
博主的研究方向为图像分割,想顶会发一篇关于全景分割的论文,语义分割和实例分割是全景分割的必经之路。所以本人先把自己最近阅读的顶会中语义分割相关的优秀论文罗列出来,方便复习巩固,对语义分割方向有一个宏观的掌握。
一、论文综述
图像分割是将一幅图像分成多个子区域的过程,使得每个子区域内的像素具有相似的特征。图像分割是计算机视觉领域中的一个基础问题,被广泛应用于医学影像分析、目标跟踪、自动驾驶等领域。语义分割是图像分割的一种特殊形式,即将图像中的每个像素划分到一组预定义的语义类别中,与物体实例无关。因此,语义分割可以被视为图像分类问题的推广,而不是像素级别的物体检测或实例分割问题。语义分割是许多计算机视觉任务中的基础,如自动驾驶、智能视频监控等领域,因为它能够帮助计算机理解图像中不同区域的语义含义,从而做出更准确的判断和决策。目前,深度学习中使用的卷积神经网络(CNN)和语义分割中的特定结构和算法使得语义分割在许多领域中获得了重大进展。
1.1 经典分割算法
1.1.1 FCN
论文:Fully Convolutional Networks for Semantic Segmentation
FCN是语义分割领域的开山之作 ,由Jonathan Long, Evan Shelhamer和Trevor Darrell于2015年提出,端到端训练为后续语义分割算法的发展铺平了道路。FCN在 PASCAL VOC(2012年的数据,相对之前的方法提升了 20% ,达到62.2% 的平均IoU),NYUDv2 和 SIFT Flow 上实现了最优的分割结果,对于一个典型的图像,推断只需要 1/3 秒的时间。
算法主要的贡献:
- 将传统的全连接层替换为卷积层,使得FCN能够接收任意大小的输入图像,并且在输出中同时保留空间信息和像素级别的预测结果。FCN算法的另一个重要贡献是引入了上采样层,以便将输出大小恢复到输入图像大小。在FCN中,下采样层通过降采样图像大小来获取更高层次的特征,上采样层则通过反卷积将图像大小恢复到原始尺寸,并且在恢复大小的同时,将低分辨率特征与高分辨率特征进行融合,得到像素级别的预测结果。
- FCN算法的另一个重要特点是引入了跳跃式连接(Skip Connections),这种连接方式将卷积层输出与上采样层输入连接起来,从而可以保留更丰富的语义信息,提高了预测的准确性。跳跃式连接还使得FCN算法可以通过不同层次的特征来生成预测结果,从而在细节和语义级别上都可以更好地进行分割。
网络模型图
- FCN-32s:直接将 pool5 的输出,上采样到原图大小,做预测,从图 4 可以看出,预测的结果非常粗糙(mIoU 59.4)
- FCN-16s:将 pool5 上采样 2 倍,和 pool 4 特征进行相加,然后上采样到原图大小,结果会比 32s 的精细一些(mIoU 62.4)
- FCN-8s:将 pool5(上采样2倍)和 pool4 相加后的特征,先上采样 2 倍,然后和 pool3 相加,得到 FCN-8s 特征(mIoU 62.7)
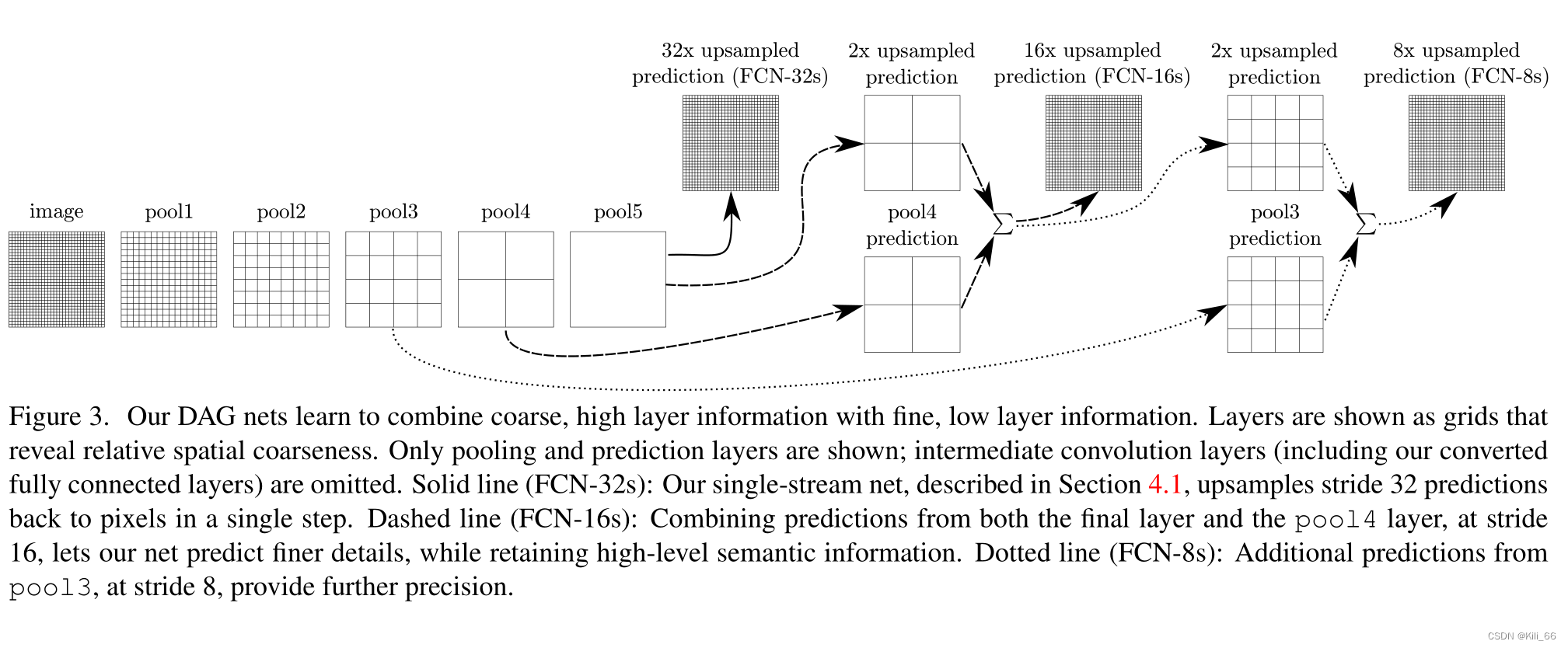
在传统的分类 CNNs 中,池化操作用来增加视野,同时减少特征图的分辨率。对分类任务来说非常有效,分类模型关注图像总体类别,而对其空间位置并不关心。所以才会有频繁的卷积层之后接池化层的结构,保证能提取更多抽象、突出类的特征。另一方面,池化和带步长的卷积对语义分割是不利的,这些操作会带来空间信息的丢失。不同的语义分割模型在码解器中使用了不同机制,但目的都在于恢复在编码器中降低分辨率时丢失的信息。
语义分割架构的另一个重要点是,对特征图使用反卷积,将低分辨率分割图上采样至输入图像分辨率,或者花费大量计算成本,使用空洞卷积在编码器上部分避免分辨率下降。即使在现代 GPUs 上,空洞卷积的计算成本也很高。
1.1.2 U-Net
论文: U-Net: Convolutional Networks for Biomedical Image Segmentation
U-Net 架构包括一个捕获上下文信息的收缩路径和一个支持精确定位的对称扩展路径,这样一个网络可以使用非常少的图像进行端到端的训练。U-Net主要用于医学影像分割,它在ISBI神经元结构分割挑战赛中取得了比之前方法都更好的结果。
