
本文记录了使用rvest & RSelenium 包进行爬虫与网页渲染的相关知识点及本人的编程操作过程。涉及到基本爬取操作、爬取缺失部分如何处理、操作网页过滤等步骤。
本人非计算机专业,如有措辞不慎敬请提出。
爬虫目标
这学期为了凑学分,选了一门R语言的课,才发现R语言远比我们想象的要强大。至少问过身边同学,他们都不知道R还能爬虫qaqq
为了防止自己学过就忘..写一篇blog记录一下被rvest与Rselenium折磨的这一个周的成果。
以下是代码爬取的要求:
- 从IMDb首页出发,提取该榜单所有电影的user reviews各100条
- 使用Rselenium进行网页操作:User Reviews可能存在剧透(Spoilers),需要进行隐藏(Hide Spoilers);每个review网页初始显示评论25条,需要点击Load More加载更多评论。
- 保存每条评论及对应的电影评分。Tips:存在只有内容没有评分的评论。
1 爬虫知识整理
在进行实例展示之前,先回顾一下R语言爬虫需要用到的知识。主要涉及两个库:rvest与rselenium
1.1 Rvest包
Rvest功能强大,语法简洁,用起来真的很顺手。由于本文只用到了读取与提取的API,在这里也只对相关的API进行说明。
编号函数名作用1read_html()根据给定的url,【读取其html文档】2html_nodes()提取html文档中的对应【节点与元素】3html_name()提取【标签名称】4html_text()提取标签内的【文本内容】5html_attrs()提取【所有的属性名称及其内容】6html_attr()提取【指定】属性的内容7html_table()将网页数据表的数据解析到R的dataframe中8html_form()提取表单
我们结合具体环境看一下部分代码的作用:
1.1.1 read_html()
在read_html()的参数部分,我们给定一个网址,这个函数就能够返回这个网址指向的HTML网页数据。
