
前言
Spark SQL是用于结构化数据处理的Spark模块。它提供了一种称为DataFrame的编程抽象,是由SchemaRDD发展而来。不同于SchemaRDD直接继承RDD,DataFrame自己实现了RDD的绝大多数功能。Spark SQL增加了DataFrame(即带有Schema信息的RDD),使用户可以在Spark SQL中执行SQL语句,数据既可以来自RDD,也可以是Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据。
Spark SQL目前支持Scala、Java、Python三种语言,支持SQL-92规范。
那么根据上篇文章:
PySpark数据分析基础:PySpark基础功能及DataFrame操作基础语法详解
我们知道PySpark可以将DataFrame转换为Spark DataFrame,这为我们python使用Spark SQL提供了实现基础。且在spark3.3.0目录下的pyspark sql可以看到所有函数和类方法:
本篇文章将具体讲述PySpark的SQL核心函数使用方法。
一、pyspark.sql.SparkSession
基础语法:
class pyspark.sql.SparkSession(sparkContext: pyspark.context.SparkContext, jsparkSession: Optional[py4j.java_gateway.JavaObject] = None, options: Dict[str, Any] = {})
SparkSession是使用Dataset和DataFrame API编程Spark的入口点。
SparkSession可以用于创建DataFrame、将DataFrame注册为表、在表上执行SQL、缓存表和读取parquet文件。要创建SparkSession,需要使用以下生成器模式:
该类可以通过Builder去构建SparkSession:
若对此函数不了解可以去看Spark SQL DataFrame创建一文详解运用与方法和Spark RDD数据操作函数以及转换函数一文详解运用与方法这两篇文章。
使用方法:
spark = SparkSession.builder \
.master("local") \
.appName("Word Count") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
对标开发Spark的Scala源码:
//暂时保存 用户的sparkContext spark 内部使用
//例如 SQLContext 中 this(SparkSession.builder().sparkContext(sc).getOrCreate())
//用来创建SQLContext实例
private[spark] def sparkContext(sparkContext: SparkContext): Builder = synchronized {
userSuppliedContext = Option(sparkContext)
this
}
//设置config到这个类的 options 中去保存,还有各种value其他类型的重载方法
def config(key: String, value: String): Builder = synchronized {
options += key -> value
this
}
//设置 spark.app.name
def appName(name: String): Builder = config("spark.app.name", name)
//把用户在sparkConf中设置的config 加到 这个类的 options 中去
def config(conf: SparkConf): Builder = synchronized {
conf.getAll.foreach { case (k, v) => options += k -> v }
this
}
//设置 spark.master 可以是 local、lcoal[*]、local[int]
def master(master: String): Builder = config("spark.master", master)
//用来检查是否可以支持连接hive 元数据,支持集成hive
def enableHiveSupport(): Builder = synchronized {
//hiveClassesArePresent 是SparkSession Object的一个方法,用来判断是否包含
//hive的一些支持包(org.apache.spark.sql.hive.HiveSessionStateBuilder,org.apache.hadoop.hive.conf.HiveConf),
//通过ClassForName 反射来判定所需的jar是否存在,自已这里的ClassForName 是spark自己封装的,目的在于尽可能使用启动本线程的 类加载器
//如果所需的集成hive依赖都在的话,hiveClassesArePresent 会返回true
if (hiveClassesArePresent) {
//在此类Builder的属性options中加入
//catalog的config (spark.sql.catalogImplementation, hive)
config(CATALOG_IMPLEMENTATION.key, "hive")
} else {
throw new IllegalArgumentException(
"Unable to instantiate SparkSession with Hive support because " +
"Hive classes are not found.")
}
}
//这个方法用来增加扩展点(injection points|extension points)到
//SparkSessionExtensions里面
def withExtensions(f: SparkSessionExtensions => Unit): Builder = synchronized {
f(extensions)
this
}
那么builder()配置有下面几种:
MethodDescriptiongetOrCreate()获取或创建一个新的SparkSessionenableHiveSupport()增加Hive支持appName()设置application的名字config()设置各种配置master()加载spark.master设置
那么该函数最直接的使用方法就是创建一个sparkContext:
data = sc.parallelize([1, 2, 3])
data.collect()
[1, 2, 3]
创建转换为RDD。
二、类方法
1.parallelize
该方法为Spark中SparkContext类的原生方法,用于生产一个RDD。
上述已经演示过了。
2.createDataFrame
基础语法
SparkSession.createDataFrame(data,schema=None,samplingRatio=None,verifySchema=True)
功能
从一个RDD、列表或pandas dataframe转换创建为一个Spark DataFrame。
参数说明
- data:接受类型为[pyspark.rdd.RDD[Any], Iterable[Any], PandasDataFrameLike]。任何类型的SQL数据表示(Row、tuple、int、boolean等)、列表或pandas.DataFrame的RDD。