训练深度学习网络需要大量的数据,语义分割的难点在于:高分辨率特征和低分辨率特征的结合,也可以看做是低层位置信息和高层语义信息的结合,缺一不可,所以两者如何联合使用是一个很值得研究的问题
- 高分辨率特征能够保证位置信息
- 低分辨率特征能够保证语义信息
本文在 FCN 的基础上,进行了一些修改和优化,能够保证在使用少量数据的基础上产生更准确的分割结果。
FCN 的主要核心:
- 在常规的卷积层后,添加了上采样层,将特征图扩大,并且在扩大的时候使用了前一层的高分辨率特征,引入了更优质的位置信息。
U-Net 的主要改进在于:
- 在上采样部分,也采用了很多的通道,能让更多的上下文信息传递到高分辨率层
- 使用了一些数据增强方法,让网络能够学习更鲁棒的特征
- 使用了加权 loss
U-Net 框架结构:
如图 1 所示,U-Net 和 FCN 结构类似,也分为 encoder 和 decoder 模块,网络结构中只有卷积和池化层,包括两个路径:
- 捕获上下文信息的收缩路径(encoder)
- 实现精确定位的对称扩展路径(decoder)
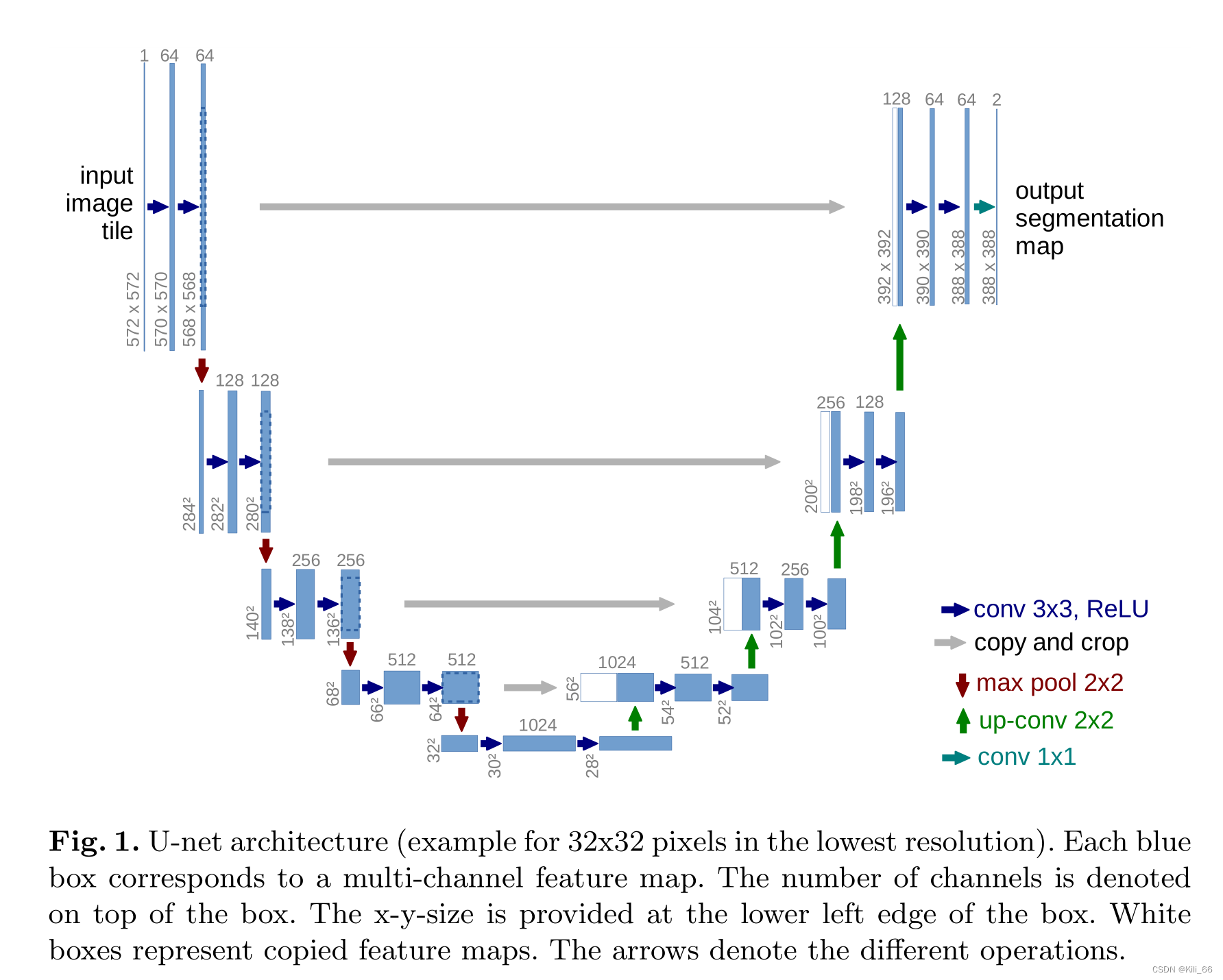
特点:
- U-Net 的上下采样使用了相同数据的卷积操作,且使用了 skip 链接,使得下采样层的特征直接传递到上采样层,保证了 U-Net 更精确的像素定位。
- U-Net 训练效率也高于 FCN ,U-Net 只需要一次训练,而 FCN-8s 需要 3 次训练
1.1.3 SegNet
论文: SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
SegNet 的新颖之处在于解码器对其较低分辨率的输入特征图进行上采样的方式。
- SegNet 在解码器中使用「反池化」对特征图进行上采样,并在分割中保持高频细节的完整性。
- 编码器舍弃掉了全连接层(和 FCN 一样进行卷积),因此是拥有较少参数的轻量级网络。
网络结构:

- Encoder:VGG-16 网络(去掉最后一层分类层),共 13 层卷积层,卷积结构为 Conv+BN+ReLU,下采样使用最大池化来实现(2x2,s=2),但一般会丢失位置信息,逐级增加的损耗(boundary detail)非常不利于语义分割的结果语义分割中边界非常重要,所以,encoder 中尽可能多的保留边界信息非常重要。考虑到内存和效率问题,有一些方法提出保留最大值对应的位置来保留位置信息,所以本文也使用了这种方法。
- Decoder:每个 encoder 都会对应一个 decoder,所以 decoder 也共有 13 层,通过使用 memorized max-pooling 的方式,来上采样。解码的结构如图 3 所示,
- 分类层:最后一层 decoder 的输出会输入 multi-class soft-max 分类器,为每个像素来生成对应的类别预测

这种方法消除了学习上采样的需要。经上采样后的特征图是稀疏的,因此随后使用可训练的卷积核进行卷积操作,生成密集的特征图。SegNet与FCN等语义分割网络比较,结果揭示了在实现良好的分割性能时所涉及的内存与精度之间的权衡。
1.1.4 Deeplab系列
Deeplab v1
论文:Semantic image segmentation with deep convolutional nets and fully connected crfs
DeepLab v1是最早的DeepLab模型,最初在2014年提出。DeepLab v1主要采用了空洞卷积(也称为膨胀卷积)来增加感受野大小,从而可以处理更大的图像。此外,DeepLab v1也将全连接层替换为了膨胀卷积,减少了网络参数量,避免了过拟合的问题,后处理引入了 fully-connected CRF 来定位更精确的分割边界。

DeepLab v2
论文:Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs
DeepLab v2是DeepLab v1的改进版,最初在2015年提出。DeepLab v2主要采用了多尺度信息融合和空间金字塔池化(ASPP)来进一步提高分割的准确率。