# 使用read_html()下载IMDB首页的html文件
url <- "https://www.imdb.com/chart/moviemeter?sort=rk,asc&mode=simple&page=1"
webpage <- read_html(url)
webpage
# 返回结果:
#{html_document}
#<html xmlns:og="http://ogp.me/ns#" xmlns:fb="http://www.facebook.com/2008/fbml">
#[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">\n<script #...
#[2] <body id="styleguide-v2" class="fixed">\n <img height="1" width="1" style #...
1.1.2 html_*()
不可避免的,我们需要了解一些HTML的知识:
下图中<>框起的部分就是标签,而每个<>后对应的第一个紫色英文单词就是我们所说的标签(如div);黄色部分是属性名称(如name, class);属性名称 = “?” ,引号中的内容就是我们说的属性内容;黑色部分就是显示的文本
将各部分拆解了以后,我们也就能明白每个函数能提取出什么来——
html_nodes():使用标签进行定位;
html_attrs():提取等号后的属性内容;
html_text():提取“黑色部分”
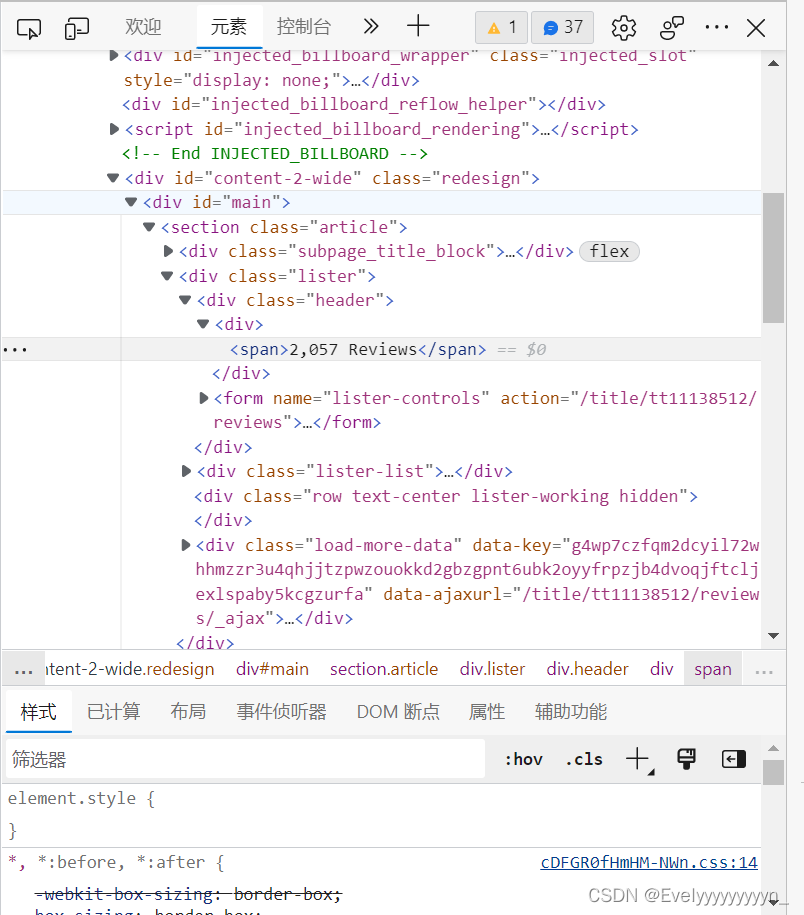
1. html_nodes()
参数有二:
编号参数说明1x可以是html文件,也可以是之前提取过的nodes文件2css/xpath需要提取的节点位置
比较重要的就是节点位置的选取,也就是我们的第二个参数部分。以下图为例,我们想提取header部分,我们可以采用以下方法提取:
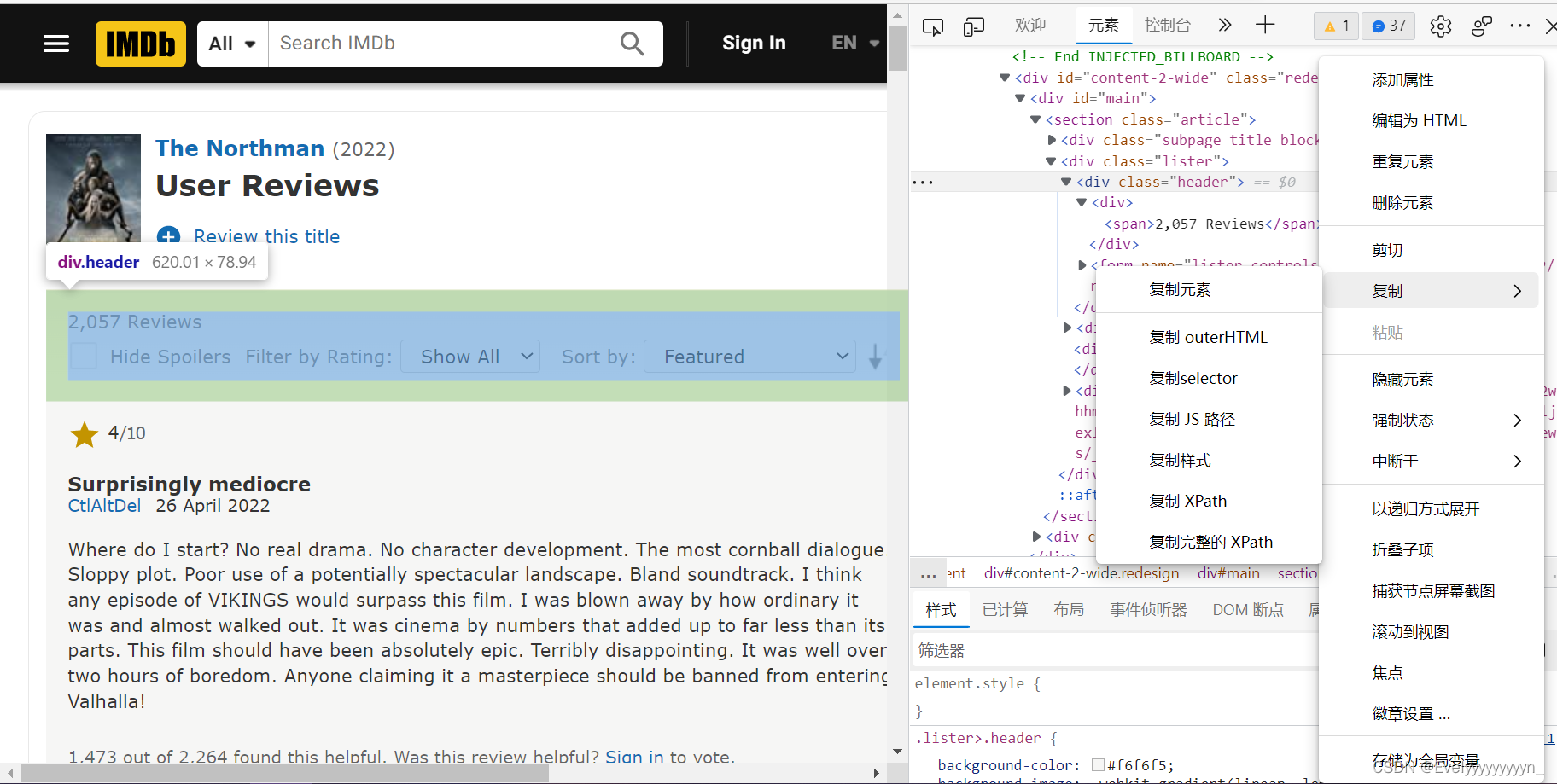
① css/xpath:直接复制型
如上图所示,我们将鼠标移到对应元素的html文档上面,点击右键→复制→复制selector/复制XPath,即可获得路径如下→GET!
