
一、基本介绍
Apriori算法是经典的挖掘频繁项目集和关联规则的数据挖掘算法。当定义问题时,通常会使用先验知识或者假设,这被称作"一个先验"。算法使用频繁项目集的先验性质,即频繁项目集的所有非空子集也一定是频繁的。Apriori算法使用一种称为逐层搜索的迭代方法,其中*k*项集用于探索(k+1)项集。首先通过扫描数据库,累计每个项的计数,并收集满足最小支持度的项,找出频繁1项集的集合。该集合记为L1。然后,使用L1找出频繁2项集的集合L2,使用L2找出L3……如此下去,直到不能再找到频繁k项集。每找出一个Lk需要一次数据库的完整扫描。Apriori算法利用频繁项目集的先验性质来压缩搜索空间。
二、核心思想
项目空间集理论:
定理1:若项目集*X*是频繁项目集,则它的所有非空子集都是频繁项目集。 定理2:如项目集*X*是非频繁项目集,则它的所有超集都是非频繁项目集。
三、原理演示

红色部分为不小于最小支持度的项,被添加到频繁项目集中; 黄色部分为小于最小支持度的项,它及它的超集不会添加到频繁项目集中; 蓝色部分为最大频繁项目集,本身是频繁项集,且其中任何一项的超集都是非频繁的。
四、算法流程图

五、关键源码展示
1、导入数据

2、数据预处理
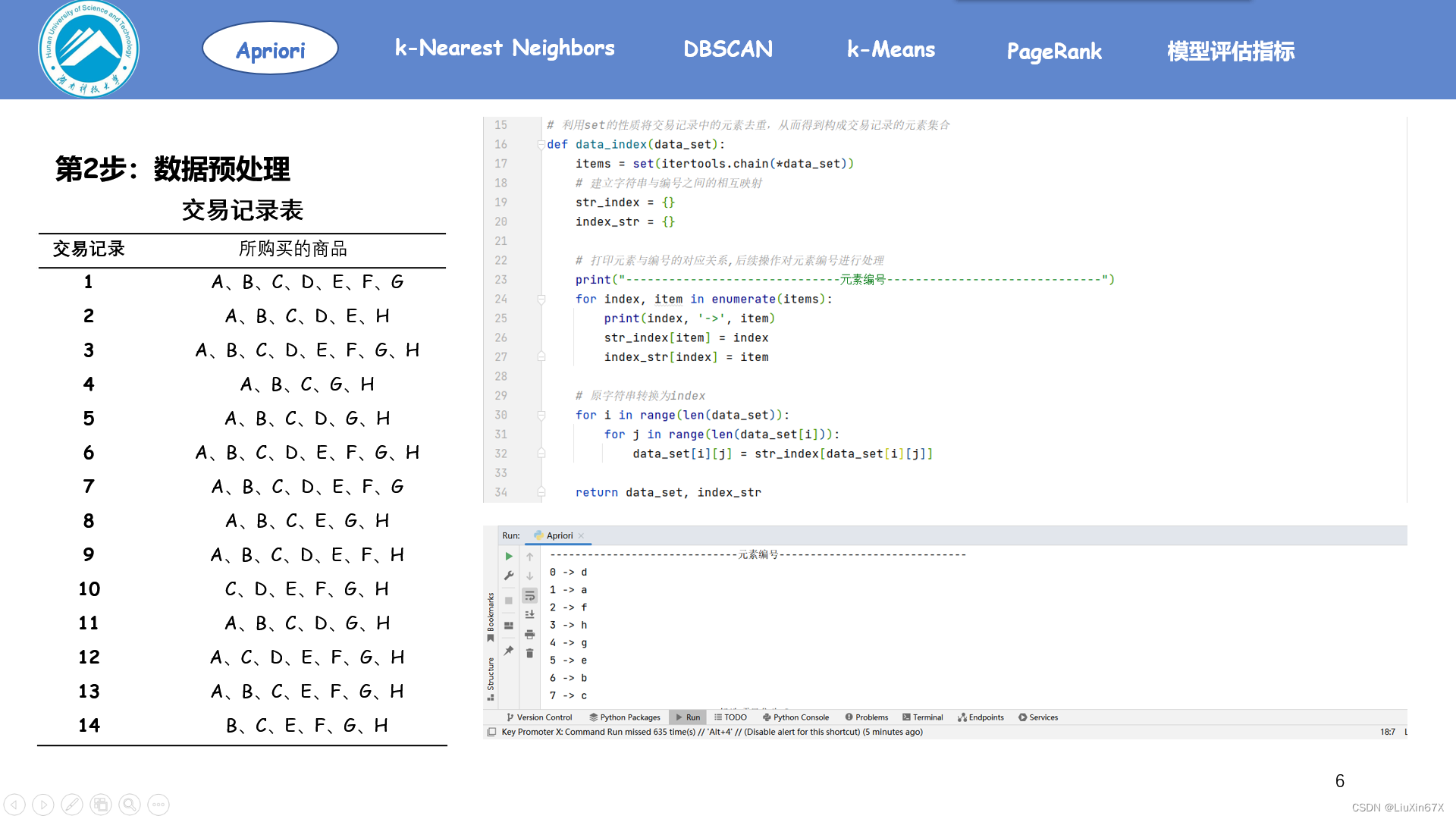
3、生成候选/频繁项目集



4、关联规则生成


标签:
数据挖掘
本文转载自: https://blog.csdn.net/Liu_Xin233/article/details/128337643
版权归原作者 LiuXin67X 所有, 如有侵权,请联系我们删除。
版权归原作者 LiuXin67X 所有, 如有侵权,请联系我们删除。