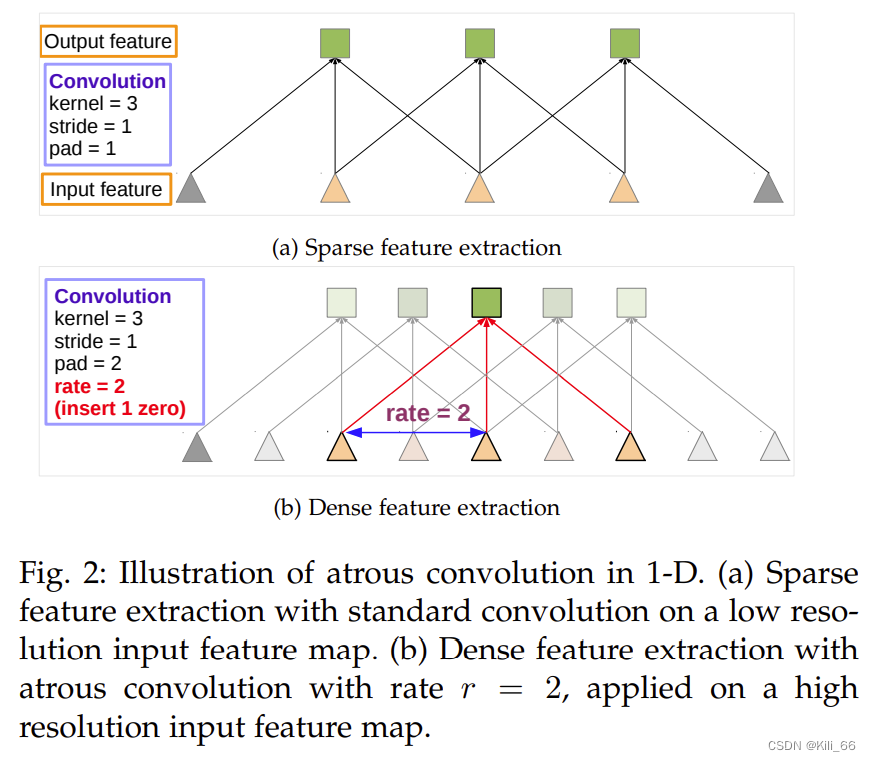
ASPP 框架结构: 4 组并行且使用不同膨胀率的卷积
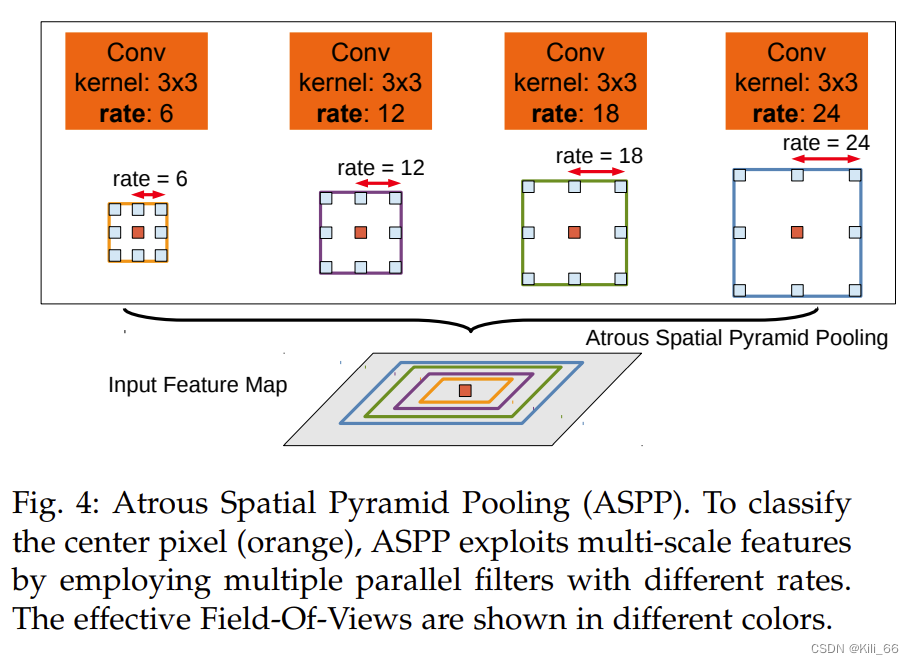
Deeplab v3
论文:Rethinking atrous convolution for semantic image segmentation
DeepLab v3是DeepLab系列中最重要的一个版本,最初在2017年提出。DeepLab v3采用了可变形卷积来更好地适应不同尺度物体的分割任务,同时也对ASPP模块进行了进一步改进,提高特征表达能力。
网络结构:
DeepLab V3包含2种实现结构:分别为 cascaded model 级联型 和 ASPP model 金字塔池化型。
两种模型分别如下的2幅图所示。
- cascaded model 中 Block1,2,3,4 是 ResNet 网络的层结构(V3主干网络采用 ResNet50 或 101),但 Block4 中将 33 卷积和捷径分支 11 卷积步长 Stride 由 2 改为 1,不进行下采样,且将 33 卷积换成膨胀卷积,后面的 Block5,6,7是对 Blockd 的 copy。(图中 rate 不是真正的膨胀系数,真正的膨胀系数 = rateMulti - grid参数)

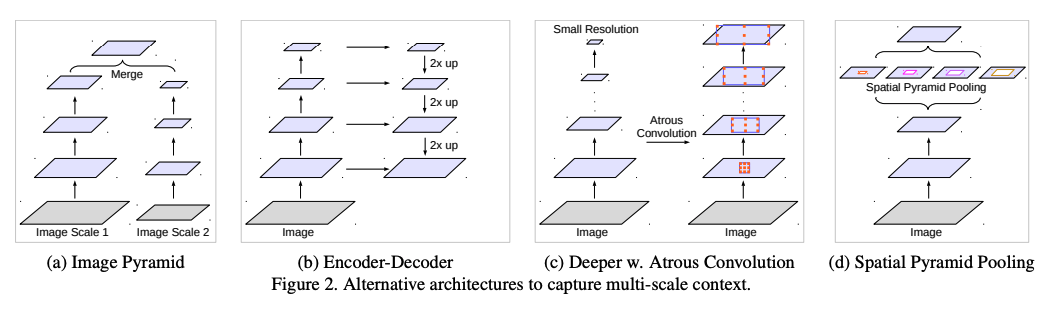
目标大小差别较大,一般的解决方法为如下四种:多尺度融合、encoder-decoder 结构、使用额外的结构来捕捉长距离依赖、空间金字塔池化(多个不同的池化率,捕捉不同尺度的特征)
在 ASPP 中添加了 batch normalization,来加速训练,提升效果
增加了一个并行的全局平均池化,来捕捉全局信息
ASPP 是使用不同的膨胀率来捕捉不同尺度的信息,但是当膨胀率变大的时候,有效的元素就越少,也就是间隔越大,会有很多权重落到特征图外,无法起作用,极端情况就是这个3x3的卷积的效果类似于一个1x1的卷积。因此,作者在最后一层特征图使用全局平均池化捕获全局信息,将该 “image-level” 的特征输入 1x1 卷积中+BN 中,再上采样到需要的大小。

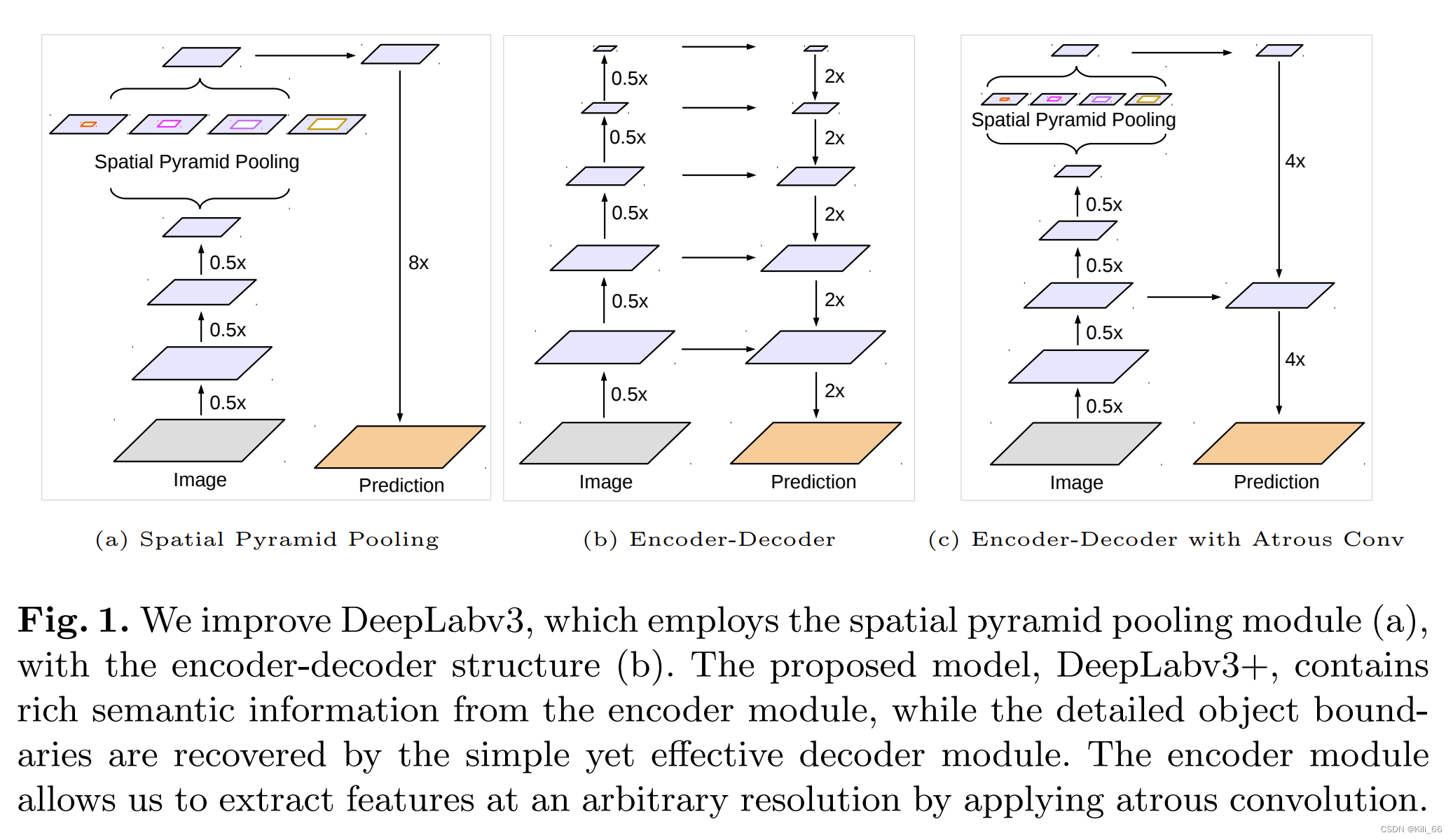
Deeplabv3+
论文:Encoder-decoder with atrous separable convolution for semantic image segmentation
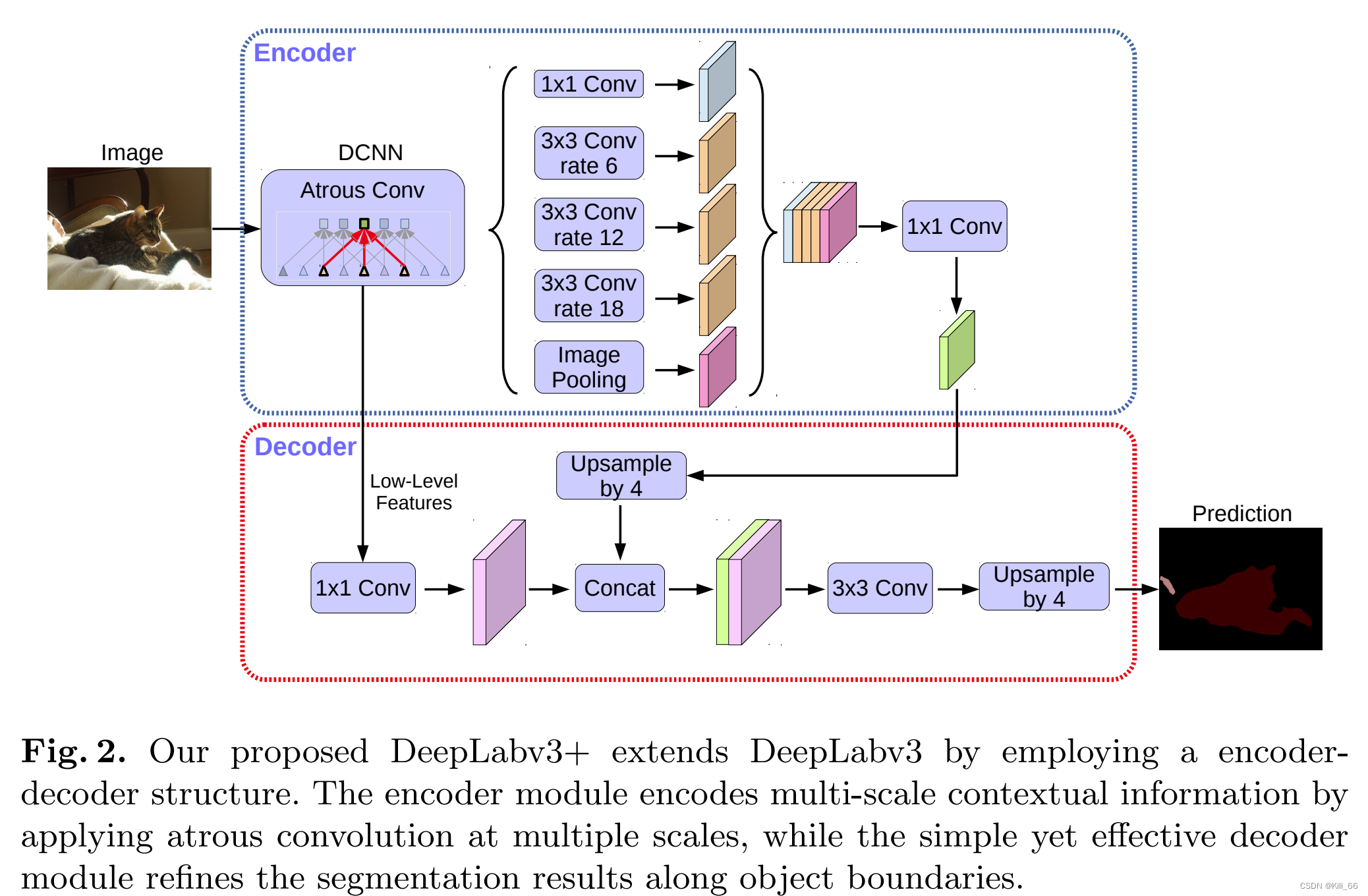
Deeplab v3+引入了一种新的编码器-解码器结构,称为"ASPP with decoder"。其中,ASPP部分类似于Deeplab v3中的ASPP模块,但加入了多个不同空洞率的卷积操作,并在最后一层后加入了一个1x1卷积层,用于降维。解码器部分则是通过反卷积操作将低分辨率的特征图上采样到与原图相同的分辨率,再与ASPP部分输出的高分辨率特征图相结合,最终生成预测结果。
Deeplab v3+相较于Deeplab v3的改进主要有以下几点:
- ASPP with decoder结构:Deeplab v3+引入了ASPP with decoder结构,提高了网络对不同尺度目标的识别能力,同时可以减少最终预测结果的量化误差。
- 基于Xception的backbone:Deeplab v3+使用了基于Xception的backbone,相较于ResNet,Xception有更少的参数和更高的计算效率。
- 多尺度训练与测试:Deeplab v3+在训练和测试阶段均使用了多尺度的方法,可以提高网络的鲁棒性和预测精度。
网络模型:
1.1.5 GCN(全局卷积网络)
论文:Large Kernel Matters —— Improve Semantic Segmentation by Global Convolutional Network GCN(全局卷积网络)是一种用于图像语义分割的深度卷积神经网络。相比于传统的卷积神经网络,GCN将卷积操作从局部感受野扩展到全局图像信息,从而能够更好地保留全局特征,对于一些细小目标的分割效果更好。
