

记录备忘。
总体而言,yolov4是尝试组合一堆tricks,获取得到的模型,该模型具有训练更快、模型更轻、精度更高的特性。
1. 网络结构的不同
yolov4网络结构可分为以下三部分。与yolov3相比,其中backbone和neck不同,head是一样的。

1.1 Backbone
yolov3是Darknet53, yolov4是CSPDarknet53。
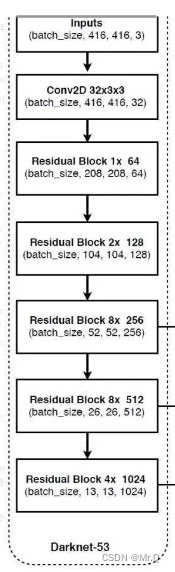
1.1.1 Darknet53
属于全卷积网络结构。
(1)整体可分为1个普通的3x3核,步长为2的卷积,再接5个layer;
(2)每个layer堆叠了大量的残差块Residual Block,且每个layer之间插入一个步长为2,3x3的卷积,完成下采样过程;
(3)如果输入的是416x416,则输出三个尺度:52x52x256, 26x26x512, 13x13x1024.
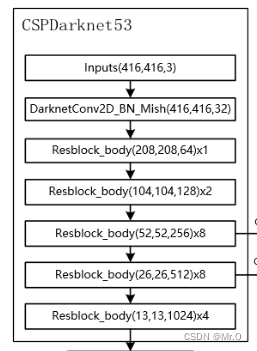
1.1.2 CSPDarknet53
CSPDarknet53是在Darknet53的基础上加了CSP block. csp block的特点是充分利用跨层信息:使用Cross Stage Partial Network结构,将输入特征图分成两个部分,然后通过跨层连接来结合这两个部分的信息。这样可以在减少计算复杂度的同时,提高网络的感受野和特征表达能力。
