layer = 0;
rmRecorder() { this->nextLayer(); }
void nextLayer() {
this->ch.push(set<stack<node<T> *> *>());
this->layer++;
}
void backtrack() {
for (auto it = this->ch.top().begin(); it != this->ch.top().end(); it++)
(*it)->pop();
this->layer--;
ch.pop();
}
};
数据结构部分:
struct Literal {
llu index; //
bool neg;
CNF *cnf;
node<Clause> *cl;
node<Occur> *oc;
Literal(CNF *_cnf, string s, bool _neg);
string str();
void RemoveOccurrence();
};
struct Clause {
slist<Literal> *lt;
CNF *cnf;
Clause(CNF *_cnf);
string str();
};
struct Occur {
node<Literal> *lit;
Occur(node<Literal> *_lit) { this->lit = _lit; }
};
struct AvAtom {
llu index;
slist<Occur> *oc;
CNF *cnf;
AvAtom(CNF *_cnf, llu i);
};
struct CNF {
map<string, llu> Dict;
vector<string> Atoms;
vector<ll> scheme;
llu AtomN = 0;
slist<Clause> CL;
slist<AvAtom> AVA;
vector<node<AvAtom> *> avAtoms;
rmRecorder<Literal> Rec_Literal;
rmRecorder<Clause> Rec_Clause;
rmRecorder<Occur> Rec_Occur;
rmRecorder<AvAtom> Rec_AvAtom;
stack<list<ll>> Rec_assign;
CNF() {
this->CL.regRec(&this->Rec_Clause);
this->AVA.regRec(&this->Rec_AvAtom);
}
void read();
string str();
string occurStr();
string schemeStr();
void removeLiteral(node<Clause> *cl, node<Literal> *lit);
void removeClause(node<Clause> *cl);
ll AssignLiteralIn(node<Clause> *cl, node<Literal> *unit);
bool PureLiteralAssign();
bool UnitPropagate();
void nextLayer();
void backtrack();
bool containEmptyClause = false;
bool DPLL(bool disableSimp);
};
void CNF::removeLiteral(node<Clause> *cl, node<Literal> *lit) {
cout << "DEL literal \"" << lit->X->str() << "\" in \"" << cl->X->str()
<< "\"" << endl;
lit->X->RemoveOccurrence();
cl->X->lt->rm(lit);
}
void CNF::removeClause(node<Clause> *cl) {
cout << "DEL Clause \"" << cl->X->str() << "\"" << endl;
for (auto lit = cl->X->lt->begin(); lit != cl->X->lt->end();
lit = lit->next())
lit->X->RemoveOccurrence();
this->CL.rm(cl);
}
void CNF::nextLayer() {
this->Rec_Literal.nextLayer();
this->Rec_Clause.nextLayer();
this->Rec_Occur.nextLayer();
this->Rec_AvAtom.nextLayer();
this->Rec_assign.push(list<ll>());
}
void CNF::backtrack() {
this->Rec_Literal.backtrack();
this->Rec_Clause.backtrack();
this->Rec_Occur.backtrack();
this->Rec_AvAtom.backtrack();
for (auto it = this->Rec_assign.top().begin();
it != this->Rec_assign.top().end(); it++)
this->scheme[*it] = 0;
this->Rec_assign.pop();
}
算法主体部分:
ll CNF::AssignLiteralIn(node<Clause>*cl, node<Literal>*unit){this->scheme[unit->X->index]= unit->X->neg ?2:1;this->Rec_assign.top().push_back(unit->X->index);bool changed =false;for(auto it = cl->X->lt->begin(); it != cl->X->lt->end(); it = it->next())if(it->X->index == unit->X->index){if(it->X->neg == unit->X->neg){this->removeClause(cl);return1;}else{this->removeLiteral(cl, it);if(cl->X->lt->empty()){this->containEmptyClause =true;return2;}
changed =true;}}return changed ?1:0;}bool CNF::UnitPropagate(){bool ok =false;for(auto it1 =this->CL.begin(); it1 !=this->CL.end(); it1 = it1->next())if(it1->X->lt->single()){
node<Literal>*A = it1->X->lt->begin();for(auto it2 =this->CL.begin(); it2 !=this->CL.end();
it2 = it2->next()){if(it1 == it2)continue;
