
又来写笔记了~今天是Task2,我也算是个deadliner了,一直都赶在最后提交。
学习目标
- 学习如何加载和微调预训练模型,以加快训练过程并提高模型性能。
- 掌握模型训练的各个步骤,包括前向传播、损失计算、反向传播和参数更新。
- 如何通过准确率等指标评估模型性能,并进行相应的优化。
写在前面
Task2的内容在Task1的基础上更深入了一些,上次是初窥的话,这次就是深入入门了,已经进了深度学习这扇大门了,哈哈哈哈哈哈。之前就是扒在门框上偷偷看了几眼。言归正传,使用手册因为涉及的内容太多,所以讲的相对浅一些,其中涉及代码的部分也不多,主要是原理,并且更多的内容还需要大家自行查阅。代码的话则主要是项目里提到的notebook,直播里也有提到,然后进行微调的话,直播里也讲到了,我今天的微调及score提高也是根据他的baseline稍微改的哈~
整体内容分成两大部分,深度学习进一步的介绍及深度学习的训练,其次还有迁移学习以及列举的常见的图像分类网络。
深度学习进一步介绍
深度学习使用神经网络模拟人脑的学习方式,依赖于多层神经网络,每一层神经元接受前一层神经元的输出,并通过权重和激活函数进行计算,传递到下一层神经元。
那么此时我们就应该好奇了,神经元是什么,是生物里的神经元吗?是神经系统最基本的结构和功能单位,分为细胞体和突起两部分吗?在这里显然不是,虽然是仿照人脑的模式来的,但是在这里的神经元模型是一个数学模型,是人们根据神经元的功能类似创立的具有相似功能的数学模型。
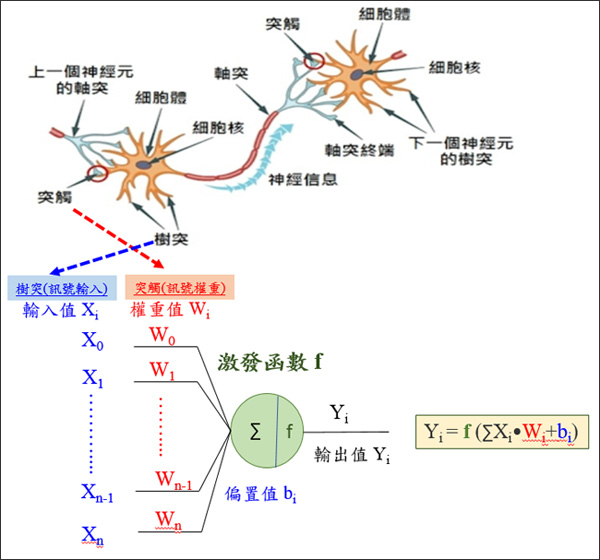
一个简单的神经元模型包括输入、权重、激活函数和输出。
- 输入就像神经元 树突 接收到的信号,
- 权重则像是调整信号强度的小调节器,
- 激活函数决定是否产生输出,
- 输出则是传递给其他神经元的信号。
深度学习则是由这些神经元模型层层堆叠起来的复杂结构。深度将它们按照一定的层次连接起来,形成一个庞大的网络。这个网络的最底层接收输入数据,比如图片或文本,然后通过每一层的处理,逐渐提取出更高级别的特征,最后在顶层输出结果。
从最基础的神经元模型出发,科学家们逐步构建了越来越复杂的神经网络模型,最初科学家们从模拟单个神经元的行为开始,创建了简单的神经元模型,这些模型能够接收输入信号并产生输出。这些基础模型为后续更复杂结构的构建奠定了基础。随着对神经元理解的加深,科学家们开始将这些基本的神经元模型组合起来,形成了多层次的网络结构。这些网络,我们称之为神经网络,它们能够在各个层次上处理和传递信息,就像大脑中的神经回路一样。他们设计了一系列实验,使用不同类型的数据集来训练这些网络,比如图像、文本或声音数据。
为了进一步提高模型的准确性和泛化能力,科学家们引入了各种优化技术和算法,如
- 激活函数Activation Fuction的改进
- 权重初始化Weight Initilization方法
- 正则化技术Normalization以及
- 梯度下降的变种G****radient Gescent Optimization Algoritms 。
- 他们还开发了新的网络结构Network Structure,如卷积神经网络(CNN)和循环神经网络( RNN ),以适应不同类型的数据和任务。
深度学习的训练
深度学习能够通过大量的数据和反复的训练来自动调整这些小开关(权重)的设置,使得整个网络能够越来越准确地完成特定的任务。
那么如何衡量完成任务的准确性呢,我们有真实值和预测值,是否可以通过衡量他们直接的差异来衡量我的效果呢?答案显然是肯定的,我们给他起个名词,就叫做损失函数。在深度学习中,我们希望最小化损失函数,使模型预测值与真实值之间的差异变小。
那么如何缩小他们之间的差异,最小化损失函数呢?我们引入了数学里的梯度。梯度是损失函数关于模型参数的导数,它指示了参数的调整方向,我们可以借此减少损失函数的值。
梯度下降
梯度下降是一种优化算法,用于最小化函数。
梯度下降算法基于这样一个原理:损失函数的梯度指向函数增长最快的方向。
因此,如果我们希望减少损失函数的值,我们就需要沿着梯度的反方向调整模型的参数。
这样,每次迭代都会使模型参数朝着减少损失的方向移动。
在训练循环中,我们首先加载一小批量数据,将其输入到神经网络中进行前向传播,计算出网络的输出。
然后,我们使用损失函数来计算当前批次的损失,并通过反向传播算法计算损失函数关于每个参数的梯度。根据这些梯度,调整权重和偏置以减少损失。
特殊情况
当数据集非常大时,一次性处理所有数据可能会导致内存不足或计算过于缓慢。通过将数据分成小批量,我们可以更频繁地更新模型参数,以使得训练过程更加高效。
