
一、摘要
知识图谱是一种用图模型来描述知识和建模世界万物之间关联关系的大规模语义网络,是大数据时代知识表示的重要方式之一。而大型语言模型,如OpenAI发布的GPT-4 ,通过在大量文本等数据上进行预训练,展示出了极其强大的通识知识和问题解决能力[1][2][3][4]。知识图谱可以为大型语言模型提供精准的结构化的知识,助力和改善模型的推理效果和生成质量,并提供对知识的精准操作和分析能力。
目前,诸多领域仍缺乏足够精准和完备的知识图谱,那么GPT-4等大模型是否能为高效知识图谱构建带来便利?我们对GPT-4的知识抽取能力进行了分析,探究的主要内容有:
GPT-4对不同类型知识如事实、事件及不同领域如通用、垂直知识的抽取能力分析
GPT-4 和ChatGPT抽取能力对比及错误案例分析
GPT-4抽取未见知识的泛化能力分析
展望大模型时代知识图谱构建的新思路
二、知识抽取能力分析
因还未申请到GPT-4的API,我们基于ChatGPT-plus的交互式界面并通过随机采样测试集/验证集样本的方式,评测了GPT-4在实体、关系、事件等知识上的Zero-shot以及One-shot抽取能力,并和ChatGPT及全监督基线模型的结果进行了对比。我们选取了DuIE2.0[5]、RE-TACRED[6]、MAVEN[7]以及SciERC[8]作为本次实验的数据集。因为部分数据集并未提供实体类型,所以我们在指令提示(Prompt)中统一设置为只提供待抽取的关系/事件类型,且不显式指定待抽取的实体类型。
通过随机采样测试,我们发现,无论在Zero-shot还是One-shot的情况下,GPT-4在多个学术基准抽取数据集上均取得了相对较好的性能,且比ChatGPT取得了一定程度的进步。同时,One-shot的引入也使模型在Zero-shot上的性能得到了进一步提升。这在一定程度上说明了GPT-4具备着对不同类型、不同领域知识的抽取能力。然而,我们也发现目前GPT-4仍不如全监督小模型。这也与前人的相关工作发现一致[2][4]。特别注意的是,该结果为随机采样测试集并通过交互界面(非API)测试结果,可能会受到测试集数据分布和采样样本的影响。
此外,提示的设计和数据集本身的复杂程度也对本次实验的结果有较大的影响。具体地,我们发现在四种数据集上ChatGPT和GPT-4评估结果可能受到如下几种原因的影响:
- 数据集:存在噪音且部分数据集类型不够明晰(如未提供头尾实体类型、语境复杂等)
- **指令提示(Prompt)**:语义不够丰富的指令会影响抽取性能(如加入相关样本In-Context Learning[9]可以提升性能;Code4Struct[10]发现基于代码结构可促进结构化信息抽取)。需要指出的是,由于部分数据集存在无头尾实体类型的情况,此处为了横向公平对比不同模型在数据集上的能力,实验在提示指令中并未指明抽取的实体类型,这也会在一定程度上影响实验的结果。
- 评估方式:现有的评估方式可能不太适用于大模型如ChatGPT与GPT-4抽取能力的评估。如数据集中所给标签并未完全覆盖正确答案,部分超出答案的结果仍可能是正确的(存在同义词等)。
具体内容我们将在下一章节进行详细分析。
三、能力对比与错误案例分析
我们进一步针对选取的四个数据集中的部分案例进行了分析(由于实验中使用的Prompt较长,在这里只展示部分重要信息)。
(一) DuIE2.0
1. Zero-shot
- ChatGPT VS GPT-4


在SPO三元组的抽取过程中,我们注意到在使用相同的Prompt的情况下,GPT-4更能理解Prompt所提供的指令并理解待抽取样本的上下文信息,执行符合条件的三元组抽取。如图所示,ChatGPT虽然能够理解句子的大意,给出**[作者,是 , 岑叶明]的结果,但与答案[昔年一起走过的路 , 作者 , 岑叶明]**仍存在较大差距。相较于GPT-4在此条样本上的表现,ChatGPT在谓词的抽取上以及主语宾语的选择上显得不够精炼准确。
- GPT-4


