
资源下载地址:https://download.csdn.net/download/sheziqiong/85771938
资源下载地址:https://download.csdn.net/download/sheziqiong/85771938
BP神经网络识别手写字体
导言
- 问题描述: 本次实验所要解决的问题是使用人工神经网络实现识别手写字体。实验采用MINST手写字符集作为识别对象。其中60000张作为训练集,剩余10000张作为测试集。实验采用python语言进行编程,使用到一些python的第三方库。使用的神经网络模型为BP神经网络,这是一种按照误差逆向传播算法训练的多层前馈神经网络。而其逆向传播过程使用了小批量梯度下降法(MBGD)。本次实验中使用的是含隐藏层的7843010的网络模型,在此模型下,学习率为3的情况下,大概30次学习后可以取得95%的正确率。其余结果详解结果分析。
- 背景介绍:****1)识别手写字体:字符识别是图像识别领域中的一个非常活跃的分支,一方面是由于问题本身的难度使之成为一个极具挑战性的课题,另一方面,是因为字符识别不是一门孤立的应用技术,其中包含了模式识别领域的其它分支都会遇到的一些基本的、共性的问题。也正是由于字符识别技术的飞速发展,才促使模式识别和图像分析发展成为一个成熟的科学领域。2)人工神经网络:人工神经网络是20世纪80 年代以来人工智能领域兴起的研究热点。它从信息处理角度对人脑神经元网络进行抽象, 建立某种简单模型,按不同的连接方式组成不同的网络。神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则因网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。人工神经网络是由大量处理单元互联组成的非线性、自适应信息处理系统。它是在现代神经科学研究成果的基础上提出的,试图通过模拟大脑神经网络处理、记忆信息的方式进行信息处理。3)BP神经网络:BP神经网络是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。BP神经网络模型拓扑结构包括输入层(input)、隐层(hide layer)和输出层(output layer)。4)梯度下降法:梯度下降法是一个最优化算法,通常也称为最速下降法。梯度下降法的计算过程就是沿梯度下降的方向求解极小值(也可以沿梯度上升方向求解极大值)。梯度下降法又有批量梯度下降法BGD、随机梯度下降法SGD、小批量梯度下降法MBGD。
实验过程
- 算法理论部分 在本次实验中的神经网络,我们对节点的激励函数采用常用的sigmoid函数。这个函数如下所示:
 它的导数可求,且可以表示为如下所示:
它的导数可求,且可以表示为如下所示: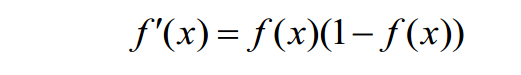 我们使用误差函数来描述正确结果与网络输出的差值,并对这个误差函数求偏导作为每一个神经网络中更新权重以及偏移量的依据。这里使用如下的误差函数:
我们使用误差函数来描述正确结果与网络输出的差值,并对这个误差函数求偏导作为每一个神经网络中更新权重以及偏移量的依据。这里使用如下的误差函数: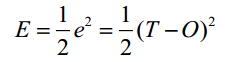 其中T为正确结果,O为神经网络输出的结果。 假设BP神经网络模型如下所示:
其中T为正确结果,O为神经网络输出的结果。 假设BP神经网络模型如下所示: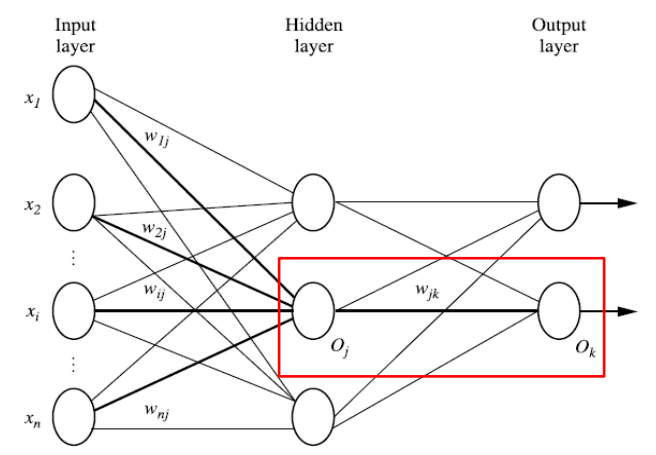 给定隐藏层或输出层的单元 j,单位j的净输入Ij为:
给定隐藏层或输出层的单元 j,单位j的净输入Ij为: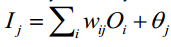 wij是从上一层单元i到单元j的连接权重;,Oi是上一层单元i的输出,θj是j单元的偏置. 给定单元j的输入Ij, 则单位j的输出Oj的公式如下,即使用sigmoid函数作为激励函数.
