

专栏文章索引:爬虫
一、介绍
所用工具:DrissionPage
二、找到目标数据(2个确定)
1.确定目标网页
- 打开目标网站
网站:「南京招聘网」海量南京人才招聘信息 - BOSS直聘(自动定位所在地点,我是南京)

- 通过关键字搜索

- 观察页面上是否有想要的数据

2.确定目标网址
我们直接用浏览器网网址输入框中的网址即可
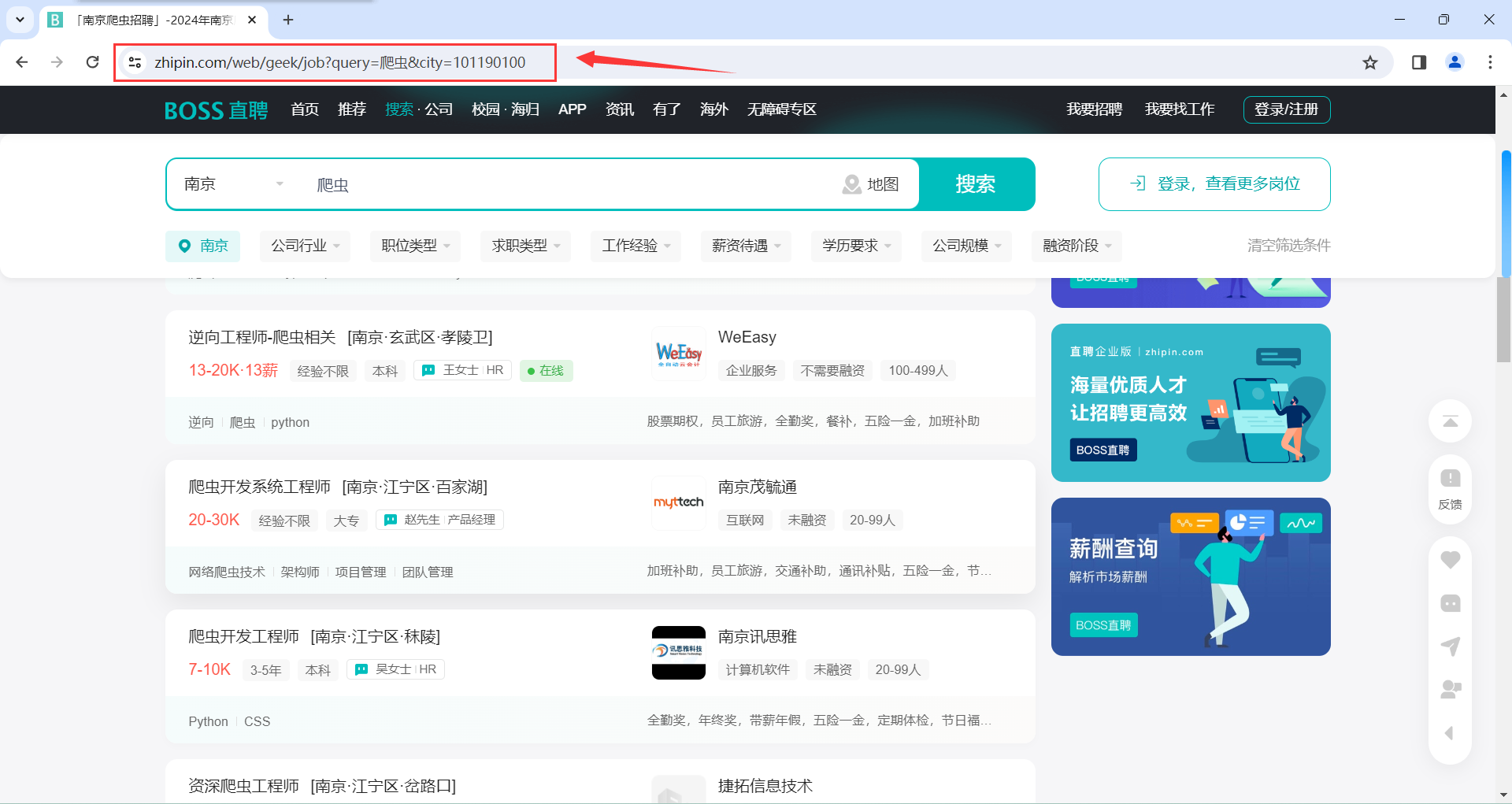
- 切换网页并复制粘贴网址
由于网址(域名+参数),域名不会变,参数可能会随着页面的变化而变化
我们可先翻到第2页