在上图中,我们让GPT-4完成对句子“然而近日,网友通过不少陈年旧照发现,张小斐其实并非喜剧曲艺出身,而是毕业于2005届北京电影学院的表演系本科专业,与现今大红大紫的内地花旦杨幂、袁姗姗等曾同窗为友,怪不得每次出场气质逼人”的三元组抽取。数据集中给出的正确答案为**[杨幂 , 毕业院校 , 北京电影学院]、[杨幂 , 毕业院校 , 2005届北京电影学院 ]**。由图可知,GPT-4并没有成功抽取出这两组信息。究其原因可能是数据集本身的信息指向性不够明确,导致GPT-4所关注的信息产生偏差。但只关注GPT-4本身给出的答案,我们仍可以在一定程度上认为GPT-4在三元组抽取上具有不错的表现。
2. One-shot
- ChatGPT VS GPT-4

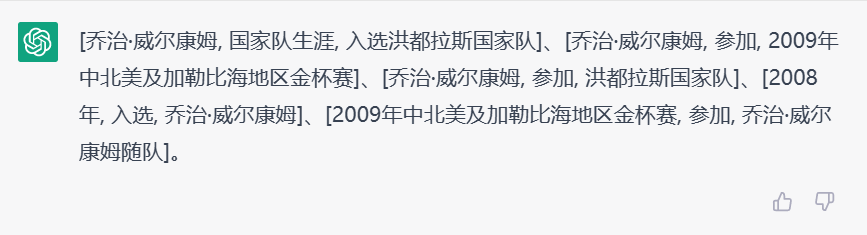

与Zero-shot的情况类似,One-shot实验条件下,GPT-4所给出的结果与ChatGPT相比都更为完善。同时GPT-4也注意到了更多的信息。如图所示,例句“国家队生涯乔治·威尔康姆在2008年入选洪都拉斯国家队,他随队参加了2009年中北美及加勒比海地区金杯赛”中,对应的三元组应为**[乔治·威尔康姆 , 国籍 , 洪都拉斯]**,此条信息并没有在文本中提及,却被GPT-4成功抽取出。我们也倾向于认为这是GPT-4知识储备丰富的带来的结果。(如从乔治·威尔康姆入选国家队的事实中推断出他的国籍)
3. Zero-shot vs One-shot
ChatGPT和GPT-4的性能均在One-shot设置下得到了提升,而ChatGPT的增幅尤为明显。
- ChatGPT


图. Zero-shot(上)One-shot(下)
针对同一条样本,ChatGPT在One-shot的情况下的结果更为准确(样本对应的答案为[史奎英 , 丈夫 , 蒋洁敏]、[蒋洁敏 , 妻子 , 史奎英]、[中石油 , 董事长 , 蒋洁敏]),同时ChatGPT给出答案的模式也更符合Prompt的要求。
- GPT-4


图. Zero-shot(上)One-shot(下)
如图,此例句对应的三元组应为**[刘恺威, 妻子, 杨幂], [杨幂, 丈夫, 刘恺威]**,示例样本的引入,使得GPT-4能够更好的完成关系的抽取,给出更符合语义的答案。
(二)MAVEN
1. Zero-shot
- ChatGPT VS GPT-4
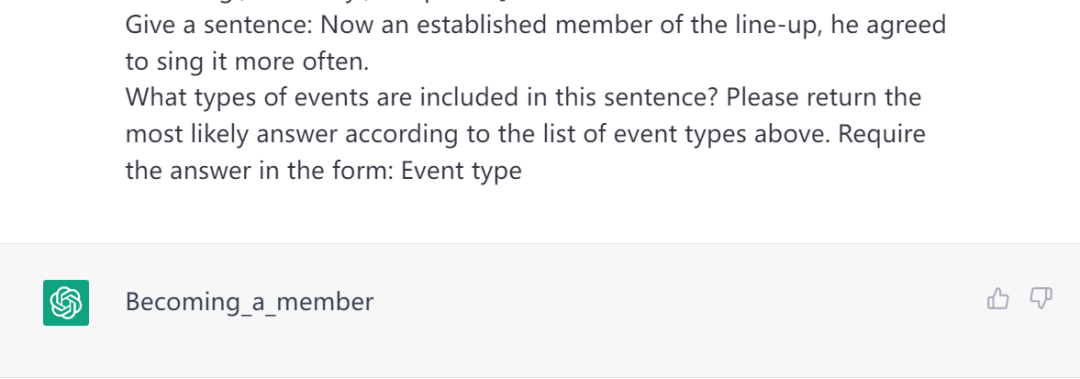

