
FPN(feature pyramid network)
FPN是目标检测中用于多尺度物体检测的重要工具。高层特征,语义信息丰富,但目标位置模糊;低层特征,语义信息较少,但目标位置清晰。FPN通过融入特征金字塔,将高层特征与低层特征进行融合,将高语义信息传递给低层特征,提高了目标检测的准确率,尤其是小物体的检测上。
网络结构
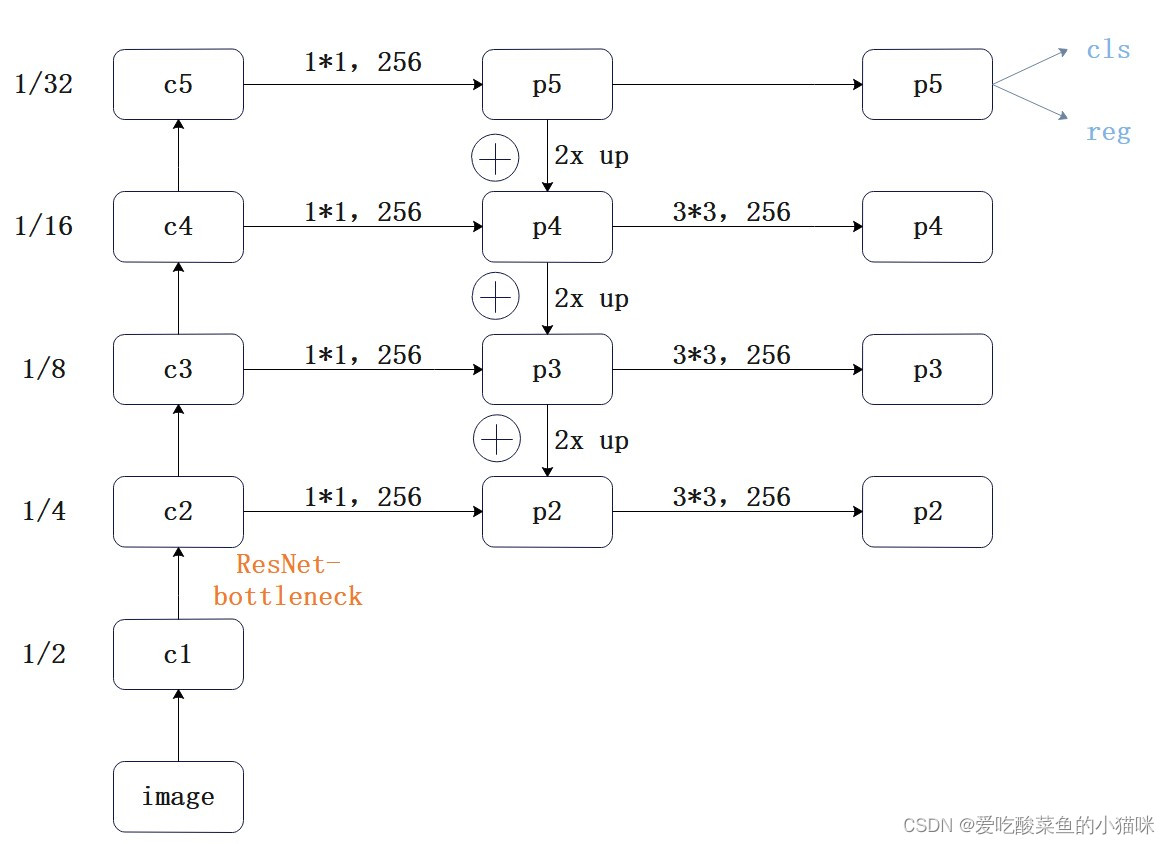
采用自底向上、横向连接以及自底向下三种结构。其中自底向上时采用ResNet的bottleneck,每一层特征图的尺寸均为上一层的1/2;横向连接时采用1*1卷积来降低维度,输出通道数均为256;自底向下时将高层特征2倍上采样,此时特征图大小与低层特征相同,因此与低层特征融合。
特征融合完之后,进行一个3*3的卷积,最终得到本层的特征输出p2-p5。使用这个3*3卷积的目的是为了消除上采样产生的混叠效。混叠效应,指经过上采样插值后生成的图像灰度不连续,在灰度变化的地方可能出现明显的锯齿状。金字塔所有层的输出特征都共享 分类cls/回归reg,所以3*3卷积输出的维度都被统一为256。
bottleneck
采用ResNet的bottleneck
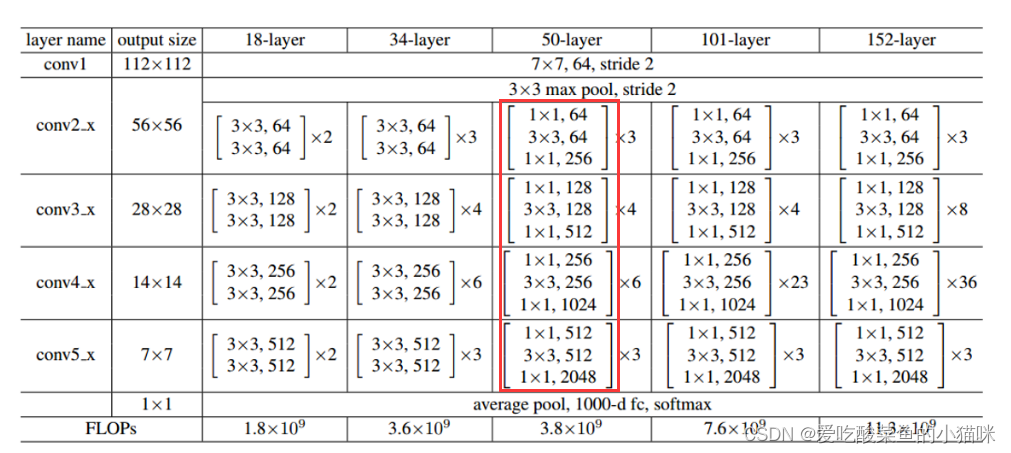
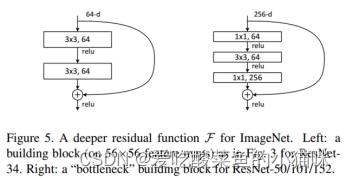
使用右侧的bottleneck(ResNet50 101 152中采用的backbone):对输入特征进行1*1卷积 bn relu -> 3*3卷积 bn relu -> 1*1卷积 bn(输出通道数为输入通道数的4倍,即通道扩增数=4)后,与输入特征相加,经过relu激活函数输出。
pytorch代码实现
import torch.nn as nn
import torch.nn.functional as F
# ResNet基本的Bottleneck类(Resnet50/101/152)
class Bottleneck(nn.Module):
expansion = 4 # 通道扩增倍数(Resnet网络的结构)
def __init__(self,in_planes,planes,stride=1,downsample=None):
super(Bottleneck, self).__init__()
self.bottleneck=nn.Sequential(
nn.Conv2d(in_planes,planes,kernel_size=1,bias=False),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True),
nn.Conv2d(planes, planes, kernel_size=3,stride=stride, padding=1,bias=False),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True),
nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False),
nn.BatchNorm2d(self.expansion*planes),
)
self.relu=nn.ReLU(inplace=True)
self.downsample=downsample
def forward(self, x):
identity = x # 初始的x
out = self.bottleneck(x)
# 残差融合前需保证out与identity的通道数以及图像尺寸均相同
if self.downsample is not None:
identity = self.downsample(x) # 初始的x采取下采样
out += identity
out = self.relu(out)
return out
class FPN(nn.Module):
'''
FPN需要初始化一个list,代表ResNet每一个阶段的Bottleneck的数量
'''
def __init__(self, layers):
super(FPN, self).__init__()
# 构建C1
self.inplanes = 64
self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 自下而上搭建C2、C3、C4、C5
self.layer1 = self._make_layer(64, layers[0])
self.layer2 = self._make_layer(128, layers[1], 2) # c2->c3第一个bottleneck的stride=2
self.layer3 = self._make_layer(256, layers[2], 2) # c3->c4第一个bottleneck的stride=2
self.layer4 = self._make_layer(512, layers[3], 2) # c4->c5第一个bottleneck的stride=2
# 对C5减少通道,得到P5
self.toplayer = nn.Conv2d(2048, 256, 1, 1, 0) # 1*1卷积
# 横向连接,保证每一层通道数一致
self.latlayer1 = nn.Conv2d(1024, 256, 1, 1, 0)
self.latlayer2 = nn.Conv2d(512, 256, 1, 1, 0)
self.latlayer3 = nn.Conv2d(256, 256, 1, 1, 0)
# 平滑处理 3*3卷积
self.smooth = nn.Conv2d(256, 256, 3, 1, 1)
# 构建C2到C5
def _make_layer(self, planes, blocks, stride=1, downsample = None):
