
接上一篇Redis的过期策略详解
Redis的过期策略详解
所谓的淘汰策略就是:
我们redis中的数据都没有过期,但是内存有大小,所以我们得
淘汰一些没有过期的数据
!!
那么怎么去淘汰了,我们上一篇讲了冰箱其实也是相当于一个缓存容器,放菜!!
那么如果现在冰箱里面的菜都是好的没过期的,但是你家冰箱满了,买新冰箱又来不及,要去扔菜或者把它吃掉!就是要清理菜!你们会怎么清理?
官网:Redis淘汰策略官网地址
官网目前给出了8种策略(4.0版本以后加入了LFU),但是咱们这里只重点研究LRU和LFU,其他的像随机这种,一看就懂,我们自行看一下就好
PS:是在config文件中配置的策略:
#maxmemory-policy noeviction
默认就是不淘汰,如果满了,能读不能写!就跟你冰箱满了一样,能吃,不能放!
LRU
Least Recently Used
翻译过来是最久未使用,根据时间轴来走,很久没用的数据只要最近有用过,我就默认是有效的。
也就是说这个策略的意思是先淘汰长时间没用过的
那么怎么去判断一个redis数据有多久没访问了,Redis是这样做的
redis的所有数据结构的对外对象里,它里面有个字段叫做lru
源码:server.h 620行
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;/*
\*LRU time (relative to global lru_clock) or
\* LFU data (least significant 8 bits frequency
\* and most significant 16 bits access time).
*/int refcount;void*ptr;} robj;
每个对象都有1个LRU的字段,看它的说明,好像LRU跟我们后面讲的LFU都跟这个字段有关,并且这个lru代表的是一个时间相关的内容。
那么我们大概能猜出来,redis去实现lru肯定跟我们这个对象的lru相关!!
首先,我告诉大家,这个lru在LRU算法的时候代表的是这个数据的访问时间的秒单位!!但是只有24bit,无符号位,所以
这个lru记录的是它访问时候的秒单位时间的后24bit!
用Java来写就是:(不会有人不知道redis是C写的吧#手动滑稽)
long timeMillis=System.currentTimeMillis();System.out.println(timeMillis/1000);//获取当前秒System.out.println(timeMillis/1000&((1<<24)-1));//获取秒的后24位
我们刚才讲了,是获取当前时间的最后24位,那么当我们最后的24bit都是1了的时候,时间继续往前走,那么我们获取到的时间是不是就是24个0了!
举个例子:
11111111111111111000000000011111110 假如这个是我当前秒单位的时间,获取后8位 是 11111110
11111111111111111000000000011111111 获取后8位 是11111111
11111111111111111000000000100000000 获取后8位 是00000000