wij是从上一层单元i到单元j的连接权重;,Oi是上一层单元i的输出,θj是j单元的偏置. 给定单元j的输入Ij, 则单位j的输出Oj的公式如下,即使用sigmoid函数作为激励函数.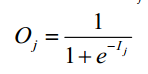 为了调整权重 wjk,我们首先计算在E关于wjk的偏导数,这里可以使用求偏导的链式法则。然后利用这个值修正权重。
为了调整权重 wjk,我们首先计算在E关于wjk的偏导数,这里可以使用求偏导的链式法则。然后利用这个值修正权重。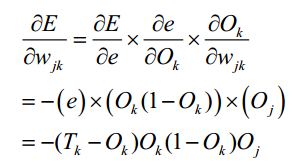 同样的,如果要调整偏移量,也是计算误差函数E关于其的偏导数。 最终,由计算可得,对于输出层的单元k,误差梯度可表示如下:
同样的,如果要调整偏移量,也是计算误差函数E关于其的偏导数。 最终,由计算可得,对于输出层的单元k,误差梯度可表示如下: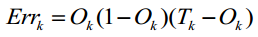 隐藏层单元 j 的误差梯度为:
隐藏层单元 j 的误差梯度为: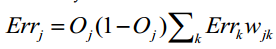 而权重和偏移量的更新可表示如下:
而权重和偏移量的更新可表示如下: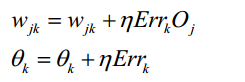 根据以上三个公式,即可反向传播误差,结合梯度下降算法,修正神经网络的权重和偏移量。 对于梯度下降算法,导言中有所提及,这里我们使用的是小批量梯度下降算法(MBGD)。MBGD在每次更新参数时使用b个样本(b一般为10),求得这b个样本的误差平均值之后,更新一次权重和偏移量。它的伪代码表现如下:
根据以上三个公式,即可反向传播误差,结合梯度下降算法,修正神经网络的权重和偏移量。 对于梯度下降算法,导言中有所提及,这里我们使用的是小批量梯度下降算法(MBGD)。MBGD在每次更新参数时使用b个样本(b一般为10),求得这b个样本的误差平均值之后,更新一次权重和偏移量。它的伪代码表现如下: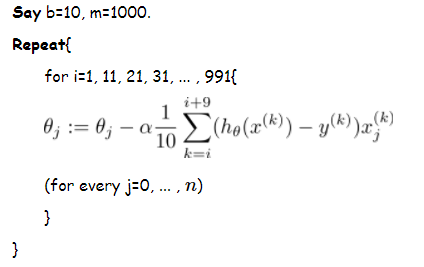
- 代码实现部分 代码实现部分的流程如下所示。
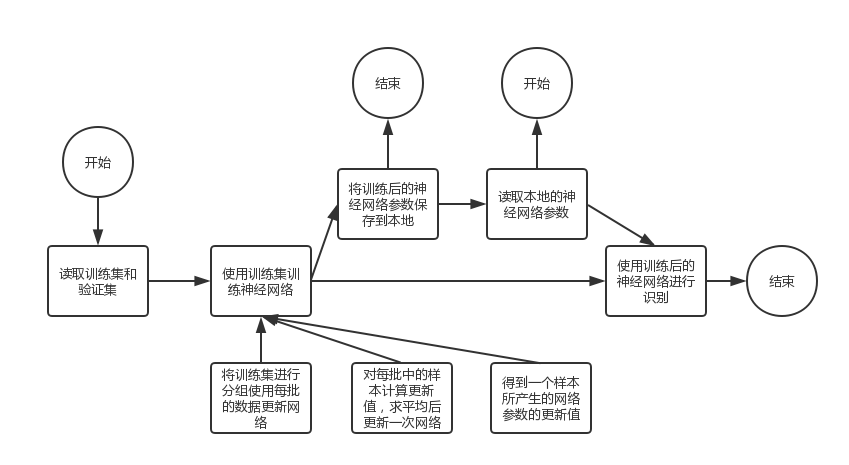 Main函数部分: Main函数如下所示。
Main函数部分: Main函数如下所示。train_images = decode_idx3_ubyte(train_images_idx3_ubyte_file)train_labels = decode_idx1_ubyte(train_labels_idx1_ubyte_file)test_images = decode_idx3_ubyte(test_images_idx3_ubyte_file)test_labels = decode_idx1_ubyte(test_labels_idx1_ubyte_file)trainingimages =[(im /255).reshape(1,784)for im in train_images]# 归一化traininglabels =[vectorized_result(int(i))for i in train_labels]testimages =[(im /255).reshape(1,784)for im in test_images]testlabels =[l for l in test_labels]net = NueraLNet([28*28,30,10])net.train_net(trainingimages, traininglabels,30,3,10, testimages, testlabels)net.save_training()net.read_training()net.test_net(testimages, testlabels)print("end")首先是从字符集中读取出训练集和验证集的图片及其数字的数据,以list的形式存储。而对于每一个图片则是为numpy数组,对于每一个标签则为浮点数。由于读取出来的是像素的灰度值,我们需要将其归一化才能使用,并将其每一张图片重构为1784的数组。而对于训练集的标签,我们还需要为其每一个标签重新构造110的数组,其中下标为标签值的地方值为1,原因是为了与我们神经网络10的输出节点相对应。