(1)Darknet53是由一系列residual block组成;
(2)而CSPDarknet53则是在每个卷积层CBM后追加CSP blocks. 如下图所示。
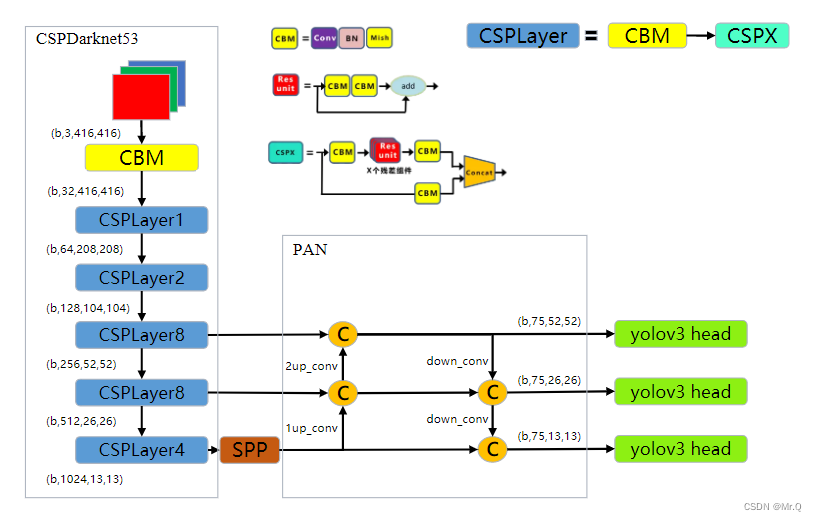
图中CBL = conv + BN + Leaky relu;CBM = conv + BN + Mish. 即激活函数换成平滑非单调的Mish激活函数(后面会详细介绍)。
CSP网络结构
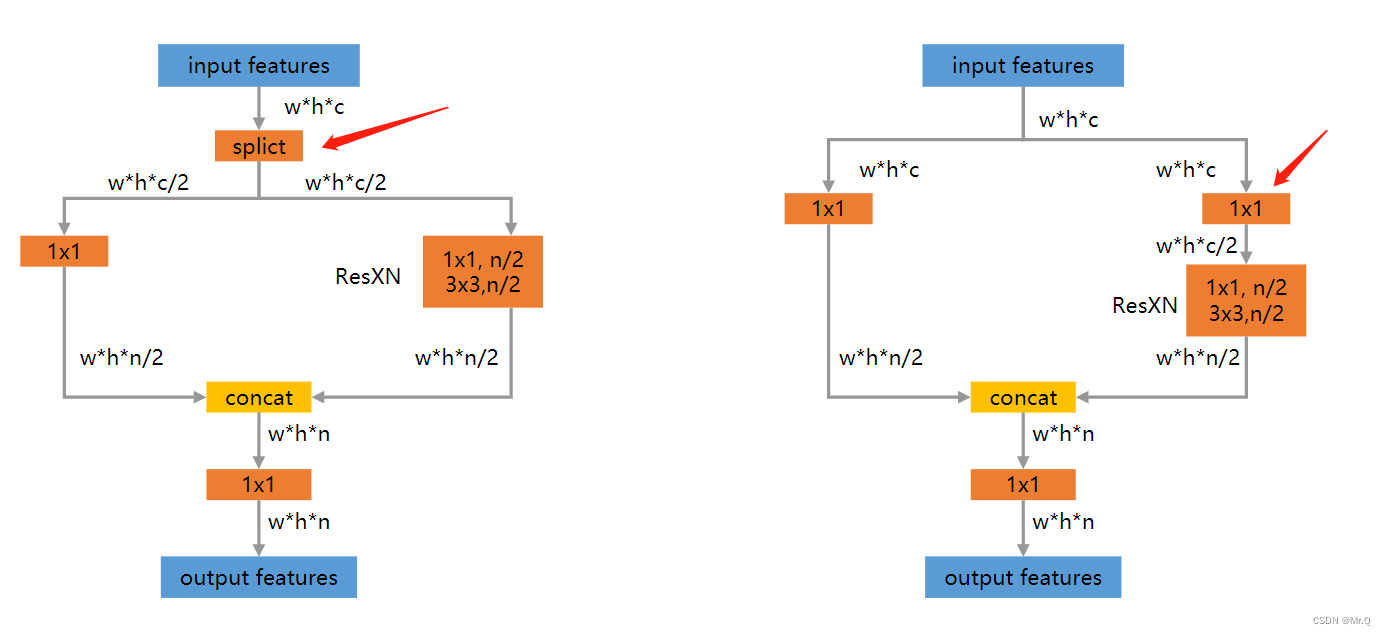
在进入多个残差块之前,左右两种方式都将通道数减半,坐边是简单的splict函数直接拆分通道,右边是通过1x1的卷积。通道数减半后,再进入残差块,计算量就少了。
实际的算法实现通常是采用第二种,一个是方便部署(模型转换时估计不支持split函数),一个是1x1的卷积操作使得两个分支都充分的使用到了输入的全部特征,而不是一半。具体pytorch实现如下所示。

1.1.3 libtorch c++实现CSPDarknet53网络
实现的CSPDarknet53整体结构图如下。

其组件如下。
(1)CBM
conv2d + bn + Mish

(2)CSPLayer
CBM用作下采样(scale/2, channels*2),其中卷积是3x3卷积核,步长是2;
CSPX是csp模块,X是残差块Res unit的个数.