Pytorch训练代码
回顾一下Task1 的PyTorch 代码,我们在训练一个分类模型。
def train(train_loader, model, criterion, optimizer, epoch):
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# compute output output = model(input)
loss = criterion(output, target)
optimizer.zero_grad()
# compute gradient and do SGD step
loss.backward()
optimizer.step()
首先,我们需要准备一批图片数据(通过
train_loader
)和这些图片对应的正确标签(
target
)。
在开始训练之前,将模型设置为训练模式(
model.train()
),这样模型就知道现在是学习时间了。
接着,开始喂给模型图片数据,并让它尝试预测这些图片的内容。
模型会基于它目前的学习给出预测结果(
output
),而会计算这些预测结果与实际标签之间的差异,这个差异就是损失(
loss
)。
为了让模型学会准确预测,需要指出它的错误,并更新它的内部参数来减少这些错误(通过
loss.backward()
和
optimizer.step()
)。
这个过程就像是模型在自我调整,以便在下一次遇到类似图片时能够做出更准确的预测。
迁移学习
迁移学习是一种机器学习技术,它将已在一个任务上学到的知识(如模型参数、特征表示等)应用到另一个相关任务上。它在模型数据稀缺的情况下也能表现出色。
通常使用在大规模数据集上预训练的模型作为起点,在预训练模型的基础上,使用少量标记数据对模型进行微调,以适应新任务。
实现方法
微调(Fine-tuning)是深度学习中一种有效的迁移学习策略,它允许我们利用预训练模型对特定任务进行优化。其基本原理是,首先在一个大规模的数据集上预训练一个深度学习模型,捕捉通用的特征表示,然后将这个预训练模型作为起点,在目标任务上进行进一步的训练以提升模型的性能。
微调的过程通常开始于选择一个在大型数据集上预训练的模型,这个预训练模型已经学到了丰富的特征表示,这些特征在广泛的领域内都是通用的。接着,我们将这个预训练模型适配到新的目标任务上。适配过程通常涉及以下步骤:
- 我们会替换模型的输出层,以匹配目标任务的类别数量和类型。例如,如果目标任务是图像分类,而预训练模型原本用于不同的分类任务,我们就需要将模型的最后一层替换成适合新任务类别数的新层。
- 【可做可不做】我们冻结预训练模型中的大部分层,这样可以防止在微调过程中这些层学到的通用特征被破坏。通常情况下,只对模型的最后一部分层进行解冻,这些层负责学习任务特定的特征。
- 使用目标任务的数据集对模型进行训练。在这个过程中,我们会用梯度下降等优化算法更新模型的权重,从而使模型能够更好地适应新的任务。训练时,可能会使用比预训练时更低的学习率,以避免过度拟合目标数据集。
在下面代码中,
timm.create_model('resnet18', pretrained=True, num_classes=2)
这行代码就是加载了一个预训练的ResNet-18模型,其中
pretrained=True
表示使用在ImageNet数据集上预训练的权重,
num_classes=2
表示模型的输出层被修改为有2个类别的输出,以适应二分类任务(例如区分真实和Deepfake图像)。通过
model = model.cuda()
将模型移动到GPU上进行加速。
import timm model = timm.create_model('resnet18', pretrained=True, num_classes=2)
model = model.cuda()
常见的图像分类网络
图像分类是计算机视觉中的一个基本任务,它涉及到将给定的图像分配到一个或多个预定义的类别中。随着深度学习的发展,已经设计出许多不同的卷积神经网络(CNN)架构来提高图像分类的准确率。
AlexNet,https://en.wikipedia.org/wiki/AlexNet
AlexNet是一种具有深远影响的卷积神经网络(CNN)架构,由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton设计。
它在2012年的ImageNet大规模视觉识别挑战赛(ILSVRC)中取得了突破性的成绩,大幅度超越了之前的图像分类技术(非深度学习技术)。
