
Learning a Deep Multi-Scale Feature Ensemble and an Edge-Attention Guidance for Image Fusion
(学习深度多尺度特征集成和图像融合的边缘注意指南)
在本文中,我们提出了一种用于红外和可见光图像融合的深度网络,该网络将具有融合学习机制的特征学习模块级联。首先,我们应用从粗略到精细的深度体系结构来学习多模态图像的多尺度特征,这使得能够为以后的融合操作发现突出的常见结构。建议的特征学习模块不需要对齐良好的图像对进行训练。与现有的基于学习的方法相比,所提出的特征学习模块可以集合来自各个模态的大量示例进行训练,从而提高了特征表示的能力。其次,我们在多尺度特征上设计了一种边缘引导的注意机制,以引导融合聚焦在常见结构上,从而在衰减噪声的同时恢复细节。
介绍
红外和可见光融合的关键点是如何从两个来源中提取典型特征,以及如何设计适当的融合规则以生成互补输出。为此,近几十年来开发了许多方法来设计有效的特征提取策略和适当的融合规则。这些方法可以大致分为基于传统框架的方法和基于深度学习的方法。
传统方法利用多尺度变换 (MST),稀疏表示,子空间分解,混合工具,数学优化和其他提取有效特征。其中,基于MST的方法由于其灵活性和在视觉效果方面的优势而引起了极大的关注。这些方法通过特定的变换工具 (例如非次采样curvelet,小波和边缘保留滤波器) 在不同尺度上提取代表性特征。因此,随后的融合过程可以完全包含各种尺度上的特征信息,并使用简单的max或平均运算符将其融合。但是,这种类型的方法通常会因在多个尺度上重叠不对称特征信息而导致光晕和边缘模糊。
