
💖作者简介:大家好,我是车神哥,府学路18号的车神🥇
⚡About—>车神:从寝室到实验室最快3分钟,最慢3分半(那半分钟其实是等红绿灯)
📝个人主页:车手只需要车和手,压力来自论文_府学路18号车神_CSDN博客
🥇 官方认证:人工智能领域优质创作者
🎉点赞➕评论➕收藏 == 养成习惯(一键三连)😋⚡希望大家多多支持🤗~一起加油 😁
- 专栏
- 《20天掌握Pytorch实战》
不定期学习《20天掌握Pytorch实战》,有兴趣就跟着专栏一起吧~
开源自由,知识无价~
最近读Paper,发现有很多提出的改进和创新都存在很多trick,无法复现。看到一句话,真的很戳搞科研的心,但也很现实:
很多的邻域门槛很低,当某一天那些灌水的paper干不过在网络搜出来的东西,那么这波人也就自动消失了。我们到底应不应该花大量的时间阅读那些最新的研究?应该,但更多的时候,它们不配。
图片数据建模流程范例
🤗前言:torch和torchvision安装
由于我是在PyCharm中进行实验的,所以需要自行安装torch的库,和其他的库安装一样,直接在Terminal中pip就OK了。
pip install torchpip install torchvision -i https://pypi.tuna.tsinghua.edu.cn/simple/整个安装过程可能有点慢,包也比较大,耐心等待即可。
如果是使用Jupyter notebook的同学,可以直接使用。(mac系统上pytorch和matplotlib在jupyter中同时跑需要更改环境变量)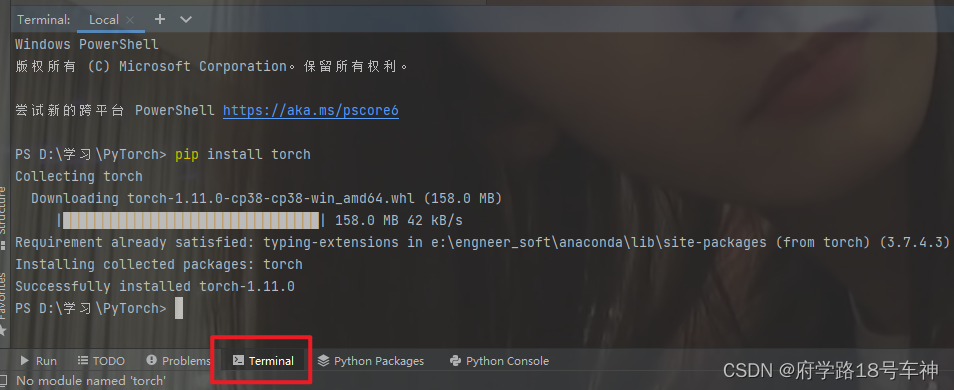
所用到的源代码及书籍+数据集以帮各位小伙伴下载放在文末,自取即可~
😁概览
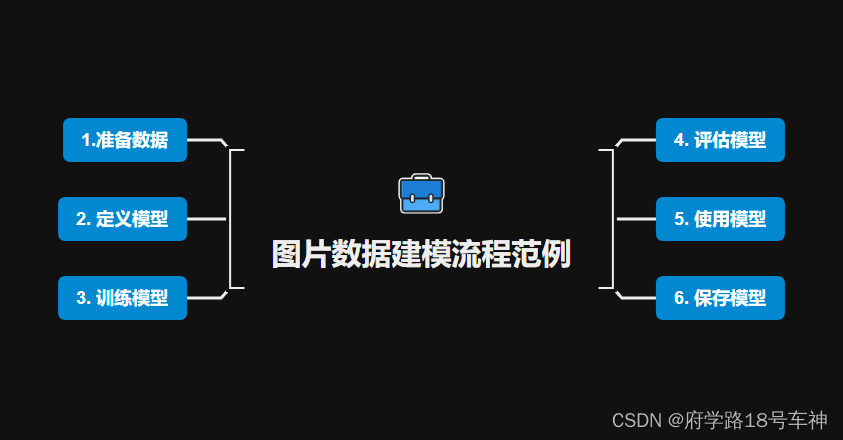
一、 🎉准备数据
老规矩,后面模型的
history
需要获取每次迭代的时间,下面的打印时间代码必备~
import os
import datetime
#打印时间defprintbar():
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')print("\n"+"=========="*8+"%s"%nowtime)#mac系统上pytorch和matplotlib在jupyter中同时跑需要更改环境变量
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
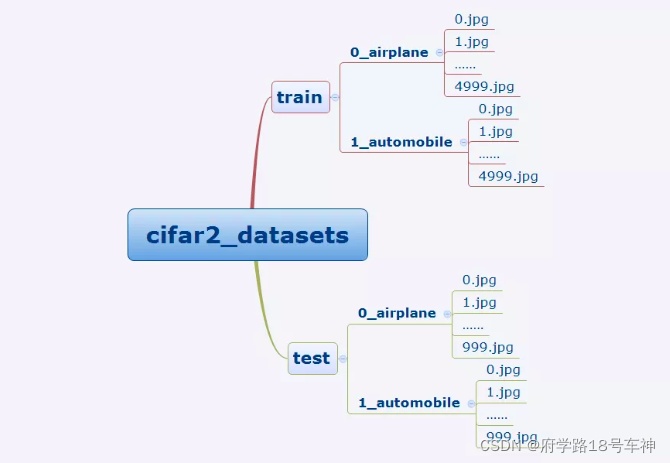
cifar2数据集
为
cifar10数据集
的
子集
,只包括前两种类别
airplane
和
automobile
。
训练集有airplane和automobile图片各5000张,测试集有airplane和automobile图片各1000张。
cifar2任务的目标
是训练一个模型来对飞机airplane和机动车automobile两种图片进行
分类
。
我们准备的Cifar2数据集的文件结构如下所示。
在