AlexNet包含八个层次结构,前五个是卷积层,其中一些后跟最大池化层,最后三个是全连接层。具体结构如下:
- 卷积层:AlexNet的前五个层次都是卷积层,每个卷积层后面跟着一个ReLU激活函数,以引入非线性。这些卷积层旨在提取图像的特征。
- 局部响应归一化(LRN):在某些卷积层后使用了局部响应归一化,这是一种提高模型泛化能力的正则化方法。
- 最大池化层:在部分卷积层之后使用最大池化层来降低特征的空间维度,减少计算量和过拟合的风险。
- 全连接层:网络的最后三个层次是全连接层,其中最后两个全连接层后跟有Dropout,以进一步防止过拟合。
- 输出层:最后一个全连接层后是线性层,然后是softmax激活函数,输出1000个类别上的概率分布。
ResNet,https://en.wikipedia.org/wiki/Residual_neural_network
ResNet(残差网络)是一种深度卷积神经网络架构,由微软研究院的研究员何恺明等人提出。ResNet在2015年的ImageNet图像识别大赛中取得了冠军,并在深度学习领域产生了重大影响。它的主要创新点是引入了残差学习的概念,允许训练非常深的网络,从而缓解了深度神经网络训练中的梯度消失和梯度爆炸问题。
ResNet的核心是残差块(residual block),网络通过堆叠这些残差块来构建。一个基本的残差块包含以下几部分:
- 跳跃连接(Skip Connections):这是ResNet最关键的创新,通过跳跃连接,输入可以直接绕过一个或多个层传到输出,输出是输入与这些层的输出的加和。这种结构使得网络可以学习输入到输出的残差,而不是直接学习输出,这有助于缓解梯度消失问题。
- 卷积层:残差块内部包含多个卷积层,通常使用小尺寸的卷积核(如3x3),并且通常会有批量归一化(Batch Normalization)和ReLU激活函数。
- 池化层:在某些残差块之间会插入最大池化层来降低特征图的空间维度。
ResNet有多个变种,包括ResNet-50、ResNet-101、ResNet-152等,数字代表了网络中权重层的数量。这些变种在网络的深度和宽度上有所不同,但都基于相同的残差学习架构。
ResNet能够成功训练超过100层的网络,这在之前是不可能实现的。
EfficientNet,https://paperswithcode.com/method/efficientnet
EfficientNet是一种高效的卷积神经网络(CNN)架构,它通过一种新颖的网络缩放方法来提升模型的性能和效率。EfficientNet 的核心是其 compound scaling 方法,该方法通过一个复合系数统一缩放网络的深度、宽度和分辨率。在过去,网络缩放通常是通过任意选择深度、宽度或分辨率的增加来实现的,而EfficientNet的方法则是通过一系列固定的缩放系数来同时增加这三个维度。例如,如果想要使用更多的计算资源,可以通过增加网络深度、宽度和图像大小的特定比例来实现,其中的比例系数是通过在小型模型上进行小规模的网格搜索确定的。
EfficientNet的复合缩放方法的直觉在于,如果输入图像更大,网络就需要更多的层来增加感受野,以及更多的通道来捕捉更细粒度的模式。EfficientNet的架构本质上并不复杂。基本的EfficientNet-B0网络作为后续缩放的基础。作者指出,他们使用NAS来构建基本网络,利用了多目标搜索来同时优化网络的准确性和计算效率。
今日score提升
首先友情放上我参考的链接,表示诚挚的感谢,虽然我没有达到作者的最好成绩,但是也算是提升了一点点。https://www.kaggle.com/code/chg0901/0-98-deepfake-ffdi-ways-to-defeat-0-86-beseline
以下是我的score,最下面的是第一次提交的,最上面的是最新的。
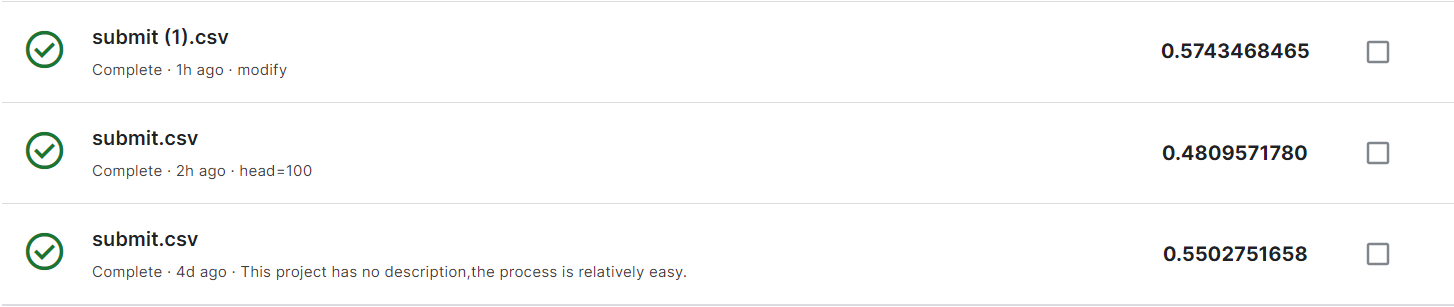
主要改动有以下几个部分,
train_label.head(100)
import timm
model = timm.create_model('resnet50', pretrained=True, num_classes=2)
model = model.cuda()
batch_size=32
for epoch in range(10):
进行了head数量、模型的修改,也修改了epoch及batch的size,最终的效果是0.5743,之后继续努力~
版权归原作者 Amelia&pku 所有, 如有侵权,请联系我们删除。