(3)CSPX
csp结构,通过前面两个CBM结构把输入通道减半,其中一个分支进入到多个残差块中,另一个分支不做处理,最后两个分支concat在一起。
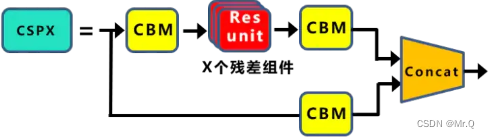
(3)Res unit

实现代码如下。
CSPDarknet53
// CSPDarknet53
class CSPDarknet53Impl : public torch::nn::Module {
public:
CSPDarknet53Impl();
std::vector<torch::Tensor> forward(torch::Tensor x);
private:
CBM conv1{ nullptr };
CSPLayer layer1{ nullptr };
CSPLayer layer2{ nullptr };
CSPLayer layer3{ nullptr };
CSPLayer layer4{ nullptr };
CSPLayer layer5{ nullptr };
}; TORCH_MODULE(CSPDarknet53);
CSPDarknet53Impl::CSPDarknet53Impl() {
conv1 = CBM(3, 32, 1, 1); // 1x1. (b,3,416,416) -> (b,32,416,416).
layer1 = CSPLayer(1, 32, 64); // (b,32,416,416) -> (b,64,208,208).
layer2 = CSPLayer(2, 64, 128); // (b,64,208,208) -> (b,128,104,104).
layer3 = CSPLayer(8, 128, 256); // (b,128,104,104) -> (b,256,52,52).
layer4 = CSPLayer(8, 256, 512); // (b,256,52,52) -> (b,512,26,26).
layer5 = CSPLayer(4, 512, 1024); // (b,512,26,26) -> (b,1024,13,13).
register_module("conv1", conv1);
register_module("layer1", layer1);
register_module("layer2", layer2);
register_module("layer3", layer3);
register_module("layer4", layer4);
register_module("layer5", layer5);
}
std::vector<torch::Tensor> CSPDarknet53Impl::forward(torch::Tensor x) {
x = conv1->forward(x); // 1x1. (b,3,416,416) -> (b,32,416,416).
x = layer1->forward(x); // (b,32,416,416) -> (b,64,208,208).
x = layer2->forward(x); // (b,64,208,208) -> (b,128,104,104).
torch::Tensor x1 = layer3->forward(x); // (b,128,104,104) -> (b,256,52,52).
torch::Tensor x2 = layer4->forward(x1); // (b,256,52,52) -> (b,512,26,26).
torch::Tensor x3 = layer5->forward(x2); // (b,512,26,26) -> (b,1024,13,13).
return std::vector<torch::Tensor>({ x1, x2, x3 }); // (b,256,26,26) (b,512,13,13)
}
CBM
// Mish activation
class MishImpl : public torch::nn::Module {
public:
MishImpl() {}
torch::Tensor forward(torch::Tensor x) {return x * torch::tanh(torch::softplus(x)); }
}; TORCH_MODULE(Mish);
//Conv2d + BatchNorm2d + Mish
class CBMImpl : public torch::nn::Module {
public:
CBMImpl(int in_channels, int out_channels, int kernel_size, int stride = 1);
torch::Tensor forward(torch::Tensor x);
private:
// Declare layers
torch::nn::Conv2d conv{ nullptr };
torch::nn::BatchNorm2d bn{ nullptr };
Mish mish{ nullptr };
}; TORCH_MODULE(CBM);
/// <summary>
/// Conv+Bn+Mish: 通过步长控制是否下采样. 使用了padding操作。
/// </summary>
CBMImpl::CBMImpl(int in_channels, int out_channels, int kernel_size, int stride) :
conv(conv_options(in_channels, out_channels, kernel_size, stride, int(kernel_size / 2), 1, false)),
bn(torch::nn::BatchNorm2d(out_channels)),
mish(Mish())
{
register_module("conv", conv);
register_module("bn", bn);
}
torch::Tensor CBMImpl::forward(torch::Tensor x) {
x = conv->forward(x);
x = bn->forward(x);
x = mish->forward(x);
return x;
}
CSPLayer
// 5个csp layer: 每个layer由一次下采样,加多个csp组成。
class CSPLayerImpl : public torch::nn::Module {
public:
CSPLayerImpl(int res_n, int in_channels, int out_channels);
torch::Tensor forward(torch::Tensor x);
private:
CBM down_conv{ nullptr };
CSPX cspx{ nullptr };
}; TORCH_MODULE(CSPLayer);
CSPLayerImpl::CSPLayerImpl(int res_n, int in_channels, int out_channels) {
down_conv = CBM(in_channels, out_channels, 3, 2); // 2*channels. scale/2.
