
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
关于ollama
- ollama和LLM(大型语言模型)的关系,类似于docker和镜像,可以在ollama服务中管理和运行各种LLM,下面是ollama命令的参数,与docker管理镜像很类似,可以下载、删除、运行各种LLM
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
cp Copy a model
rm Remove a model
help Help about any command
- 官网:https://ollama.com/
- 非常简洁
本篇概览
- 作为入门操作的笔记,本篇记录了部署和简单体验ollama的过程,并且通过docker部署了web-ui,尝试通过页面使用大模型
- 本次操作的环境如下
- 电脑:macbook pro m1,Sonoma 14.4.1
- ollama:0.1.32
安装
- 在官网首页点击Download即可下载,得到zip安装包,解压后就是应用程序了
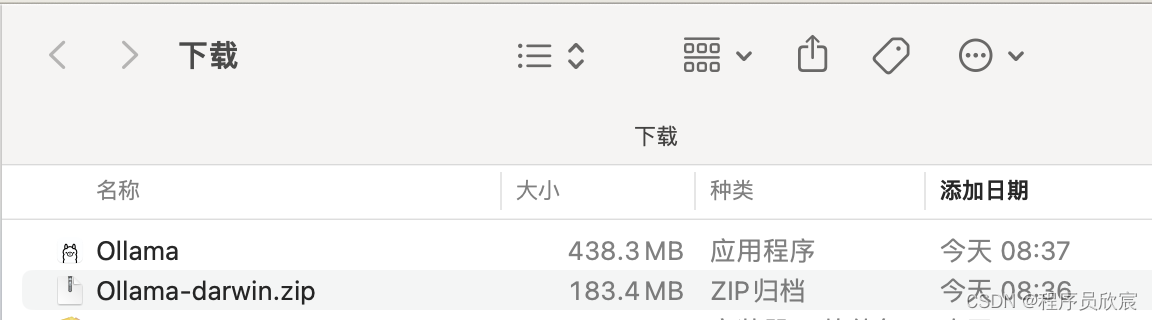