最近,研究人员使用深度学习 (DL) 进行红外和可见光图像的健壮和高效融合。这些基于DL的方法实现了最先进的性能,但仍然存在局限性。首先,DL技术通常用于从源图像中提取显着特征,然后生成用于融合的加权图。这些深度显著特征是在一个单一尺度下给出的,忽略了跨尺度的局部/全局信息,从而在一定程度上降低了融合质量。其次,这些方法采用简单的融合规则,例如加法和级联,因此最终结果中可能出现不良的伪影或模糊的边缘。最后但并非最不重要的一点是,深度网络的培训需要大量对齐的可见光/红外对,这些在实践中很难收集。
贡献
• 我们提出了一种新颖的红外和可见光图像融合深度体系结构,以学习多尺度的显着特征以及融合规则。我们的方法不会在训练阶段获取已注册的图像对,从而消除了对特定训练数据集的依赖。
• 为了从输入图像中获得更全面的特征,我们精心建立了一个特征提取器,该特征提取器以密集的上下文扩展网络为主干,以从多个尺度分层地集成从粗到细的特征。重新设计的特征提取器有效地利用了中间特征,而无需对源图像进行向上或向下采样。
• 我们制定了一种跨域边缘引导的注意机制,以实现具有可用的细节特征的融合图像的数据一致性,从而保留详细信息,同时衰减噪声或不良伪影。这种基于学习的机制突破了手工制作的融合规则的限制,显著提高了融合性能。
• 我们构建了一个新的对准红外和可见光图像融合数据集,名为RealStreet,具有广泛的挑战性条件,包括不良的照明和室外性能评估。
相关工作
关于传统融合方法和基于深度学习的融合方法:略
Attention Mechanism in DL