#css:
"#main > section > div.lister > div.header"
#xpath:
"//*[@id="main"]/section/div[2]/div[1]"
② 标签.属性内容 型
标签:div;属性:name;属性内容:header。将属性(黄色部分)划了去,直接div.header→GET!定位成功!
P.S 有时如果掌握不好这个方法,也可以将元素选择鼠标放到对应的位置上,就会自动显示出节点。比如说图中左侧的div.header
③ 标签(空格)标签 型
这里换一个例子比较合适。使用薄荷健康食品库的网页(因为比较简单)。
如果我们想爬取食品类别和烹饪方式,发现对应元素标签
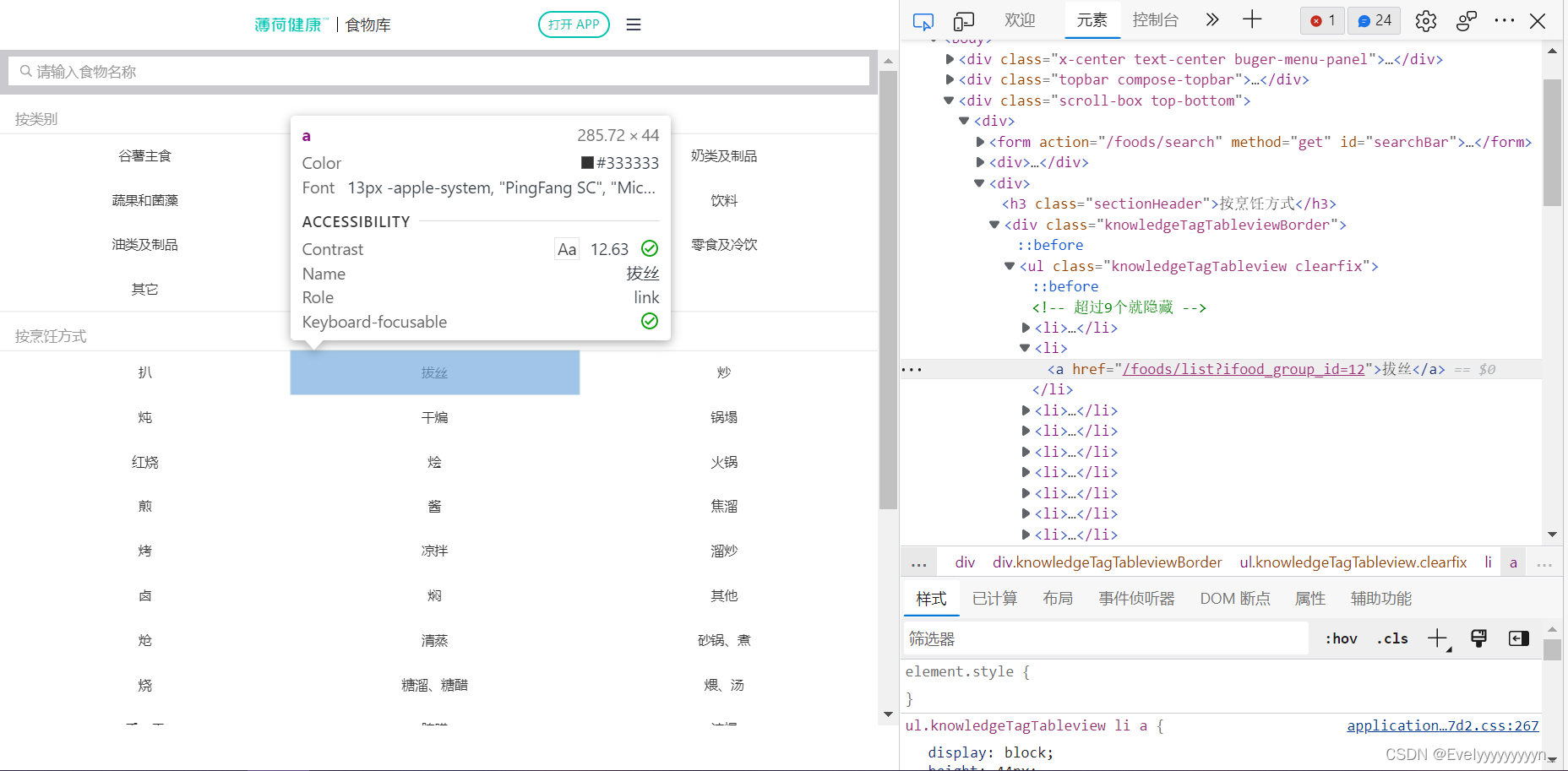
那么我们的节点就可以写为:
cooking_style <- start %>% html_nodes("li a")
# 返回结果
#{xml_nodeset (40)}
# [1] <a href="/foods/list?ifood_group_id=1">谷薯主食</a>
# [2] <a href="/foods/list?ifood_group_id=2">肉蛋及制品</a>
# ...
2. html_text():
这个函数正如我们上面所说,爬的是黑色部分——文本。
那还是薄荷健康的例子,在获取了cooking_style这个具体的元素块了以后,我们对文本进行提取:
cooking_style <- start %>% html_nodes("li a") %>% html_text(trim = TRUE)