语义分割不仅需要图像分割,而且需要对分割目标进行分类。在分割结构中不能使用全连接层,这项研究发现可以使用大维度内核来替代。采用大内核结构的另一个原因是,尽管ResNet等多种深层网络具有很大的感受野,有相关研究发现网络倾向于在一个小得多的区域来获取信息,并提出了有效感受野的概念。大内核结构计算成本高,且具有很多结构参数。因此,k×k卷积可近似成1×k+k×1和k×1+1×k的两种分布组合。这个模块称为全局卷积网络(Global Convolutional Network, GCN)。
接下来谈结构,ResNet(不带空洞卷积)组成了整个结构的编码器部分,同时GCN网络和反卷积层组成了解码器部分。该结构还使用了一种称作边界细化(Boundary Refinement,BR)的简单残差模块。
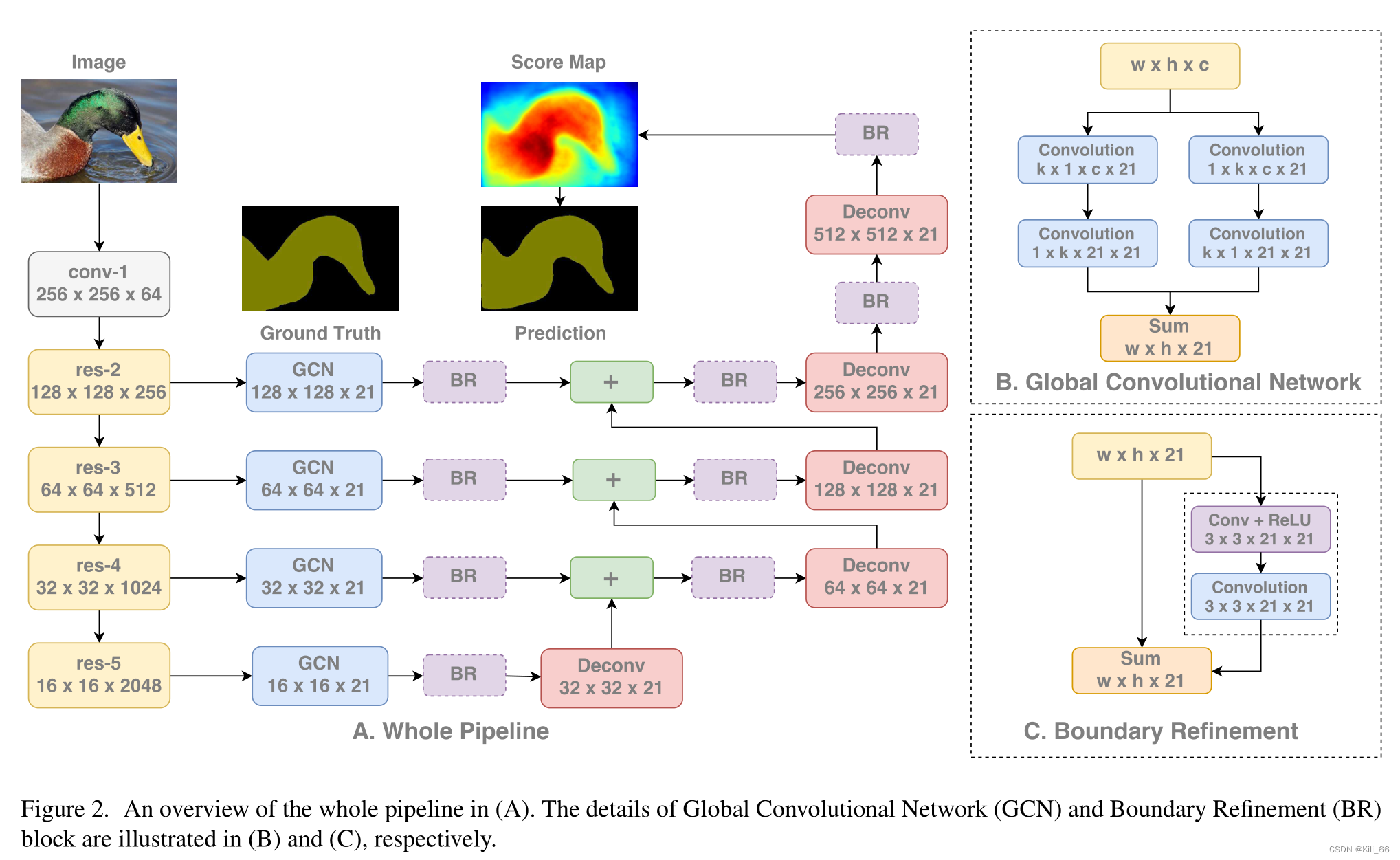
1.1.6 DANet
论文:Dual attention network for scene segmentation
提出了一种新的场景分割模型——双重注意力网络(Dual Attention Network, DAN),旨在有效地捕捉全局上下文信息和物体间的相互关系,以提高场景分割的性能。主要贡献如下:
- 双重注意力机制:DAN模型引入了双重注意力机制,包括物体级别和像素级别的注意力,以捕捉全局和局部信息。物体级别注意力用于筛选重要的物体,而像素级别注意力用于聚焦关注度高的像素。
- 基于注意力的特征增强:DAN模型通过注意力机制来增强特征表示,使得模型更加关注重要的信息。通过注意力机制,DAN可以自适应地调整特征权重,以提高场景分割的准确性。
- 强化了空间信息的传递:DAN模型在卷积过程中引入了注意力机制,使得模型可以聚焦于关键区域,并更好地捕捉全局和局部上下文信息。这进一步强化了空间信息的传递,提高了场景分割的性能。
为了同时捕捉空间和通道的相关性,DANet 使用并行的方法,在通道和空间同时使用了 non-local 模块。
- position attention:也是空间 attention,可以得到每个像素和其他像素的关系,关系越近,权重越大
- channel attention:也是类别 attention,可以得到每个通道的权重,通道越重要,权重越大

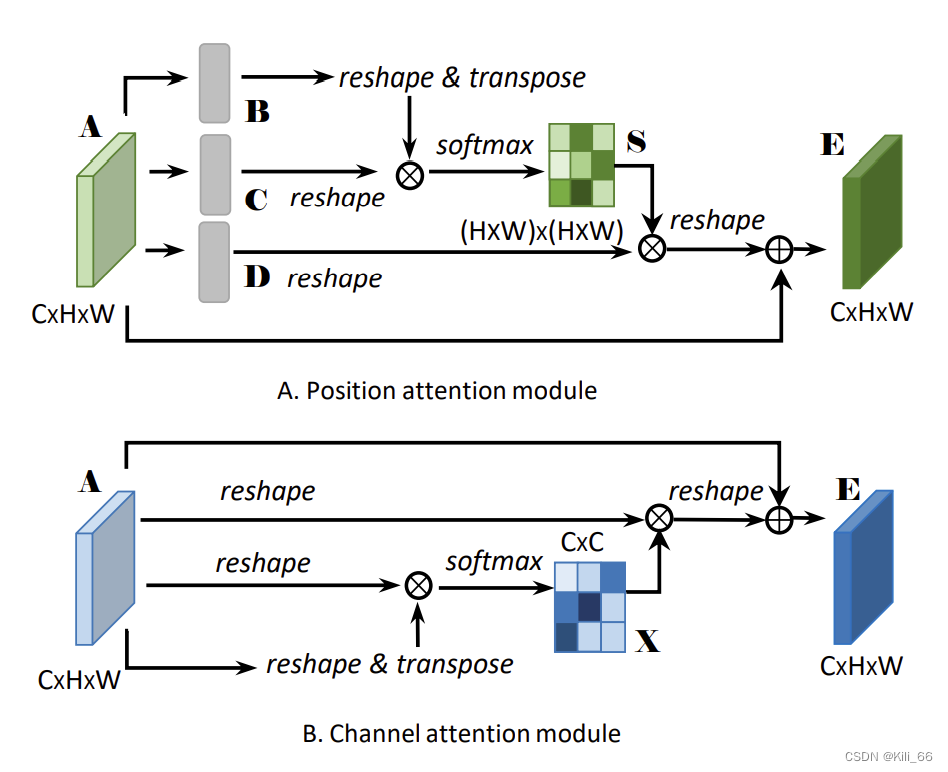 1.1.7 Swin Transformer
1.1.7 Swin Transformer
论文:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》是一篇由香港中文大学、清华大学和Horizon Robotics Inc.联合发表在2021年CVPR上的论文。这篇论文提出了一种新的Vision Transformer架构,即Swin Transformer,通过采用一种称为shifted window的机制来解决现有Vision Transformer架构中的两个主要问题:1.高分辨率图像的高计算成本;2.长序列的计算成本。
Swin Transformer通过将输入图像划分成多个小块,然后对这些小块进行计算,以减少计算成本。然而,与常规的划分方式不同,Swin Transformer使用了shifted window的机制,即在相邻的两个小块之间有一定的重叠区域。这种机制使得模型可以更好地利用空间上的局部信息,提高了模型的准确性。
Swin Transformer在COCO2017物体检测、实例分割和语义分割数据集上进行了评估,并与现有的Transformer架构进行了比较。实验结果表明,Swin Transformer在保持相同计算成本的情况下,可以获得更好的性能,且在计算成本相同的情况下,可以获得更高的性能。此外,Swin Transformer还可以通过横向和纵向的可扩展性进行进一步扩展,适应不同大小的图像。
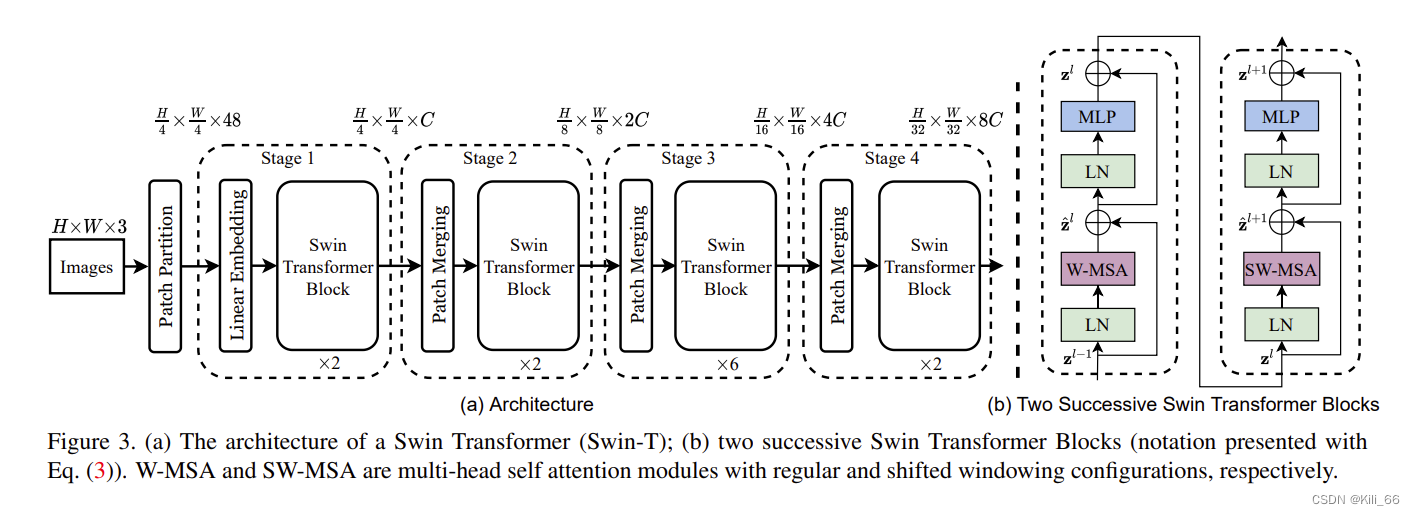
1.2 实时分割算法
1.2.1 ENet
