

为了更好地理解神经网络如何解决现实世界中的问题,同时也为了熟悉 TensorFlow 的 API,本篇我们将会做一个有关如何训练神经网络的练习,并以此为例,训练一个类似的神经网络。
我们即将看到的神经网络,是一个预训练好的用于对手写体数字(整数)图像进行识别的神经网络,它使用了 MNIST 数据集(http://yann.lecun.com/exdb/mnist/),这是一个经常被用于研究模式识别任务的经典的数据集。
01、MNIST 数据集
Modifiled National Institute of Standards and Technology(MNIST)数据集包含 6 万张图像的训练集和 1 万张图像的测试集。每个图像是一个手写体的数字。来自美国政府所提供数据的 MNIST 数据集,最初是用来测试计算机系统识别手写字体方法的。如果计算机能成功识别手写体,这将对提高邮政服务和税收系统以及政府服务的效率,具有重大意义。在当前的研究中,也有一些不同的、更新的数据集(如 CIFAR 数据集)。但是,用 MNIST 数据集来理解神经网络的工作原理仍然是非常有用的,因为使用它,已知模型可达到很高的精确度和效率。
▍CIFAR 数据集是一个机器学习数据集,包含不同类别的图像。与 MNIST 数据集不同的是,CIFAR 数据集包含许多不同领域的类,比如动物、活动和对象。CIFAR 数据集可在https://www.cs.toronto.edu/~kriz/cifar.html下载。

▍摘自 MNIST 数据集的训练集图像。每个图像是一个单独的 20×20 像素的手写数字图像,原始数据集可以在
http://yann.lecun.com/exdb/mnist/找到
02、用 TensorFlow 训练神经网络
现在,让我们用 MNIST 数据集训练一个神经网络,并识别新的数字。
在这个手写体识别的问题上,我们用一个特殊的神经网络——“卷积神经网络”——来解决。我们的神经网络包含三个隐藏层:两个全连接层和一个卷积层。卷积层被以下基于 Python 语言的 TensorFlow 代码段所定义,详见代码段 1。
W = tf.Variable(
tf.truncated_normal([5, 5, size_in, size_out],
stddev=0.1),
name="Weights")
B = tf.Variable(tf.constant(0.1, shape=[size_out]),
name="Biases")
convolution = tf.nn.conv2d(input, W, strides=[1, 1, 1, 1],
padding="SAME")
activation = tf.nn.relu(convolution + B)
tf.nn.max_pool(
activation,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
在神经网络训练期间,只需执行一次代码段。
变量 W 和 B 代表权重(weights)和偏差(biases)。这些变量是在隐藏层节点中使用的,用于在数据通过神经网络时,更改神经网络对数据的解释。神经网络中还包含其他变量,但是现在暂时不用考虑这些。
全连接层被以下 Python 代码段所定义,详见代码段 2。
W = tf.Variable(
tf.truncated_normal([size_in, size_out], stddev=0.1),