捕获感兴趣区域的注意力机制起源于机器翻译任务,并且一直是人工智能的热门话题。具体来说,该机制使用整个输入序列来计算权重,然后将权重引入到输入序列中,以选择性地更多地关注重要区域。人类生物系统也可以解释,人类可以很容易地观察到重要的信息,而忽略其他不重要的信息。注意机制在图像处理社区中发挥了关键作用 (例如,显着性检测,图像恢复和语义分割)。Wang等人通过堆叠能够捕捉显著特征的注意力模块,引入了网络,实现了突出的识别性能。研究人员还设计了边缘引导的注意机制,以产生视觉上吸引人的图像。Zhang等人提出了一种提高医学图像分割精度的新方法。他们使用边缘指导模块来学习早期编码层中的边缘注意表示,然后通过使用加权聚合模块来融合转移的表示特征。Zhao等人提出了一种边缘制导网络 (EGNet),通过显著边缘与对象信息的互补来解决对象检测中的粗边界问题。
方法
Coarse-to-Fine Feature Extractor
红外和可见光图像融合任务的一个重要问题是提取丰富的特征来表示输入图像。通常,特征提取对融合结果产生巨大影响。以前的深度方法设计了一个完全连接的层作为特征提取器,而没有考虑上下文化的信息,这可能会导致融合结果中出现伪像。
因此,我们提出了一种上下文扩展特征提取模块,以通过以下两种方式获得粗到细的特征:
- 我们通过多尺度上下文聚合结构在具有不同感受域的多尺度上聚合了三个卷积路径的表示。
- 我们在每个卷积路径中集成了一个密集块,以提供更丰富的功能供后续使用。
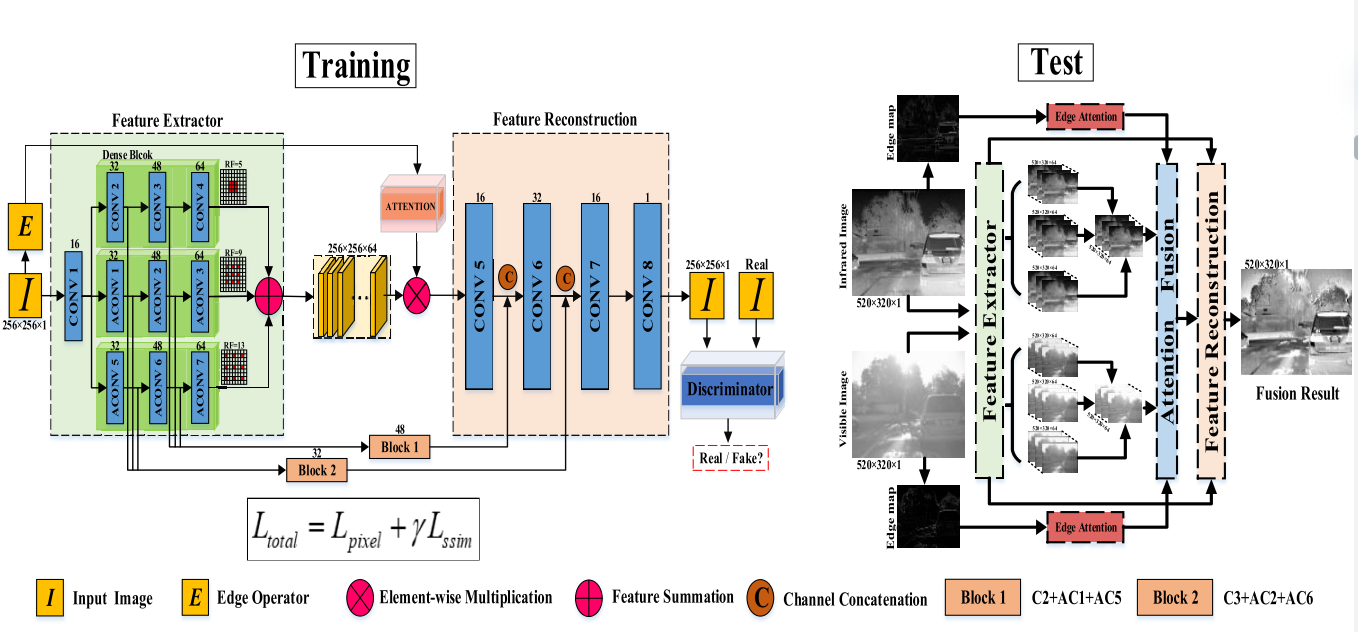
如图2所示,网络通过第一卷积将红外和可见图像转换到特征空间中。然后,汇总具有不同扩张因子的三个卷积路径的中间结果,以获取多个尺度的总体信息。膨胀卷积 使用放大因子的步长对像素进行加权,从而在不改变分辨率的情况下增加其感受野。通过使用相同的内核大小3 × 3,每个扩张路径都由三个卷积组成。这三种路径分别使用其典型的接受域5 × 5、9 × 9和13 × 13,以提供更精确的互补信息。
