
活动地址:CSDN21天学习挑战赛
📢📢📢📣📣📣
哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10年DBA工作经验
一位上进心十足的【大数据领域博主】!😜😜😜
中国DBA联盟(ACDU)成员,目前从事DBA及程序编程
擅长主流数据Oracle、MySQL、PG 运维开发,备份恢复,安装迁移,性能优化、故障应急处理等。
✨ 如果有对【数据库】感兴趣的【小可爱】,欢迎关注【IT邦德】💞💞💞
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
文章目录
前言
Python实际针对数据分析的学习是库,用库来解决一系列的数据分析问题
🐴 DA44 某店铺消费最多的前三名用户
🚀 描述
现有某店铺会员消费情况sales.csv。包含以下字段:
user_id:会员编号;
recency:最近一次消费距离当天的天数;
frequency:一段时间内消费的次数;
monetary:一段时间内消费的总金额。
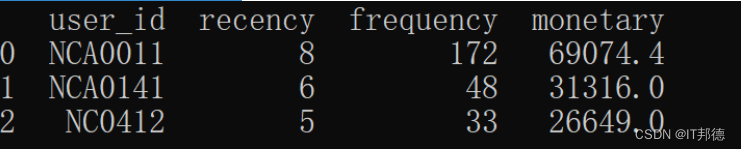
请你统计消费金额最多的前3名用户。
📖 输入描述
数据集可以从当前目录下sales.csv读取。
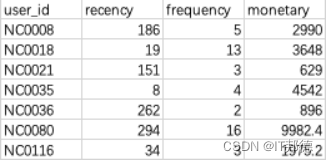
📖 输出描述:
输出销售金额最多的前3名用户,索引从0开始。
以上数据集的输出如下图所示。
🍌🍌 答案
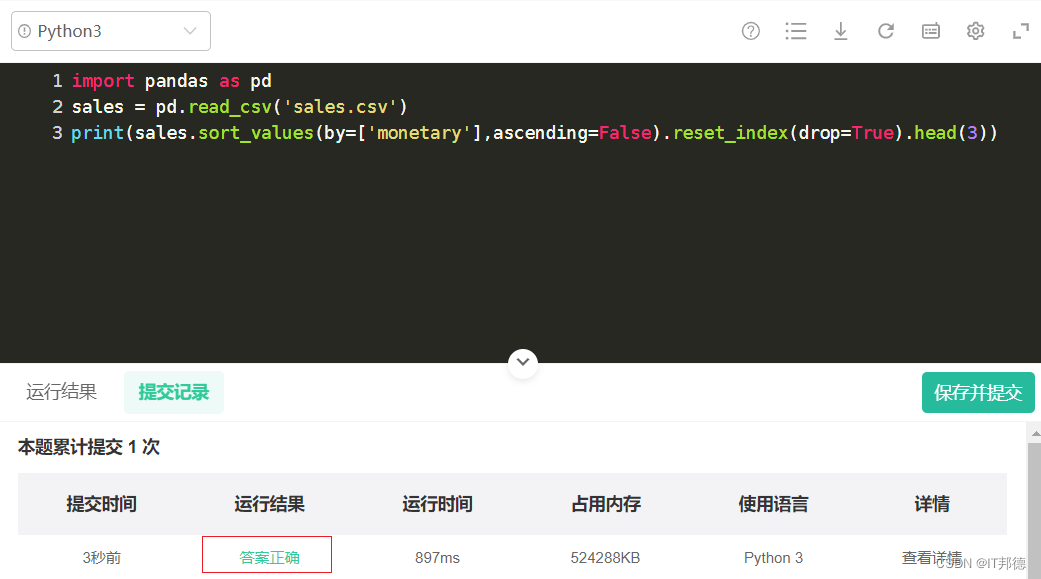
import pandas as pd
sales = pd.read_csv('sales.csv')print(sales.sort_values(by=['monetary'],ascending=False).reset_index(drop=True).head(3))
🐴 DA45 按照等级递增序查看牛客网用户信息
🚀 描述
现有一个Nowcoder.csv文件,记录了牛客网的部分用户的个人信息,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Name:用户名
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
牛牛在查看这些数据的时候,等级都是混乱的,他想按照1-7级的递增序查看这些用户数据,你能帮他输出一下吗?