# 返回结果
# [1] "谷薯主食" "肉蛋及制品" "奶类及制品" "蔬果和菌藻" "坚果及制品" "饮料" "油类及制品"
# [8] "调味品" "零食及冷饮" "其它" "扒" "拔丝" "炒" "炖"
# ...
trim = TRUE能够将文本中的空格进行剔除,这样获得的文本也会更加规范。
3. html_attrs():
这个函数最常见的用途一定是获得其他网页的url了!而url出现的位置:a href = "巴拉巴拉巴" 就是我们说的【引号中的部分】
在薄荷健康中,如果我们想获取每种食物or烹饪方式的网址,那么:
website <- start %>% html_nodes("div.knowledgeTagTableviewBorder a") %>%
html_attr("href")
# 返回结果:
# website
# [1] "/foods/list?ifood_group_id=1" "/foods/list?ifood_group_id=2" "/foods/list?ifood_group_id=3"
# [4] "/foods/list?ifood_group_id=4" "/foods/list?ifood_group_id=5" "/foods/list?ifood_group_id=6"
But 我们一看,这个网址和实际上的不一样嘛!
这就需要我们使用paste()进行网址的补全:
website <- paste("http://m.boohee.com/", website, sep = "")
# 返回结果:
# website
# [1] "http://m.boohee.com//foods/list?ifood_group_id=1"
# [2] "http://m.boohee.com//foods/list?ifood_group_id=2"
# ...
这样就对了!可以访问这些链接了!