ll res =this->AssignLiteralIn(it2, A);if(res ==2)returnfalse;if(res) ok =true;}if(ok)returntrue;}returnfalse;}bool CNF::PureLiteralAssign(){for(llu i =0; i <this->AtomN; i++)if(this->avAtoms[i]->X->oc->single()){this->scheme[this->avAtoms[i]->X->index]=this->avAtoms[i]->X->oc->begin()->X->lit->X->neg ?2:1;this->Rec_assign.top().push_back(this->avAtoms[i]->X->index);this->removeClause(this->avAtoms[i]->X->oc->begin()->X->lit->X->cl);returntrue;}returnfalse;}bool CNF::DPLL(bool disableSimp =false){
stack<ll> STACK;
AvAtom *x;
ll layerNow =-1, Status;
STACK.push(0);while(!STACK.empty()){
Status = STACK.top();
STACK.pop();/***/ cout <<"=== NEW STATUS : "<< Status <<" ==="<< endl;while(layerNow >=abs(Status)){
layerNow--;/***/ cout <<"BACKTRACK: -> "<< layerNow << endl;this->backtrack();}
layerNow =abs(Status);/***/ cout <<"FORMULA: begin processing(layer="<< layerNow
<<"):"<< endl;/***/ cout <<this->str();this->nextLayer();if(Status ==0){/***/ cout <<"INIT: skip assignments"<< endl;goto SIMPLIFICATION;}
x =this->AVA.begin()->X;/***/ cout <<"ASSIGN: \""<< Atoms[x->index]<<"\" -> "<<(Status >0?"True":"False")<< endl;this->scheme[x->index]= Status >0?1:2;this->Rec_assign.top().push_back(x->index);for(auto it = x->oc->begin(); it != x->oc->end(); it = it->next()){if((Status <0)== it->X->lit->X->neg)this->removeClause(it->X->lit->X->cl);else{this->removeLiteral(it->X->lit->X->cl, it->X->lit);if(it->X->lit->X->cl->X->lt->empty()){this->containEmptyClause =true;break;}}}/***/ cout <<"FORMULA: finish assignments:"<< endl;/***/ cout <<this->str();
SIMPLIFICATION:if(!disableSimp){while(this->UnitPropagate()){}/***/ cout <<"FORMULA: Unit-propagatated:"<< endl;/***/ cout <<this->str();while(this->PureLiteralAssign()){}/***/ cout <<"FORMULA: Pure-literal-assigned:"<< endl;/***/ cout <<this->str();}if(this->CL.empty()){/***/ cout <<"***FORMULA IS EMPTY: It can be satisfied."<< endl;/***/ cout <<"***ALGORITHM FINISHED."<< endl;returntrue;}if(this->containEmptyClause){/***/ cout <<"***FORMULA CONTAIN EMPTY CLAUSES: backtrack."<< endl
<< endl;this->containEmptyClause =false;continue;}
STACK.push(abs(Status)+1);
STACK.push(-abs(Status)-1);/***/ cout << endl;}/***/ cout <<"***The formula cannot be satisfied."<< endl;/***/ cout <<"***ALGORITHM FINISHED."<< endl;returnfalse;}
代码使用示例
最低 C++ 标准:C++ 11
输入格式:一行一个正整数
n
n
n,表示合取范式包含
n
n
n 个子句。接下来
n
n
n 行,第
i
i
i 行开头为一个正整数
k
i
k_i
ki 表示该子句包含
k
i
k_i
ki 个文字,随即有
k
i
k_i
ki 个以空格分隔的字符串,表示各个文字,若该字符串以
^
开头,则表示该文字为否定文字。
例如,下列合取范式:
(
a
∨
b
)
∧
(
¬
a
∨
¬
c
)
∧
(
b
∨
¬
t
∨
a
∨
¬
c
)
∧
(
c
∨
d
)
∧
a
\begin{aligned} &(a\vee b)\\ \wedge\ &(\neg a\vee\neg c)\\ \wedge\ &(b\vee\neg t\vee a\vee\neg c)\\ \wedge\ &(c\vee d)\\ \wedge\ &a \end{aligned}
∧ ∧ ∧ ∧ (a∨b)(¬a∨¬c)(b∨¬t∨a∨¬c)(c∨d)a
的输入代码就为:
5
2 a b
2 ^a ^c
4 b ^t a ^c
2 c d
1 a
包含头文件
dpll.hpp
,保证其和
slist.hpp
在同一文件夹下,即可创建
CNF
对象,调用其
.read()
方法以从标准输入输出中读入合取范式。接着便可通过调用方法
.DPLL()
应用算法(加上参数
true
可以使算法跳过化简步骤),许多调试信息都会一并输出出来。如果要获取一种可行的赋值方案(前提是公式可满足),可以在应用 DPLL 算法后输出
.schemeStr()
方法生成的字符串,其样式如下:
"a" -> True
"b" -> _
"c" -> False
"t" -> _
"d" -> True
每行表示一个变量的赋值,若赋值为下划线
_
则说明其赋值为
true
或
false
均可。
我们对上述合取范式示例应用算法,输出应为:
=== NEW STATUS : 0 ===
FORMULA: begin processing(layer=0):
{
| ( a ∨ b )
| ∧ ( ¬a ∨ ¬c )
| ∧ ( b ∨ ¬t ∨ a ∨ ¬c )
| ∧ ( c ∨ d )
| ∧ a
}
INIT: skip assignments
DEL Clause "a ∨ b"
DEL literal "¬a" in "¬a ∨ ¬c"
DEL Clause "b ∨ ¬t ∨ a ∨ ¬c"
DEL literal "c" in "c ∨ d"
FORMULA: Unit-propagatated:
{
| ¬c
| ∧ d
| ∧ a
}
DEL Clause "a"
DEL Clause "¬c"
DEL Clause "d"
FORMULA: Pure-literal-assigned:
{
}
***FORMULA IS EMPTY: It can be satisfied.
***ALGORITHM FINISHED.
1
"a" -> True
"b" -> _
"c" -> False
"t" -> _
"d" -> True
从中可以清晰地看到算法执行的流程和经过各个化简步骤后公式的内容。这条公式经过一次化简后就足以判断其是否可满足了,我们通过
.DPLL(true)
禁用化简步骤可以清晰地看到算法回溯的过程:
=== NEW STATUS : 0 ===
FORMULA: begin processing(layer=0):
{
| ( a ∨ b )
| ∧ ( ¬a ∨ ¬c )
| ∧ ( b ∨ ¬t ∨ a ∨ ¬c )
| ∧ ( c ∨ d )
| ∧ a
}
INIT: skip assignments
=== NEW STATUS : -1 ===
FORMULA: begin processing(layer=1):
{
| ( a ∨ b )
| ∧ ( ¬a ∨ ¬c )
| ∧ ( b ∨ ¬t ∨ a ∨ ¬c )
| ∧ ( c ∨ d )
| ∧ a
}
ASSIGN: "a" -> False
DEL literal "a" in "a ∨ b"
DEL Clause "¬a ∨ ¬c"
DEL literal "a" in "b ∨ ¬t ∨ a ∨ ¬c"
DEL literal "a" in "a"
FORMULA: finish assignments:
{
| b
| ∧ ( b ∨ ¬t ∨ ¬c )
| ∧ ( c ∨ d )
| ∧ ( )
}
***FORMULA CONTAIN EMPTY CLAUSES: backtrack.
=== NEW STATUS : 1 ===
BACKTRACK: -> 0
FORMULA: begin processing(layer=1):
{
| ( a ∨ b )
| ∧ ( ¬a ∨ ¬c )
| ∧ ( b ∨ ¬t ∨ a ∨ ¬c )
| ∧ ( c ∨ d )
| ∧ a
}
ASSIGN: "a" -> True
DEL Clause "a ∨ b"
DEL literal "¬a" in "¬a ∨ ¬c"
DEL Clause "b ∨ ¬t ∨ a ∨ ¬c"
DEL Clause "a"
FORMULA: finish assignments:
{
| ¬c
| ∧ ( c ∨ d )
}
=== NEW STATUS : -2 ===
FORMULA: begin processing(layer=2):
{
| ¬c
| ∧ ( c ∨ d )
}
ASSIGN: "c" -> False
DEL Clause "¬c"
DEL literal "c" in "c ∨ d"
FORMULA: finish assignments:
{
| d
}
=== NEW STATUS : -3 ===
FORMULA: begin processing(layer=3):
{
| d
}
ASSIGN: "d" -> False
DEL literal "d" in "d"
FORMULA: finish assignments:
{
| ( )
}
***FORMULA CONTAIN EMPTY CLAUSES: backtrack.
=== NEW STATUS : 3 ===
BACKTRACK: -> 2
FORMULA: begin processing(layer=3):
{
| d
}
ASSIGN: "d" -> True
DEL Clause "d"
FORMULA: finish assignments:
{
}
***FORMULA IS EMPTY: It can be satisfied.
***ALGORITHM FINISHED.
1
"a" -> True
"b" -> _
"c" -> False
"t" -> _
"d" -> True
输出中间出现
BACKTRACK
就说明算法执行了一次回溯,将公式还原回赋值、化简前的形态。
参考
- Boolean satisfiability problem - Wikipedia https://en.wikipedia.org/wiki/Boolean_satisfiability_problem
- DPLL algorithm - Wikipedia https://en.wikipedia.org/wiki/DPLL_algorithm
版权归原作者 Chesium 所有, 如有侵权,请联系我们删除。