在例句“Now an established member of the line-up, he agreed to sing it more often.”中ChatGPT得到的结果是Becoming_a_member,而GPT-4得到Becoming_a_member, Agree_or_refuse_to_act, Performing,三种事件类型。由结果可知,与ChatGPT相比,GPT-4提供的信息更为完整,除了关注到member 这个词之外,GPT-4也关注到了agree触发词得到了“Agree_or_refuse_to_act”这一事件类型。同时值得说明的是,在本次实验中,我们发现ChatGPT给出的答案往往只有一种事件类型,而GPT-4获取上下文信息的能力更强,得到的答案更具多样性,故而在MAVEN数据集中的效果更好(MAVEN数据集本身包含的句子可能存在一种或多种关系)。
- GPT-4

在这项抽取任务中的例句:“The final medal tally was led by Indonesia, followed by Thailand and host Philippines.”中,数据集中给出此条样本的事件类型为“Process_end”以及“Come_together”。但此处GPT-4给出了“Comparison, Earnings_and_losses, Ranking”这三个结果。GPT-4在完成任务的过程中,确实注意到了句子中所提及“印尼在最终的奖牌榜上居首,泰国和东道主菲律宾紧随其后”中隐藏的关于排名与比较的信息,但是忽略了触发词final对应的“Process_end”以及触发词host对应的“Come_together”类型。我们认为可能是因为数据集中给出的类型在例句中不算明晰,同时,一个句子中存在多个事件类型也使此类事件抽取变得更加复杂,从而导致抽取效果不佳。
2. One-shot
- ChatGPT VS GPT-4



在One-shot的实验过程中,我们发现,相较于ChatGPT,GPT-4的答案依旧保持着数量的优势,从而也取得了较高的正确率。如上图,例句应当对应6 种事件类型:Process_end , Catastrophe , Damaging , Name_conferral , Causation 以及GiveUp。但ChatGPT只答对了1种类型(Name_conferral),而GPT-4提供了四个符合条件的答案(Catastrophe, Damaging, Process_end, Name_conferral,)。
3. Zero-shot vs One-shot
通过对比处于Zero-shot和One-shot不同条件下两种模型在样本上的表现,我们发现,ChatGPT和GPT-4的性能都获得了一定程度的改进。
- ChatGPT
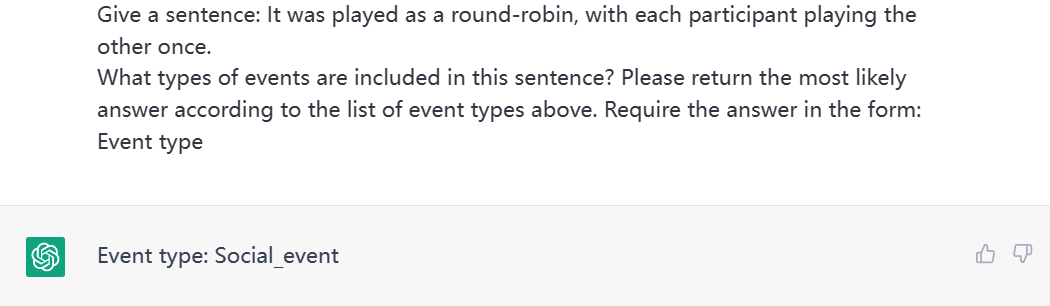

图. Zero-shot(上)One-shot(下)
针对同一条样本,ChatGPT在One-shot的情况下纠正了在Zero-shot下做出“Social_event”的错误判断,改为了正确答案之一的“Competition”。
- GPT-4

