
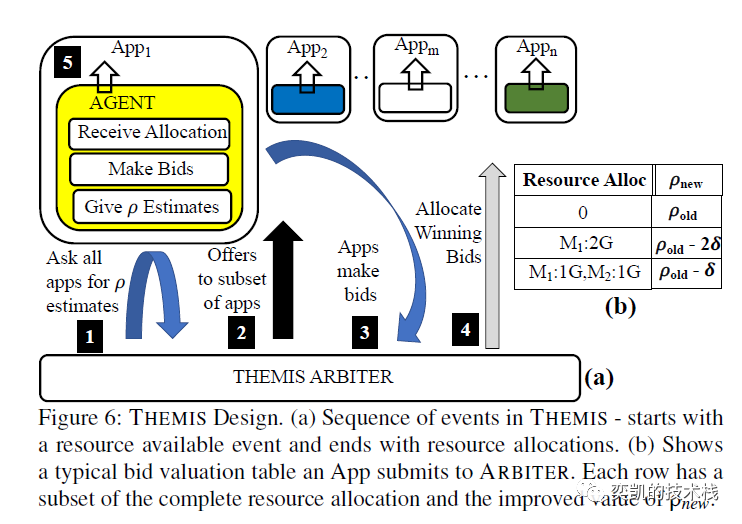
GPU 集群已经成为分布式机器学习 (ML) 训练工作的主流基础设施。但是因为GPU的独占特性当多个工作负载在共享集群上执行时就会发生严重的资源冲突,导致底层硬件的利用率和效率较低。Themis [1] 的作者提到目前可用的集群调度机制不适合 ML 训练工作负载的独特特征。ML 训练工作负载通常是需要批量调度的长时间运行的作业,并且它们的性能对任务的相对位置很敏感。于是他们提出 Themis [1] 作为 ML 训练工作负载的新调度框架。该机制是一种以完成时间进行公平调度的GPU分配策略(在一个共享的集群中有N个应用程序的运行时间与在一个1/N集群中单独运行的运行时间的比率)。Themis 的目标是在有效利用集群 GPU 的同时,保证各工作负载调度的公平性并最大限度地减少所有 ML 应用程序的完成时间。Themis 包含两级调度架构,其中 ML 作业在调度引擎中对可用资源进行投标,这样可以使调度引擎可以捕获布局敏感性并确保效率。调度引擎的分配是通过在短期内将GPU 分配给中标者以换取更多效率,但在长期内仍然确保所有工作完成时间的公平性。Themis 在 Apache YARN 3.2.0 上实现,并通过重放大型企业跟踪中的工作负载进行评估,公平性提高了 2.25 倍以上,集群效率提高了 ~5% 到 ~250%。
分享激励( sharing incentive)就是公平,如果 N 个用户共享一个由 C 个 GPU 组成的集群,那么每个用户的性能必须不低于使用大小为 C/N 的私有集群,并且他们不能忍受长时间的等待。以前的试图提供共享集群激励的集群调度框架 [2,3,4] 是为大数据工作负载设计的(对 ML 工作负载无效)。他们没有考虑 ML 任务的长时间和 ML 应用程序的放置偏好。
现有的大数据调度程序对于 ML 工作负载是不公平的:
- ML 作业具有需要调度的长时间运行的任务,即 gang-scheduling
- ML 工作对执行的位置敏感。作业中的每个任务通常会运行多次迭代,同时在每次迭代结束时同步模型更新。这表明通信在 ML 工作负载中变得很重要。如果一个作业的所有任务都放在同一台机器或同一机架上,由于更快的通信,这将导致显着的加速。
基于对 5000 个唯一用户共享的 50 个 GPU 上的执行跟踪观察得出的结果如下:
- ML 应用程序在资源使用、提交的作业数量和运行时间方面是异构的。它们比大数据分析工作要长得多。大数据作业通常需要几个小时才能完成。
- 约 10% 的应用程序有 1 个作业,约 90% 的应用程序执行多达 100 个作业的超参数搜索。
帕累托最优 (PE) 和无嫉妒(envy-free)表达式:
帕累托最优也称为帕累托效率(Pareto efficiency),是指资源分配的一种理想状态,假定固有的一群人和可分配的资源,从一种分配状态到另一种状态的变化中,在没有使任何人境况变坏的前提下,使得至少一个人变得更好,这就是帕累托改进或帕累托最优化。
Envy-Freedom指的是当资源在享有平等权利的人之间分配时,每个人都应该得到一份,在他们看来,至少与任何其他人得到的份额一样好。
该算法提出的动机和机制
ML Applications:一个或多个ML模型训练Job的集合,与用户对应,用于高级目标,如语音识别或对象检测(用户知道适当的超参数来训练这些模型,或通过训练一组超参数来探索它们)
Job:并行Task的集合。在任何给定的时间,一个Job的所有Task集体处理一个小批量的培训数据。
Task:处理批处理的一个子集,从模型的初始版本开始,执行底层学习算法的多次迭代,以改进模型。
由于应用程序执行时间长,占用容量的用户会让许多其他用户需要较高的等待时间。一些无法获得资源的用户则会选择不使用集群服务转而购买自己的硬件。虽然有一个调度器来确保底层硬件的高利用率很重要,但该调度器应该在ML应用程序之间公平地共享资源。
公平完成时间指标的公式如下:
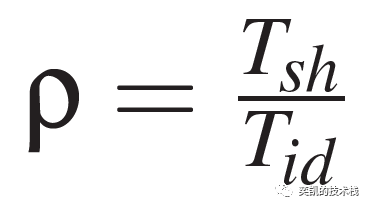
Tsh 是共享完成时间,Tid 是独立完成时间。
分配机制必须估计不同 GPU 分配的完成时间指标的值,但是调度引擎无法预测或确定指标的值。因此Themis 在应用程序和调度引擎之间提出了一个更广泛的接口,可以允许应用程序表达对每个分配的偏好,并建议应用程序可以将此信息编码为如下表。
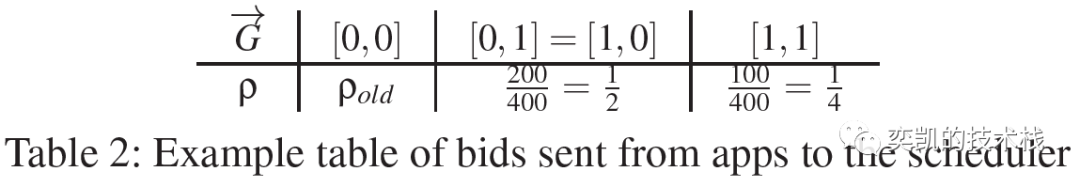