Pytorch
中构建图片数据管道通常有
两种方法
。
- 第一种是使用 torchvision中的datasets.ImageFolder来读取图片然后用 DataLoader来并行加载。
- 第二种是通过继承 torch.utils.data.Dataset 实现用户自定义读取逻辑然后用 DataLoader来并行加载。第二种方法是读取用户自定义数据集的通用方法,既可以读取图片数据集,也可以读取文本数据集。
文档中只介绍了第一种方法,那就直接搞起来吧~
和上一篇的数据构建有所不同
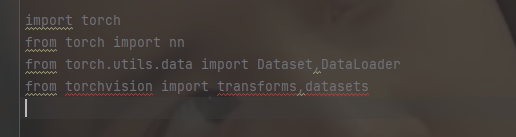
导入库
import torch
from torch import nn
from torch.utils.data import Dataset,DataLoader
from torchvision import transforms,datasets
有的小伙伴可能也没有安装
torchvision
,下面给出安装的指令,同样也是在
terminal
命令行:
pip install torchvision -i https://pypi.tuna.tsinghua.edu.cn/simple/
国内由于网速的限制,使用命令安装时需在后面加上清华的镜像,这样下载速度会大大提升,安装更容易成功。
下面简单介绍一下torchvision :
torchvision是PyTorch中专门用来处理图像的库。这个包中有四个大类。
- torchvision.datasets: 用来进行数据加载的,PyTorch团队在这个包中帮我们提前处理好了很多很多图片数据集。
- torchvision.models: 为我们提供了已经训练好的模型,让我们可以加载之后,直接使用。
- torchvision.transforms: 提供了一般的图像转换操作类
- torchvision.utils: 数据处理工作箱,包括四个类,具体可以参考 这里。
- 划分数据集
transform_train = transforms.Compose([transforms.ToTensor()])
transform_valid = transforms.Compose([transforms.ToTensor()])
ds_train = datasets.ImageFolder("./data/cifar2/train/",
transform = transform_train,target_transform=lambda t:torch.tensor([t]).float())# 训练集构建
ds_valid = datasets.ImageFolder("./data/cifar2/test/",
transform = transform_train,target_transform=lambda t:torch.tensor([t]).float())# 验证集构建print(ds_train.class_to_idx)# 输出训练集的类别与index,按顺序为这些类别定义索引为0,1...