让fin表示提取模块的输入特征图,我们计算出提取模型的输出特征图
f
e
f^e
feout如下:
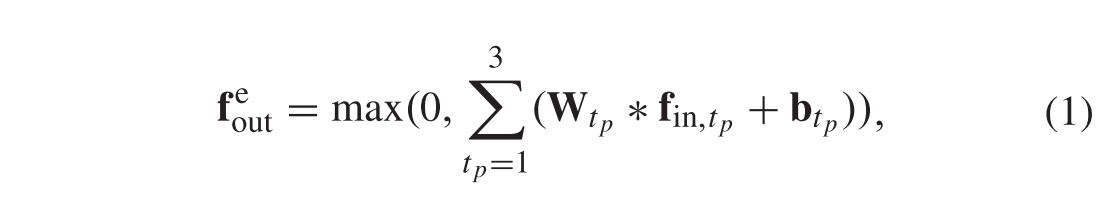
其中 ∗ 表示卷积算子,tp表示扩张卷积路径的序号。W和b分别表示卷积层的滤波器参数和基。
除了在多个尺度上聚集显着特征之外,我们还在每个膨胀路径中进一步添加了密集连接,以尽可能保留深层特征。每一层的输出级联作为下一层的输入。我们将特征提取模块给出的红外和可见光图像的输出特征分别表示为
f
e
f^e
feir和
f
e
f^e
fevis。
密集膨胀特征提取模块充分整合了来自不同感受野的信息,保证了深层特征的结构一致性。
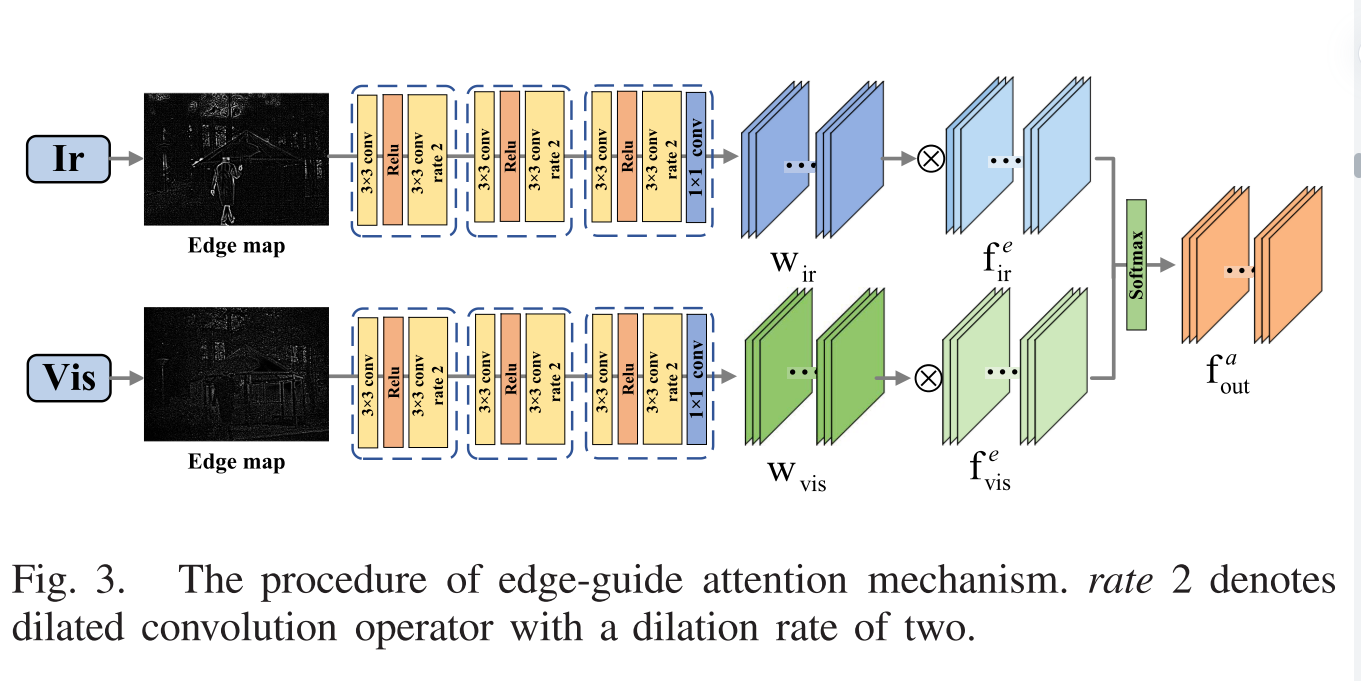
Edge-Guided Attention Feature Fusion
多种注意机制已成功应用于许多计算机视觉任务中,因为它们可以捕获视觉场景中的感兴趣区域。融合的主要目的是找到每种模态的适当特征。为此,并受先前工作的启发,我们利用粗略的中间特征来获得增强边缘图像的注意力图。通过这种设计的基于边缘的注意机制,我们的融合结果可以同时保留更多的纹理细节并衰减不良的伪影。
具体地,通过两个步骤获得边缘图。我们将大小为m × n的输入灰度图像表示为u,并将其梯度图 ▽u定义为:
标签ua(i) 和ub(i) 分别表示位于源像素i的右侧和下方的最近邻居像素。我们还设计了一个边缘增强算子,以使梯度信息更加引人注目: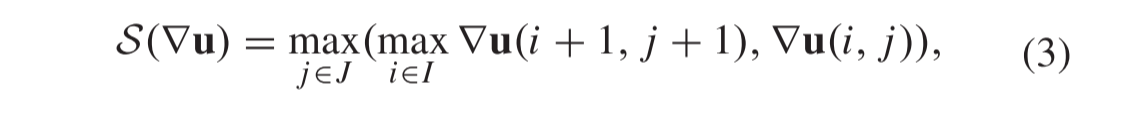