每列都有一个潜在的 GPU 分配的排列和接收此分配时完成时间公平度量的估计。
ML 应用程序的完成时间公平性是它接收到的 GPU 分配的函数。分配策略采用这些完成时间公平指标和输出分配。
最初可能会想到一个基于应用程序报告的完成时间公平指标并基于它们分配 GPU 的幼稚策略分类应用程序作为解决方案。但是应用程序可以提交有关其完成时间公平度量值的虚假信息,从而增加其赢得分配的机会。为了解决这个问题,作者建议使用拍卖竞价的方式进行。

两级调度设计在底层包含一个集中的应用间调度程序,在顶层包含一个 API接口,用于与现有的超参数调整框架集成。几个现有的框架 [5, 6] 可以在单个应用程序中的各种作业之间智能地共享 GPU 资源,并且在某些情况下,如果其进展不理想,还可以提前终止作业。
作者认为应用程序的完成时间是确定最佳模型和相关超参数的时间。在完整这样一个模型的过程中,应用程序可能决定提前终止它的一些Jobs或通过检查验证准确性来终止Jbos。对于包含单个job的应用程序,完成时间是将此模型训练到目标精度或最大迭代次数所需的时间。
总结
在集群上调度ML工作负载时,传统的大数据框架无法提供帮助。因为ML工作负载具有独特的特性,必须考虑使用具有效率(高利用率)的激励共享集群。Themis解决了这个问题,它提出了一个基于类似现实世界拍卖的概念的两级调度器和资源分配。然而,在分配应用程序时,当它们没有充分利用底层资源时,应该考虑ML工作负载。
引用
[1] K. Mahajan et al., “Themis: Fair and Efficient GPU Cluster Scheduling,” in 17th USENIX Symposium**on Networked Systems Design and Implementation (NSDI 20), 2020, bll 289–304.
[2] Ghodsi, Ali, et al. “Dominant Resource Fairness (DRF): Fair Allocation of Multiple Resource Types.” Nsdi. Vol. 11. №2011. 2011.
[3] Isard, Michael, et al. “Quincy: fair scheduling for distributed computing clusters.” Proceedings of the ACM SIGOPS 22nd symposium on Operating systems principles. 2009.
[4] Grandl, Robert, et al. “Altruistic scheduling in multi-resource clusters.” 12th {USENIX} symposium on operating systems design and implementation ({OSDI} 16). 2016.
[5] Bergstra, James, et al. “Hyperopt: a python library for model selection and hyperparameter optimization.” Computational Science & Discovery 8.1 (2015): 014008.
[6] Rasley, Jeff, et al. “Hyperdrive: Exploring hyperparameters with pop scheduling.” Proceedings of the 18th ACM/IFIP/USENIX Middleware Conference. 2017.
[7] Gu, Juncheng, et al. “Tiresias: A GPU cluster manager for distributed deep learning.” 16th USENIX**Symposium on Networked Systems Design and Implementation (NSDI 19). 2019.
LAS (Least used Service)分配策略:GPU(或资源)在一定期限内租用,当租用期满时,可用的GPU将被分配给接收到最少GPU时间的作业。
作者:Ehsan Yousefzadeh-Asl-Miandoab