
更多优秀文章借鉴:
使用Selenium实现黑马头条滑块自动登录
使用多线程采集爬取豆瓣top250电影榜
使用Scrapy爬取去哪儿网游记数据
数据采集技术综合项目实战1:国家水稻网数据采集与分析
数据采集技术综合项目实战2:某东苹果15数据采集与分析
数据采集技术综合案例实战3:b站弹幕采集与分析
项目介绍及需求:
本项目主要是通过对b站电影弹幕进行采集并分析。1.获得弹幕高频词生成符合该电影特征、主题、角色等相关字段的词云图,通过词云图的方式对某部电影主题具体化。2.获取用户年内评论发布时间观生成时间的折线图,以便从侧面观察该电影在不同的年播放量。3.获取年内周内评论发布时间生成时间的折线图,以便观察每周用户的生活特性。
数据采集部分:
目标网址:【动画/奇幻】西游记之大圣归来(2015)_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1vs411d7eJ/?spm_id_from=333.337.search-card.all.click&vd_source=6ad54d82286ed98cdb21f8eb15b8df5f
爬虫思路分析:
1.确定采集目标:爬取“大圣归来”的弹幕包括用户、弹幕发布时间、弹幕具体内容、出现时间点、弹幕池、颜色等字段,如下图所示:

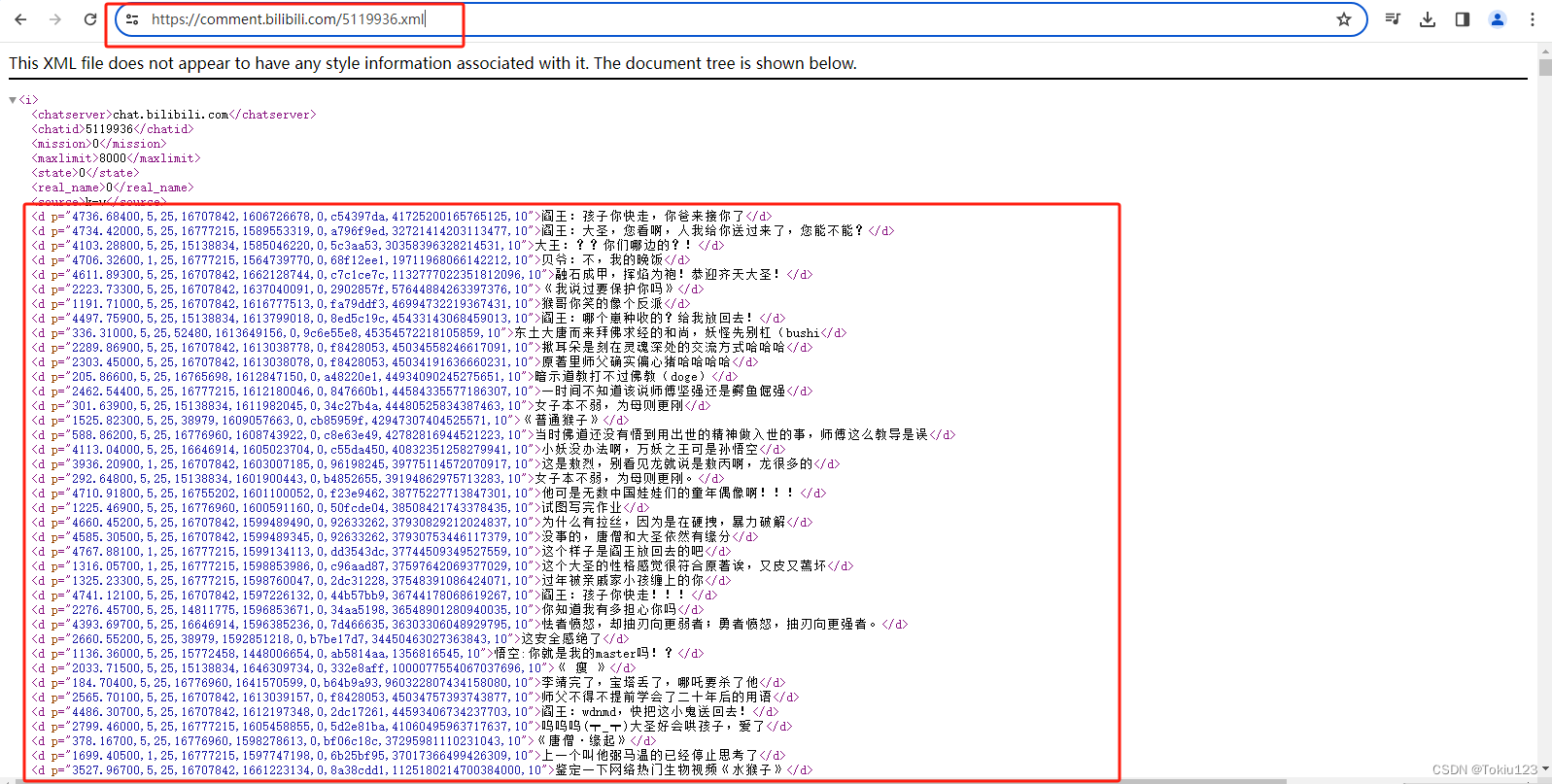
2.查看评论来源:打开网页源代码,按住“Ctrl+F”搜索相应评论,发现并无相关对应信息;但通过百度发现,B站的弹幕数据文件的url为“固定的url地址+视频的cid+.xml”。这里为:https://comment.bilibili.com/5119936.xml

在浏览器中对的步骤二获得的网址文件发起请求,如下图所示:
3.确定采集技术:由步骤二可见,每一个d标签内存储着每一条评论的具体信息,包括弹幕具体内容、出现时间点、用户ID等相关字段;这里直接使用BeautifulSoup解析方式直接对d标签中的内容进行采集(可有效减少代码量)。
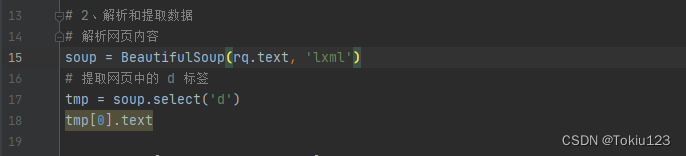
解析后如下图所示:

分割数据:又步骤3可得,解析后得到的d标签内的p数据是字符串类型,这里(因为是用逗号分隔)则直接使用字符串的spilt方法对逗号进行分隔。