- schema:接受类型为*[pyspark.sql.types.AtomicType, pyspark.sql.types.StructType, str, None] *a pyspark.sql.types:数据类型、数据类型字符串或列名列表,默认值为无。数据类型字符串格式等于pyspark.sql.types.DataType.simpleString,除了顶级结构类型可以省略struct<>。 - 当schema是一列列索引名称时,每一列数据类型将会根据数据类型定义。- 当schema为None时,它将尝试从数据中推断模式(列名和类型),判断数据为Row、namedtuple或dict。- 当schema为pyspark.sql.types.DataType或为数据类型字符串,它必须与真实数据匹配,否则将在运行时引发异常。如果给定的schema不是pyspark.sql.types.StructType,它将被包装成pyspark.sql.types.StructType作为其唯一字段,字段名将为“value”。每个记录也将被包装成一个元组tuple,也可以将其转换为row。- 如果不指定schema,则使用samplingRatio来确定用于模式推理的行的比率。如果samplingRatio为None,则使用第一行。
- **samplingRatio:**接受类型:float, optional。用于推断的行的采样率
- verifySchema:根据架构验证每行的数据类型。默认情况下启用。
返回
返回一个pyspark.sql.dataframe.DataFrame。
data参数代码运用:
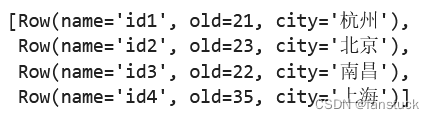
pd_df=pd.DataFrame(
{'name':['id1','id2','id3','id4'],
'old':[21,23,22,35],
'city':['杭州','北京','南昌','上海']
},
index=[1,2,3,4])
spark.createDataFrame(pd_df).collect()
simple=[('杭州','40')]
spark.createDataFrame(simple,['city','temperature']).collect()

simple_dict=[{'name':'id1','old':21}]
spark.createDataFrame(simple_dict).collect()
[Row(name='id1', old=21)]
rdd = sc.parallelize(simple)
spark.createDataFrame(rdd).collect()
[Row(_1='杭州', _2='40')]
schema参数代码运用:
simple=[('杭州',40)]
rdd = sc.parallelize(simple)
spark.createDataFrame(rdd, "city:string,temperatur:int").collect()
[Row(city='杭州', temperatur=40)]
3.getActiveSession
基础语法:
classmethod SparkSession.getActiveSession()
功能:
返回通过builder生成的当前线程的活动SparkSession
代码示例
s = SparkSession.getActiveSession()
simple=[('杭州',40)]
rdd = s.sparkContext.parallelize(simple)
df = s.createDataFrame(rdd, ['city', 'temperatur'])
df.select("city").collect()
[Row(city='杭州')]
4.newSession
基础语法:
SparkSession.newSession()
功能:
将新的SparkSession作为新会话返回,该会话具有单独的SQLConf、注册的临时视图和UDF,但共享SparkContext和表缓存。
重新返回一个新的newSparkSession,作表数据对比时可用。
5.range
基础语法:
SparkSession.range(start,end= None, step: int = 1, numPartitions: = None)
功能:
使用单个pyspark.sql.types.LongType列名为id,包含从开始到结束(独占)范围内的元素,步长值为step。
参数说明:
- start:类型[int],开始值
- end:类型[int],结束值
- step:类型[int],步长
- numPartitions:类型[int],DataFrame分区数
代码示例:
spark.range(1, 100, 20).collect()
[Row(id=1), Row(id=21), Row(id=41), Row(id=61), Row(id=81)]
如果只指定了一个参数,则将其用作结束值,默认起始值为0。
spark.range(5).collect()
[Row(id=0), Row(id=1), Row(id=2), Row(id=3), Row(id=4)]
6.sql
基础语法:
SparkSession.sql(sqlQuery: str, **kwargs: Any)
功能:
返回表示给定查询结果的DataFrame。当指定kwargs时,此方法使用Python标准格式化程序格式化给定字符串。
参数说明:
- sqlQuery:接受类型[str],SQL查询字符串。
- kwargs:接受类型[dict],用户想要设置的、可以在查询中引用的其他变量。
代码示例:
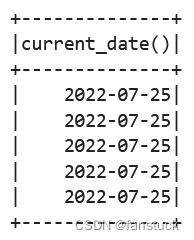
spark.sql("SELECT current_date() FROM range(5)").show()
spark.sql(
"SELECT * FROM range(10) WHERE id > {bound1} AND id < {bound2}", bound1=7, bound2=9
).show()
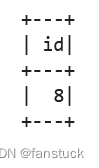
mydf = spark.range(10)
spark.sql(
"SELECT {col} FROM {mydf} WHERE id IN {x}",
col=mydf.id, mydf=mydf, x=tuple(range(4))).show()
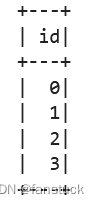
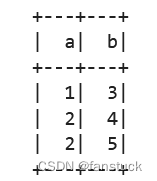
复杂运用:
spark.sql('''
SELECT m1.a, m2.b
FROM {table1} m1 INNER JOIN {table2} m2
ON m1.key = m2.key
ORDER BY m1.a, m2.b''',
table1=spark.createDataFrame([(1, "a"), (2, "b")], ["a", "key"]),
table2=spark.createDataFrame([(3, "a"), (4, "b"), (5, "b")], ["b", "key"])).show()
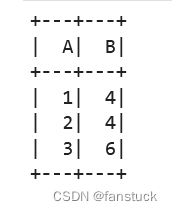
此外,还可以使用DataFrame中的class:Column进行查询。
mydf = spark.createDataFrame([(1, 4), (2, 4), (3, 6)], ["A", "B"])
spark.sql("SELECT {df.A}, {df[B]} FROM {df}", df=mydf).show()
7.table
基础语法
SparkSession.table(tableName: str)
功能:
将指定的表作为DataFrame返回。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
参阅
Spark-SparkSession.Builder 源码解析
SparkSession的简介和方法详
版权归原作者 fanstuck 所有, 如有侵权,请联系我们删除。