
每天天都在努力学习的我们
前言
本篇博客讲解的内容依旧是使用Spark进行相关的数据分析,按理来说数据分析完之后应该搞一搞可视化的,由于目前时间紧张,顾不得学习可视化了,先来看一下此次的内容把。
在Kaggle数据平台下载了数据集albunms.csv,里面包含了的主要字段如下,先来看一下。

使用Spark读取csv
spark读取csv的方式有两种,一种是使用rdd进行读取csv,然后创建RDD对象。另一种是使用spark SQL进行读取,创建DataFrame对象。本篇博客使用Spark SQL进行读取文件,RDD和Data Frame处理数据。
csv文件我们都知道,","分隔符,但是读取csv文件的同时也要注意是否有无表头,表头字段类型。下面来看一下Spark SQL读取csv。
private
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark SQL") private
val sparkContext = new SparkContext(sparkConf)
private val sparkSession: SparkSession =SparkSession.builder().config(sparkConf).getOrCreate()
import sparkSession.implicits._ def
Transform_demo()={
//使用sparksession 读取csv文件,此csv文件有表头
val dataFrame = sparkSession.read.format("com.databricks.spark.csv")
//有无表头
.option("header", true)
//是否自动推断表头类型
.option("inferSchema", false)
//分隔符
.option("delimiter", ",")
//csv文件的地址
.csv("date/albums.csv")
dataFrame
}
统计各类型专辑的数量
**思路:**
各类型专辑的数量 ==》根据专辑类型(genre)分组,求出专辑类型的总和
使用spark SQL进行处理
def genre_demo() = {
//统计各个类型专辑的数量
val unit = Transform_demo()
.select($"genre")
.groupBy($"genre")
.count()
.sort($"count".desc)
.show() }
在Spark SQL中使用group by的时候,提供了group by之后的操作,比如
** max(colNames:String*):获取分组中指定字段或者所有的数字类型字段的最大值,只能作用于数字型字段。**
** min(colNames:String*):获取分组字段或者所有的数字类型字段的最小值,只能作用于数字类型的字段。**
** mean(colName:String*):获取分组中指定字段或者所有数字类型字段的平均值,只能作用于数据类型的字段**
** sum(colNames:String*):获取分组中指定字段或者所有数字类型字段的累加值,只能作用于数字类型的字段**
** count():获取分组中的元素个数**
根据genre字段分组后,求出专辑类型的个数,对专辑类型的个数进行排序。如果需要导入到文件里面,那么需要.write。