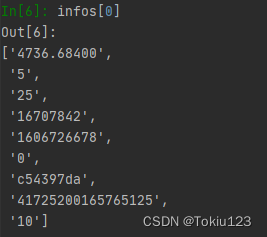
然后定义数据框,将分割后的内容放入数据框中。

5.控制台输出拼接完后的数据框信息,如下图所示:
输出数据框内数据:

通过data.to_csv ('file_name.csv', encoding='')语句即可将数据框保存为csv文件;如下图所示:

数据预处理部分:
预处理思路分析:
1.转变标准时间:先使用了apply函数和lambda函数来实现每个时间戳转换为对应的日期时间格式,并将转换后的日期时间以'%Y-%m-%d %H:%M:%S'的格式表示转换通过再通过pands库的to_datetime方法将发送时间进行转化,转化结果如下图所示(左边:转化前,右边:转化后):

结果演示:
原数据格式:
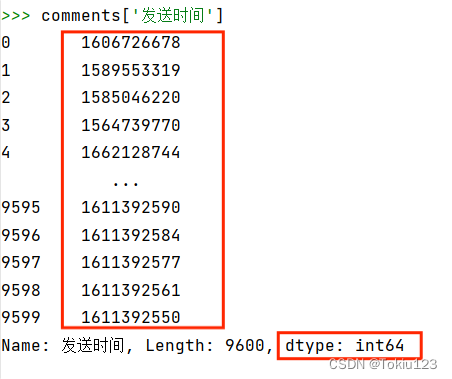
将时间戳转化为日期时间格式(此时为字符串):
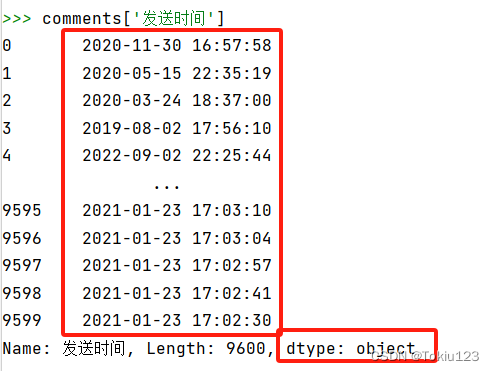
将日期时间格式转化为标准时间:
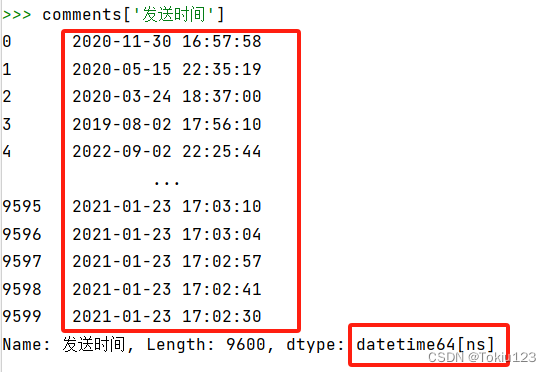
2.数据探究:观察列表框内相关数据:通过value_counts()方法来查看该列中的元素出现了几次,通过shape()方法即可观察数据框剩余几行数据;通过columns()方法可看出清洗后的数据框的列索引。
数据可视化部分:
(1)根据评论分词出现频率生成词云图:
1.分词:导入jieba库,将拼接后的comment.csv文件进行读取,再对data_all中的content列中的每个文本进行分词操作,使用jieba.lcut函数对文本进行切词。
import pandas as pd
import jieba
from tkinter import _flatten
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from PIL import Image
import numpy
# 数据读取
comments = pd.read_csv('comment.csv',encoding='utf8')
# (1)分词
comment_cut = comments['comment'].apply(jieba.lcut)