对比实验结果发现,GPT-4在Zero-shot下无法正确识别类型的样本,在One-shot下依旧无法正常识别,但是它会给出更多的答案,这也在一定程度上导致了GPT-4在样本上的表现变差。如前述在本节Zero-shot分析GPT-4的样例中,GPT-4给出了“Comparison, Earnings_and_losses, Ranking”这三个结果,而在One-shot情况下,它的事件类型变为了五种。我们推测这可能依旧与测试样本本身的含义指向不明确有关。但不可否认的是,GPT-4给出的答案具有着一定的合理性。
(三)SciERC
1. Zero-shot
- ChatGPT VS GPT-4



从实验的结果来看,我们看到ChatGPT和GPT-4在SciERC数据集上的表现相差不大,并且GPT-4并没有体现出在前述实验中展现的优势。这可能是因为Prompt的设计欠佳,模型无法有效的获取待抽取三元组的更多有效信息。但通过上图所示的例子,我们仍可以看出,就SciERC数据集而言,虽然两个模型的性能均较差,但相比ChatGPT,GPT-4在头尾实体抽取方面的能力有着较为明显的提升。
- GPT-4
同时,在实验的过程中,我们推测GPT-4在SciERC上在关系类型的理解上可能存在一定问题——在一些情况下存在头尾实体抽取正确但是关系提供异常的情况。这或许与Prompt设计不完备以及与数据集本身的专业性强、复杂度高等因素有关。

在上图中,“The result theoretically justifies the effectiveness of features in robust PCA. ”(该结果从理论上证明了稳健PCA中特征的有效性)此句中含有的关系-实体三元组为[features, FEATURE-OF, robust PCA],但GPT-4中给出的关系类型为USED-OF。

例句“**Hitherto , smooth motion has been encouraged using a trajectory basis , yielding a hard combinatorial problem with time complexity growing exponentially in the number of frames .”(迄今为止,一直鼓励使用轨迹基础的平滑运动,产生了一个硬的组合问题,其时间复杂性在帧数上呈指数增长)中含有的关系-实体三元组为[time complexity, EVALUATE-FOR, hard combinatorial problem],但GPT-4给出的答案为[hard combinatorial problem, FEATURE-OF, time complexity]**。
2. One-shot
- ChatGPT VS GPT-4


在One-shot设置下,我们发现GPT-4与ChatGPT仍存在上述对关系类型区分不足的问题,在此就不作详细展示说明。而在实验中GPT-4性能较差的原因可能是“在错误的方向上做出了更多的努力”。如上图所示,在相同的测试样本上,GPT-4虽然给出了比ChatGPT更完备的答案,却并没有“答对”。我们认为这也可能和评价指标的选取有关,一个更加完备的评价指标可能更加适合大模型对此类任务的评测。
3. Zero-shot vs One-shot
在One-shot设置下,我们发现ChatGPT与GPT-4给出答案的规范性得到了明显的提高。
- ChatGPT


图. Zero-shot(左)One-shot(右)
如上图,One-shot的设置可以在一定程度上提高ChatGPT抽取时答案的凝练精简程度。但答案数目的减少也会造成有效答案的缺失。
- GPT-4
而One-shot带给GPT-4的变化则不甚明显,我们推测是由于单个训练样本的引入不足以弥补GPT-4对于SciERC这个数据集认知的缺失。这可能是由数据集本身所决定的,因此如果想要进一步的提高GPT-4在该数据集上的效果,可以考虑引入多个示例样本等方式来扩大训练样本的集合。
(四) RE-TACRED
1. Zero--shot
- ChatGPT VS GPT-4


在例句“**The two projects -- a trachoma prevention plan and a cooking oil plan -- are jointly organized by the New York-based Helen Keller International -LRB- HKI -RRB- , the United Nations Children 's Fund and the World Health Organization , the spokesman said , adding that the HKI will implement the two programs using funds donated by Taiwan . ”(发言人说,这两个项目--沙眼预防计划和食用油计划--是由总部设在纽约的海伦-凯勒国际组织、联合国儿童基金会和世界卫生组织联合举办的,并补充说,香港国际组织将利用台湾捐赠的资金实施这两个项目)中,[Helen Keller International, org:alternate_names, HKI]**,为句子中所关注的三元组,但可能由于此项例子中头尾实体距离较近且谓词不明晰,ChatGPT并没有将此类关系抽取出。而相反,GPT-4则补全了头尾实体之间的"org:alternate_names "并成功抽取出了三元组。这也在一定程度上表明了GPT-4语言理解(阅读)能力方面相对于ChatGPT的提升。
- GPT-4