关于ImageFolder
ImageFolder是一个通用的数据加载器,它要求我们以下面这种格式来组织数据集的训练、验证或者测试图片。
参数解析:
dataset=torchvision.datasets.ImageFolder(
root, transform=None,
target_transform=None,
loader=<function default_loader>,
is_valid_file=None)
root:图片存储的根目录,即各类别文件夹所在目录的上一级目录。transform:对图片进行预处理的操作(函数),原始图片作为输入,返回一个转换后的图片。target_transform:对图片类别进行预处理的操作,输入为 target,输出对其的转换。 如果不传该参数,即对 target 不做任何转换,返回的顺序索引 0,1, 2…loader:表示数据集加载方式,通常默认加载方式即可。is_valid_file:获取图像文件的路径并检查该文件是否为有效文件的函数(用于检查损坏文件)
返回的dataset都有以下三种属性:
self.classes:用一个 list 保存类别名称self.class_to_idx:类别对应的索引,与不做任何转换返回的 target 对应self.imgs:保存(img-path, class) tuple的 list
运行结果:
{'0_airplane':0, '1_automobile':1}
- 加载数据
dl_train = DataLoader(ds_train,batch_size =50,shuffle =True,num_workers=0)# ds_train表示加载的数据集;batch_size:每批次加载了50个样本;num_workers:加载数据的子进程数有3个
dl_valid = DataLoader(ds_valid,batch_size =50,shuffle =True,num_workers=0)# 验证集的数据加载如上
用到了torch.utils.data.DataLoader
- DataLoader(
dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None)
参数说明:
- dataset (Dataset): 加载数据的数据集
- batch_size (int, optional): 每批加载多少个样本
- shuffle (bool, optional): 设置为“真”时,在每个epoch对数据打乱.(默认:False)
- sampler (Sampler, optional): 定义从数据集中提取样本的策略,返回一个样本
- batch_sampler (Sampler, optional): like sampler, but returns a batch of indices at a time 返回一批样本. 与atch_size, shuffle, sampler和 drop_last互斥.
- num_workers (int, optional): 用于加载数据的子进程数。0表示数据将在主进程中加载。(默认:0)
- collate_fn (callable, optional): 合并样本列表以形成一个 mini-batch. # callable可调用对象
- pin_memory (bool, optional): 如果为 True, 数据加载器会将张量复制到 CUDA 固定内存中,然后再返回它们.
- drop_last (bool, optional): 设定为 True 如果数据集大小不能被批量大小整除的时候, 将丢掉最后一个不完整的batch,(默认:False).
- timeout (numeric, optional): 如果为正值,则为从工作人员收集批次的超时值。应始终是非负的。(默认:0)
- worker_init_fn (callable, optional): If not None, this will be called on each worker subprocess with the worker id (an int in
[0, num_workers - 1]) as input, after seeding and before data loading. (default: None).
这里提供下官方的手册:
- torch.utils.data官方手册
- torch.utils.data官方手册中文翻译
下面准备数据的最后一步,查看上面加载到管道的数据,我们根据文档内容通过循环遍历输出图片:
# %matplotlib inline# %config InlineBackend.figure_format = 'svg'#查看部分样本from matplotlib import pyplot as plt
plt.figure(figsize=(8,8))# 设置图片大小,matplot就不解释了,过于基础for i inrange(9):# 循环遍历9个图片
img,label = ds_train[i]
img = img.permute(1,2,0)
ax=plt.subplot(3,3,i+1)
ax.imshow(img.numpy())
ax.set_title("label = %d"%label.item())
ax.set_xticks([])
ax.set_yticks([])
plt.show()

原始数据集图像和上面加载出来的一致,由于图片像素极低,放大后更低更模糊了。
# Pytorch的图片默认顺序是 Batch,Channel,Width,Heightfor x,y in dl_train:print(x.shape,y.shape)break
注意:这里运行会报错,文档作者不知道是不是会报错,反正我的报错了。已经有博主解决这个问题啦~
原因:datasets.ImageFolder使用了lambda函数,cell4中num_workers被设置为3,这两个因素共同作用导致报错。解决方法:依旧是在jupyter notebook环境中,把num_workers=3改为num_workers=0
输出:
torch.Size([50,3,32,32]) torch.Size([50,1])# 分别表示(batch size:50, channel:3, height:32, width::32)
对torch.Size的理解:
- torch.Size括号中有几个数字就是几维
- 第一层(最外层)中括号里面包含了两个中括号(以逗号进行分割),这就是(2,3,4)中的2 第二层中括号里面包含了三个中括号(以逗号进行分割),这就是(2,3,4)中的3 第三层中括号里面包含了四个数(以逗号进行分割),这就是(2,3,4)中的4

二、 🎉定义模型
使用Pytorch通常有
三种方式
构建
模型
:使用
nn.Sequential
按层顺序构建模型,继承
nn.Module
基类构建自定义模型,继承
nn.Module
基类构建模型并辅助应用模型容器(
nn.Sequential
,
nn.ModuleList
,
nn.ModuleDict
)进行封装。
此处选择通过继承
nn.Module
基类构建自定义模型。
#测试AdaptiveMaxPool2d的效果
pool = nn.AdaptiveAvgPool2d((1,1))# 输出尺寸指定为1*1
t = torch.randn(10,8,32,32)# print(pool(t).shape)
关于nn.AdaptiveMaxPool2d的解释:
- class torch.nn.AdaptiveMaxPool2d(
output_size, return_indices=False)
对输入信号,提供2维的自适应最大池化操作 对于任何输入大小的输入,可以将输出尺寸指定为HW,但是输入和输出特征的数目不会变化。可以用来实现*全局平均最大池化层output_size=1.