论文:ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
实时执行像素级语义分割的能力在移动应用程序中至关重要。最近的DCNN网络的缺点在于需
要大量浮点运算,运行时间长,阻碍了语义分割的可用性。ENet是实时语义分割最早的文章之一,在准确度和计算时间上做到了权衡。
一些轻量化语义分割模型的设计思路
- 减少上、下采样的次数(FCN中下采样到1/32,而ENet中只到1/4),因为频繁下采样会导致信息缺失。
- 使用轻量化的Decoder(本文就是使用了segnet的decoder),而不是UNet的对称结构。
- 实验发现,去掉前面几个conv的relu效果会变好,测试后认为原因是网络深度不够。所以使用prelu替换relu。
- 使用分解卷积(55 -> 15+51,分解后计算量大概相当于33)
- 使用空洞卷积,提高感受野,效果很好。
- 正则化,即dropout。
- 下采样很必要,但会丢失信息。为了减少信息丢失,下采样是分别进行conv和max pooling,然后对两者结果concat,保留更多信息。
- 网络结构如下图
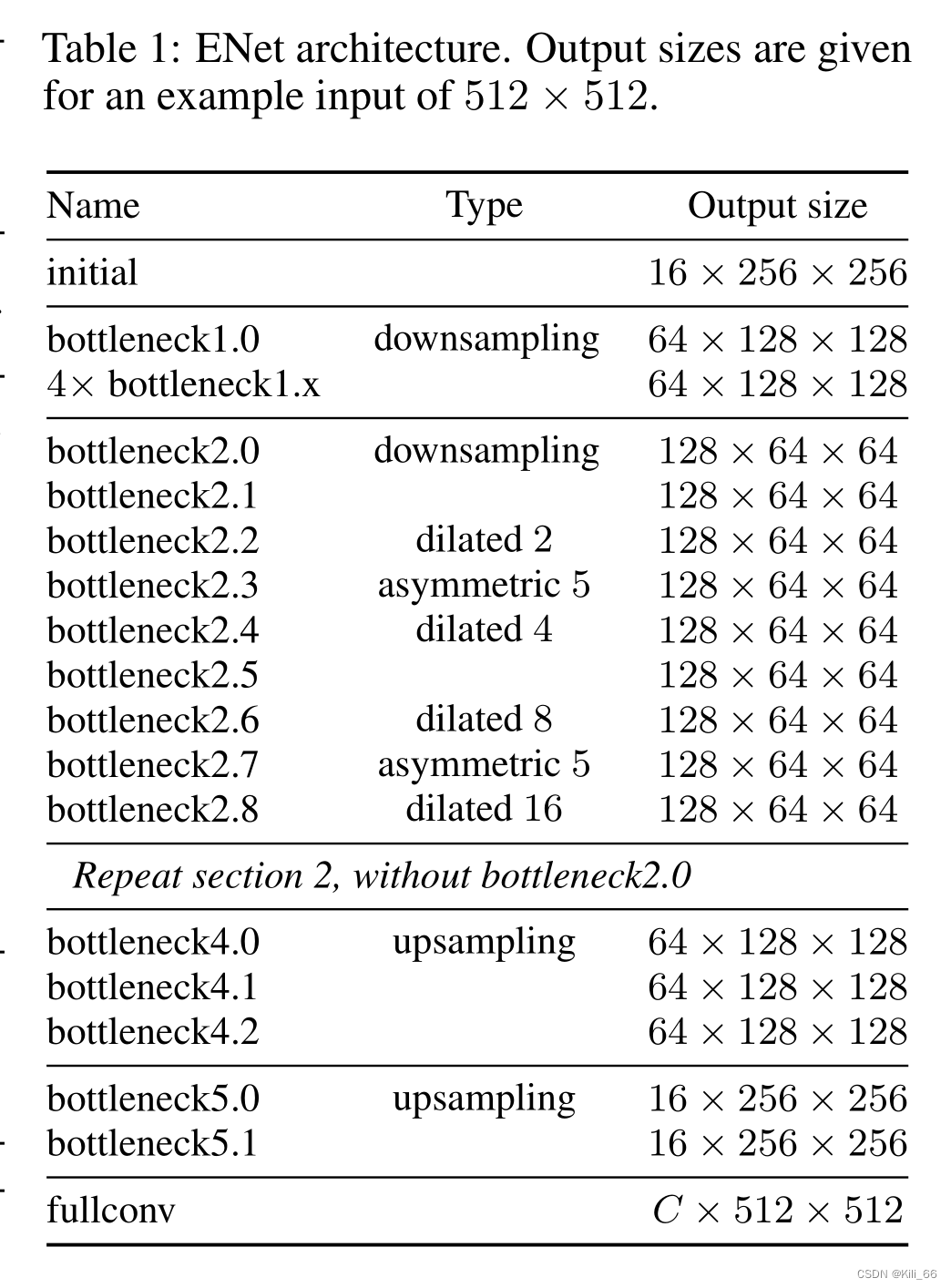
- 在conv(可能是普通卷积、空洞卷积、转置卷积)后添加bn和prelu。
- 下表就是整体结构,可以看到下采样只下采样2次。

1.2.2 BiSeNet
论文:BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation
本文对之前的实时性语义分割算法进行了总结,发现当前主要有三种加速方法:
- 通过剪裁或 resize 来限定输入大小,以降低计算复杂度。尽管这种方法简单而有效,空间细节的损失还是让预测打了折扣,尤其是边界部分,导致度量和可视化的精度下降;
- 通过减少网络通道数量加快处理速度,尤其是在骨干模型的早期阶段,但是这会弱化空间信息。
- 为追求极其紧凑的框架而丢弃模型的最后阶段(比如ENet)。该方法的缺点也很明显:由于 ENet 抛弃了最后阶段的下采样,模型的感受野不足以涵盖大物体,导致判别能力较差。
这些提速的方法会丢失很多 Spatial Details 或者牺牲 Spatial Capacity,从而导致精度大幅下降。为了弥补空间信息的丢失,有些算法会采用 U-shape 的方式恢复空间信息。但是,U-shape 会降低速度,同时很多丢失的信息并不能简单地通过融合浅层特征来恢复。

总结而言,实时性语义分割算法中,加速的同时也需要重视空间信息。论文中提出了一种新的双向分割网络BiSeNet。首先,设计了一个带有小步长的空间路径来保留空间位置信息生成高分辨率的特征图;同时设计了一个带有快速下采样率的语义路径来获取客观的感受野。在这两个模块之上引入一个新的特征融合模块将二者的特征图进行融合,实现速度和精度的平衡。
具体来说,空间路径Spatial Path使用较多的 Channel、较浅的网络来保留丰富的空间信息生成高分辨率特征;上下文路径Context Path使用较少的 Channel、较深的网络快速 downsample来获取充足的 Context。基于这两路网络的输出,文中还设计了一个Feature Fusion Module(FFM)来融合两种特征。
 1.2.3 DFANet
1.2.3 DFANet
论文:DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation
DFANet是旷视发布于2019年4月份的一个针对于道路场景理解的语义分割网络,该网络的backbone采用的是轻量级的Xception网络,然后分别通过sub-network和sub-stage来进行级联聚合特征信息。
该网络模型的设计出发点是为了更好的更充分的利用下采样过程中各个特征图的信息,文中利用两种策略来实现不同特征图的信息聚合,第一个是将backbone采集的不同尺寸的特征信息来进行重复使用,进行语义层和空间层的信息融合(对应的sub-network)。第二个是在网络结构的过程路径中,通过不同的阶段的特征组合来提升网络特征的表现能力(对应sub-stage)。
