
** 前 言:**作为当前先进的深度学习目标检测算法YOLOv5,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv5的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。
解决问题:YOLOv5主干特征提取网络采用C3结构,带来较大的参数量,检测速度较慢,应用受限,在某些真实的应用场景如移动或者嵌入式设备,如此大而复杂的模型时难以被应用的。首先是模型过于庞大,面临着内存不足的问题,其次这些场景要求低延迟,或者说响应速度要快,想象一下自动驾驶汽车的行人检测系统如果速度很慢会发生什么可怕的事情。所以,研究小而高效的CNN模型在这些场景至关重要,至少目前是这样,尽管未来硬件也会越来越快。本文尝试将主干特征提取网络替换为更轻量的EfficientNetV2网络,以实现网络模型的轻量化,平衡速度和精度。
以下为历史发布博客篇。
YOLOv5改进之十一:主干网络C3替换为轻量化网络MobileNetV3_人工智能算法工程师0301的博客-CSDN博客
YOLOv5改进之十二:主干网络C3替换为轻量化网络ShuffleNetV2_人工智能算法工程师0301的博客-CSDN博客
原理:
论文地址:https://arxiv.org/abs/2104.0029
谷歌的MingxingTan与Quov V.Le对EfficientNet的一次升级,旨在保持参数量高效利用的同时尽可能提升训练速度。在EfficientNet的基础上,引入了Fused-MBConv到搜索空间中;同时为渐进式学习引入了自适应正则强度调整机制。两种改进的组合得到了本文的EfficientNetV2,它在多个基准数据集上取得了SOTA性能,且训练速度更快。比如EfficientNetV2取得了87.3%的top1精度且训练速度快5-11倍。
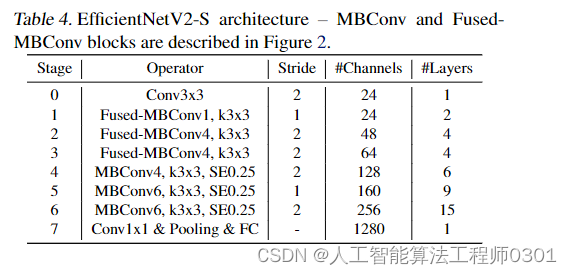
方 法:
第一步修改common.py,增加MobileNetV3模块。
class stem(nn.Module):
def __init__(self, c1, c2, kernel_size=3, stride=1, groups=1):
super().__init__()
self.conv = nn.Conv2d(c1, c2, kernel_size, stride, padding=padding, groups=groups, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=1e-3, momentum=0.1)
self.act = nn.SiLU(inplace=True)
def forward(self, x):
# print(x.shape)
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
return x
def drop_path(x, drop_prob: float = 0., training: bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class SqueezeExcite_efficientv2(nn.Module):
def __init__(self, c1, c2, se_ratio=0.25, act_layer=nn.ReLU):
super().__init__()
self.gate_fn = nn.Sigmoid()
reduced_chs = int(c1 * se_ratio)
self.conv_reduce = nn.Conv2d(c1, reduced_chs, 1, bias=True)
self.act1 = act_layer(inplace=True)
self.conv_expand = nn.Conv2d(reduced_chs, c2, 1, bias=True)
def forward(self, x):
x_se = self.avg_pool(x)
x_se = self.conv_reduce(x_se)
x_se = self.act1(x_se)
x_se = self.conv_expand(x_se)
x_se = self.gate_fn(x_se)
x = x * (x_se.expand_as(x))
return x
class FusedMBConv(nn.Module):
def __init__(self, c1, c2, k=3, s=1, expansion=1, se_ration=0, dropout_rate=0.2, drop_connect_rate=0.2):
super().__init__()
assert s in [1, 2]
self.has_shortcut = (s == 1 and c1 == c2)
expanded_c = c1 * expansion
if self.has_expansion:
self.expansion_conv = stem(c1, expanded_c, kernel_size=k, stride=s)
self.project_conv = stem(expanded_c, c2, kernel_size=1, stride=1)
else:
self.project_conv = stem(c1, c2, kernel_size=k, stride=s)
self.drop_connect_rate = drop_connect_rate
if self.has_shortcut and drop_connect_rate > 0:
self.dropout = DropPath(drop_connect_rate)
def forward(self, x):
if self.has_expansion:
result = self.expansion_conv(x)
result = self.project_conv(result)
else:
result = self.project_conv(x)
if self.has_shortcut:
if self.drop_connect_rate > 0:
result = self.dropout(result)
result += x
return result
class MBConv(nn.Module):
def __init__(self, c1, c2, k=3, s=1, expansion=1, se_ration=0, dropout_rate=0.2, drop_connect_rate=0.2):
super().__init__()
assert s in [1, 2]
self.has_shortcut = (s == 1 and c1 == c2)
# print(c1, c2, k, s, expansion)
expanded_c = c1 * expansion
self.dw_conv = stem(expanded_c, expanded_c, kernel_size=k, stride=s, groups=expanded_c)
self.se = SqueezeExcite_efficientv2(c1, expanded_c, se_ration) if se_ration > 0 else nn.Identity()
self.project_conv = stem(expanded_c, c2, kernel_size=1, stride=1)
self.drop_connect_rate = drop_connect_rate
if self.has_shortcut and drop_connect_rate > 0:
self.dropout = DropPath(drop_connect_rate)
def forward(self, x):
# print(x.shape)
result = self.expansion_conv(x)
result = self.dw_conv(result)
result = self.se(result)
result = self.project_conv(result)
if self.has_shortcut:
if self.drop_connect_rate > 0:
result = self.dropout(result)
result += x
return result
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5, e=0.5, ratio=1.0): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
# c_ = c1 // 2 # hidden channels
c_ = int(c1 * e)
c2 = int(c2 * ratio)
c2 = make_divisible(c2, 8)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
第二步:将yolo.py中注册模块。
if m in [Conv,MobileNetV3_InvertedResidual,ShuffleNetV2_InvertedResidual, ]:
第三步:修改yaml文件
backbone:
[[-1, 1, stem, [24, 3, 2]], # 0-P1/2
[-1, 2, FusedMBConv, [24, 3, 1, 1, 0]], # 1-p2/4
[-1, 1, FusedMBConv, [48, 3, 2, 4, 0]], # 2
[-1, 3, FusedMBConv, [48, 3, 1, 4, 0]], # 3
[-1, 1, FusedMBConv, [64, 3, 2, 4, 0]], # 4
[-1, 3, FusedMBConv, [64, 3, 1, 4, 0]], # 5
[-1, 1, MBConv, [128, 3, 2, 4, 0.25]], # 6
[-1, 5, MBConv, [128, 3, 1, 4, 0.25]], # 7
[-1, 1, MBConv, [160, 3, 2, 6, 0.25]], # 8
[-1, 8, MBConv, [160, 3, 1, 6, 0.25]], # 9
[-1, 1, MBConv, [256, 3, 2, 4, 0.25]], # 10
[-1, 14, MBConv, [256, 3, 1, 4, 0.25]], # 11
[-1, 1, SPPF, [1024, 5]], #12
# [-1, 1, SPP, [1024, [5, 9, 13]]],
]
# YOLOv5 v6.0 head
结 果:本人在多个数据集上做了大量实验,针对不同的数据集效果不同,map值有所下降,但是权值模型大小降低,参数量下降。
预告一下:下一篇内容将继续分享网络轻量化方法ghost的分享。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦
PS:主干网络的替换不仅仅是适用改进YOLOv5,也可以改进其他的YOLO网络以及目标检测网络,比如YOLOv4、v3等。
最后,希望能互粉一下,做个朋友,一起学习交流。
版权归原作者 人工智能算法研究院 所有, 如有侵权,请联系我们删除。