
【前沿技术杂谈:多模态文档基础模型】使用多模态文档基础模型彻底改变文档 AI
您是否曾经被包含不同信息(如应付账款、日期、商品数量、单价和金额)的发票所淹没?在处理重要的商业合同时,您是否担心小数点后点错误,造成无法估量的经济损失?您是否在寻找顶尖人才时阅读过大量简历?商务人士必须处理所有这些任务和各种各样的文件,包括保险单、业务报告、电子邮件和运输订单。
在数字时代,公司通常必须将所有这些文档以及各种图表和图像数字化,以简化其程序。然而,手动数字化文档是一种低效的做法,因为许多扫描文档的质量参差不齐,而网页和电子文档可能具有不同的布局。我们如何有效地提取、组织和分析这些不同文档中的信息?答案是文档人工智能技术,它将员工和公司从这种重复而乏味的工作中解放出来。

具有不同布局和格式的业务文档的扫描图像
文档AI主要是指利用AI技术,以丰富的排版格式从网页、数字文档或扫描文档中自动提取、分类和理解信息。它是自然语言处理(NLP)和计算机视觉(CV)交叉的重要研究领域。深度学习技术的激增极大地推动了文档人工智能的发展,在视觉信息提取和文档布局分析,以及文档视觉问答和文档图像分类等方面都有显著的性能提升。Document AI 在帮助企业节省运营成本、提高员工效率和减少人为错误方面也发挥着重要作用。
从文本到多模态模型:文档 AI 逐渐发展新技能。
Microsoft Research Asia的Document AI系列研究始于2019年。在对深度学习的深入研究中,研究人员希望从公开可用的文档中提取有用的信息,以建立一个可以支持深度学习模型预训练任务的知识库。然而,由于现实世界的文档不包含结构化数据,因此从杂乱的文档中提取结构化文本信息是研究人员必须解决的第一个问题。
为了解决这个问题,Microsoft Research Asia提出了UniLM,这是一种统一的预训练语言模型,可以读取文档并自动生成内容。UniLM模型在自然语言理解和生成任务方面取得了很好的成果。此外,研究人员还为该系统提供了通过开发跨语言预训练模型(InfoXLM)将英语NLP任务扩展到多种语言的功能。在现实世界中,文档不仅包含文本信息,还包含布局和样式信息(例如,字体、颜色和下划线)。因此,仅处理文本信息的模型无法应用于需要多模态程序的实际场景。
2019年底,Microsoft亚洲研究院推出了LayoutLM,这是一个结合了NLP和CV技术的通用预训练文档基础模型。这是第一个可以在文档级预训练的单个框架中同时学习文本和布局信息的模型。LayoutLM 对来自 IIT-CDIP Test Collection 1.0 数据集的大约 1100 万张扫描文档图像进行了预训练。它还可以通过大规模使用未标记的扫描文档图像以自我监督的方式轻松训练,在表单和收据理解以及图像分类任务方面优于其他模型。 在一个名为LayoutLMv2的更新模型中,研究人员随后将视觉信息纳入预训练过程,以提高其图像理解能力。这个新模型成功地将文档文本、布局和视觉信息统一到一个可以学习跨模态交互的端到端框架中。
记录Microsoft亚洲研究院的AI研究进展
此外,研究人员还开发了 LayoutXLM,这是一种基于 LayoutLMv2 的多模态预训练模型,但可以执行多语言文档理解,以满足使用各种语言的不同用户的需求。LayoutXLM 模型不仅集成了来自多语言文档的文本和视觉信息,还利用了它们的局部不变性。LayoutXLM 可以处理近 200 种语言的文档。为了准确评估预训练模型在多语言文档理解方面的性能,研究人员还创建了多语言表单理解基准数据集XFUND,该数据集涵盖七种语言(即中文、日语、西班牙语、法语、意大利语、德语和葡萄牙语)。
与包含扫描文档图像和数字生成的 PDF 文件的固定布局文档不同,许多基于标记语言的文档(如基于 HTML 的网页和基于 XML 的 Office 文档)通常是实时呈现的。出于这个原因,研究人员开发了 MarkupLM 模型来处理基于标记语言的文档的源代码,并在没有额外计算资源的情况下理解它们。实验结果表明,MarkupLM明显优于以往基于固定布局的方法,具有较强的实用性。