name="Weights")
B = tf.Variable(tf.constant(0.1, shape=[size_out]),
name="Biases")
activation = tf.matmul(input, W) + B
这里依然有 TensorFlow 的两个变量:权重 W 和偏移量 B。可注意到,这些变量的初始化非常简单:权重 W 被初始化为随机值,这个初始化是被来自标准差(standard deviation)为 0.1 的被剪枝的高斯分布(使用 size_in 和 size_out 进行剪枝)来完成的;而偏移量 B 则被初始化为常数 0.1。这两个值会随着每次运行而被更改。该代码片段被执行了两次,产生两个全连接层——其中的一个将数据传递给另一个。
这 11 行 Python 代码代表了一个完整的神经网络。我们将使用 Keras 来对每个组件的模型架构进行详细讨论。现在,重点是了解神经网络在每次运行时每个层中的 W 和 B 的值是如何改变的,以及这些代码段如何形成不同的神经层。这 11 行的代码也是几十年神经网络研究成果的积累。
让我们来开始训练这个网络,并且来评估它再 MNIST 手写体数据集中的表现如何。
03、训练神经网络
按照以下步骤来搭建该练习的相关环境:
1.打开两个终端实例(instance)。
2.分别进入到 chapter_4/activity_2[1]目录。
3.在这两个 instance 中,确保您的 Python 3 虚拟环境处于激活状态,并确认已经安装 requirements.txt 中所列举的所有安装包。
4.在其中一个 instance 中,使用如下命令启动 TensorBoard:
$ tensorboard--logdir=mnist_example/
5.在另一个 instance 中,从相应路径下,运行 mnist.py 脚本。
6.打开服务。打开浏览器,在 TensorBoard 提供的 URL(及端口)中,打开页面。
在运行脚本 mnist.py 的终端中,您将看到一个进度条,其中包含了模型在不同时期的训练情况。打开浏览器页面时,您将看到一些图表,点击读取 Accuracy(准确率)的那个,放大它,让页面刷新(或者点击 refresh 按钮刷新)。随着训练次数的增加,您会看到随着迭代次数的增加,这个模型的准确率会越来越高。
这可以解释神经网络在训练过程中能够很早达到高准确度的能力。
我们可以看到,在大约第 200 个 epochs(或迭代步数 steps)时,神经网络的准确率超过了 90%。也就是说,网络可以正确地预测测试集中 90%的手写数字。在训练到第 2000 步的时候,该网络的准确率不断提高,在这一阶段结束时达到了 97%的准确率。
现在让我们来测试一下这个网络在对于从未使用过的数据表现如何。我们使用 Shafeen Tejani 创建的开源网络应用程序来测试一下这个神经网络是否能够正确识别出我们自己写的手写数字。
04、用未见数据测试神经网络的性能
在浏览器中访问http://mnist-demo.herokuapp.com/,然后我们可以在指定的白色方格中画一个 0 到 9 之间的数字(如下图所示)。
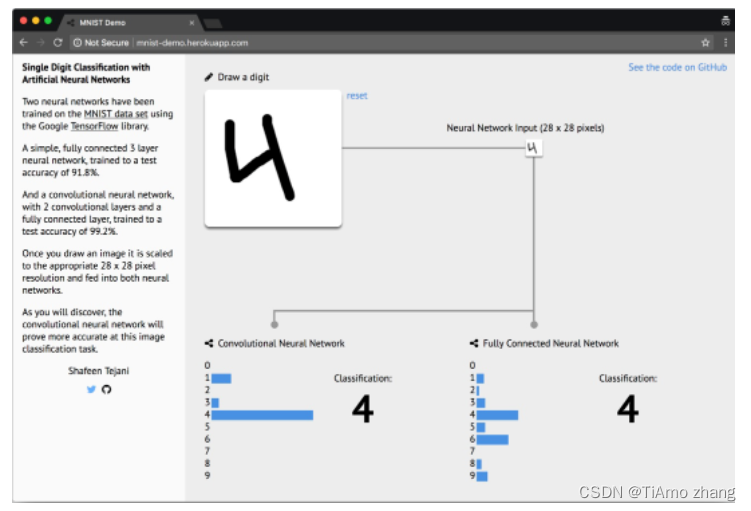
▍可以手绘数字并可测试神经网络准确性的 Web 应用程序
▍上述应用程序:
https://github.com/ShafeenTejani/mnist-demo .