output_size: 输出信号的尺寸,可以用(H,W)表示HW的输出,也可以使用数字H表示HH大小的输出return_indices: 如果设置为True,会返回输出的索引。对 nn.MaxUnpool2d有用,默认值是False
关于torch.randn的解释:
- torch.randn(
*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor 返回一个符合均值为0,方差为1的正态分布(标准正态分布)中填充随机数的张量
参数解释:
size(int…)--定义输出张量形状的整数序列。可以是数量可变的参数,也可以是列表或元组之类的集合。
Keyword Arguments:
out(Tensor, optional) --输出张量dtype(torch.dtype, optional) --返回张量所需的数据类型。默认:如果没有,使用全局默认值layout(torch.layout, optional) --返回张量的期望布局。默认值:torch.strideddevice(torch.device, optional) --返回张量的所需 device。默认:如果没有,则使用当前设备作为默认张量类型.(CPU或CUDA)requires_grad(bool, optional) –autograd是否应该记录对返回张量的操作(说明当前量是否需要在计算中保留对应的梯度信息)。默认值:False。
输出结果:
torch.Size([10, 8, 1, 1])
- 模型构建
classNet(nn.Module):def__init__(self):super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3,out_channels=32,kernel_size =3)
self.pool = nn.MaxPool2d(kernel_size =2,stride =2)
self.conv2 = nn.Conv2d(in_channels=32,out_channels=64,kernel_size =5)
self.dropout = nn.Dropout2d(p =0.1)
self.adaptive_pool = nn.AdaptiveMaxPool2d((1,1))
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(64,32)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(32,1)
self.sigmoid = nn.Sigmoid()defforward(self,x):"""
前向传播函数
:param x: 输入,tensor 类型
:return: 返回结果
"""
x = self.conv1(x)
x = self.pool(x)
x = self.conv2(x)
x = self.pool(x)
x = self.dropout(x)
x = self.adaptive_pool(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
y = self.sigmoid(x)return y
net = Net()print(net)
- 输出打印出来构建的整个网络的具体信息,如池化层、优化器、卷积等设置:
Net((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1))(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(conv2): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1))(dropout): Dropout2d(p=0.1, inplace=False)(adaptive_pool): AdaptiveMaxPool2d(output_size=(1, 1))(flatten): Flatten(start_dim=1, end_dim=-1)(linear1): Linear(in_features=64, out_features=32, bias=True)(relu): ReLU()(linear2): Linear(in_features=32, out_features=1, bias=True)(sigmoid): Sigmoid())
一一解释上面构建的网络:
- nn.Conv2d:Conv2d(in_channels, out_channels, kernel_size, stride=1,padding=0, dilation=1, groups=1,bias=True, padding_mode=‘zeros’)
in_channels:输入的通道数目 【必选】out_channels: 输出的通道数目 【必选】kernel_size:卷积核的大小,类型为int或者元组,当卷积是方形的时候,只需要一个整数边长即可,卷积不是方形,要输入一个元组表示 高和宽。【必选】stride:卷积每次滑动的步长为多少,默认是 1 【可选】padding: 设置在所有边界增加 值为 0 的边距的大小(也就是在feature map外围增加几圈 0 ),例如当 padding =1 的时候,如果原来大小为 3 × 3 ,那么之后的大小为 5 × 5 。即在外围加了一圈0 。【可选】dilation:控制卷积核之间的间距【可选】groups:控制输入和输出之间的连接。(不常用)【可选】bias: 是否将一个 学习到的 bias 增加输出中,默认是 True 。【可选】padding_mode: 字符串类型,接收的字符串只有 “zeros” 和 “circular”。【可选】注意 :参数 kernel_size,stride,padding,dilation 都可以是一个整数或者是一个元组,一个值的情况将会同时作用于高和宽 两个维度,两个值的元组情况代表分别作用于 高 和 宽 维度。
nn.MaxPool2d:
class torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
参数解释:
kernel_size:表示做最大池化的窗口大小,可以是单个值,也可以是tuple元组stride:步长,可以是单个值,也可以是tuple元组padding:填充,可以是单个值,也可以是tuple元组dilation:控制窗口中元素步幅return_indices:布尔类型,返回最大值位置索引ceil_mode:布尔类型,为True,用向上取整的方法,计算输出形状;默认是向下取整。
具体参数的详解在:这里
也可在官方文档内查询。
nn.Dropout2d:为了防止或减轻过拟合而使用的函数,它一般用在全连接层
Dropout就是在不同的训练过程中随机扔掉一部分神经元。也就是让某个神经元的激活值以一定的概率p,让其停止工作,这次训练过程中不更新权值,也不参加神经网络的计算。但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了。Dropout常常用于抑制过拟合,pytorch也提供了很方便的函数。但是经常不知道dropout的参数p是什么意思。在TensorFlow中p叫做keep_prob,就一直以为pytorch中的p应该就是保留节点数的比例,但是实验结果发现反了,实际上表示的是不保留节点数的比例。
- nn.AdaptiveMaxPool2d:
class torch.nn.AdaptiveMaxPool2d(output_size, return_indices=False)
对输入信号,提供2维的自适应最大池化操作 对于任何输入大小的输入,可以将输出尺寸指定为H*W,但是输入和输出特征的数目不会变化。可以用来实现全局平均最大池化层output_size=1.
