
在初步了解了关于爬虫的课程之后,我也进行了一些自己的尝试。本文将从“爬取BiliBili Vtuber区直播信息为切入点,来探讨requests, re等库的基础应用。在爬取信息之后,本文将通过matplotlib以及pandas库做数据分析以及可视化
爬虫部分
确认url
首先,我们先确认任务:打开Bilibili,在直播分区中选择虚拟主播区
我们需要获取主播名称以及观看人数的对应信息。
打开f12,切换到Network界面并使用f5刷新,找到与主播信息对应的网页url。
(当然,首先应该查验一下信息是不是直接保存在网页源代码里,在本例中,已提前确认源代码中的信息不完全)
在一阵找寻之后,我们注意到如下信息:

使用”在新标签页中打开“之后,我们得到如下内容:

在其中,我们寻找代表名称以及观看人数的键值对,通过对比数据可以发现,代表名称的是:
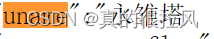
而代表观看人数的是:
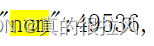
那么接下来,我们需要观察url的规律,其url为:
https://api.live.bilibili.com/xlive/web-interface/v1/second/getList?platform=web&parent_area_id=9&area_id=0&sort_type=sort_type_291&page=1
随着url末尾page的变化,可以对应不同的直播数据,每页实际上存放了20个人的数据,在作者爬取数据时,一共有47页有余。
构造函数
知道了这些之后,我们开始构造函数:
首先是获取html网页的函数:
def getHTMLList(url):
try:
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("ERROR1")
return ""
获取了html网页之后,采用正则表达式的方式匹配键值对:
def parsePage(html, info_list):
try:
name = re.findall(r'\"uname\"\:\".*?\"', html)
audience = re.findall(r'\"num\"\:\d*', html)
for i in range(len(audience)):
name_str = eval(name[i].split(':')[1]) # eval去掉引号,之后split分开只取右边部分
audience_str = eval(audience[i].split(':')[1])
info_list.append([name_str, audience_str])
except:
print("")
最后再把爬取的信息储存在xlsx文件当中:
def printStockList(info_list):
stock_list = pd.DataFrame(info_list, columns=['name', 'audience'])
stock_list.to_excel("Vtuber直播信息.xlsx")
全部代码
'''
爬取bilibili直播数据
'''
import requests
import re
import pandas as pd
kv = {'user-agent': 'Mozilla/5.0'}
def getHTMLList(url):
try:
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print("ERROR1")
return ""
def parsePage(html, info_list):
try:
name = re.findall(r'\"uname\"\:\".*?\"', html)
audience = re.findall(r'\"num\"\:\d*', html)
for i in range(len(audience)):
name_str = eval(name[i].split(':')[1]) # eval去掉引号,之后split分开只取右边部分
audience_str = eval(audience[i].split(':')[1])
info_list.append([name_str, audience_str])
except:
print("")
def printStockList(info_list):
stock_list = pd.DataFrame(info_list, columns=['name', 'audience'])
stock_list.to_excel("Vtuber直播信息.xlsx")
def main():
depth = 48
info_list = []
for i in range(1, depth):
try:
url = "https://api.live.bilibili.com/xlive/web-interface/v1/second/getList?platform=web&parent_area_id=9&area_id=0&sort_type=sort_type_291&page=" + str(i)
html = getHTMLList(url)
parsePage(html, info_list)
print("正在获取第{}页信息".format(i))
except:
continue
printStockList(info_list)
main()
实际上,这个代码只需要简单替换url以及正则表达式便可广泛用于爬取各种数据(当然,对于一些稍有反扒技术的网站,可能就需要对请求头做改变了……)
结果汇总
运行这段代码

之后打开保存的xlsx文件,发现已经保存信息:


图中展示的是一部分信息
后续讨论
实际上到此为止,爬虫的部分已经完成了。接下来,我们需要讨论一下关于爬虫的问题。
访问https://www.bilibili.com/robots.txt查看b站关于爬虫的限制:

发现除了少数浏览器外,b站实际上不允许其他用户进行爬虫。不过在MOOC上的老师说……只要同学们访问的次数/频率没有明显异于人类,乃至于对网站造成负担时,是可以在小范围内进行爬虫的。事实上,python+request库的速度明显较慢,在实际测试中每秒几十个数据也没有显著超过一个人下拉页面所产生的访问量,所以仍然进行了这次爬虫练习。
数据处理部分
接下来打开jupyter notebook,对读取的Excel文件进行一些力所能及的分析与处理
首先是引入需要的库以及配置:
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = ["SimHei"] # 只加这个会导致负号无法显示
plt.rcParams['axes.unicode_minus'] = False # 这两个设置是为了正确显示汉字
然后读入数据:
df = pd.read_excel("Vtuber直播信息.xlsx") # 读入数据,保存为DataFrame格式
df.head() # 查看读入数据(jupyter notebook上的用法……)

可见,数据已经读入了
注意一下……这个数据是某日晚上7点半左右的数据,并不一定具有代表性,仅作练习使用,请不要用这些数据为论据发布攻击性信息,感谢~
接下来,分别统计观众数量的中位数以及平均数:

可见对于每个Vtuber而言,平均有387位观众观看直播,然而关注的中位数却只有34个,即一半的主播观众不到34人。这说明观看人数差距较大,研究观看人数的方差:

也可见方差很大
通过sort_values函数进行排序:

排序之后实际上应该更改一下索引,采取了一种略显丑陋的方法:

之后,我们绘制饼状图,以描述观众的分布,为了方便显示,只选取观众数量前10位的Vtuber进行单独展示,其他人归类到”其他“
vtubers = [df["name"][i] for i in range(1,11)]
vtubers.append("其他")
audience = [int(df["audience"][i]) for i in range(1,11)]
audience.append(df["audience"][12:].sum())
plt.pie(audience, labels=vtubers, autopct='%.2f%%', wedgeprops = {'width':0.5})
plt.style.use("bmh")
plt.tight_layout()
plt.show()
最终得到的饼状图如图所示:
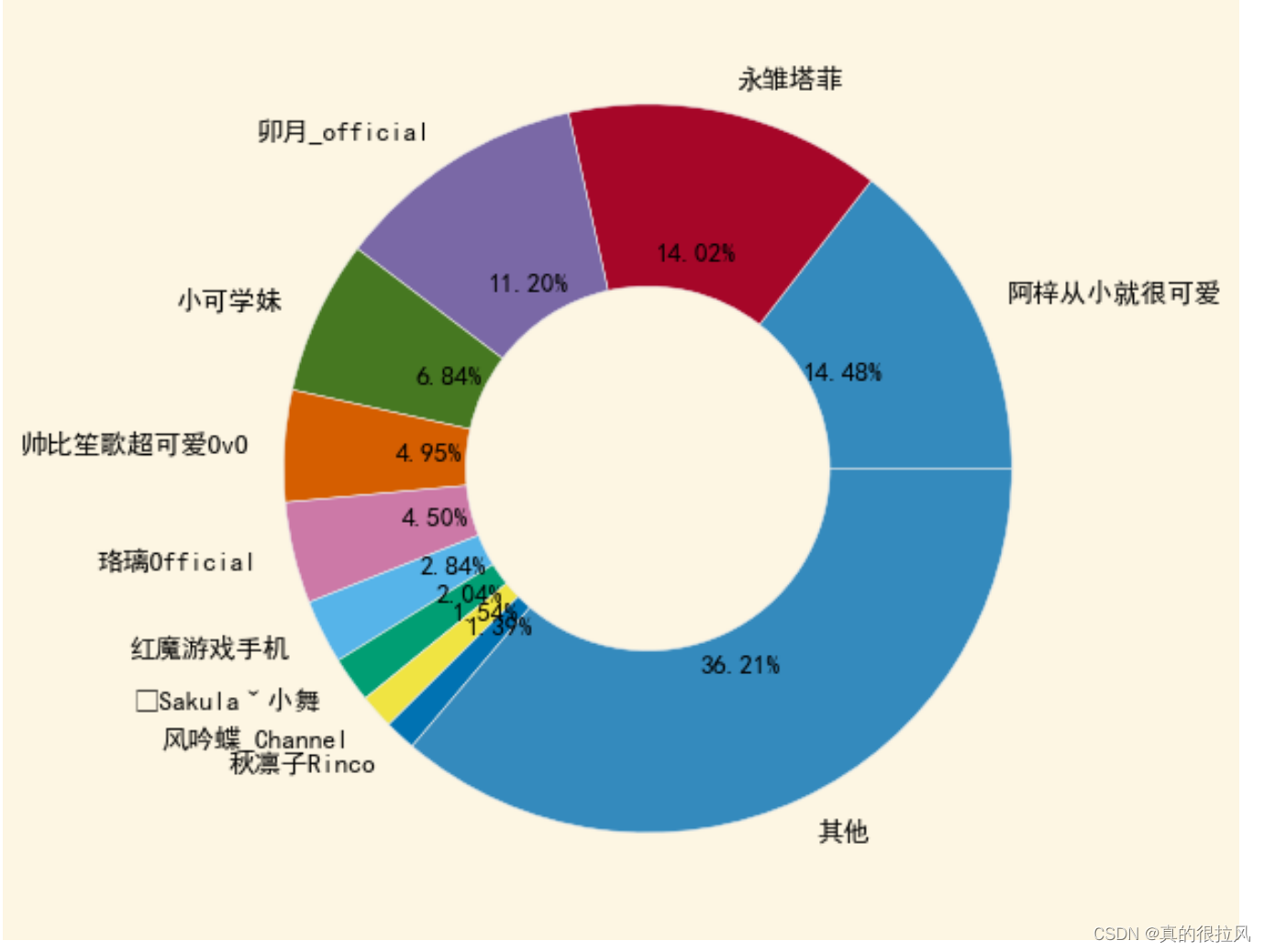
还是有点丑陋……不过也算是完成了
版权归原作者 真的很拉风 所有, 如有侵权,请联系我们删除。