读取字符集以及转化标签的函数均为自定义函数,由于与神经网络无关,这里不作解释。 接着,我们声明了一个神经网络对象,这个对象的类是我们自定义的。初始化是一个列表,表明了每一层各有多少个节点。其中输入层为784个节点,对应图片的784个像素点,输出层为10个节点,对应输出0-9.隐层可以自定义。Train_net函数为训练神经网络,save_training函数为报错训练后的神经网络参数到本地。read_training函数为读取本地已保存过的网络参数。test_net是使用验证集,验证神经网络的结果。以上几个函数均在类NueraLNet中定义,其具体用法稍后解释。自定义神经网络类NueraLNet部分: 在实现自定义类之前,我们先使用sigmoid函数定义了激励函数及其导数,以供类中使用。defsigmoid(x):return np.longfloat(1.0/(1.0+ np.exp(-x)))defsigmoid_prime(x):return sigmoid(x)*(1- sigmoid(x))首先是对类的初始化,传入一个列表代表网络每一层的节点数。然后保存层数,以及这个列表。并根据这个列表随机生成神经网络的权重及偏移量。两者都是列表,其中偏移量bias中的是数组,每一个数组代表从第二层开始的每一层的节点的偏移量。权重weights中的是二维数组,其中行代表前一层的节点位置,列代表后一层的节点位置。对应的即为前一层某个节点到后一层某个节点的权重。def__init__(self, sizes): self.num_layers =len(sizes) self.sizes = sizes self.bias =[np.random.randn(1, y)for y in sizes[1:]] self.weights =[np.random.randn(x, y)for x, y inzip(sizes[:-1], sizes[1:])]如下函数体现了神经网络的前向传播部分,即通过神经网络得出结果。最终得到的result是一个numpy数组,其中有输出层每一个节点的输出。defget_result(self, images): result = images for b, w inzip(self.bias, self.weights): result = sigmoid(np.dot(result, w)+ b)return result下边的函数是训练神经网络,其中trainimage是训练集的图片,trainresult是训练集的结果,traintime是使用次训练集训练的次数。Rate是学习率,默认为1,minbatch为小批梯度下降中,每一批量的样本个数,默认为10。test_image为验证集图片,test_result为验证集结果,默认为空。 接下来就是对于每一次训练。我们先将训练集分组,分成小批量。对于每一批量,我们调用update_net函数更新网络参数。更新结束后 ,输出第几次学习结束。最后判断有没有验证集,如果有的话,我们将使用test_net函数,查看这一次训练后,神经网络检测字体的正确率。deftrain_net(self, trainimage, trainresult, traintime, rate=1, minibatch=10, test_image=None, test_result=None):for i inrange(traintime): minibatchimage =[trainimage[k:k+minibatch]for k inrange(0,len(trainimage), minibatch)] minibatchresult =[trainresult[k:k+minibatch]for k inrange(0,len(trainimage), minibatch)]for image, result inzip(minibatchimage, minibatchresult): self.update_net(image, result, rate)print("第{0}次学习结束".format(i+1))if test_image and test_result: self.test_net(test_image, test_result)下边的函数就是刚刚提到过的更新网络的update_net函数。在这个函数中使一批中所有样本误差梯度的平均值更新一次神经网络的参数。