在该应用程序中,您可以看到两个神经网络的实验结果。我们训练的那个神经网络(称为卷积神经网络 CNN)位于左侧。看看它能否识别您手写的数字?试着在指定区域的边缘画出数字。例如,试着把数字 1 画在那个区域的右边,如下图所示。
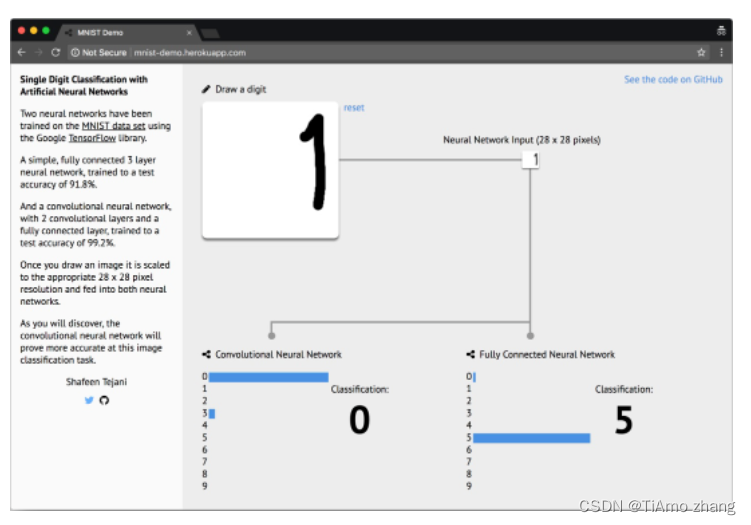
▍两个神经网络都很难估计区域边缘的值
▍在本例中,我们看到数字 1 绘制在绘图区域的右侧。这个绘在边缘的数字,两个网络都没识别出来它应该是 1。
MNIST 数据集中不包含写在边缘的数字图像。由于没有包含处于区域边缘的训练数据,因此这两个神经网络都无法正确识别边缘处的数字。如果我们把手写数字写到更靠近指定区域的中心,那么这两个神经网络的识别效果能够得到一定的改善,这说明神经网络的性能依赖于训练数据。如果用于训练的数据与用于测试的数据差异很大,那么神经网络很可能会出现令人失望的结果。
05、实例:探索一个训练好的神经网络
下面将探索刚才在练习中训练的神经网络。我们还会通过改变超参数来训练一些其他的神经网络。那么就让我们从练习中训练的神经网络开始吧。
让我们用 TensorBoard 打开神经网络,来了解神经网络的组成。
打开终端,chapter_4/activity_2 目录下,执行以下指令
$ tensorboard --logdir=mnist_examle/
启动 TensorBoard(如下图所示):
▍启动 TensorBoard 实例后的终端显示
现在,在浏览器中打开 TensorBoard 提供的 URL。您应该能够看到 TensorBoard 标量页面。
通过 TensorBoard 命令提供的 URL,打开对应的页面,可以看到如下图所示的 TensorBoard 界面:
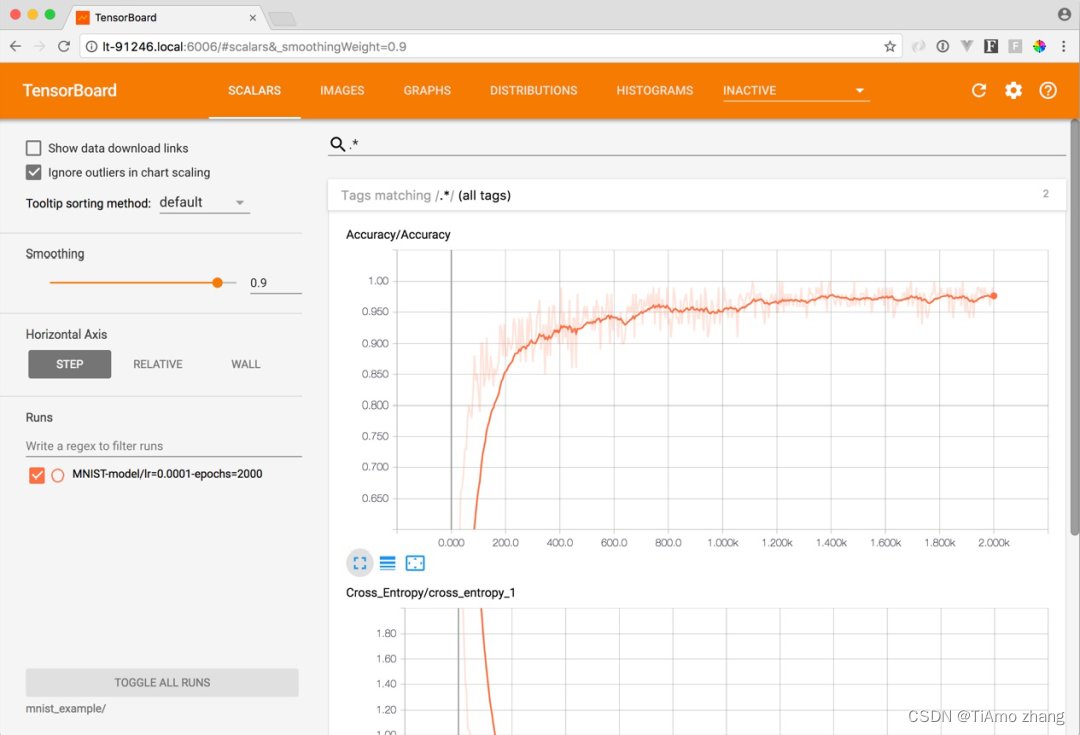
▍TensorBoard 登录页面
现在让我们来深入了解这个已经训练好的神经网络,看看它是如何工作的。
在 TensorBoard 页面上,点击 Scalars 页,将 Accuracy 图放大。然后把 Smoothing 进度条移动到 0.9。