2.去除停用词:读取名为stopword.txt的停用词文件,将文件中的停用词加载到stop_list列表中,然后将额外的词语'哈哈哈' 、 '哈哈哈哈' 、 ' ' 、 '呜呜' 、 '啊啊啊'等词添加到stop_list列表中。接着,对经过分词后的文本数据进行停用词过滤,去除stop_list中的词语。
# (2)去除停用词
with open('stopword.txt', encoding = 'utf-8' ) as f:
stop_list = f.read()
# 扩充停用词表
stop_list = stop_list + '哈哈哈' + '哈哈哈哈' + ' ' + '呜呜' + '啊啊啊'
comment_after = comment_cut.apply(lambda x:[i for i in x if i not in stop_list])
3.统计词频:将经过停用词过滤后的文本数据转换为一个包含所有词语的列表words,然后使用pd.Series(words).value_counts()方法统计每个词语出现的频率,得到词频统计结果。
# (3)统计词频
word = _flatten(list(comment_after))
word_freq = pd.Series(word).value_counts()
print(word_freq)
4.生成词云图:根据本机内文字字体路径确定生成词云图的文字字体(font_path)、自定义背景图、背景颜色;若未定义文字字体这一步将导致生成图形的文字无法看见,最后通过to_file()方法保存词云图即可。
# (4)词云图的绘制
# 获取词云图背景轮廓
mask = numpy.array(Image.open("p1.png"))
# 创建词云图对象
wc = WordCloud(font_path = "C:/Windows/Fonts/msyh.ttc", mask=mask, background_color='white')
wc.fit_words(word_freq)
plt.imshow(wc)
plt.axis("off")
plt.show()
# 保存生成的词云图
wc.to_file('词云图.png')
结果演示:

结论:由图可得该电影的受众者主要是来自观看西游记被孙悟空的优秀品质所“征服”的粉丝,从词云上即可看出观众的热情高涨!一致好评!