参数:
output_size: 输出信号的尺寸,可以用(H,W)表示HW的输出,也可以使用数字H表示HH大小的输出return_indices: 如果设置为True,会返回输出的索引。对nn.MaxUnpool2d有用,默认值是False
nn.Flatten():
torch.nn.Flatten(),因为其被用在神经网络中,输入为一批数据,第一维为batch,通常要把一个数据拉成一维,而不是将一批数据拉为一维。所以torch.nn.Flatten()默认从第二维开始平坦化。
- nn.Linear:
torch.nn.Linear(in_features, out_features, bias=True)
nn.Linear()是用于设置网络中的全连接层的,需要注意在二维图像处理的任务中,全连接层的输入与输出一般都设置为二维张量,形状通常为[batch_size, size],不同于卷积层要求输入输出是四维张量。
参数:
in_features指的是输入的二维张量的大小,即输入的[batch_size, size]中的size。out_features指的是输出的二维张量的大小,即输出的二维张量的形状为[batch_size,output_size],当然,它也代表了该全连接层的神经元个数。
从输入输出的张量的shape角度来理解,相当于一个输入为
[batch_size, in_features]
的张量变换成了
[batch_size, out_features]
的输出张量。
- nn.ReLU:
class torch.nn.ReLU(inplace: bool = False)
线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元。其定义如下图,在横坐标的右侧,ReLU函数为线性函数。在横坐标的右侧,ReLU函数为值为0。
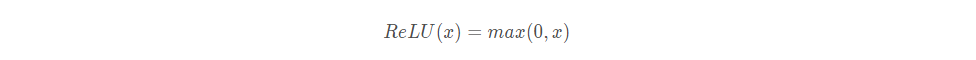
参数:
inplace=True:inplace为True,将会改变输入的数据,否则不会改变原输入,只会产生新的输出
- nn.Sigmoid:

import torchkeras
torchkeras.summary(net,input_shape=(3,32,32))
输出:
----------------------------------------------------------------
Layer (type) Output Shape Param #================================================================
Conv2d-1[-1,32,30,30]896
MaxPool2d-2[-1,32,15,15]0
Conv2d-3[-1,64,11,11]51,264
MaxPool2d-4[-1,64,5,5]0
Dropout2d-5[-1,64,5,5]0
AdaptiveMaxPool2d-6[-1,64,1,1]0
Flatten-7[-1,64]0
Linear-8[-1,32]2,080
ReLU-9[-1,32]0
Linear-10[-1,1]33
Sigmoid-11[-1,1]0================================================================
Total params:54,273
Trainable params:54,273
Non-trainable params:0----------------------------------------------------------------
Input size (MB):0.011719
Forward/backward pass size (MB):0.359634
Params size (MB):0.207035
Estimated Total Size (MB):0.578388----------------------------------------------------------------
Process finished with exit code 0
torchkeras.summary:打印显示网络结构和参数
打印出来配置的网络参数
三、🎉训练模型
Pytorch通常需要用户编写
自定义训练循环
,训练循环的代码风格因人而异。
有3类典型的训练循环代码风格:
脚本形式训练循环
,
函数形式训练循环
,
类形式训练循环
。
此处介绍一种较通用的
函数形式训练循环
。
和之前的训练模型的循环方式类似
import pandas as pd
from sklearn.metrics import roc_auc_score
model = net
model.optimizer = torch.optim.SGD(model.parameters(),lr =0.01)# 优化器配置:SGD随机梯度下降法
model.loss_func = torch.nn.BCELoss()# 构建损失函数
model.metric_func =lambda y_pred,y_true: roc_auc_score(y_true.data.numpy(),y_pred.data.numpy())# roc_auc_score:求随机森林的AUC值
model.metric_name ="auc"
from sklearn.metrics import roc_auc_score
直接根据真实值(必须是二值)、预测值(可以是0/1,也可以是proba值)计算出auc值,中间过程的roc计算省略。
函数形式训练循环
:
deftrain_step(model,features,labels):# 训练模式,dropout层发生作用
model.train()# 梯度清零
model.optimizer.zero_grad()# 正向传播求损失
predictions = model(features)
loss = model.loss_func(predictions,labels)
metric = model.metric_func(predictions,labels)# 反向传播求梯度
loss.backward()
model.optimizer.step()return loss.item(),metric.item()defvalid_step(model,features,labels):# 预测模式,dropout层不发生作用
model.eval()# 关闭梯度计算with torch.no_grad():
predictions = model(features)
loss = model.loss_func(predictions,labels)
metric = model.metric_func(predictions,labels)return loss.item(), metric.item()# 测试train_step效果
features,labels =next(iter(dl_train))print(train_step(model, features, labels))
结果:
(0.6913514733314514,0.5057471264367817)
训练模型:
deftrain_model(model,epochs,dl_train,dl_valid,log_step_freq):
metric_name = model.metric_name
dfhistory = pd.DataFrame(columns =["epoch","loss",metric_name,"val_loss","val_"+metric_name])print("Start Training...")