其中I ={1,…,m − 1} 和J ={1,…,n − 1}。索引i和j分别表示梯度图像的水平方向和垂直方向。
随后,我们将红外图像和可见光图像的增强边缘图输入注意机制,生成特征权重图Wir和Wvis,并计算边缘引导注意加权的融合特征
f
a
f^a
faout:
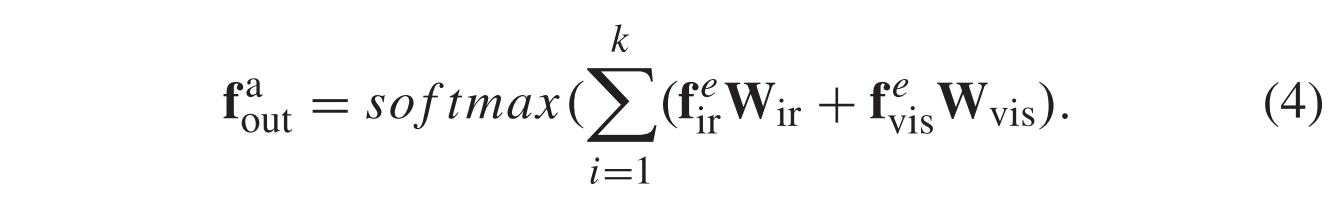
来自由注意图Wir和Wvis加权的提取模块的双模态特征
f
e
f^e
feir和
f
e
f^e
fevis的总和生成融合特征,如图3所示。最终融合图像由如下给出的训练解码器从融合特征
f
a
f^a
faout中重建。
Feature Compensation Reconstruction
图像重建旨在通过卷积层将特征图从特征空间转换为图像空间。简单地利用卷积操作可能会导致恢复图像过程中的重要信息丢失。我们引入了两个跳过连接,以减轻多次卷积后特征图的信息丢失。具体来说,我们将特征提取器模块中的三个不同的扩张特征相加,以补偿红外和可见特征,然后使用select-max策略以元素方式选择红外或可见特征。最后,我们在特征重建模块中沿着通道将这些补偿的特征连接到基于注意的融合特征。结果,从特征重建模块中恢复融合图像。我们的方法的流程图如图2所示。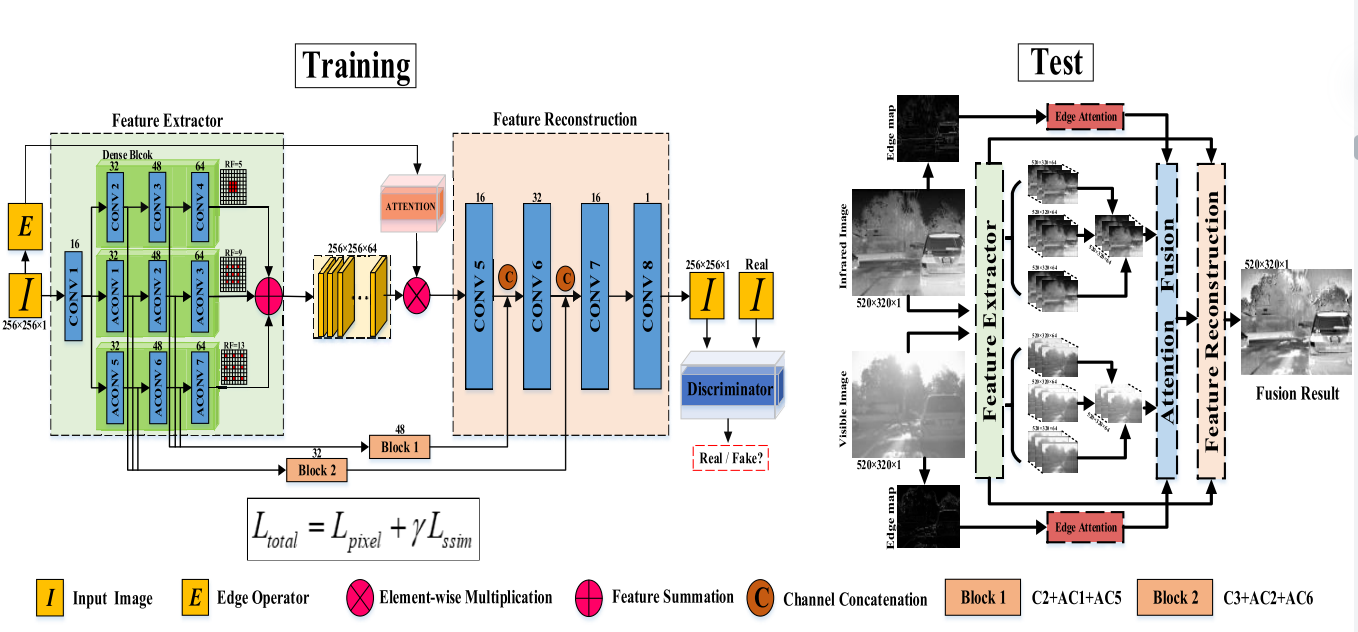
Loss Function and Training Details
对于多模式图像融合,网络执行有监督/无监督学习没有基本道理。此外,在现实世界中很难获得足够的配准图像对。为此,我们通过馈送红外或可见光来训练网络,除了边缘注意机制外,我们还可以通过编码器解码器部分重建输入图像。我们在训练阶段的方法的详细框架显示在图2的左侧。