while Rvest包中还存在着一些处理乱码、进行行为模拟操作的API。虽然我没有用到,但在这里还是展示一下:
分类编号函数名作用
乱码处理
*_encoding()
1guess_encoding()用来探测文档的编码,方便我们在读入HTML文档时设置正确的编码格式2repair_encoding()修复HTML文档读入后的乱码问题行为模拟(如输入账号、密码等)1set_values()修改表单2submit_form()提交表单3html_session()模拟HTML浏览器会话4jump_to()得到相对链接或绝对链接5follow_link()通过表达式找到当前页面下的链接6session_history()历史记录导航工具
1.2 RSelenium包
Rvest包是帮助你对给定网页直接进行信息爬取的工具,而RSelenium包则是进行“网页自动控制”的工具。它能够自动打开网页,并根据我们的代码指令进行比如说像点击、查询特定信息等活动,帮助我们进行更精确的爬虫操作。
P.S rselenium包是基于JAVA存在的,因此在使用之前需要提前下载安装Java SE Development Kit
加载如下packages:
library(tidyverse)
library(rvest)
# install.packages("RSelenium")
library(RSelenium)
# install.packages("netstat")
library(netstat) # we are going to use the function free_port() in this package
1.2.1 打开浏览器(谷歌chrome)
rs_driver_object <- rsDriver(browser = "chrome",chromever = "106.0.5249.21",verbose = F, port = free_port())
remDr <- rs_driver_object$client
可以通过在Chrome浏览器中键入“chrome://settings/help”或在R中输入binman::list_versions("chromedriver")查看自己的浏览器版本。
1.2.2 网页导航
- 打开一个网页:
remDr$navigate("http://www.imdb.com/title/tt1856010/reviews")
- 刷新操作:
remDr$refresh()
- 得到当前页面网址:
remDr$getCurrentUrl()
这个功能还是需要说一下的。正如我们之前所说,Rvest包与RSelenium包功能不同,所以也不能用一种逻辑使用两种工具包。
我们在对一个网页进行所有selenium操作后,需要注意,此时的url和之前是不同的,会显示很多条件。

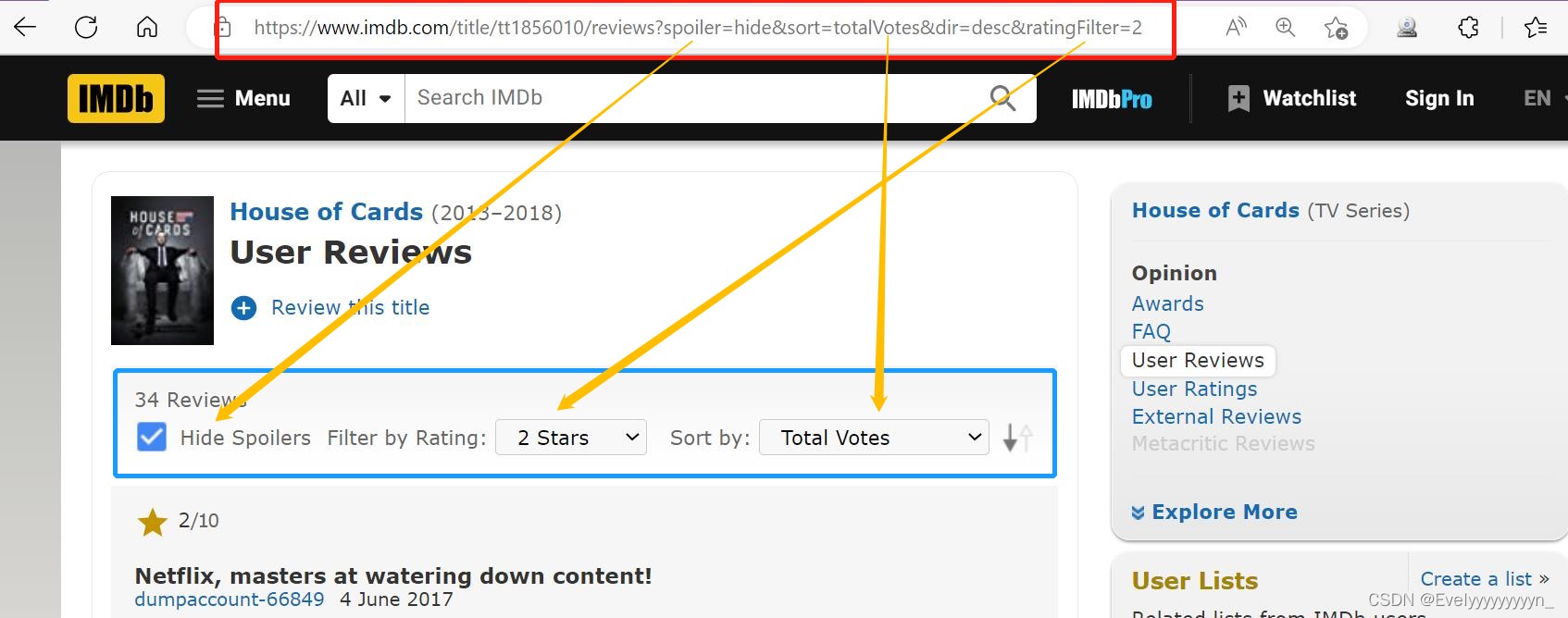
这时,我们需要使用remDr$getCurrentUrl()语句得到当前的url,然后使用read_html()读入其HTML文件,进行爬取工作。
- 前进、回撤动作
remDr$goBack()
remDr$goForward()
1.2.3 定位HTML元素
我们可以使用id, name, class 或css selector、xpath等定位方式寻找我们需要的元素。
使用语句findElement()即可。第一个参数为定位方式,第二个参数为元素名称。
# id方式
loadmore <- remDr$findElement(using = "id", value = "load-more-trigger")
# css方式
loadmore <- remDr$findElement(using = "css", "#load-more-trigger")
1.2.4 将操作传递给元素
- 点击操作click
(1) 直接单击操作:clickElement()
loadmore$clickElement()
(2) 如果要控制点击的左右键:click(buttonId=0/1/2)
click(buttonId = 0)
0单击左键,1单击滚动条,2单击右键。
(3) 双击:doubleclick()
doubleclick(buttonId = 0)
- 模仿鼠标的一些其他操作,如使用滚轮滑到页面最下端
bottom <- remDr$findElement("css", "body")
bottom$sendKeysToElement(list(key = "end")) #“滚动到最下端”
sendKeysToElement()功能主要用于在指定元素中输入文本。一般是先使用findelement()定位到该元素,再使用sendKeysToElement()进行内容与操作的传递。sendKeysToElement()的参数必须为list形式。
- 传递文本信息