- 会提示是否移动到应用程序目录,回车确认

- 打开后是个简单的页面
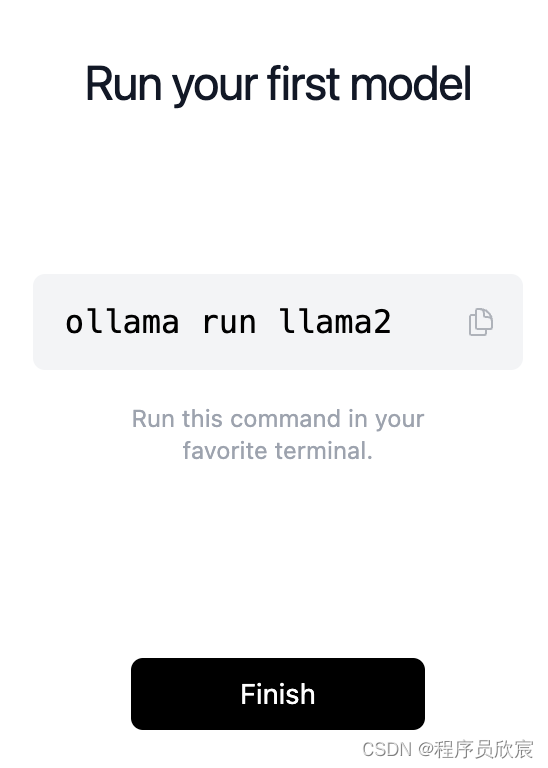
- 完成安装,会有一个提示,告诉你如何安装指定模型
关于模型
ollama支持的全量模型在这里:https://ollama.com/library
官方给出的部分模型
ModelParametersSize下载命令Llama 38B4.7GBollama run llama3Llama 370B40GB
ollama run llama3:70bPhi-33.8B2.3GB
ollama run phi3Mistral7B4.1GB
ollama run mistralNeural Chat7B4.1GB
ollama run neural-chatStarling7B4.1GB
ollama run starling-lmCode Llama7B3.8GB
ollama run codellamaLlama 2 Uncensored7B3.8GB
ollama run llama2-uncensoredLLaVA7B4.5GB
ollama run llavaGemma2B1.4GB