首先我们按照类中存储权重和偏移量的变量格式相应声明存取权重和偏移量误差梯度的变量。接下来,对于批次中的每一个样本,我们通过get_error函数得到测试这个样本之后权重和偏移量的误差梯度。这个get_error函数也就是我们的反向传播误差的过程。这个函数稍后讲解。然后我们将这一批次中所有样本的误差梯度累加到先前声明的存取误差梯度的类中。最后我们根据这一批次所有样本的误差梯度平均值,乘上学习率来调整神经网络的权重和偏移量。defupdate_net(self, training_image, training_result, rate): batch_b_error =[np.zeros(b.shape)for b in self.bias] batch_w_error =[np.zeros(w.shape)for w in self.weights]for image, result inzip(training_image, training_result): b_error, w_error = self.get_error(image, result) batch_b_error =[bbe + be for bbe, be inzip(batch_b_error, b_error)] batch_w_error =[bwe + we for bwe, we inzip(batch_w_error, w_error)] self.bias =[b -(rate/len(training_image))*bbe for b, bbe inzip(self.bias, batch_b_error)] self.weights =[w -(rate/len(training_image))*bwe for w, bwe inzip(self.weights, batch_w_error)]接下来就是反向传播误差的函数get_error。这个函数的参数即为一个样本及其结构。首先也是按照类中存储权重和偏移量的变量格式相应声明存取权重和偏移量误差梯度的变量。由于反向传播误差的过程中,我们需要神经网络中间的输入输出数据。所以定义列表out_data存储每一个节点的输出值,其中第一个元素是输入层的输出值也就是测试的样本。定义列表in_data存储每一个节点的输入值。 接下来我们使用一个for循环进行了前向传播输入的过程并记录了节点的输入输出值。在列表in_data后边添加上一层输出(out_data[-1])乘以权重加上偏移量,作为这一层的输入。在列表out_data后边添加刚刚的输入(in_data[-1])通过激励函数后的值,作为这一层节点的输出。这样就保存测试过程中,每一层节点的输入和输出值。 接下来是计算整个网络的权重及偏移量的误差梯度。这里计算的完全按照之前理论部分推导出来的公式,只要之前理解,这里也好理解。首先是计算输出层的偏移量和最后一层的权重的误差梯度。按照公式来。接下来是使用for循环进行反向传播误差。计算之前的每一层的偏移量和权重的误差梯度。这个也是按照公式来的计算即可。 最后则返回计算好的偏移量和权重的误差梯度。defget_error(self, image, result): b_error =[np.zeros(b.shape)for b in self.bias] w_error =[np.zeros(w.shape)for w in self.weights] out_data =[image] in_data =[]for b, w inzip(self.bias, self.weights): in_data.append(np.dot(out_data[-1], w)+ b) out_data.append(sigmoid(in_data[-1])) b_error[-1]= sigmoid_prime(in_data[-1])*(out_data[-1]- result) w_error[-1]= np.dot(out_data[-2].transpose(), b_error[-1])for l inrange(2, self.num_layers): b_error[-l]= sigmoid_prime(in_data[-l])* \ np.dot(b_error[-l+1], self.weights[-l+1].transpose()) w_error[-l]= np.dot(out_data[-l-1].transpose(), b_error[-l])return b_error, w_error接下来这个函数是测试神经网络正确率的函数,先前在训练神经网络时也调用过。