cspx = CSPX(res_n, out_channels, out_channels); // keep channels and scale unchange.
register_module("down_conv", down_conv);
register_module("cspx", cspx);
}
// cspDarknet一共有5个layer. 每个layer前面都是一个下采样
torch::Tensor CSPLayerImpl::forward(torch::Tensor x) {
x = down_conv->forward(x); // 2*channels. scale/2.
x = cspx->forward(x); // keep channels and scale unchange.
return x;
}
CSPX
// CSPX: split. 每个CSP模块前面的卷积核的大小都是3*3,stride=2,因此可以起到下采样的作用。
// CSPX: 输入和输出维度是一样的。
class CSPXImpl : public torch::nn::Module {
public:
CSPXImpl(int res_n, int in_channels, int out_channels);
torch::Tensor forward(torch::Tensor x);
private:
CBM cbm1{ nullptr }; // splict0
CBM cbm2{ nullptr }; // splict1
torch::nn::Sequential res_block_list = torch::nn::Sequential();
CBM cbm3{ nullptr };
}; TORCH_MODULE(CSPX);
CSPXImpl::CSPXImpl(int res_n, int in_channels, int out_channels) {
// split
cbm1 = CBM(in_channels, in_channels / 2, 1, 1); // 1x1卷积. 分支1
cbm2 = CBM(in_channels, in_channels / 2, 1, 1); // 1x1卷积, 分支2
// 分支1
for (int i = 0; i < res_n; i++) res_block_list->push_back(ResBlock(in_channels / 2, in_channels / 2, 3, 1));
cbm3 = CBM(in_channels / 2, in_channels / 2, 3, 1);
register_module("cbm1", cbm1);
register_module("cbm2", cbm2);
register_module("cbm3", cbm3);
register_module("res_block_list", res_block_list);
}
torch::Tensor CSPXImpl::forward(torch::Tensor x) {
// split
torch::Tensor split_b1 = cbm1->forward(x);
torch::Tensor split_b2 = cbm1->forward(x);
split_b1 = res_block_list->forward(split_b1);
split_b1 = cbm3->forward(split_b1);
torch::Tensor csp_res = torch::cat({ split_b1, split_b2 }, 1);
return csp_res;
}
1.2 Neck
特征融合方式,yolov3使用的是FPN,而yolov4组合使用了SPP和PAN.

1.2.1 FPN
FPN,Feature Pyramid Network结构示意图如下。FPN结构通过上采样不断的融合不同尺度的特征,得到多尺度的输出,使得网络能够预测多尺度目标。
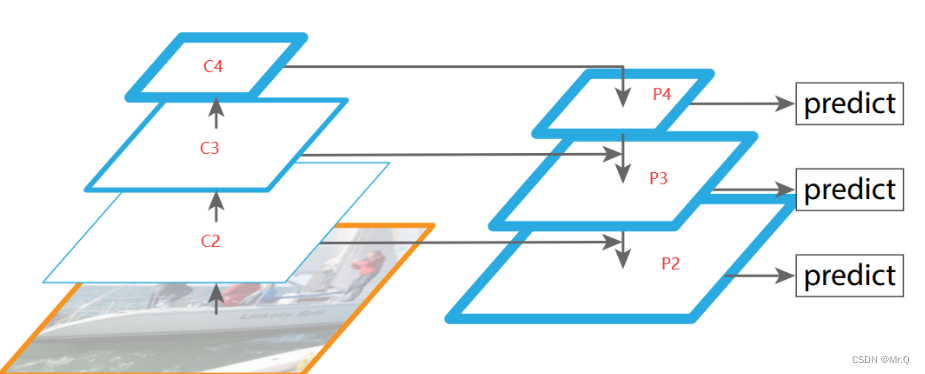
yolov3中的Darknet53输出三种尺度的特征(b,1024,13,13), (b,512,26,26), (b,256,52,52),经过FPN结构输出的对应结果尺度是(b,num_anchor*(5+num_cls),13,13), (b,num_anchor*(5+num_cls),26,26), (b,num_anchor*(5+num_cls),52,52).