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')print("=========="*8+"%s"%nowtime)for epoch inrange(1,epochs+1):# 1,训练循环-------------------------------------------------
loss_sum =0.0
metric_sum =0.0
step =1for step,(features,labels)inenumerate(dl_train,1):
loss,metric = train_step(model,features,labels)# 打印batch级别日志
loss_sum += loss
metric_sum += metric
if step%log_step_freq ==0:print(("[step = %d] loss: %.3f, "+metric_name+": %.3f")%(step, loss_sum/step, metric_sum/step))# 2,验证循环-------------------------------------------------
val_loss_sum =0.0
val_metric_sum =0.0
val_step =1for val_step,(features,labels)inenumerate(dl_valid,1):
val_loss,val_metric = valid_step(model,features,labels)
val_loss_sum += val_loss
val_metric_sum += val_metric
# 3,记录日志-------------------------------------------------
info =(epoch, loss_sum/step, metric_sum/step,
val_loss_sum/val_step, val_metric_sum/val_step)
dfhistory.loc[epoch-1]= info
# 打印epoch级别日志print(("\nEPOCH = %d, loss = %.3f,"+ metric_name + \
" = %.3f, val_loss = %.3f, "+"val_"+ metric_name+" = %.3f")%info)
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')print("\n"+"=========="*8+"%s"%nowtime)print('Finished Training...')return dfhistory
epochs =20
dfhistory = train_model(model,epochs,dl_train,dl_valid,log_step_freq =50)
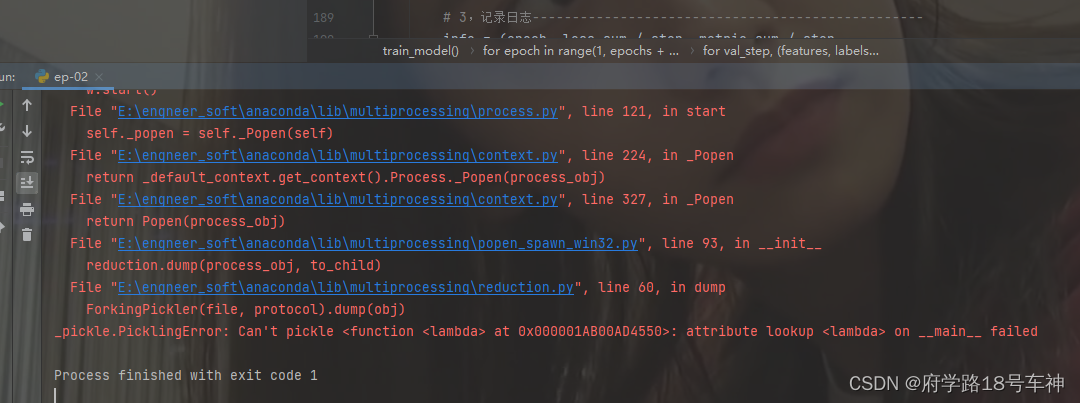
注意:这里还是会报错,和Day01的一样,只需将
num_workers=3改为
num_workers=0即可。如下位置,修改。

测试结果:
迭代20个epoch,需要等待几分钟。
Start Training...================================================================================2022-04-1021:26:09[step =50] loss:0.690, auc:0.633[step =100] loss:0.688, auc:0.665[step =150] loss:0.686, auc:0.688[step =200] loss:0.684, auc:0.703
EPOCH =1, loss =0.684,auc =0.703, val_loss =0.673, val_auc =0.825================================================================================2022-04-1021:26:23[step =50] loss:0.672, auc:0.773[step =100] loss:0.669, auc:0.772[step =150] loss:0.665, auc:0.774[step =200] loss:0.660, auc:0.776
EPOCH =2, loss =0.660,auc =0.776, val_loss =0.632, val_auc =0.831================================================================================2022-04-1021:26:33[step =50] loss:0.631, auc:0.785[step =100] loss:0.624, auc:0.789[step =150] loss:0.616, auc:0.792[step =200] loss:0.608, auc:0.795
EPOCH =3, loss =0.608,auc =0.795, val_loss =0.559, val_auc =0.835......[step =50] loss:0.401, auc:0.913[step =100] loss:0.399, auc:0.915[step =150] loss:0.394, auc:0.916[step =200] loss:0.393, auc:0.917