ollama run gemma:2bGemma7B4.8GB
ollama run gemma:7bSolar10.7B6.1GB
ollama run solar另外需要注意的是本地内存是否充足,7B参数的模型需要8G内存,13B需要16G内存,33B需要32G内存
运行8B的Llama3
- 我的mac笔记本内存16G,所以打算运行8B的Llama3,命令如下
ollama run llama3
- 第一次运行,因为没有模型文件,所以需要下载,等待下载中
 - 下载完毕后就可以问答了
- 下载完毕后就可以问答了
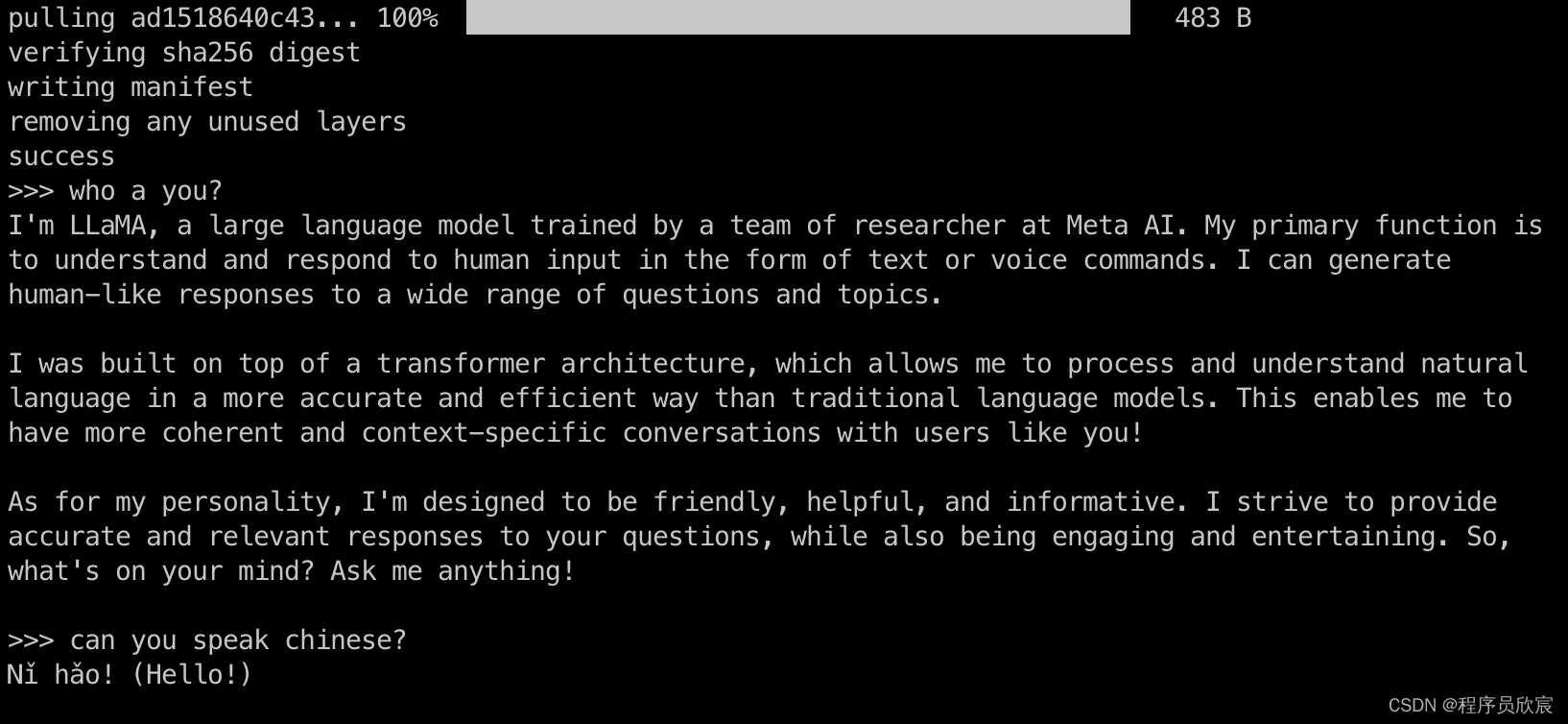
- 退出的方法是输入/bye
Linux版本
- 如果操作系统是Linux,安装命令如下
curl-fsSL https://ollama.com/install.sh |sh
- 安装完成后还要启动
ollama serve
webui
- 如果电脑上装有docker,请执行以下命令来启动ollama的webui
docker run -d-p3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