同时,我们也在RE-TACRED数据集上的实验中发现,GPT-4在有关复杂句式的三元组识别中表现欠佳。如上图,例句“The footprint was found on a bathroom rug in the house in Perugia , central Italy , where Meredith Kercher was killed in November 2007 .”中存在的关系三元组应为:[Meredith Kercher, per:country_of_death, Italy],但GPT-4无法成功抽取出Meredith Kercher与Italy的关系country_of_death。这部分实验结果很大一部分受输入的Prompt影响,我们认为如果在Prompt中引入待抽取头尾实体的类型,那么此类误判则大部分可以得到规避。
2. One-shot
- ChatGPT VS GPT-4
在Re-TACRED数据集的实验中,ChatGPT和GPT-4在测试样本上得到正确三元组的数目相差不多,但与SciERC中实验不同的是,ChatGPT和 GPT-4在性能上的差异主要来自于ChatGPT给出预测结果数量上的增多。具体情况将在下一部分说明。
3. Zero-shot vs One-shot
- ChatGPT


图. Zero-shot(上)One-shot(下)
在实验过程中,我们注意到ChatGPT在One-shot上给出的答案普遍比Zero-shot多,如图中的例子,Zero-shot条件下给的答案数是3条,而One-shot则给出了27条答案(图中已省略)。所以虽然在答对数目变多的情况下,One-shot的性能仍比Zero-shot低,这可能是与数据集本身的难易程度有关。同时我们也认为未来可以在Prompt的设计上进行研究,这可能会使模型在数据集上的性能得到进一步提升。
- GPT-4

在One-shot设置下,我们发现,GPT-4成功抽取出了前述例句 “**The footprint was found on a bathroom rug in the house in Perugia , central Italy , where Meredith Kercher was killed in November 2007 .”中的三元组[Meredith Kercher, per:country_of_death, Italy]**。这可能也在一定程度上说明单训练样本的加入确实帮助GPT-4获取到更多有效信息,从而得以解决Zero-shot中存在的问题。
总的来说,GPT-4的强大抽取能力可以显著降低知识图谱构建的成本,进而提高知识图谱分析应用的效率。那么GPT-4强大的抽取能力是因为其见过海量的实体、关系知识,还是其本身因指令学习[11]和人类反馈而具备极强的泛化能力呢?我们进一步进行了未见知识抽取的泛化能力分析。
四、未见知识抽取的泛化能力分析
我们设计了一种虚拟知识抽取评测来分析未见知识的抽取泛化能力,通过使用随机数的方式构建虚拟实体知识(GPT-4的数据截止到2021年9月),并构建了自然界不存在的实体类型和关系类型组成知识三元组,通过指令告诉模型抽取该类型知识,以检验知识抽取的泛化能力。我们对随机的10个句子进行了实体、关系抽取评估,发现ChatGPT不具备对虚拟知识的抽取能力,而GPT-4能够准确根据指令抽取完全没有见过的实体和关系知识。因此,我们可以初步得出结论,GPT-4在一定程度上具备较强的泛化能力,可以通过指令快速具备新知识的抽取能力而非记忆了相关的知识(相关工作[12]已实证发现大模型具备极强的指令泛化能力)。
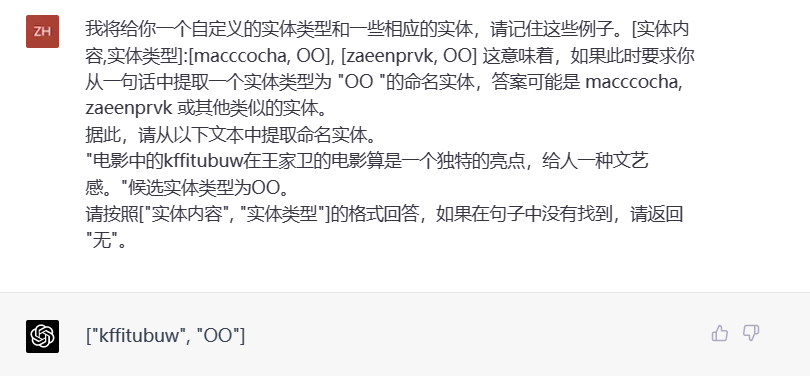
虚拟实体抽取