query <- remDr$findElement(using = "css", "#suggestion-search")
query$sendKeysToElement(list("The Godfather", key = "enter"))
# 输入文本the godfather, 然后回车搜索
1.2.5 检索页面源代码
正如前面getCurrentUrl()步骤所说,在进行完一系列操作后,我们需要获得此时的url,然后才能进行接下来的爬取工作。
page_source <- remDr$getPageSource()[[1]]
remDr$getCurrentUrl()
page_source %>% read_html()
2. 爬取IMDb电影网的数据
(1)安装相应的package
library(tidyverse)
library(rvest)
library(xml2)
library(RSelenium)
library(netstat)
(2)从电影网首页出发,获取其HTML文件
# 使用read_html()下载IMDB首页的html文件
webpage <- read_html("https://www.imdb.com/chart/moviemeter?sort=rk,asc&mode=simple&page=1")
webpage
(3)使用html_nodes() %>% html_attrs(),获取排行榜中各电影主页的链接
# 从首页信息出发,提取100部电影首页的网址
website <- html_nodes(webpage, "td.titleColumn a") %>% html_attr("href")
# 使用paste()将url补充完整
website_title <- paste("http://www.imdb.com",website,sep = "")
由于提取的URL缺少部分内容,我们使用字符串拼接paste()函数将其补全
paste(..., sep = " ", collapse = NULL)
① ...:需要拼接的文本
② sep:使用什么符号将文本分隔开,default = 空格
③ collapse:若不指定值(default = NULL),则结果返回由sep中指定符号连接而成的字符型向量;若指定值(如“,”),则将字符型向量间通过collapse的值连接形成一个字符串
(4) 由于各电影主页中包含多种“评论”的链接,我们需要在各电影首页提取user reviews的网址
review_page <- c()
for (i in 1:100){
all_page <- read_html(website_title[i])
reviews <- html_nodes(all_page, ".isReview") %>% html_attr("href")
# 上一步会返回user/critic/metascore 三个网址,在这里只保留返回的第一个结果
review_page <- c(review_page, reviews[1])
}
# 补充url
review_title <- paste("http://www.imdb.com",review_page,sep = "")
review_title
·定义review_page()为一个空的向量,在每次读取URL后将新的内容补充进去。
·使用paste补充网址,将结果存储到review_title变量中。
(5)使用RSelenium对网页进行操作
# 连接chrome浏览器
rs_driver_object <- rsDriver(browser = "chrome", chromever = "106.0.5249.61",
verbose = F, port = free_port())
remDr <- rs_driver_object$client
# total用于存储所有页面的评论与评分信息
total <- data.frame()
在100部电影的user reviews页面,我们需要勾选“隐藏剧透”的单选框,并通过点击load more键,获取100条评论及其评分。
① 对于review_title中的网址,我们需要将其转换为character格式,然后再进行navigate导航。
② 隐藏剧透:使用findElement进行定位,通过clickElement点击单选框
③ 加载更多:
A. 在不点击的情况下,一个界面提供25条评论;
B. 确认该电影的评论数量:使用read_html()读取界面HTML文档,定位至评论数量。由于返回的文本格式为“xxx Reviews”,我们使用字符串截取substr()函数进行文本提取。
substr(s, first, last)
① s:需要处理的字符串
② first:起始位置(包含在内)
③ last:结束位置(包含在内)
【nchar:确认字符串长度】
我们需要将上一步的评论数量转化为数值型,以便进行下一步判断。如果评论数量上千会出现分位符,我们使用替换字符gsub()函数将其消掉。