EPOCH =18, loss =0.393,auc =0.917, val_loss =0.361, val_auc =0.930================================================================================2022-04-1021:29:10[step =50] loss:0.388, auc:0.932[step =100] loss:0.387, auc:0.926[step =150] loss:0.387, auc:0.924[step =200] loss:0.385, auc:0.924
EPOCH =19, loss =0.385,auc =0.924, val_loss =0.332, val_auc =0.935================================================================================2022-04-1021:29:20[step =50] loss:0.420, auc:0.919[step =100] loss:0.393, auc:0.923[step =150] loss:0.384, auc:0.924[step =200] loss:0.382, auc:0.927
EPOCH =20, loss =0.382,auc =0.927, val_loss =0.343, val_auc =0.938================================================================================2022-04-1021:29:29
Finished Training...
Process finished with exit code 0
简单小节一下,通过day01的标准流程,基本大体思路还是了解了,模型训练好后,后期就验证、评估、应用了。重点还是在本小节的模型构建和训练。建议自己写一遍,模仿循环的写法,能够自己掌握最后。加油
四、🎉评估模型
查看迭代的结果:
print(dfhistory)
结果显示:
epoch loss auc val_loss val_auc
01.00.6871990.6898930.6779730.81923112.00.6709370.7870230.6551240.82695723.00.6391570.7976400.6050080.82374634.00.5841200.8002660.5395340.82845545.00.5415840.8082710.5081390.83728556.00.5208960.8192900.4901450.84694867.00.5119960.8250610.4831560.85285678.00.5022650.8331390.4700600.86068689.00.4961000.8389610.4619130.867318910.00.4875180.8457590.4577400.8701741011.00.4815990.8537480.4444330.8767841112.00.4708090.8606110.4361020.8861811213.00.4596030.8673600.4307470.8922511314.00.4511450.8765190.4380980.8974831415.00.4381030.8852330.4026680.9031181516.00.4286770.8963890.4594900.9086231617.00.4188700.9029350.3757930.9182691718.00.4200090.9091870.3594110.9250131819.00.4051860.9138220.3456650.9296641920.00.3939560.9216990.3357960.938696
可视化部分:
# %matplotlib inline# %config InlineBackend.figure_format = 'svg'import matplotlib.pyplot as plt
defplot_metric(dfhistory, metric):
train_metrics = dfhistory[metric]
val_metrics = dfhistory['val_'+metric]
epochs =range(1,len(train_metrics)+1)
plt.plot(epochs, train_metrics,'bo--')
plt.plot(epochs, val_metrics,'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric,'val_'+metric])
plt.show()
plot_metric(dfhistory,"loss")
结果: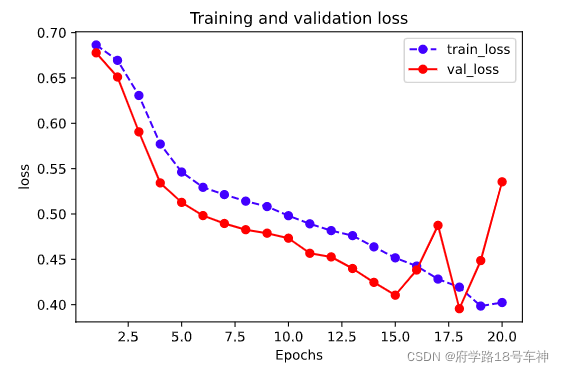
plot_metric(dfhistory,"auc")
结果: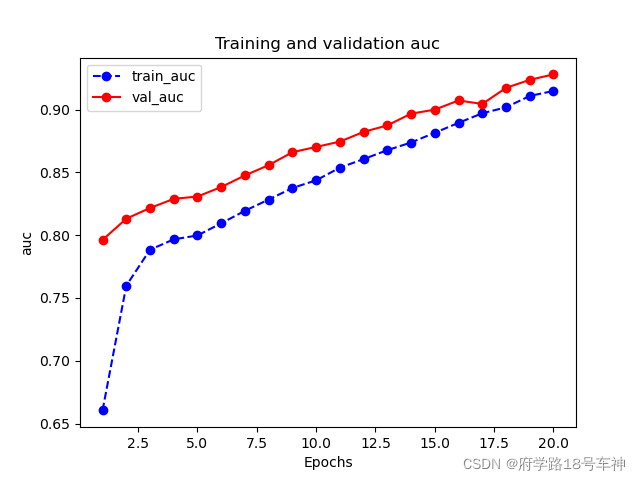
模型训练完后,迭代次数越多精确度越高。从上上图中,在epoch=16~18的时候,验证集的损失值呈现震荡,或许陷入了局部最优,又导致了跳出最优后面epoch=20,loss又上升了。