所以,它有个轮询的概念,它如果超过24位,又会从0开始!所以我们不能直接的用系统时间秒单位的24bit位去减对象的lru,而是要判断一下,还有一点,为了性能,我们系统的时间不是实时获取的,而是用redis的时间事件来获取,所以,我们这个
时间获取是100ms去获取一次
。
如图: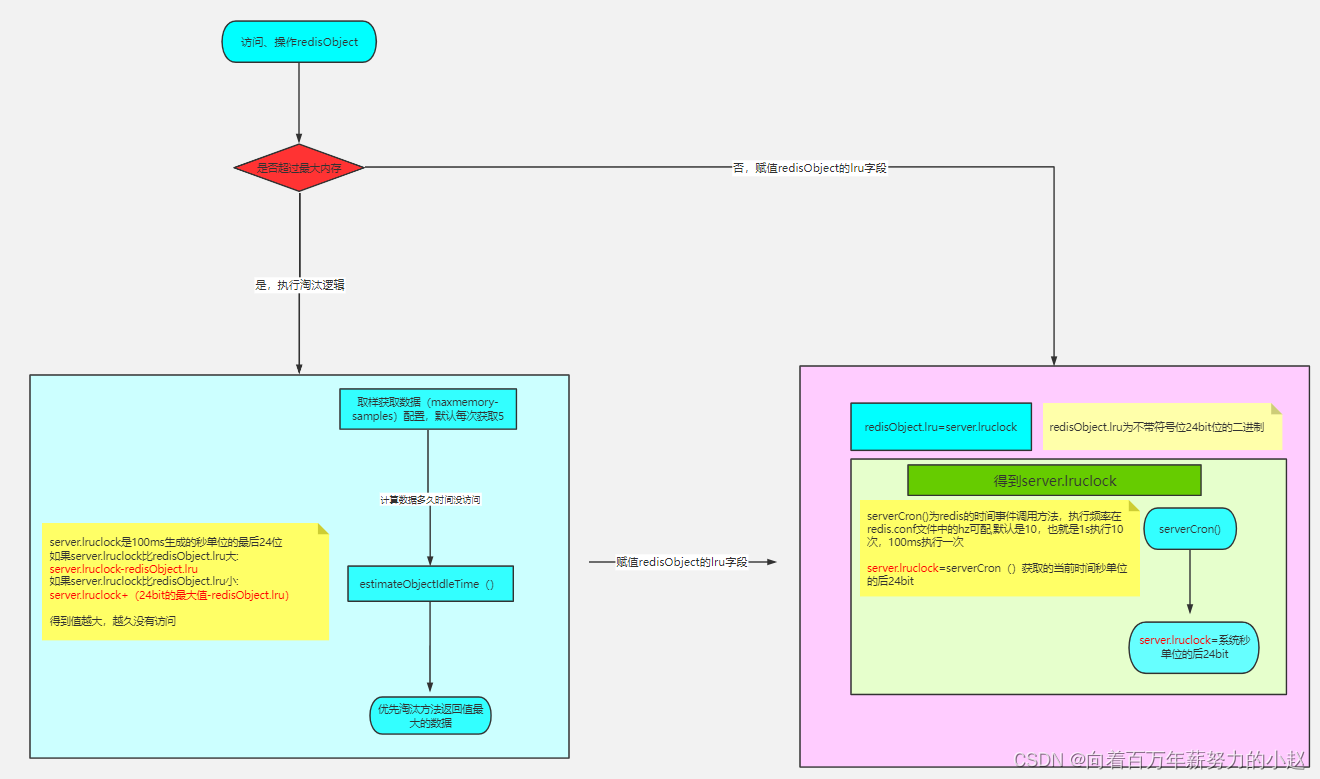
好,现在我们知道了原来redis对象里面原来有个字段是记录它访问时间的,那么接下来肯定有个东西去跟这个时间去比较,拿到差值!
我们去看下源码evict.c文件
unsigned longlongestimateObjectIdleTime(robj *o){//获取秒单位时间的最后24位
unsigned longlong lruclock =LRU_CLOCK();//因为只有24位,所有最大的值为2的24次方-1//超过最大值从0开始,所以需要判断lruclock(当前系统时间)跟缓存对象的lru字段的大小if(lruclock >= o->lru){//如果lruclock>=robj.lru,返回lruclock-o->lru,再转换单位return(lruclock - o->lru)* LRU_CLOCK_RESOLUTION;}else{//否则采用lruclock + (LRU_CLOCK_MAX - o->lru),得到对象的值越小,返回的值越大,越大越容易被淘汰return(lruclock +(LRU_CLOCK_MAX - o->lru))*
LRU_CLOCK_RESOLUTION;}}
我们发现,跟对象的lru比较的时间也是serverCron下面的当前时间的秒单位的后面24位!但是它有个判断,有种情况是系统时间跟对象的LRU的大小,因为最大只有24位,会超过!!
所以,我们可以总结下我们的结论
- Redis数据对象的LRU用的是server.lruclock这个值,server.lruclock又是每隔100ms生成的系统时间的秒单位的后24位!所以server.lruclock可以理解为延迟了100ms的当前时间秒单位的后24位!
- 用server.lruclock 与 对象的lru字段进行比较,因为server.lruclock只获取了当前秒单位时间的后24位,所以肯定有个轮询。所以,我们会判断server.lruclock跟对象的lru字段进行比较,如果server.lruclock>obj.lru,那么我们用server.lruclock-obj.lru,否则server.lruclock+(LRU_CLOCK_MAX-obj.lru),得到lru越小,那么返回的数据越大,相差越大的就会被淘汰!
LFU
Least Frequently Used 翻译成中文就是最不常用,不常用的衡量标准就是
使用次数
但是LFU的有个致命的缺点!就是它只会加不会减!为什么说这是个缺点
举个例子:去年有一个热搜,今年有一个热搜,热度相当,但是去年的那个
因为有时间的积累
,所以点击次数高,今年的点击次数
因为刚发生
,所以累积起来的次数没有去年的高,那么我们如果已点击次数作为衡量,是不是应该删除的就是今年的?这就导致了
新的进不来旧的出不去
所以我们来看redis它是怎么实现的!怎么解决这个缺点!