yolov3中FPN结构如下。
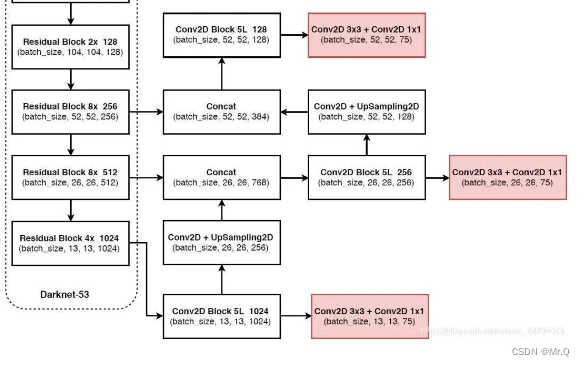
1.2.2 PAN
PAN, Path Aggregation Network(路径聚合网络)网络结构如下。左边和右边的PAN区别在于不同尺度特征融合方式,左边是相加、右边是concat方式。
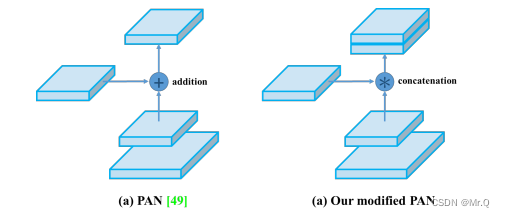
FPN(Feature Pyramid Network)和PAN(Path Aggregation Network)是两种常用于多尺度目标检测和语义分割任务的神经网络模型,它们的相同点和不同点如下所述:
相同点:多尺度特征融合,FPN和PAN都采用类似的特征金字塔结构来融合不同尺度的特征,以捕捉目标物体的多尺度信息。
不同点:连接方式不同,FPN是自顶向下的路径,从而形成一个单一的特征金字塔。而PAN则包含了自顶向下和自下而上的路径,路径更多,以实现不同分辨率的特征融合。
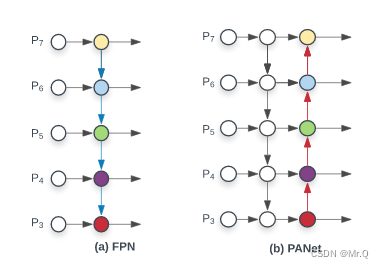
yolov4中PAN结构如下。
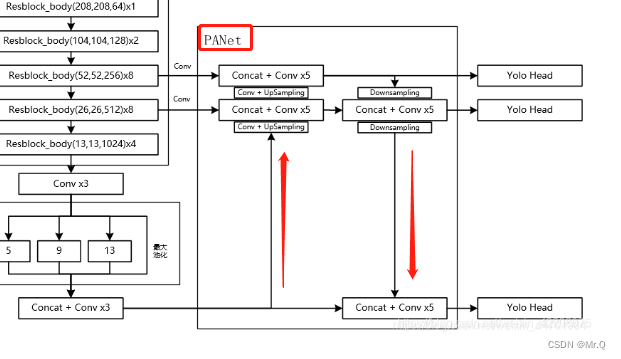
PANet 细化图

// PAN: Path Aggregation Network
class PANImpl : public torch::nn::Module {
public:
PANImpl();
std::vector<torch::Tensor> forward(std::vector<torch::Tensor> x);
private:
UpConv up1{ nullptr };
UpConv up2{ nullptr };
DownConv down1{ nullptr };
DownConv down2{ nullptr };
CBM conv1{ nullptr };
CBM conv2{ nullptr };
CBM conv3{ nullptr };
CBM conv4{ nullptr };
CBM conv5{ nullptr };
CBM conv6{ nullptr };
CBM conv7{ nullptr };
}; TORCH_MODULE(PAN);
PANImpl::PANImpl()
{
// up
up1 = UpConv(1024, 256, 3, 1); // (b,1024,13,13) -> (b,256,26,26)
conv1 = CBM(512, 256, 3, 1); // (b,512,26,26) -> (b,256,26,26)
up2 = UpConv(512, 128, 3, 1); // (b,512,26,26) -> (b,128,52,52)
conv2 = CBM(256, 128, 3, 1); // (b,256,52,52) -> (b,128,52,52)
// down
down1 = DownConv(256, 256, 3, 1); // (b,256,52,52) -> (b,256,26,26)
conv3 = CBM(512, 256, 3, 1); // (b,512,26,26) -> (b,256,26,26)
down2 = DownConv(512, 512, 3, 1); // (b,512,26,26) -> (b,512,13,13)
conv4 = CBM(1024, 512, 3, 1); // (b,1024,13,13) -> (b,512,13,13)
// output
conv5 = CBM(256, 75, 3, 1); // (b,256,52,52) -> (b,75,52,52)
conv6 = CBM(512, 75, 3, 1); // (b,512,26,26) -> (b,75,26,26)
conv7 = CBM(1024, 75, 3, 1); // (b,1024,13,13) -> (b,75,13,13)
register_module("up1", up1);