可以看到网址也发生了改变
我们可以切换不同的页码并将网址赋值粘贴下来(一般3-4个即可)
注意最后再重新翻到第一页
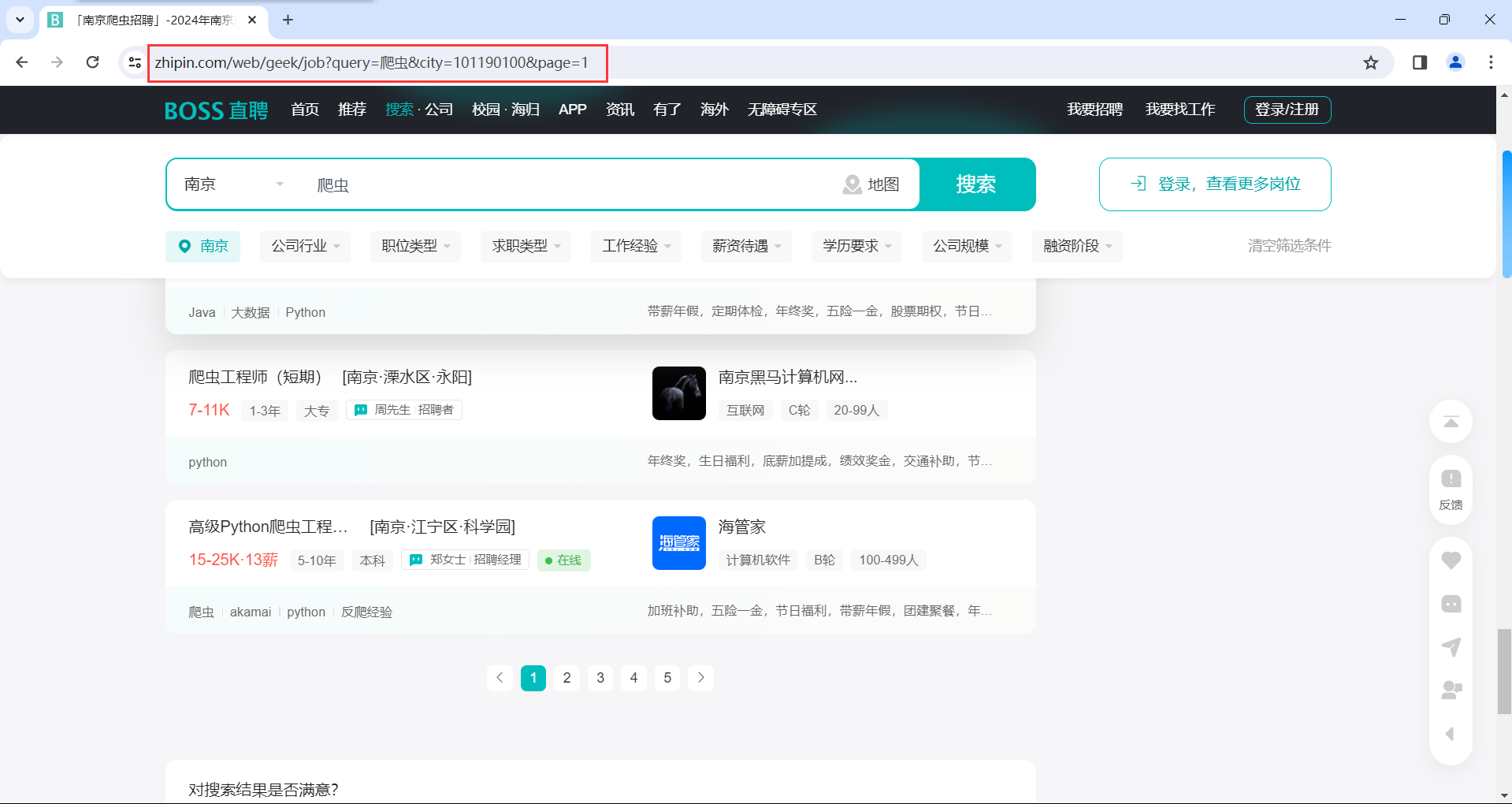
可以看到当重新翻到第一页的时候网址发生了变化,第一页用这个网址即可
- 观察网址

可以看到只有page参数有变化,显然page参数对应的是页码数
三、编写代码
- 导入所需库
# 导入WebPage库
from DrissionPage import WebPage
# 导入动作链
from DrissionPage.common import Actions
# 导入时间库
import time
# 导入读取和写入文件库
import csv
- 查找元素获取数据
ele1 = page.eles('.job-card-body clearfix')
for i in range(len(ele1)):
ele2 = ele1[i].ele('.job-card-left')
ele3 = ele2.ele('.job-title clearfix')
# title 岗位名称
title = ele3.ele('.job-name').text
# area 公司地址
ele4 = ele3.ele('.job-area-wrapper')
area = ele4.ele('.job-area').text
ele5 = ele2.ele('.job-info clearfix')
# salary 薪水
salary = ele5.ele('.salary').text
ele6 = ele5.ele('.tag-list')
ele7 = ele6.eles('tag:li')
# time 工作时限
time = ele7[0].text
# education 学历
education = ele7[1].text
ele8 = ele1[i].ele('.job-card-right')
ele9 = ele8.ele('.company-info')
# name 公司名称
name = ele9.ele('tag:a').text
print(title, area, salary, time, education, name)
- 切换到下一页
ac.click('.ui-icon-arrow-right')
- 保存数据
with open('招聘信息.csv', 'a', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
# 写入数据
writer.writerows(date_list)
- 完整代码(免费获取)
【免费】爬取Boss直聘招聘信息数据资源-CSDN文库
四、查看数据
- 控制台

- 文件

五、总结
直接用DrissionPage即可,没有特别的地方

本文转载自: https://blog.csdn.net/m0_63636799/article/details/136823101
版权归原作者 我和程序有一个能跑就行 所有, 如有侵权,请联系我们删除。
版权归原作者 我和程序有一个能跑就行 所有, 如有侵权,请联系我们删除。