我们还是来看我们的redisObject(server.h 620行)
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;/* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */int refcount;void*ptr;} robj;
我们看它的lru,它如果被用作LFU的时候!它前面16位代表的是时间,后8位代表的是一个数值,frequency是频率,应该就是代表这个对象的访问次数,我们先给它叫做counter。
那么这个16位的时间跟8位的counter到底有啥用呢?8位我们还能猜测下,可能就是这个对象的访问次数!
我们淘汰的时候,是不是就是去根据这个对象使用的次数,按照小的就去给它淘汰掉。
其实,差不多就是这么个意思。
还有个问题,如果8位用作访问次数的话,那么8位最大也就2的8次方,就是255次,够么?如果,按照我们的想法,肯定不够,那么redis去怎么解决呢?
既然不够,那么
让它不用每次都加
就可以了,能不能让它
值越大,我们加的越慢
就能解决这个问题
redis还加了个东西,让你们自己能主宰它加的速率,这个东西就是
lfu-log-factor
!它配置的越大,那么对象的访问次数就会加的越慢。
源码:
(evict.c 328行)
uint8_t LFULogIncr(uint8_t counter){//如果已经到最大值255,返回255 ,8位的最大值if(counter ==255)return255;//得到随机数(0-1)double r =(double)rand()/RAND_MAX;//LFU_INIT_VAL表示基数值(在server.h配置)double baseval = counter - LFU_INIT_VAL;//如果达不到基数值,表示快不行了,baseval =0if(baseval <0) baseval =0;//如果快不行了,肯定给他加counter//不然,按照几率是否加counter,同时跟baseval与lfu_log_factor相关//都是在分子,所以2个值越大,加counter几率越小double p =1.0/(baseval*server.lfu_log_factor+1);if(r < p) counter++;return counter;}
所以,LFU加的逻辑我们可以总结下:
- 如果已经是最大值,我们不再加!因为到达255的几率不是很高!可以支撑很大很大的数据量!
- counter属于随机添加,添加的几率根据已有的counter值和配置lfu-log-factor相关,counter值越大,添加的几率越小,lfu-log-factor配置的值越大,添加的几率越小!
还有,这个前16bit时间到底是干嘛的!!我们现在还不知道,传统的LFU只能加,不会减。
那么我们想下,这个时间是不是就是用来减次数的?
大家有玩王者充钱的么,如果充钱的同学应该知道,如果你很久很久不充钱的话,你的vip等级会降,诶,这个是不是就能解决我们的次数只能加不能减的问题!并且这个减还是根据你多久时间没充钱来决定的,所以,我们可以大胆猜下,这个前16bit的时间是不是也记录了这个对象的时间,然后根据这个时间判断这个对象多久没访问了就去减次数了。
没错,你猜的都是对的!我们的这个
16bit记录的是这个对象的访问时间的分单位的后16位
,每次访问或者操作的时候,都会去跟当前时间的分单位的后16位去比较,得到多少分钟没有访问了!然后去减去对应的次数!