准确率图(accuracy graph)衡量了神经网络对测试集标签的预测准确率。起初,神经网络对于数据的预测几乎全部错误。这是因为我们只是用随机值初始化了神经网络的权值和偏差,所以其预测尝试只是大致的猜测。然后,神经网络在第二次运行时,会更新其神经层的权重(weights)和偏差(biases);神经网络将继续通过改变其权重和偏差来使每个节点能更好地预测数据,而对于那些对预测造成损失的节点,则会通过惩罚项[1]逐渐减少其对神经网络的影响(最终达到 0)。通过这种方式来一步一步地降低损失,提升神经网络的准确率。正如您所看到的,这是一种非常有效的技术,可以迅速产生非常好的预测结果。
现在,让我们把注意力集中在准确率(Accuracy)的图上,来看看这个算法是如何在 1000 步(epoches)之后达到很高的准确率(>95%)的。在 1000 步到 2000 步之间,又会发生什么呢?
如果我们继续用更多的训练步数(epochs)来训练,神经网络的预测会变得更精确吗?当训练步数在 1000 到 2000 之间时,神经网络的准确率会继续提高,但提高的幅度在下降。如果用更多的训练步数(epochs)进行训练,神经网络的精准度可能还会略有改善,但在目前的网络架构下,它不会达到 100%的准确率。
该脚本是谷歌官方脚本的修改版本,它是为了展示 TensorFlow 的工作方式。我们将脚本划分为易于理解的函数,并添加了许多注释来帮助您的学习。您可以通过修改以下变量来运行该脚本:
LEARNING_RATE=0.0001EPOCHS=2000
现在,您可以通过修改这些变量的值来运行该脚本。例如,尝试将学习率(learning rate)修改为 0.1,将步数(epochs)修改为 100。您觉得神经网络的效果如何?
▍在神经网络中还有许多其他参数可以修改。现在,尝试修改网络的训练次数(epochs)和学习速度(learning rate)。您将会注意到,这两种改动都能极大地影响神经网络的输出。通过改变这两个参数,观察是否可以用当前的体系结构来更快地训练这个神经网络。
可使用 TensorBoard 来(可视化)验证一下训练的神经网络。可将初始值乘以 10,将这些参数再修改几次,直到注意到神经网络性能有提升时为止。这种对神经网络进行调优并找到提升精度的过程,与当今工业应用中用于改进现有神经网络模型的过程是类似的。
版权归原作者 TiAmo zhang 所有, 如有侵权,请联系我们删除。