网络结构

从图1也可以看出,sub-network的重点是将前一个backbone的高层特征图上采样到下一个backbone的输入,以精修预测结果。sub-network也可以看作是一个将像素预测从粗略到精细的过程。sub-stage则是在相应的阶段中的“粗略”到“精细”部分进行不同特征之间的组合。这样可以通过组合相同维度的不同特征图来传递感受野和高维度的结构细节。网络结构中的fc attention模块是参考SENet的设计理念,通过逐通道的选择特征图比例来提高网络的表现能力。因此,为了更好地提取语义信息和类别信息,FC attention中的全连接层在ImageNet上预训练得到。( 在分类任务中,网络的最后一般都是Global Pooling + FC,得到一个类别概率向量。)FC后接一个1 x 1的卷积,匹配每个backbone输出特征图的channel维度。
文中指出了轻量化模型中多支路输入网络的不足之处:1.多支路输入网络缺少了不同支路之间对于高层特征的组合;2不同的支路之间也缺少了信息的交互;3.对于高分辨率的输入图片来说限制了网络的推理速度提升。
1.3 RGB-D分割
1.3.1 RedNet
论文:RedNet: Residual Encoder-Decoder Network for indoor RGB-D Semantic Segmentation
这是一篇2018年的文章,之所以看它一是因为他的整体架构可以作为RGB-D的基础框架,比较通用,另一方面是因为在上一篇文章中提到的,恢复边界比较好。放在2018的背景下,resnet已经提出,RedNet在encoder和decoder使用了残差块作为building block。作者同时提出了多尺度深监督,在现在的许多文章都用到了。最终在SUN RGB-D上取得47.8%的成绩。
FCN分为两个种类,一类是encoder-decoder结构一类是膨胀卷积,编码解码结构通过不断的卷积来扩大感受野,但是图像的尺寸慢慢变小,下采样的丢失信息在decoder时很难恢复出来,膨胀卷积通过增大膨胀率来扩大感受野,但是图像的尺寸不变会导致计算量非常大。
RedNet使用resnet34来作为rgb和depth的backbone,并且每一个layer都会进行融合,并且使用跳连接结构传递encoder的空间信息到decoder。
模型结构
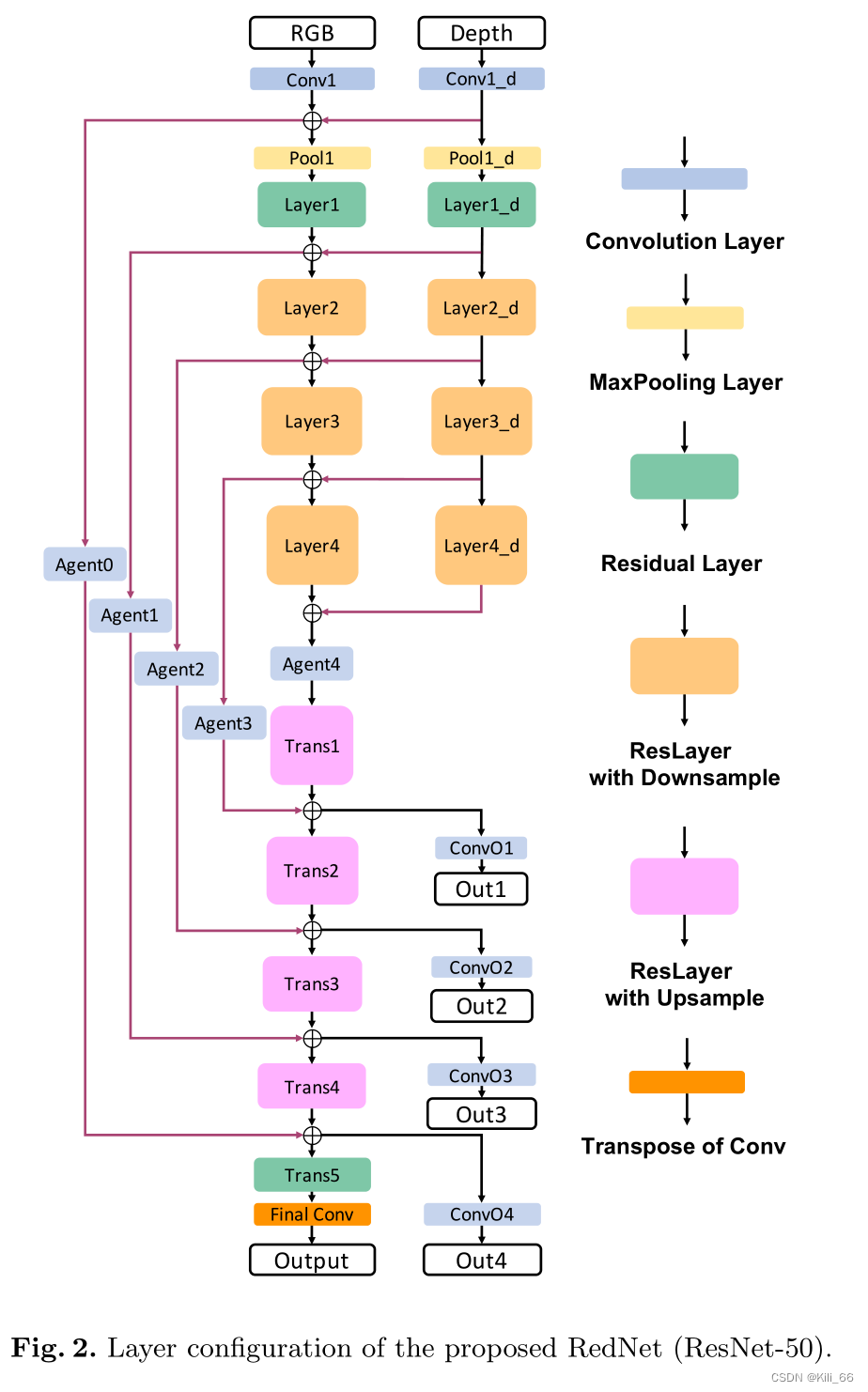
需要注意的点就是trans即模型decoder的上采样操作:
 框架中的跳连接还有四个Agent block,其实就是四个普通的1x1卷积,目的是降低encoder通道大小,为了使encoder通道可以和decoder进行融合。且只在resnet50使用,resnet34不使用,因为resnet的encoder没有维度的扩张。
框架中的跳连接还有四个Agent block,其实就是四个普通的1x1卷积,目的是降低encoder通道大小,为了使encoder通道可以和decoder进行融合。且只在resnet50使用,resnet34不使用,因为resnet的encoder没有维度的扩张。
在encoder中,每一个残差块在第一个模块进行下采样,后面跟着几个卷积,同时在旁边会有一个残差连接,下采样操作,这些在原始的resnet中很清楚,而转置上采样是开始卷积不会影响大小,到最后一个卷积时再上采样,图像的大小扩大两倍,通道减小两倍,旁边的跳连接也是这样操作。
具体的配置: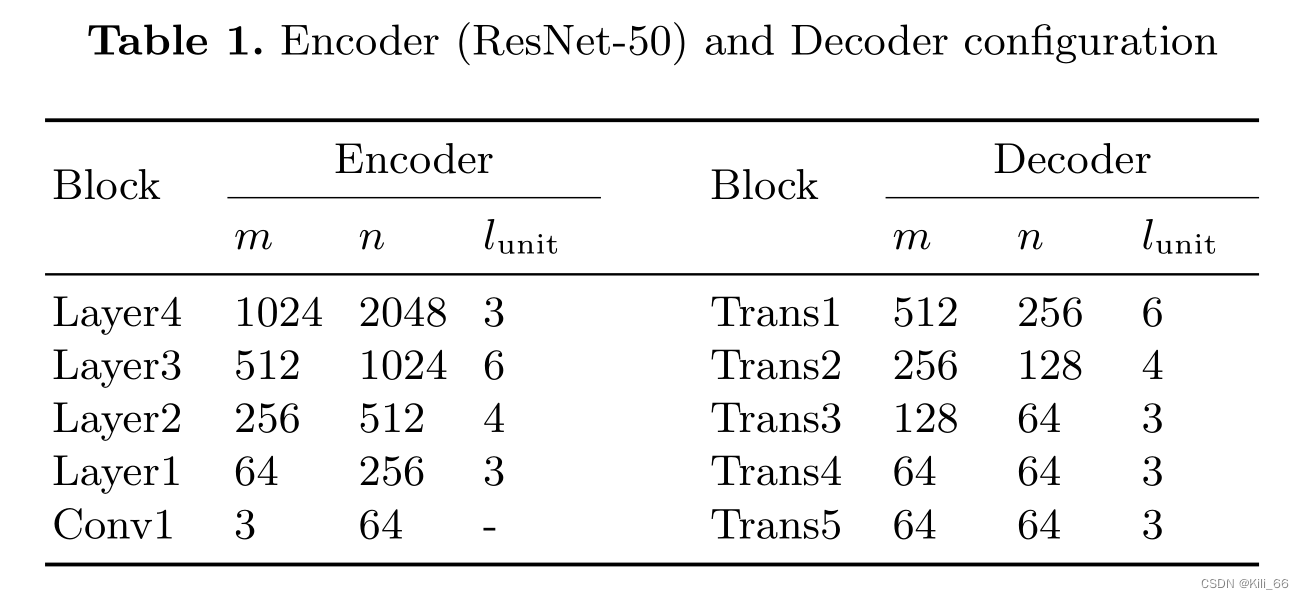
1.3.2 RDFNet
论文:RDFNet: RGB-D Multi-level Residual Feature Fusion for Indoor Semantic Segmentation
在使用RGB-D数据的多级室内语义分割中,已经表明将深度特征结合到RGB特征中有助于提高分割精度。然而,先前的研究尚未充分利用多模态特征融合的潜力,只是简单地连接RGB和深度特征或平均RGB和深度分数图。这篇论文提出了一种新的网络,将残差学习的核心思想扩展到RGB-D语义分割。此网络通过包含多模态特征融合模块和多级特征细化模块,能够有效地捕获多级RGB-D CNN特征。主要使用了NYUDv2和SUN RGB-D这两个RGB-D数据集。