gsub("目标字符", "替换字符", 对象)
然后使用if else语句进行判断。
(6) 爬取100条评论:
将Rselenium操作后的网址保存,再使用read_html读取其HTML文件。将评论区的一整块保存到all变量中。
对于该电影的所有评论(seq_along(all)),如果评分存在,则读取其评分与评论内容。
判断评分是否存在的代码为:length != 0 ,如果不存在则是空值,其长度为0,也就不进行接下来的操作。
使用rbind()函数,将每一次读取的评分与评论内容补充到dataframe中。
(record用于存储某一部电影的内容;total用于存储全部内容)
for (i in 1:100){
url <- as.character(review_title[i])
remDr$navigate(url)
# remDr$refresh()
# 隐藏剧透
hide <- remDr$findElement(using = "xpath", value = "//*[@id='main']/section/div[2]/div[1]/form/div/div[1]/label/span[1]")
hide$clickElement()
# 加载更多
thispage <- read_html(url)
numreview <- c()
# 读取当前页面的评论数量,用于分析如何进行点击操作
numreview <- html_nodes(thispage,"#main > section > div.lister > div.header > div > span") %>%
html_text(trim = TRUE) %>% substr(1,nchar(.)-8)
numreview <- as.numeric(gsub(",","", numreview))
if (numreview >= 25){
loadmore <- remDr$findElement(using = "id", value = "load-more-trigger")
loadmore$clickElement()# 一次会出现25条评论,点4次即可获得100条评论
Sys.sleep(2) # 由于网速限制,中间需要有间隔时间暂停
loadmore$clickElement()
Sys.sleep(2)
loadmore$clickElement()
Sys.sleep(2)
loadmore$clickElement()
} else {
Sys.sleep(1)
}
# 获取前面步骤已完成后的网址,用于后续爬取工作
page_source <- remDr$getPageSource()[[1]]
remDr$getCurrentUrl()
page_source <- read_html(page_source)
# all中存储了每一个评论块的xml文件
all <- html_nodes(page_source, "div.review-container")
# records用于存储当前页面的评论与评分信息
records <- data.frame()
# 爬取当前页面的评论与评分
for (j in seq_along(all)){
#设置判断:避免评分空值
if (html_nodes(all[j], "span.rating-other-user-rating") %>% length != 0){
nodes <- html_nodes(all[j], "span.rating-other-user-rating") %>%
html_text(trim = TRUE) %>% substr(1,nchar(.)-3)
notes <- html_nodes(all[j], "div.text.show-more__control")%>% html_text(trim = TRUE)
}
# 设置一个新的dataframe,用于存储每一次新爬取的评论与评分信息
new_record <- data.frame(RANKS = nodes, REVIEWS = notes)
# 将新的信息组合到records中。
records <- rbind(records, new_record)
}
# 每一次循环的信息保存到total的数据框中
total <- rbind(total, records)
}
# 保存爬取的所有文件
write_excel_csv(total, "111.csv")
在这里使用write_excel_csv()函数保存内容。用了其他的保存文件函数都出现了乱码...设置encoding = UTF8也不行,只有这个函数是好用的。如果出现乱码大家也可以自行百度,多试试几个函数。
这样,我们就爬取了100部电影及其评论文本&评论评分!
版权归原作者 Evelyyyyyyyyyn_ 所有, 如有侵权,请联系我们删除。