五、🎉使用模型
模型预测的应用
defpredict(model,dl):
model.eval()with torch.no_grad():
result = torch.cat([model.forward(t[0])for t in dl])return(result.data)
#预测概率
y_pred_probs = predict(model,dl_valid)print(y_pred_probs)
预测的结果:
tensor([[0.3127],[0.0375],[0.1940],...,[0.6114],[0.2975],[0.9395]])
预测类别:
#预测类别
y_pred = torch.where(y_pred_probs>0.5,
torch.ones_like(y_pred_probs),torch.zeros_like(y_pred_probs))print(y_pred)
预测的结果:
tensor([[0.],[0.],[0.],...,[1.],[0.],[1.]])
torch.cat:是将两个张量(tensor)拼接在一起,cat是concatenate的意思,即拼接,联系在一起。torch.ones_like函数和torch.zeros_like函数的基本功能是根据给定张量,生成与其形状相同的全1张量或全0张量.
图片的预测和之前的结构化数据模型有区别,
torch.cat和
torch.ones_like、
torch.zeros_like的操作得熟记。
六、🎉保存模型
在Day01的最后提到了两种模型保存的方式,后面应该也只选择了一种方式。那咱们就记住了哈~
- 推荐使用
保存参数方式保存Pytorch模型。
print(model.state_dict().keys())
输出显示:
odict_keys(['conv1.weight','conv1.bias','conv2.weight','conv2.bias','linear1.weight','linear1.bias','linear2.weight','linear2.bias'])
保存模型的代码:
# 保存模型参数
torch.save(model.state_dict(),"./data/model_parameter.pkl")
net_clone = Net()
net_clone.load_state_dict(torch.load("./data/model_parameter.pkl"))
predict(net_clone,dl_valid)
提醒记牢,建议自己多写,这样记忆深刻。
保存结果:
tensor([[0.0204],[0.7692],[0.4967],...,[0.6078],[0.7182],[0.8251]])
第二期就到这里吧,慢中出细活,多看多练,多理解其中的原理,不做
屌爆侠
(调包侠),加油~
😊Reference
- https://github.com/lyhue1991/eat_pytorch_in_20_days
- https://blog.csdn.net/u013230291/article/details/108487877
- https://blog.csdn.net/qq_33590958/article/details/102602029
- https://blog.csdn.net/weixin_43135178/article/details/115139178
- https://blog.csdn.net/tsq292978891/article/details/79414512
- https://pytorch.org/docs/0.3.1/data.html
- https://pytorch.apachecn.org/#/
- https://blog.csdn.net/weixin_42802447/article/details/118394274
- https://blog.csdn.net/qq_24503095/article/details/103683403
- https://blog.csdn.net/qq_42119367/article/details/110004734
- https://blog.csdn.net/qq_38863413/article/details/104108808
- https://blog.csdn.net/weixin_43135178/article/details/115495220
- https://blog.csdn.net/qq_24503095/article/details/103683403
- https://blog.csdn.net/qq_42079689/article/details/102873766
- https://blog.csdn.net/weixin_42495721/article/details/111518564
- https://blog.csdn.net/qq_39938666/article/details/88809726
书籍源码在此:
链接:https://pan.baidu.com/s/1P3WRVTYMpv1DUiK-y9FG3A
提取码:yyds
❤坚持读Paper,坚持做笔记,坚持学习,坚持刷力扣LeetCode❤!!!
坚持刷题!!!
⚡To Be No.1⚡⚡哈哈哈****哈
⚡创作不易⚡,过路能❤关注、收藏、点个赞❤三连就最好不过了
ღ( ´・ᴗ・` )
❤
版权归原作者 府学路18号车神 所有, 如有侵权,请联系我们删除。