RefineNet的网络的出现,对RGB-D图的语义分割是里程碑式的。RefineNet利用跳过连接的残差学习,可以在训练过程中轻松地反向传播梯度。 RefineNet中的多级功能通过短距离和长距离残差值连接进行连接,因此可以进行有效训练并合并到高分辨率特征图中。受到这项工作的启发,本篇论文提出了一种新颖的RGB-D融合网络(RDFNet),它将残差学习的核心思想扩展到RGB-D语义分割。网络结构组成如下图(图一):
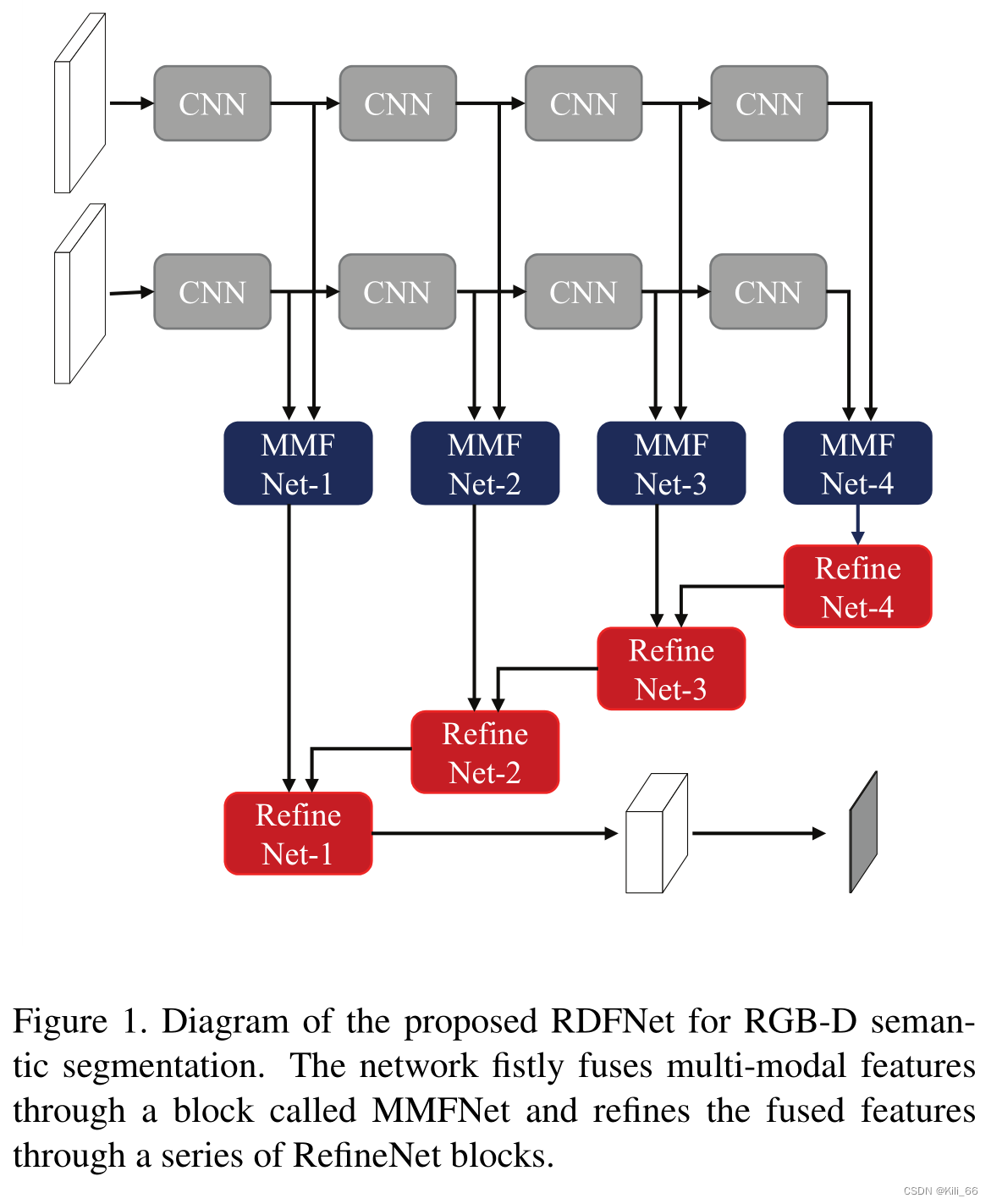
本论文的MMFNet的详细组件Figure5所示。本论文的特征融合块包含与RefineNet中相同的组件,但具有不同的输入,所需的操作略有不同。鉴于RGB和深度ResNet功能,作者的MMFNet首先通过一个卷积减少每个特征的尺寸,以促进有效的训练,同时减少参数的爆炸。然后,每个功能都通过两个RCU和一个卷积,如在RefineNet中。 MMFNet中的RCU与RefineNet中的RCU的目的存在一定的差异。作者的MMFNet中的RCU需要执行一些专门用于模态融合的非线性变换。不同模态中的两个特征互补组合以通过操作相互改进,其中RefineNet中的特征主要是通过采用具有更高分辨率的更低级别特征来改进粗略的更高级别特征。 MMFNet中的后续附加卷积对于以不同模态自适应地融合特征以及适当地重新缩放特征值以进行求和是至关重要的。由于颜色特征通常具有比用于语义分割的深度特征更好的辨别力,因此块中的求和融合主要用于学习补充或残留深度特征,其可以改善RGB特征以区分混淆模式。每个模态特征的重要性可以通过RCU之后的卷积中的可学习参数来控制。

1.4 拓展阅读
以上论文是顶会收录的语义分割方向的经典论文,适合图像分割方向的初学者,通过这些论文阅读,复现源码,可以夯实基础。当有了一定的知识储备和经验积累后,就可以继续深入钻研近两年比较热门,新颖或者有挑战性的方向。期间需要大量阅读文献,以下是获取文献的一些途径:
- 谷歌学术:https://scholar.google.com/。 谷歌学术支持关键词检索,还支持各种筛选,提供pdf下载也提供引用生成。你不会翻墙?没关系,国内有不少谷歌学术的镜像,如https://scholar.glgoo.org/等。
- 百度学术:http://xueshu.baidu.com/。百度学术功能类似于谷歌学术,对中国人友好,还有贴心的各种引用分析,以及文献求助功能,但是文献收录略逊一筹。
- dblp: computer science bibliography
- CVF Open Access
- The latest in Machine Learning | Papers With Code
- SCI-Hub. https://sci-hub.tw/。文献下载神器,支持关键词检索,DOI检索等。最关键的是不少两大学术下载不到的文献可以在这里免费获取。
- arXiv. 有的文章由于版权问题下载不到,我们可以下载它的预印本。当然arXiv只是个提交论文预印本(preprint)的平台,而且里面的论文都没有经过同行评审(peer review),所以文章质量参差不齐,不要把里面所有的文章都当做权威。
- ACM、IEEE、Springer、Elsevier等的官网
二、常见数据集
2.1 PASCAL Visual Object Classes(VOC)
VOC数据集是计算机视觉主流数据集之一,可以作分类,分割,目标检测,动作检测和人物定位五类任务数据集,其中包含21个类及其标签:车辆,房屋,动物、飞机、自行车、船、公交车、小汽车、摩托车、火车、瓶子、椅子、餐桌、盆栽植物、沙发、电视、鸟、猫、牛、狗、马、羊和人。整个数据集分成两个部分,训练集和验证集。
https://pan.baidu.com/s/1TdoXJP99RPspJrmJnSjlYg#list/path=%2F 提取码:jz27
2.2 PASCAL Context
PASCAL Context是VOC 2010的拓展,带有所有训练图像的像素级标签。它包含超过400中类别。因为里面有一些类别的数据集比较稀少,故常用其中59个类别的数据集用于训练网络。