这个函数的参数是验证集图片及其结果。我们首先使用get_result函数得到验证集图片中的每一个结果,并取其结果中最大值的索引,与验证集结果打包成tuple。接着得到所有的tuple中,两者相等的个数,即为识别正确的个数,然后输出识别的结果。deftest_net(self, test_image, test_result): results =[(np.argmax(self.get_result(image)), result)for image, result inzip(test_image, test_result)] right =sum(int(x == y)for(x, y)in results)print("正确率:{0}/{1}".format(right,len(test_result)))return results接下来是将神经网络的权重和偏移量保存的本地的函数,这样我们在识别时可以直接读取位于本地的参数,而不需要重新训练神经网络。使用numpy的savez函数将weights和bias中的numpy数组,打包存到本地的npz文件中。defsave_training(self): np.savez('./datafile/weights.npz',*self.weights) np.savez('./datafile/bias.npz',*self.bias)下边的函数是将本地的参数读取到神经网络中。使用load函数加载后,将加载后的数组依次添加到神经网络的weights和bias中去。即可不用训练神经网络就能进行识别。defread_training(self): length =len(self.sizes)-1 file_weights = np.load('./datafile/weights.npz') file_bias = np.load('./datafile/bias.npz') self.weights =[] self.bias =[]for i inrange(length): index ="arr_"+str(i) self.weights.append(file_weights[index]) self.bias.append(file_bias[index])这样,整个与神经网络有关的代码就讲解结束了。
结果分析
本次实验的编程语言为python3.6,使用的IDE为pycharm。使用到python的第三方库有numpy和PIL
本次实验中,我们可以通过调节迭代次数,学习率,隐藏层节点个数等参数,获取不同的神经网络训练结果。接下来的结果分析将从这三个参数出发。
首先是训练结果与学习率的关系。在这里我们控制隐藏层节点数为30不变。训练样本数为10000.(详细结果数据可见excel文件《结果分析-学习率》)从图中可以看出,在适当学习率的情况下,30次学习后的正确率在94%-95%左右。除了学习率为0.1和0.5的情况下,其余基本在10次学习之后就达到了相对稳定的状态。
另外分析图表我们还可以得出以下结论:
(1)学习率越高,训练结果的震荡越大。
(2)在一定范围内,学习率越高,初次迭代后的正确率越高,超过此范围后,初次迭代后的正确率下降。
(3)学习率越高,越快趋于稳定,但随着学习率增高,训练结果震荡越大。
接下来是训练结果与隐藏层节点数的关系。这里控制学习率为上次结果中较好的5.训练样本数仍未10000。
从图中可知:在30次迭代学习,学习率为5的情况下,40-70层隐藏层的网络成功率基本可以达到96%。另外,随着隐藏层数的增加,成功率基本是随之增高的。但是同样的,训练网络所耗费的时间也会大大增加。不知为何,70层隐藏层的前两次迭代正确率非常低。另外,同一学习率,在隐藏层数低的网络引起的震荡,要高于隐藏层数高的网络。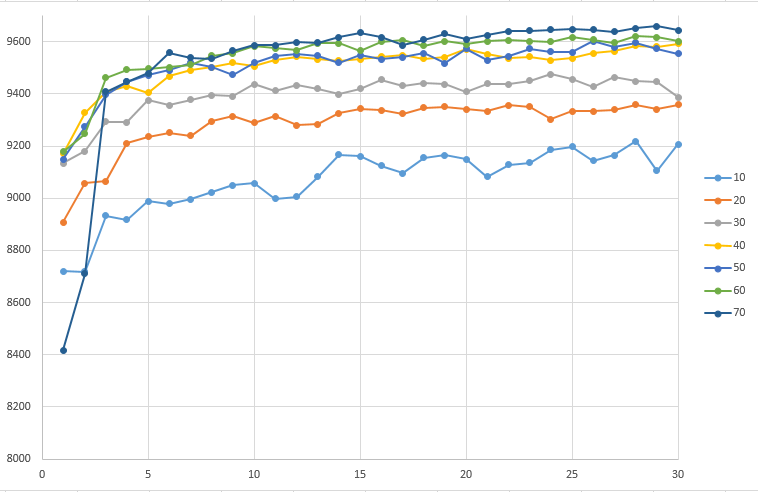
资源下载地址:https://download.csdn.net/download/sheziqiong/85771938
资源下载地址:https://download.csdn.net/download/sheziqiong/85771938
版权归原作者 biyezuopin 所有, 如有侵权,请联系我们删除。