register_module("up2", up2);
register_module("down1", down1);
register_module("down2", down2);
}
// x0, x1, x2: 52, 26, 13
std::vector<torch::Tensor> PANImpl::forward(std::vector<torch::Tensor> x) {
// up
torch::Tensor up1_tensor = up1->forward(x[2]); // (b,1024,13,13) -> (b,256,26,26)
torch::Tensor x1 = conv1->forward(x[1]); // (b,512,26,26) -> (b,256,26,26)
torch::Tensor up1_output = torch::cat({ up1_tensor, x1 }, 1); // (b,256,26,26) -> (b,512,26,26)
torch::Tensor up2_tensor = up2->forward(up1_output); // (b,512,26,26) -> (b,128,52,52)
torch::Tensor x2 = conv2->forward(x[0]); // (b,256,52,52) -> (b,128,52,52)
torch::Tensor up2_output = torch::cat({ up2_tensor, x2 }, 1); // (b,128,52,52) -> (b,256,52,52)
// down
torch::Tensor down1_tensor = down1->forward(up2_output); // (b,256,52,52) -> (b,256,26,26)
torch::Tensor x3 = conv3->forward(up1_output); // (b,512,26,26) -> (b,256,26,26)
torch::Tensor down1_output = torch::cat({ down1_tensor, x3 }, 1); // (b,256,26,26) -> (b,512,26,26)
torch::Tensor down2_tensor = down2->forward(down1_output); // (b,512,26,26) -> (b,512,13,13)
torch::Tensor x4 = conv4->forward(x[2]); // (b,1024,13,13) -> (b,512,13,13)
torch::Tensor down2_output = torch::cat({ down2_tensor, x4 }, 1); // (b,512,13,13) -> (b,1024,13,13)
// output
torch::Tensor output0 = conv5->forward(up2_output); // (b,256,52,52) -> (b,75,52,52)
torch::Tensor output1 = conv6->forward(down1_output); // (b,512,26,26) -> (b,75,26,26)
torch::Tensor output2 = conv7->forward(down2_output); // (b,1024,13,13) -> (b,75,13,13)
return std::vector<torch::Tensor>({ output0, output1, output2 }); // (b,75,52,52), (b,75,26,26), (b,75,13,13)
}
1.2.3 SPP
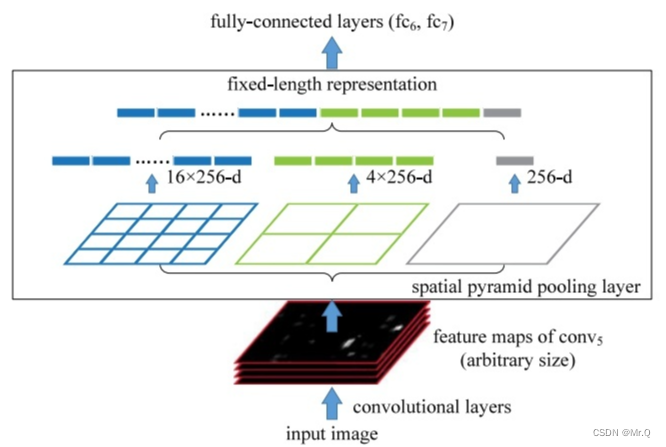
SPP,Spatial Pyramid Pooling结构如下。下面是传统意义上的SPP结构,通过把输出划分成不同的网格数,每个网格使用不同尺度核大小的maxpool。输出固定大小的向量。