(2)生成弹幕发布数量随日期变化折线图
1.设置绘图参数:字体。
import matplotlib as mpl
mpl.use('TkAgg')
# 设置绘图属性
plt.rcParams['font.sans-serif'] = 'SimHei'
2.将在数据预处理部分的步骤1转化得到的标准时间‘发送时间’通过num = comments['发送时间'].dt.date.value_counts().sort_index()方法得到日期部分(去除时间部分),然后使用value_counts()函数对日期进行计数,得到每个日期出现的次数求和并排序赋值给num。
# 它使用dt.date将时间戳转换为日期部分(去除时间部分),然后使用value_counts()函数对日期进行计数,得到每个日期出现的次数
# 其中索引是日期,值是该日期出现的次数
num = comments['发送时间'].dt.date.value_counts().sort_index()
3.使用‘gglot’的绘图风格,使用matplotlib.pyplot的plot方法建立折线图,横坐标为num的索引(即日期在排序后的位置),纵坐标为num中对应日期出现的次数。
plt.style.use('ggplot')
plt.figure(figsize=(16, 9))
# 绘制折线图,横坐标为num的索引(即日期在排序后的位置),纵坐标为num中对应日期出现的次数。
plt.plot(range(len(num)), num)
4.最后使用matplotlib.pyplot的xticks方法设置x轴刻度标签、标题、倾斜度等。
# 取横坐标的每隔21个数据点的位置作为刻度
plt.xticks(range(len(num))[::21], num.index[::21], rotation = 40)