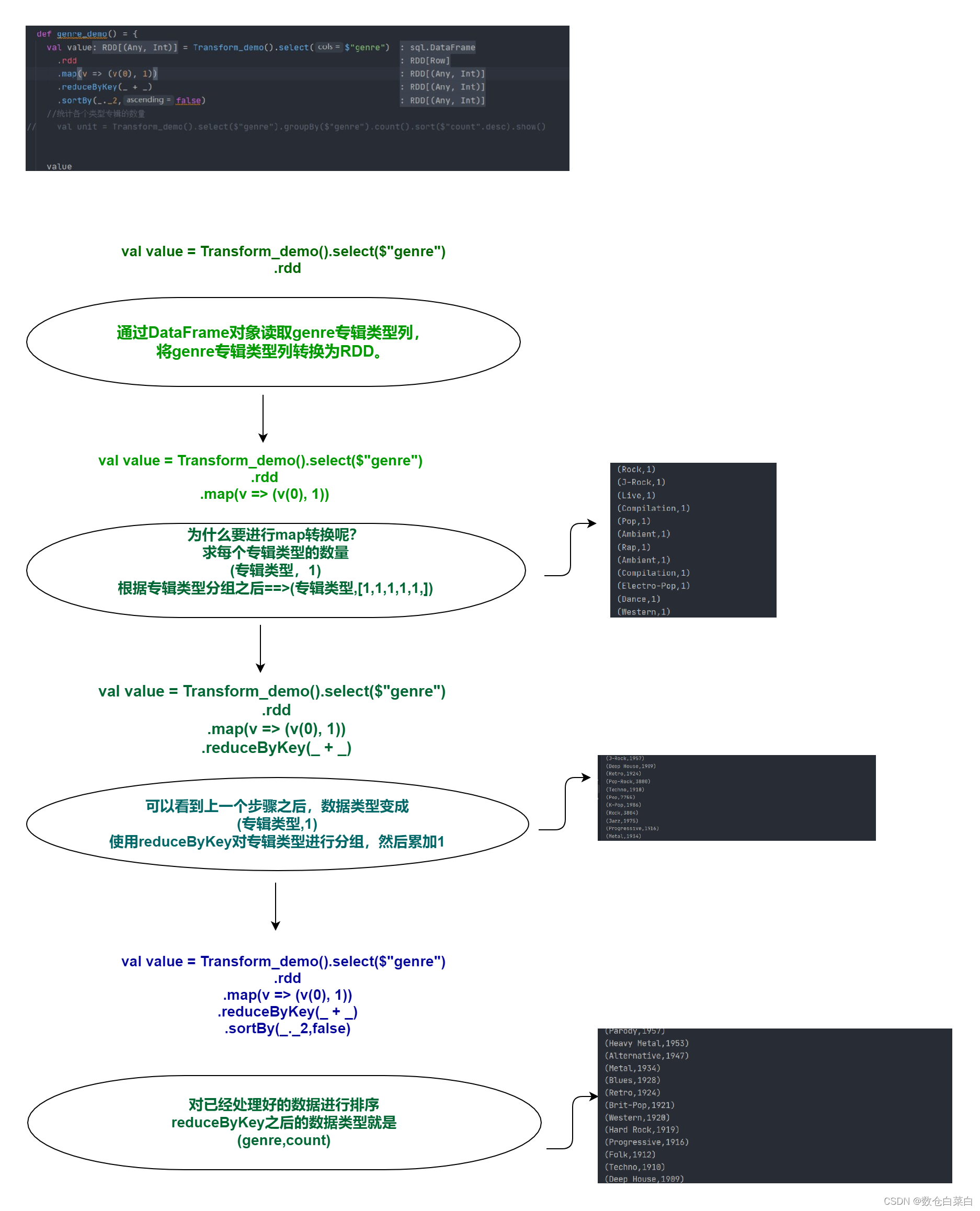
使用Rdd进行处理
def genre_demo() = {
val value = Transform_demo()
.select($"genre")
.rdd
.map(v => (v(0), 1))
.reduceByKey(_ + _)
.sortBy(_._2,false)
展示一下上面的流程图把
统计各类型专辑的销量总数
思路:
根据专辑类型分组,分组之后,计算num_of_sales专辑销量总和。
如果是spark SQL的话,流程应该是这样的。
** dataFrame => select => group by => sum()**
来看一下代码
def countByNum_sales()={
Transform_demo()
.select($"genre",$"num_of_sales")
.withColumn("num_of_sales",col("num_of_sales")
.cast("Integer"))
.groupBy("genre")
.sum("num_of_sales")
.orderBy($"sum(num_of_sales)".desc)
.show() }
如果在group by后面直接sum求和,那么是会报错的,因为在最开始的时候,我们并没有让系统自动推断表头的数据类型,默认为String类型,因此需要先转换为整型,然后对其进行操作。
来看一下RDD的代码
def countByNum_sales()={
val value = Transform_demo()
.select($"genre", $"num_of_sales")
.rdd
.map(v => (v(0).toString, v(1).toString.toInt))
.reduceByKey(_ + _) .sortBy(_._2, false)
value }

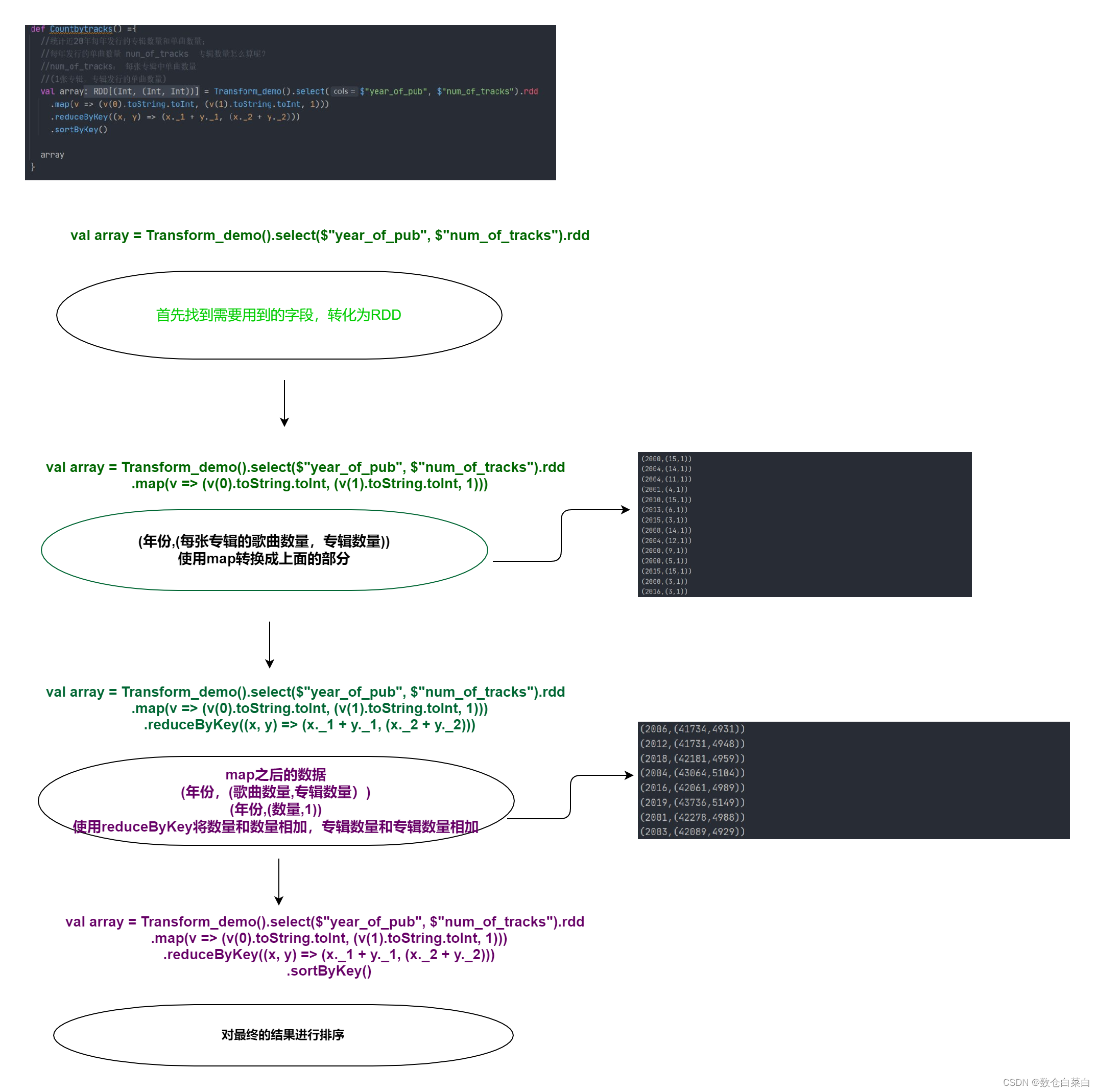
统计近20年每年发行的专辑数量和单曲数量
思路:
根据年份分组(year_of_pub),求每年发行的专辑数量和单曲数量。
单曲数量很简单(num_of_tracks)累加,但是专辑数量怎么表示呢?
** 注意一下,num_of_tracks字段:每张专辑中的单曲数量,什么意思呢?来看一下这样的表示**
** (num_of_tracks,1) =》 (每张专辑的单曲数量,专辑数量)**
这个1就代表着专辑的数量。
用RDD来理一下思路,(年份,(每张专辑的单曲数量,1)) ==>经过reduceByKey (年份,(每年发行的单曲数量,每年发行的专辑数量))
def Countbytracks() ={