如下图所示,每个网络输出一个值,有256个通道,则最大池化后,输出的向量维度是固定的,左边的4x4个网格,输出向量维度是16x256,中间是2x2个网格,输出向量维度是4x256,右边是1x1的网格,输出向量维度是256. 最后的拼接在一起,所以最后的向量维度是固定的。方便分类网络兼容多尺度输入。
** yolov4**中的SPP结构如下。可以看到有4个分支,每个分支都是最大池化,从左往右最大池化核大小是k={5x5, 9x9, 13x13, 1x1}. 采用了padding操作,使其输出不改变尺度。
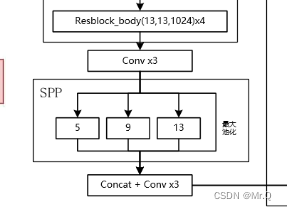
注意通道维度变化,先是利用conv,将通道降低4倍,之后每个分支的通道都是1/4,最后再concat再一起变成原始通道数。如下所示。
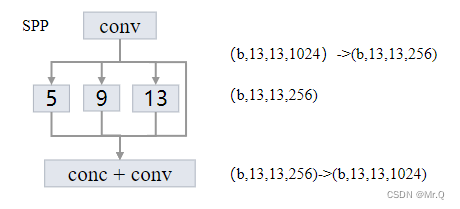
// SPP: three maxpooling. Change maximum pooling to convolution form
class SPPImpl : public torch::nn::Module {
public:
SPPImpl();
torch::Tensor forward(torch::Tensor x);
private:
CBM conv1{ nullptr };
CBM max_pool1{ nullptr };
CBM max_pool2{ nullptr };
CBM max_pool3{ nullptr };
CBM conv2{ nullptr };
}; TORCH_MODULE(SPP);
/// <summary>
/// 这里最大池化改采用卷积形式,卷积核大小分别是3,5,9,13. padding操作,移动的步长为1,不改变特征尺度。
/// </summary>
SPPImpl::SPPImpl() :
conv1(CBM(1024, 256, 3, 1)),
max_pool1(CBM(256, 256, 5, 1)),
max_pool2(CBM(256, 256, 9, 1)),
max_pool3(CBM(256, 256, 13, 1)),
conv2(CBM(1024, 1024, 3, 1))
{
register_module("conv1", conv1);
register_module("max_pool1", max_pool1);
register_module("max_pool2", max_pool2);
register_module("max_pool3", max_pool3);
register_module("conv2", conv2);
}
torch::Tensor SPPImpl::forward(torch::Tensor x) {
// 1, down channels
x = conv1->forward(x); // (b,1024,13,13) -> (b,256,13,13)
// 2, spp
torch::Tensor x1 = max_pool1->forward(x); // kernel_size = 5
torch::Tensor x2 = max_pool2->forward(x); // 9
torch::Tensor x3 = max_pool3->forward(x); // 13
x = torch::cat({ x, x1, x2, x3 }, 1); // (b,256,13,13) -> (b,1024,13,13)
// 3, conv
x = conv2->forward(x); // (b,1024,13,13) -> (b,1024,13,13)
return x;
}
1.3 Head
yolov3和yolov4的head是一样的,都基于anchor,输出多个尺度结果:
(b,num_anchor*(5+num_cls),13,13).