虚拟关系抽取
如上图所示,在给予一定的虚拟知识的时候,GPT-4能够在大部分情况下完成对于虚拟实体及关系的抽取(注:10次实验中仅有两次无法完成抽取任务)。如上图的虚拟实体抽取任务中,我们给GPT-4一些虚拟实体及相应虚拟类型如(“macccocha”,“OO”)、(“zaeenprvk”,“OO”),它能够完成对句子中“kffitubuw”这一虚拟实体的识别。与此同时,在上图对应的虚拟关系抽取任务中,我们提供了虚拟关系类型和虚拟头尾实体形成的三元组(“emvhes”,“Jancshrg”,“azqca”)等信息,也指定了头尾实体的虚拟类型“SKZ”,以及需要提取的关系类型“Jancshrg”,从结果来看,在给定相关信息的情况下,GPT-4也能完成对虚拟三元组的抽取。
五、大模型时代知识图谱构建的思路
鉴于大模型强大的可泛化抽取和大量的“参数知识”存储能力,我们简单测试了直接通过输入指令(GPT-4)和一小段文本构建知识图谱。


如图所示,我们发现GPT-4不仅精准地抽取了输入文本的中的事实知识,还生成和补全了一些不存在于文本中的知识(如:发行时间、演员等),也就是大模型GPT-4根据参数空间习得的知识脑补事实(经检查大部分都是正确的),进而构建了一个信息更丰富的知识图谱。也就是说,基于合适的输入指令,我们可以基于大模型(如通过EasyInstruct [13]等工具),同时从文本语料和参数空间抽取知识,构建更加精准、完备、个性化的知识图谱。
六、总结
本文对基于大模型的一部分知识图谱构建任务进行了评估,通过实验发现:
GPT-4在学术标准数据集上测试性能虽然仍弱于全监督小模型(该结果为初步探究,仍需通过更大规模数据集及更完备评估方式验证),但其具备较强的泛化能力,可以抽取新的和较为复杂的知识,且可以通过文本指令的优化不断提高性能,这给快速构建领域知识图谱带来了福音。
GPT-4可能在一定程度上并非依靠记忆实现知识抽取,而是通过指令学习和人类反馈具备了较强的可泛化知识抽取能力。
基于大模型指令可以同时从文本语料和参数空间抽取知识,进而提供了大模型时代构建知识图谱的新思路,可以降低知识图谱构建成本,也为通过知识图谱增强大模型(如结合Llama-Index等检索增强工具)提供了便利。
由于GPT-4的多模态接口目前未开放,因此本文未评测多模态知识抽取,但GPT-4给少样本多模态知识抽取与推理带来了新的机遇与挑战。
参考文献:
[1] Reasoning with Language Model Prompting: A Survey 2022
[2] Zero-Shot Information Extraction via Chatting with ChatGPT 2023
[3] Large Language Model Is Not a Good Few-shot Information Extractor, but a Good Reranker for Hard Samples! 2023
[4] Exploring the Feasibility of ChatGPT for Event Extraction 2023
[5] DuIE: A large-scale chinese dataset for information extraction NLPCC2019
[6] Re-tacred: Addressing shortcomings of the tacred dataset AAAI2021
[7] MAVEN: A Massive General Domain Event Detection Dataset EMNLP2020
[8] Multi-Task Identification of Entities, Relations, and Coreferencefor Scientific Knowledge Graph Construction EMNLP2018
[9] A Survey for In-context Learning 2022
[10] Code4Struct: Code Generation for Few-Shot Structured Prediction from Natural Language 2022
[11] Training language models to follow instructions with human feedback NeurIPS2022
[12] Larger Language Models Do In-Context Learning Differently
[13] https://github.com/zjunlp/EasyInstruct
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
版权归原作者 开放知识图谱 所有, 如有侵权,请联系我们删除。