plt.ylabel('弹幕数量')
plt.title('弹幕发布数量随日期变化图')
plt.show()
结果演示:
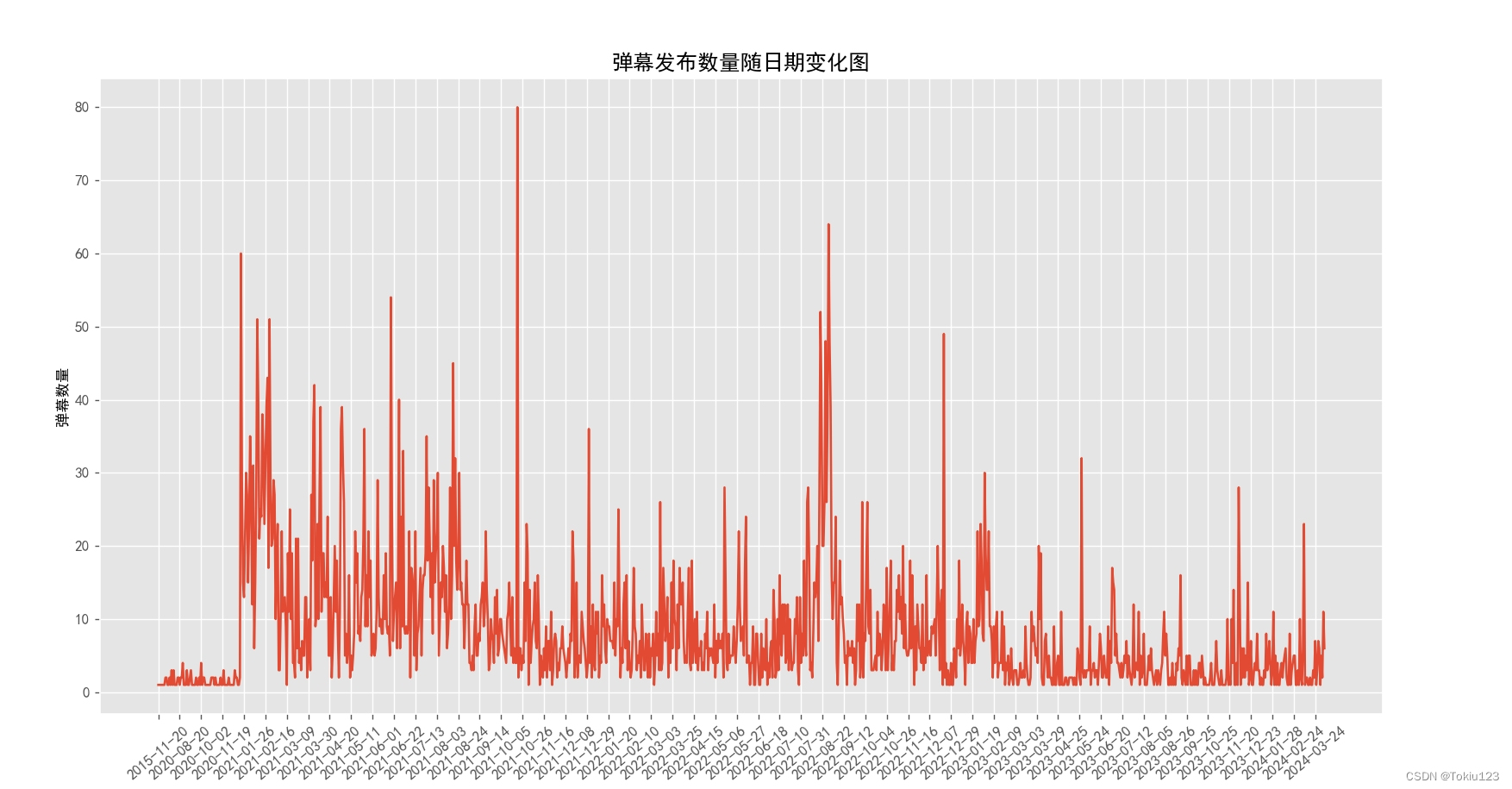
结论:由图可得:该电影于2021年10月05日弹幕评论出现高峰点,大多数观众于该日对6年前的电影进行回味。
(3)生成弹幕发布数量周内发布****折线图
1.与(2)中步骤1、2一致,唯一不同的是此处使用dt.dayofweek方法将发送时间列的时间戳转换为日期时间格式,并提取出日期部分转换为对应的星期几(用中文表示)。然后再将获得的星期几以顺序排好。
# 将发送时间列的时间戳转换为日期时间格式,并提取出日期部分
# 将日期转换为对应的星期几(用中文表示),并统计每个星期几的评论数量。
num = comments['发送时间'].dt.dayofweek.map({0:"周一", 1:"周二", 2:"周三", 3:"周四", 4:"周五", 5:"周六", 6:"周日"}).value_counts()
# 将获得的时间按顺序排好
num = num[['周一', '周二', '周三', '周四', '周五', '周六', '周日']]
2.与(2)中的步骤3一致,可举一反三。
结果演示:
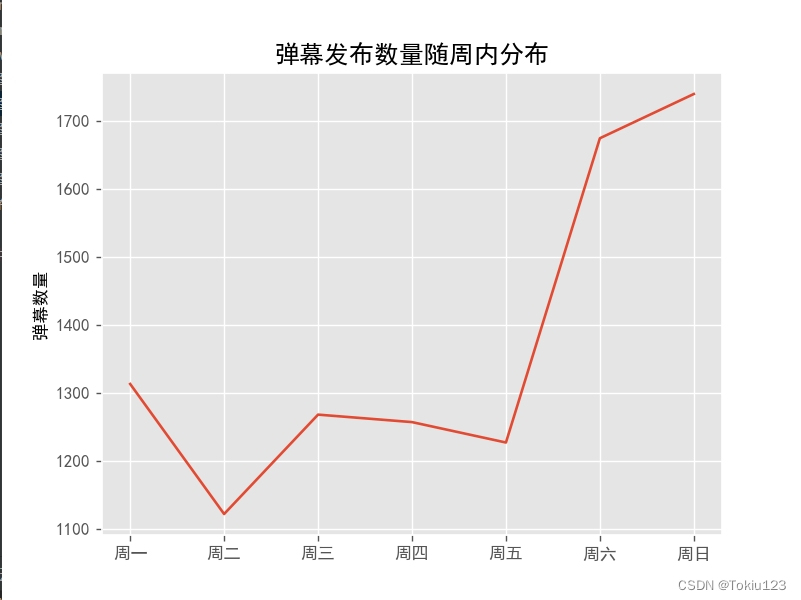
结论:由图可知,大多数观众与周日会选择以观看电影的方式来缓解一周的工作压力。
注意:因文章篇幅问题,部分源代码以及用户发表评论分布图、随播放时间评论发布图等无法展现,如有需要,请在后台私信博主哦~
创作不易,请点个赞哦~
还有更多优秀作品在博主主页~
版权归原作者 Tokiu123 所有, 如有侵权,请联系我们删除。