
强化学习(RL)的许多应用都是专门针对将人工从训练循环中脱离而设计的。例如,OpenAI Gym [1]提供了一个训练RL模型以充当Atari游戏中的玩家的框架,许多问扎根都描述了将RL用于机器人技术。但是,一个通常讨论不足的领域是应用RL方法来改善人们的主观体验。
为了演示这种类型应用,我开发了一个简单的游戏,叫做“Trials of the Forbidden Ice Palace” [2]。该游戏使用强化学习,通过为用户量身定制游戏难度来改善用户体验。
游戏如何运作
该游戏是传统的Roguelike游戏:具有RPG元素和大量程序生成的基于回合的地牢探索类游戏。玩家的目标是逐层逃离冰宫,与怪物战斗并沿途收集有用的物品。传统上会随机生成出现在每层楼上的敌人和物品,但该游戏允许RL模型根据收集到的数据生成这些实体。
众所周知,强化学习算法需要大量数据,因此在创建游戏时要遵循以下约束条件,以减少RL模型的复杂性:
1)游戏共有10层,之后玩家获得了胜利
2)每层可以产生的敌人和物品的数量是固定的
强化学习和环境
强化学习的核心概念是自动代理(Agent)通过观察和采取行动(Action)与环境(Env)相互作用,如图1所示。通过与环境的互动,代理可以获得奖励(积极的或消极的),代理利用这些奖励来学习和影响未来的决策。

对于这个应用程序,代理是RL算法,它根据它选择生成的实体来调整游戏的难度,游戏是RL算法可以观察和控制的环境。
状态 State
状态是指代理对环境所做的任何观察,可以用来决定采取哪些行动。虽然有大量的不同的数据代理可能观察(玩家血量,玩家所需的回合数,等),游戏的第一个版本的变量只考虑地板已达到和玩家的水平的玩家的性格。
行动 Actions
由于游戏的程序生成特性,代理将决定随机生成怪物/道具,而不是每次都有一个确定性的决定。由于游戏中存在大量的随机性元素,代理并不会以典型的RL方式进行探索,而是控制不同敌人/道具在游戏中生成的加权概率。
当代理选择行动时,基于迄今为止学习到的最佳模式,它将通过学习到的Q矩阵加权随机抽样来决定在游戏中产生哪个敌人/道具;反之,如果代理选择探索,代理就会从游戏中所有实体中产生概率相等的敌人/物品。
奖励 Reward
强化学习算法的奖励模型对于开发学习的模型应显示的预期行为至关重要,因为机器学习都会采用走捷径的方法来实现其目标。由于预期的目标是使玩家获得最大的享受,因此做出了以下假设,以根据RL算法的奖励来量化乐趣:
-玩家在游戏中进一步前进,而不是过早死亡会对玩家产生更多乐趣
-在没有挑战的情况下玩家每次获胜的游戏都会很无聊
考虑到这些目标,当玩家进入表I所示的新楼层时,以及如表II所述的游戏完成时,RL模型都会获得奖励。
表一:玩家晋升奖励模型
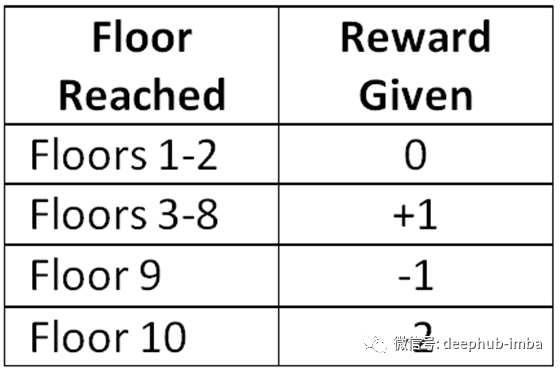
表二:完成游戏的奖励模式

考虑到上面的进程和完成分数机制,RL算法将通过允许玩家前进到第8层而最大化奖励,在这一点上玩家将最终遭遇死亡。为了最小化意外行为的可能性,RL算法也会因为玩家过早死亡而受到惩罚。
更新模型
RL算法采用了Q-Learning,该算法经过改进以适应Agent执行的随机行为。在传统的Q-Learning[3]中,一个代理在每个状态之间采取1个行动,而在此基础上,代理的行动将根据在地板上生成的所有敌人/物品的概率分布进行更新,如下式所示。

其中Q'(s_t,a_t)是Q矩阵的更新值,Q(s_t,a_t)是状态s的Q矩阵,并且在时间步长t上有一对动作,α是学习率,r_t是提供的奖励 从过渡到状态t + 1时,γ是折现因子,上划线分量是基于时间步t + 1的平均回报对未来价值的估计。
通过GCP实现全局化RL训练
全局AI模型使用所有玩家收集的游戏数据进行训练,当玩家还没有玩过游戏时,全局AI模型作为基础RL模型。新玩家在第一次开始游戏时将获得全局化RL模型的本地副本,这将在他们玩游戏时根据自己的游戏风格进行调整,而他们的游戏数据将用于进一步增强全局AI模型,供未来的新玩家使用。

图2所示的架构概述了如何收集数据以及如何更新和分发全局模型。使用GCP是因为他们的免费使用产品最适合收集和存储游戏数据的模型训练[4]。在这方面,游戏会例行地调用GCP的云函数来存储Firebase数据库中的数据。
结论
本文介绍的工作描述了如何使用强化学习来增强玩家玩游戏的体验,而不是更常见的用于自动化人类动作的RL应用程序。我们使用免费GCP架构的组件收集所有玩家的游戏会话数据,从而创建全局RL模型。虽然玩家开始游戏时使用的是全局RL模式,但他们的个人体验会创造一个定制的局部RL模式,以更好地适应自己的游戏风格。
参考
[1] OpenAI Gym, https://gym.openai.com
[2] RoguelikeRL — Trials of the Forbidden Ice Palace, https://drmkgray.itch.io/roguelikerl-tfip
[3] Kaelbling L. P., Littman M. L., & Moore A. W. (1996). Reinforcement Learning: A Survey. Journal of Artificial Intelligence Research, 4, 237–285. https://arxiv.org/pdf/cs/9605103.pdf
[4] GCP Free Tier, https://cloud.google.com/free
作者:Matt Gray
deephub翻译组