那么这个次数每分钟没访问减多少了,就是根据我们的配置lfu-decay-time。
这样就能够实现我们的LFU,并且还解决了LFU不能减的问题。
总结如图: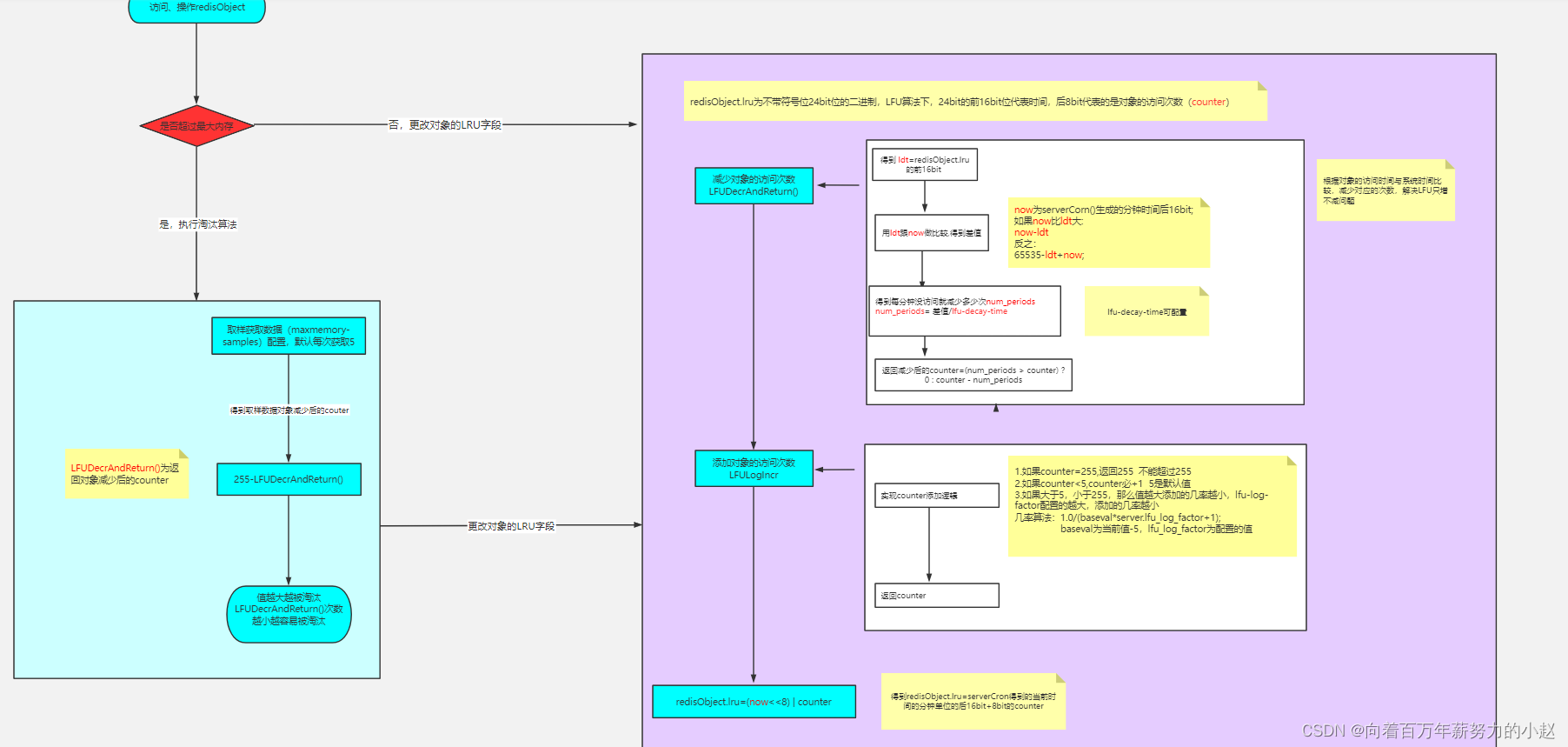
贴出减的源码:
unsigned longLFUDecrAndReturn(robj *o){//lru字段右移8位,得到前面16位的时间
unsigned long ldt = o->lru >>8;//lru字段与255进行&运算(255代表8位的最大值),//得到8位counter值
unsigned long counter = o->lru &255;//如果配置了lfu_decay_time,用LFUTimeElapsed(ldt) 除以配置的值//LFUTimeElapsed(ldt)源码见下//总的没访问的分钟时间/配置值,得到每分钟没访问衰减多少
unsigned long num_periods = server.lfu_decay_time ?LFUTimeElapsed(ldt)/ server.lfu_decay_time :0;if(num_periods)//不能减少为负数,非负数用couter值减去衰减值
counter =(num_periods > counter)?0: counter - num_periods;return counter;}
LFUTimeElapsed方法源码(evict.c):
//对象ldt时间的值越小,则说明时间过得越久
unsigned longLFUTimeElapsed(unsigned long ldt){//得到当前时间分钟数的后面16位
unsigned long now =LFUGetTimeInMinutes();//如果当前时间分钟数的后面16位大于缓存对象的16位//得到2个的差值if(now >= ldt)return now-ldt;//如果缓存对象的时间值大于当前时间后16位值,则用65535-ldt+now得到差值return65535-ldt+now;}
所以,LFU减逻辑我们可以总结下:
- 我们可以根据对象的LRU字段的前16位得到对象的访问时间(分钟), 根据跟系统时间比较获取到多久没有访问过!
- 根据lfu-decay-time(配置),代表每分钟没访问减少多少counter,不 能减成负数
版权归原作者 向着百万年薪努力的小赵 所有, 如有侵权,请联系我们删除。