(b,num_anchor*(5+num_cls),26,26).
(b,num_anchor*(5+num_cls),52,52).
2. 数据增强
YOLOv4在数据增强方面比YOLOv3做得更好。YOLOv4使用了一系列新的数据增强技术,如CutMix、Mosaic等,可以帮助模型更好地学习不同角度、不同大小、不同位置的目标,从而提高模型的鲁棒性和泛化能力。而YOLOv3则使用了一些基本的数据增强技术,如随机裁剪、随机翻转等。
2.1 CutMix

两张图片,随机裁剪其中一张图片,粘贴到另一张图片中。
2.2 Mosaic

Mosaic数据增强方法采用随机缩放、随机裁剪、随机排列的方式拼接,形成一张新的图片作为训练数据。这种增强方法可以提高模型的泛化能力,增强模型对于多样化背景、物体大小、旋转角度等情况的识别能力。
3. 激活函数
非单调的Mish激活函数是在单调递增的softplus激活函数基础上,再外包了一个单调递增的tanh激活函数。如下所示。
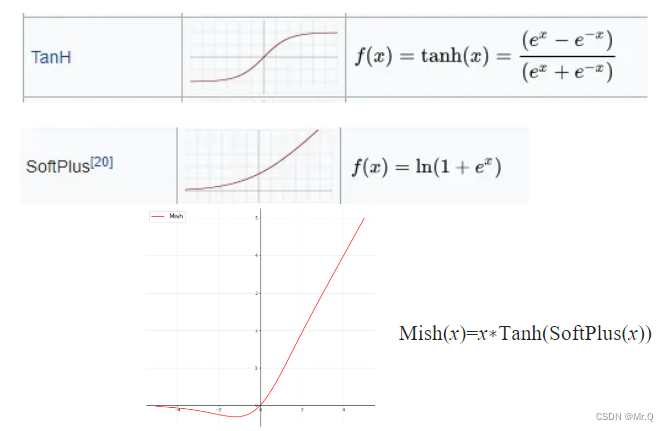
4. 损失函数
yolov4使用的是CIoU-loss,yolov3
Smoothing
5. 正则化方法
DropBlock.
借鉴cutout数据增强技术,区别是cutout是只应用到输入图像层,而DropBlock则是将cutout应用到每一个特征图,而且不是固定归零比如,是随着训练线性增加的一个比率。
知识点
参数量计算公式:
其中括号内是一个卷积核的参数量,+1是bias,是卷积核个数。
计算量计算公式:
中括号内是计算出feature map中一个点所需要的计算量,一次卷积的计算量。其中第一个小括号是乘法计算量,第二个括号是加法计算量,-1是因为加法是逐个往第一个数累加的原因,+1是bias。有C_o x W x H个输出点。
参考:
深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解 - 知乎YOLOv4特征提取网络——CSPDarkNet结构解析及PyTorch实现 - 知乎深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解 - 知乎
目标检测 - Neck的设计 PAN(Path Aggregation Network)_西西弗Sisyphus的博客-CSDN博客_pan 目标检测
版权归原作者 Mr.Q 所有, 如有侵权,请联系我们删除。