📖 输入描述
数据集直接从当前目录下的Nowcoder.csv文件中读取。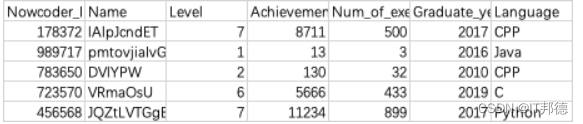
📖 输出描述:
输出排序后的全部数据,包括行号。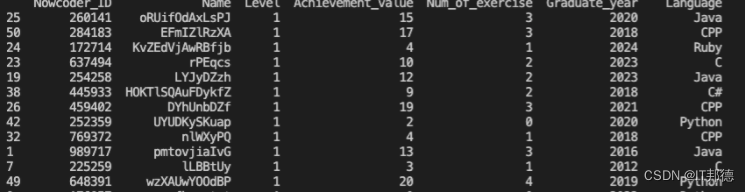
🍌🍌 答案
import pandas as pd
pd.set_option('display.width',300)# 设置字符显示宽度
pd.set_option('display.max_rows',None)# 设置显示最大行
pd.set_option('display.max_columns',None)
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
data = Nowcoder.sort_values(by='Level', ascending =False)print(data)
🐴 DA46 某店铺用户消费特征评分
🚀 描述
现有某店铺会员消费情况sales.csv。包含以下字段:
user_id:会员编号;
recency:最近一次消费距离当天的天数;
frequency:一段时间内消费的次数;
monetary:一段时间内消费的总金额。
请你分别对每个用户的每个消费特征进行评分。
📖 输入描述
数据集可以从当前目录下sales.csv读取。
📖 输出描述:
请你对每个用户销售情况的每个特征进行评分,分值为1-4分。对于recency特征,值越小越好。对于frequency和monetary值越大越好。请分别将对应的数据进行四等分并评分,如对于recency:
数值小于等于下四分位数则评为4分;
大于下四分位数并且小于等于中位数则评为3分;
大于中位数且小于等于上四分位数则评为2分;
大于上四分位数则评为1分。
对于frequency和monetary则方法刚好相反。
要求给所有数据进行评分,并输出前5行。以上数据的输出结果如下:
🍌🍌 答案
import pandas as pd
sales = pd.read_csv('sales.csv')
sales['R_Quartile']= pd.qcut(sales['recency'],[0,0.25,0.5,0.75,1],
labels=['4','3','2','1']).astype('int')
sales['F_Quartile']= pd.qcut(sales['frequency'],[0,0.25,0.5,0.75,1],
labels=['1','2','3','4']).astype('int')
sales['M_Quartile']= pd.qcut(sales['monetary'],[0,0.25,0.5,0.75,1],
labels=['1','2','3','4']).astype('int')print(sales.head())
🐴 DA47 筛选某店铺最有价值用户中消费最多前5名
🚀 描述
现有某店铺会员消费情况sales.csv。包含以下字段:
user_id:会员编号;
recency:最近一次消费距离当天的天数;
frequency:一段时间内消费的次数;
monetary:一段时间内消费的总金额。
请你统计最有价值的用户中消费金额最多的前5名用户。
📖 输入描述
数据集可以从当前目录下sales.csv读取。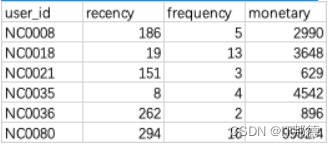
📖 输出描述:
请你先对每个用户销售情况的每个特征进行评分,分值为1-4分。再将所有评分拼接到一起形成新的列RFMClass。
评分规则如下: 对于recency特征,值越小越好。对于frequency和monetary值越大越好。如对于recency:
数值小于等于下四分位数则评为4分;
大于下四分位数并且小于等于中位数则评为3分;
大于中位数且小于等于上四分位数则评为2分;
大于上四分位数则评为1分。
对于frequency和monetary则方法刚好相反。
请你输出评分后的数据的前5行并输出最有价值的用户(评分为“444”)中销售总金额最高的前5位(索引从0开始),以上数据集的输出如下图所示(两次输出之间有一个空行)。
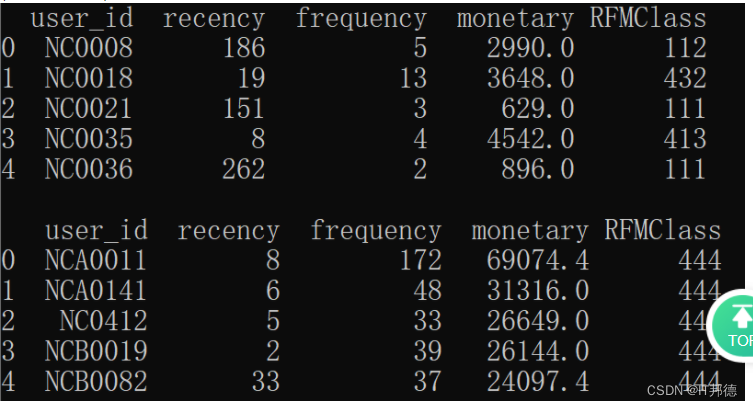
🍌🍌 答案
import pandas as pd
sales = pd.read_csv('sales.csv')
sales["monetary"]= sales["monetary"].astype("float")
sales["R_Quartile"]= pd.qcut(sales["recency"],[0,0.25,0.5,0.75,1],
labels=["4","3","2","1"]).astype("str")
sales["F_Quartile"]= pd.qcut(sales["frequency"],[0,0.25,0.5,0.75,1],
labels=["1","2","3","4"]).astype("str")
sales["M_Quartile"]= pd.qcut(sales["monetary"],[0,0.25,0.5,0.75,1],
labels=["1","2","3","4"]).astype("str")
sales['RFMClass']=sales['R_Quartile']+sales['F_Quartile']+sales['M_Quartile']
sales1=sales[['user_id','recency','frequency','monetary','RFMClass']]
data1=sales1.head(5)print(data1)
data2=sales1[sales1['RFMClass']=='444'].sort_values(by='monetary',ascending=False).head(5).reset_index(drop=True)print('\n')print(data2)

本文转载自: https://blog.csdn.net/weixin_41645135/article/details/126373484
版权归原作者 IT邦德 所有, 如有侵权,请联系我们删除。
版权归原作者 IT邦德 所有, 如有侵权,请联系我们删除。