- 出现登录页面,需要点击右下角的Sign up先注册
- 完成注册后,第一次登录会出现特性介绍
- 可以在这里修改系统语言
- 接下来试试聊天功能,先是选择模型,由于刚才已经下载过模型了,这里只要选择即可,如下图
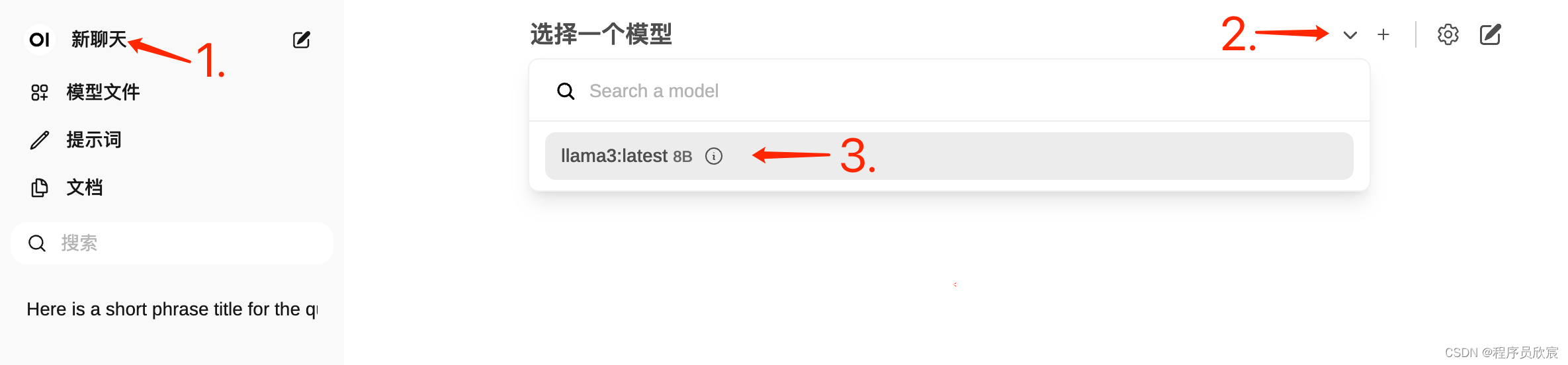
- 然后就可以对话了
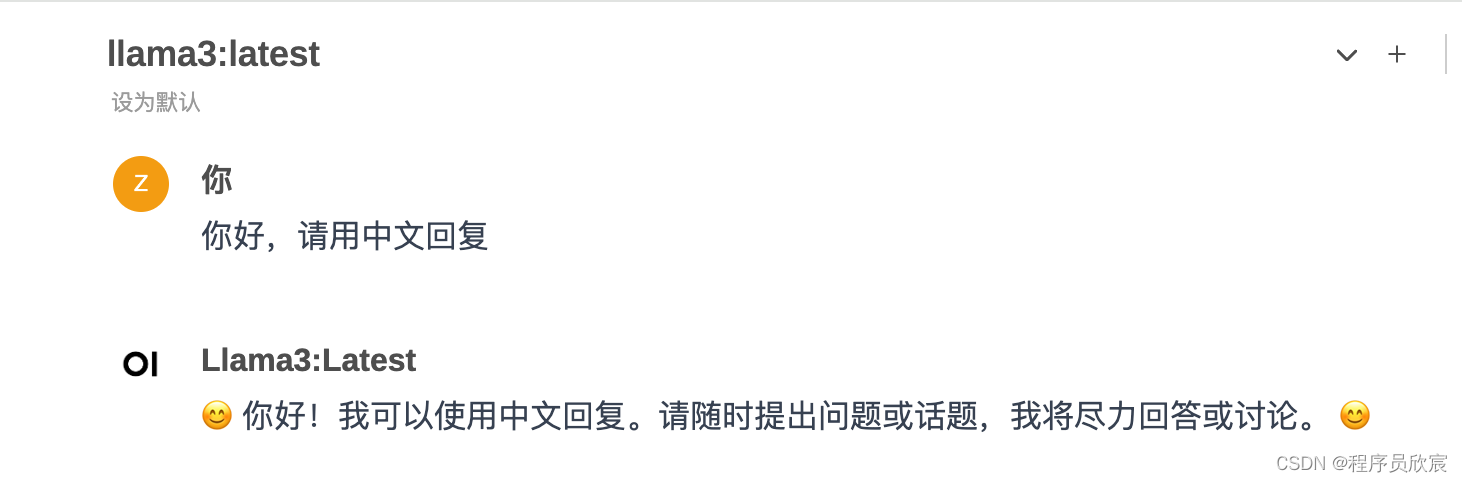
- 在设置页面可以管理模型
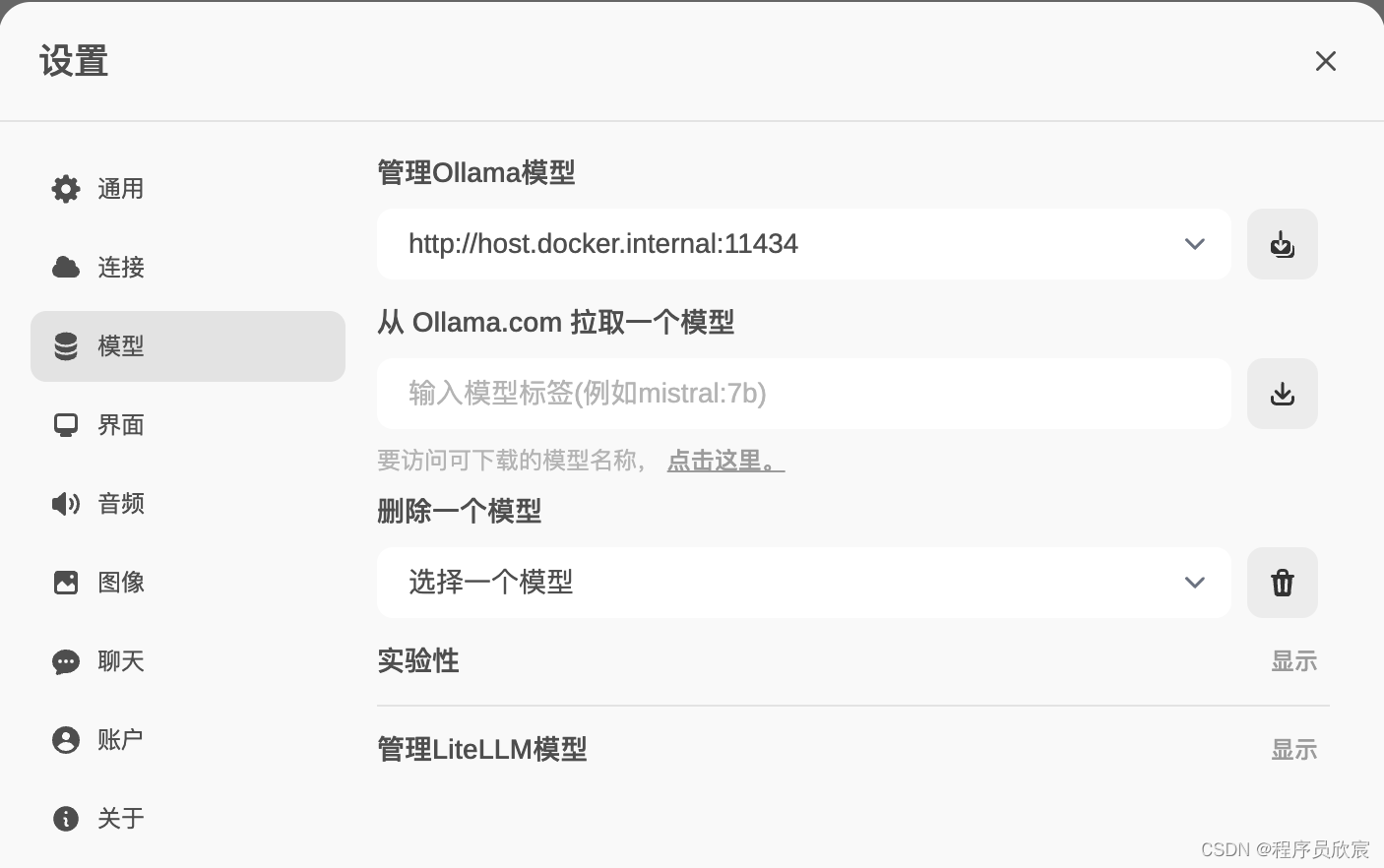
- 至此,最基础的操作已经完成,如果您正处于初步尝试阶段,希望本文可以给您一些参考
你不孤单,欣宸原创一路相伴
- Java系列
- Spring系列
- Docker系列
- kubernetes系列
- 数据库+中间件系列
- DevOps系列
本文转载自: https://blog.csdn.net/boling_cavalry/article/details/138387039
版权归原作者 程序员欣宸 所有, 如有侵权,请联系我们删除。
版权归原作者 程序员欣宸 所有, 如有侵权,请联系我们删除。