Microsoft Research Asia继续迭代Document AI技术,使其能够处理不同类型的数据,包括文本,布局和图像信息。今年,Microsoft Research Asia发布了LayoutLMv3,这是最新的多模态预训练模型,可以实现统一的蒙版文本和图像建模。LayoutLMv3 是第一个通过屏蔽文本和图像的预测来缓解文本和图像多模态表示学习之间的差异的模型。此外,LayoutLMv3 经过预训练以实现词块对齐,这意味着它可以通过预测单词的相应图像块是否被屏蔽来学习跨模态对齐。在模型架构方面,LayoutLMv3 不依赖预训练的 CNN 骨干来提取视觉特征。但是,它直接利用文档图像补丁,从而大大节省了参数,消除了区域注释,并避免了复杂的文档预处理。这些简单统一的架构和训练目标使 LayoutLMv3 成为通用预训练模型,适用于以文本为中心和以图像为中心的文档 AI 任务。
Microsoft Research Asia合伙人研究经理Furu Wei表示:“Layout(X)LM系列模型在我们推动基础模型的’大融合’和跨任务、语言和模态的大规模自监督预训练的基础研究中发挥着至关重要的作用。
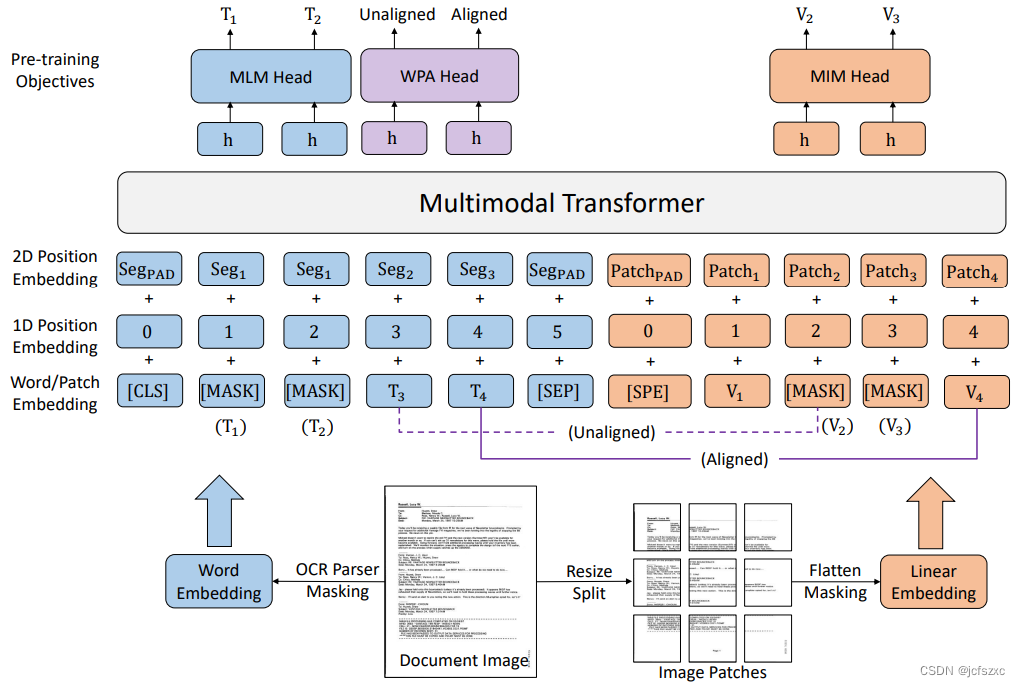
LayoutLMv3 的体系结构和预训练目标
“我们看到了一种不同模式大融合的研究趋势,来自不同领域的科学家正在研究统一模型,包括NLP、CV等。LayoutLM的前两个版本专注于语言处理,而LayoutLMv3的优势在于它可以处理NLP和CV模式的任务,在计算机视觉领域取得了重大突破,“Microsoft亚洲研究院首席研究经理崔磊说。
GitHub 链接: https://github.com/microsoft/unilm
行业领先的型号
Layout(X)LM 系列模型在利用大规模未标记数据以及将文本和图像与多模态、多页面和多语言内容集成方面处于领先地位。特别是 LayoutLMv3 的通用性和优越性,使其成为文档 AI 行业研究的标杆模型。例如,Layout(X)LM 系列模型已被许多领先公司的许多 Document AI 产品采用,尤其是在机器人流程自动化 (RPA) 领域。
“Microsoft Research Asia不仅在建模创新和基准数据集方面取得了显著成果,而且还开发了许多应用程序,允许用户仅使用一个模型架构执行多项任务。学术界和工业界的许多同事都在使用 Layout(X)LM 进行有意义的科学探索并推进文档 AI,“崔磊说。
Microsoft 在该领域处于领先地位,一系列 Microsoft Research Asia 的文档 AI 模型现已用于许多与 Microsoft 相关的产品,例如 Azure 表单识别器、AI Builder 和 Microsoft Syntex。“我们很高兴能与Microsoft亚洲研究院的这些顶尖研究人员合作。文档基础模型大大提高了我们的开发和应用效率,并为文档AI的普及做出了贡献。我们期待未来在这一领域取得更多令人兴奋的进展,“Microsoft Azure AI的合作伙伴工程经理Cha Zhang说。
Document AI 的下一步:开发通用和统一框架
随着时间的推移,文档人工智能的技术进步使其在金融、医疗保健、能源、政府服务和物流等各个行业的应用,为这些行业的人们节省了大量时间,因为他们现在可以避免手动处理。例如,在金融行业,Document AI实现了财务报表分析、智能决策分析、发票和订单的自动化信息提取;在医疗保健行业,它促进了病例数字化,分析了医学文献和病例的相关性,并提出了潜在的治疗方案。
然而,Microsoft Research Asia不会固步自封,崔磊表示。其研究人员正计划在三个方面进一步推进Document AI的基础研究:增加模型规模、扩大训练数据和统一框架。“NLP 中的 GPT-3 表明,大型语言模型可以显着提高性能。当前 Document AI 模型的训练数据不到 Web 规模数据的十分之一,因此仍有改进的余地。在未来的研究中,我们将专注于扩大数据和模型的规模,以实现跨文档AI框架的统一。
版权归原作者 jcfszxc 所有, 如有侵权,请联系我们删除。