# 残差连接前,需保证尺寸及通道数相同
if stride != 1 or self.inplanes != Bottleneck.expansion * planes:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, Bottleneck.expansion * planes, 1, stride, bias=False),
nn.BatchNorm2d(Bottleneck.expansion * planes)
)
layers = []
layers.append(Bottleneck(self.inplanes, planes, stride, downsample))
# 更新输入输出层
self.inplanes = planes * Bottleneck.expansion
# 根据block数量添加bottleneck的数量
for i in range(1, blocks):
layers.append(Bottleneck(self.inplanes, planes)) # 后面层stride=1
return nn.Sequential(*layers) # nn.Sequential接收orderdict或者一系列模型,列表需*转化
# 自上而下的上采样
def _upsample_add(self, x, y):
_, _, H, W = y.shape # b c h w
# 特征x 2倍上采样(上采样到y的尺寸)后与y相加
return F.upsample(x, size=(H, W), mode='bilinear') + y
def forward(self, x):
# 自下而上
c1=self.relu(self.bn1(self.conv1(x))) # 1/2
# c1=self.maxpool(self.relu(self.bn1(self.conv1(x)))) 此时为1/4
c2 = self.layer1(self.maxpool(c1)) # 1/4
c3 = self.layer2(c2) # 1/8
c4 = self.layer3(c3) # 1/16
c5 = self.layer4(c4) # 1/32
# 自上而下,横向连接
p5 = self.toplayer(c5)
p4 = self._upsample_add(p5, self.latlayer1(c4))
p3 = self._upsample_add(p4, self.latlayer2(c3))
p2 = self._upsample_add(p3, self.latlayer3(c2))
# 平滑处理
p5 = p5 # p5直接输出
p4 = self.smooth(p4)
p3 = self.smooth(p3)
p2 = self.smooth(p2)
return p2, p3, p4, p5
FPN(layers=[5,5,5,5])