为了更精确地重建输入图像,我们最小化总损失函数Ltotal (LSSIM和LMSE与超参数 γ 的组合) 来训练我们的网络。SSIM是两个不同图像之间结构相似性的有效度量,它结合了三个分量,即亮度,结构和对比度。同时,MSE目标是测量输入和输出图像之间的像素强度。这两个损失函数共同约束了重建的结构和像素误差。总损失函数表示为: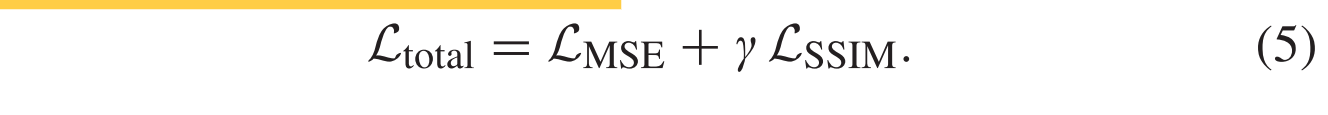
LMSE计算输入和输出图像之间的欧几里得距离: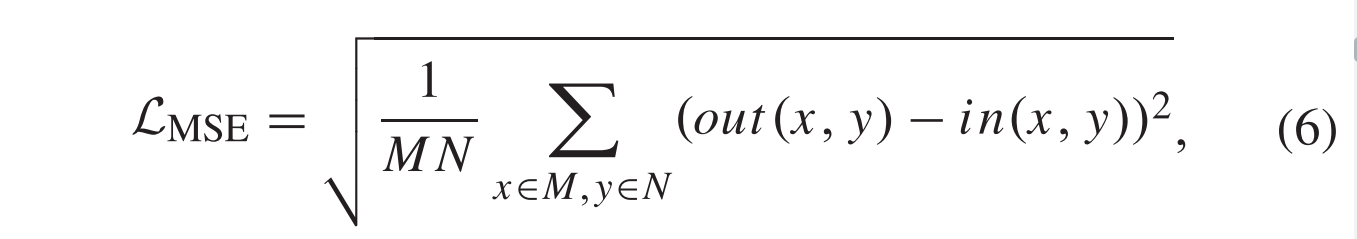
其中out和in分别表示重构数据和输入训练数据。M和N给出图像的大小,(x,y) 是像素位置。LSSIM的计算公式为: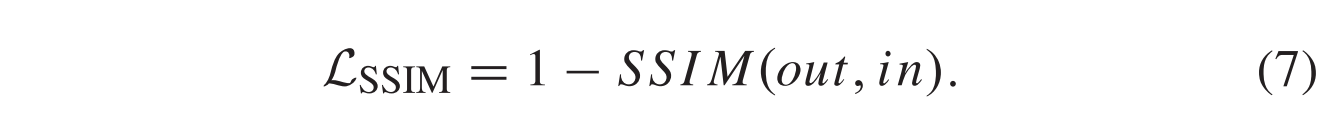
符号SSIM(·) 表示结构相似性操作。
此外,受生成对抗网络 (GANs) 的启发,我们假设上述网络作为生成器,并在网络末端添加一个判别器,以引导生成器产生更自然的图像。添加的LAdv可以写成: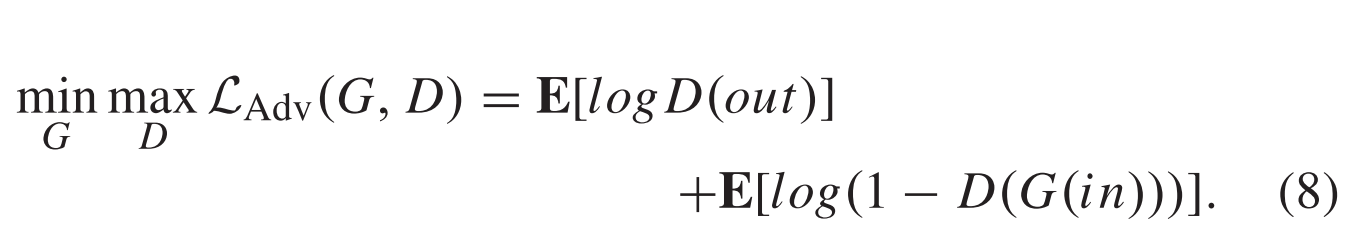
生成器和鉴别器是替代迭代,可提供更强大,更可靠的网络。
培训结束时,我们会在网络中提供两个注册的图像。训练过的coarse-to-fine模型用于从输入的两模态图像中提取深度显着特征。随后,利用联合边缘引导的权重图来乘以相应的特征,从而生成融合的特征。最后,融合的特征通过两个添加的跳过连接反馈到解码器模块中,以重建最终融合的图像。
版权归原作者 小郭同学要努力 所有, 如有侵权,请联系我们删除。