//统计近20年每年发行的专辑数量和单曲数量;
//每年发行的单曲数量 num_of_tracks 专辑数量怎么算呢?
//num_of_tracks: 每张专辑中单曲数量
//(1张专辑,专辑发行的单曲数量)
val array = Transform_demo()
.select($"year_of_pub", $"num_of_tracks")
.rdd
.map(v => (v(0).toString.toInt, (v(1).toString.toInt, 1)))
.reduceByKey((x, y) => (x._1 + y._1, (x._2 + y._2)))
.sortByKey()
array }
来看一下流程图
分析总销量前五的专辑类型的各年份销量
思路:
** 首先求出来总销售量前五的专辑类型,然后取前五个数量最多的,之后在这个五个数量最多的专辑类型里面计算每年的销量。**
首先获取总销售量前五的专辑类型
def get_genre() = {
//先获取总销售量前5的专辑类型
val array = Transform_demo()
.select($"genre", $"num_of_sales")
.withColumn("num_of_sales", col("num_of_sales").cast("Integer"))
.groupBy($"genre")
.sum("num_of_sales")
.orderBy($"sum(num_of_sales)".desc)
.rdd
.map(v => v(0).toString)
.take(5)
array }
首先更改字段类型,根据销售类型(genre)分组,找到销量最多的销售类型.经过map转换之后取前五个销售类型。
** 获取总销量前5的专辑类型的各年份销量**
def per_year_sales()={
val genre_list = get_genre()
val value = Transform_demo()
.select($"genre", $"year_of_pub", $"num_of_sales")
.rdd
.filter(v => genre_list.contains(v(0)) )
.map(v => ((v(0).toString, v(1).toString), v(2).toString.toInt))
.reduceByKey(_ + _)
value }
如果单独看上面的代码看不懂,那么来看一下下面的流程图把,一定明明白白。

总结
关于这篇音乐分析项目就到此为止了。
关于对数据的基本处理已经有了些眉目,接下来就是不断的练习练习。
之后还有会其它的项目,我们最终的Boss项目就是离线数仓项目的建设。
** 最后,希望我的她可以越来越好,天天开心**
本文转载自: https://blog.csdn.net/weixin_46300771/article/details/123285462
版权归原作者 数仓白菜白 所有, 如有侵权,请联系我们删除。
版权归原作者 数仓白菜白 所有, 如有侵权,请联系我们删除。