# 传入生成c2 c3 c4 c5特征层的bottleneck的堆叠数量,返回p2 p3 p4 p5
公式:卷积层输入输出大小的计算公式
卷积层输出feature map大小计算公式: (一般向下取整)
孔洞卷积 k' = d(k-1) + 1;非孔洞卷积的d=1,因此k'=k。
o是输出尺寸(H或W),i 是输入尺寸(H或W), k 是卷积核尺寸,p是 padding大小, s是stride步长, d是空洞卷积dilation膨胀系数。
注意:池化过程的尺寸变化同卷积过程。
细节一:代码中blocks参数的含义
最后一行需要传入产生c2 c3 c4 c5特征层的bottleneck的堆叠数量(可以设置不同的参数)。例如:ResNet50中block参数为[3,4,6,3],即c2层需c1层经过Maxpool以及3层bottleneck的堆叠,c3层需要c2层经过4层bottleneck的堆叠,以下层同理。
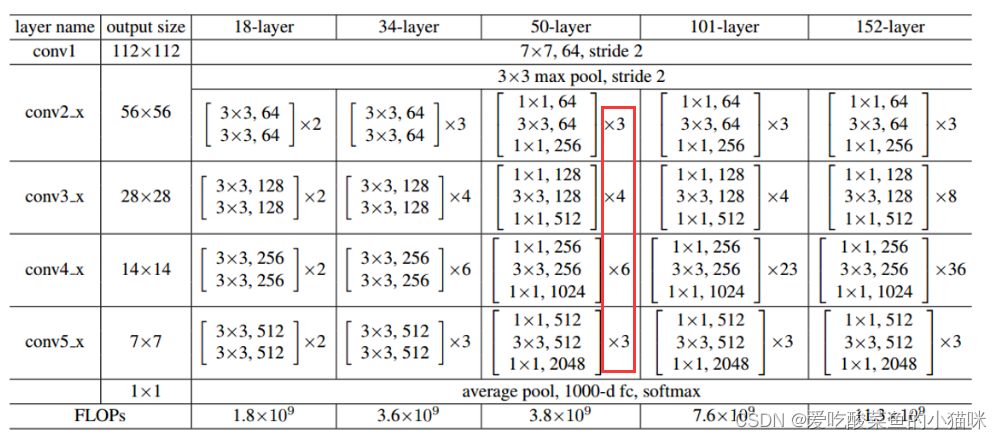
细节二:c1 c2 c3 c4 c5层尺寸分别为原图的1/2 1/4 1/8 1/16 1/32
c1层特征代码很多通常写为c1=self.maxpool(self.relu(self.bn1(self.conv1(x)))),但其实maxpool操作在c1->c2过程中。因此采用下面的方法:
c1 = self.relu(self.bn1(self.conv1(x))) # 1/2
c2 = self.layer1(self.maxpool(c1)) # 1/4
此时,c1为第一个特征图,根据卷积层输入输出计算公式,由于conv1步长为2,因此尺寸变为原图的1/2。c2特征,由于self.maxpool层,因此尺寸变为c1特征图的1/2,即原图的1/4。c3 c4 c5特征图可使用公式同样计算尺寸。因此,自底向上的过程,相邻层特征图尺寸减半,通道数变为原来的2倍。
细节三:bottleneck实现过程中,原始特征进行下采样
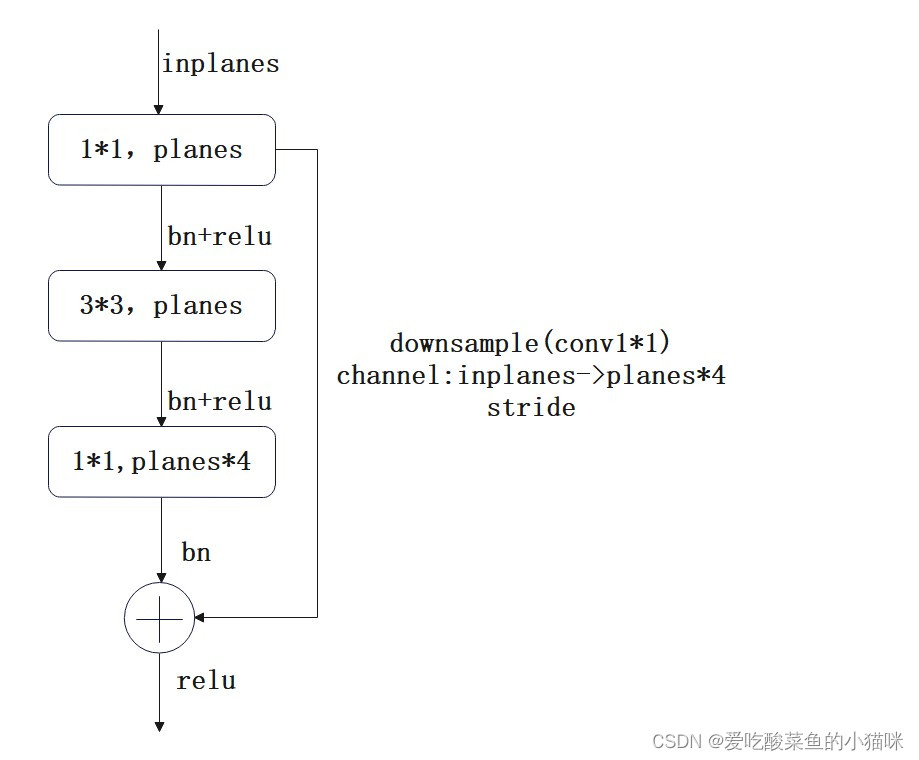
由于ResNet网络需将输出特征与原始特征进行相加,需要特征层尺寸相同且通道数相同,因此原始特征x需要进行下采样downsample,经过1*1卷积,将通道数变为4*planes。
关于步长,ResNet中c1->c2层,maxpool层使得尺寸减半,因此卷积层步长stride=1(不改变特征图大小);c3 c4 c5层的生成过程无池化过程,因此第一个block的bottleneck步长设置为2(使特征图宽高减半),后续bottleneck的堆叠,步长为1(不改变特征图尺寸)。
本文转载自: https://blog.csdn.net/m0_63077499/article/details/128025454
版权归原作者 爱吃酸菜鱼的小猫咪 所有, 如有侵权,请联系我们删除。
版权归原作者 爱吃酸菜鱼的小猫咪 所有, 如有侵权,请联系我们删除。