具体的操作详见:https://blog.csdn.net/qq_28869927/article/details/93379892
2.3 Microsoft Common Objects in Context (MS COCO)
MS COCO是另一个大规模物体检测,分割及文字定位数据集。该数据集包含众多类别,以及大量的标签。
链接:https://blog.csdn.net/qq_41185868/article/details/82939959
2.4 Cityscapes
Cityscapes是另一个大规模数据集,其关注于城市街景的语义理解。它包含了一组来自50个城市的街景的不同的立体视频序列,有5k帧的高质量像素级标注,还有一组20k的弱标注帧。它包括30个类别的语义和密集像素标注,分为8个类别:平面、人、车辆、建筑、物体、自然、天空和虚空。
链接:https://blog.csdn.net/zz2230633069/article/details/84591532
2.5 ADE20K/MIT Scene Parsing(SceneParse150)
ADE20K/MIT Scene Parsing(SceneParse150)为场景分割算法提供了标准的训练和评估平台。数据来自于ADE20K,其包含25000多张图片。
链接:http://groups.csail.mit.edu/vision/datasets/ADE20K/
2.6 SiftFlow
SiftFlow包含2688张用LabelMe标注的数据集。一共有33个用于语义分割的类别,其中分辨率为256*256的图片包含8种不同的户外场景。
链接:http://people.csail.mit.edu/celiu/SIFTflow/
2.7 Stanford background
该数据集包含从现有公共数据集中选择的715个图像,包含标签种类:天空,树,道路,草,水,建筑物,山脉和前景物体。
链接:http://dags.stanford.edu/projects/scenedataset.html
2.8 Berkeley Segmentation Dataset(BSD)
BSD数据集由彩色图和灰度图组成,共300张(现在增加到500张)。被分成两个部分,其中200张是训练集,100张是测试集。
链接:https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/segbench/
2.9 Youtube-Objects
这个数据集来自于YouTube网站上的视频数据。数据集的图片像素为480*360,共计10167张图片。
链接:https://data.vision.ee.ethz.ch/cvl/youtube-objects/
2.10 KITTI
KITTI主要用于机器人和自动驾驶,其中包含很多视频。由车辆传感器采集,一开始并不是做语义分割的,后来经过众人努力,其标记图片众多,可用于语义分割。
链接:https://blog.csdn.net/Solomon1558/article/details/70173223
三、评价指标
3.1 混淆矩阵(Confusion Matrix)
混淆矩阵(confusion matrix)也叫错误矩阵(error matrix),混淆矩阵是以模型预测的类别数量统计信息为横轴,真实标签的数量统计信息为纵轴画出的矩阵,
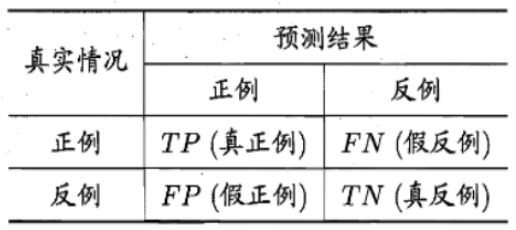
如上图所示,它表示统计分类模型的分类结果。对角线代表了模型预测和数据标签一致的数目,所以准确率也可以用混淆矩阵对角线之和除以测试集图片数量来计算。对角线上的数字越大越好,代表模型在该类的预测结果更好。其他地方是预测错误的地方,值越小说明模型预测的更好。
图像分割中的评价指标标准通常是像素精度及IoU的变种。为便于解释,假设如下:共有k+1个类(从L0到Lk,其中包含一个空类或背景),Pij表示本属于类i但被预测为类j的像素数量。即Pii表示真正的数量,而Pij和Pji则分别被解释为假正和假负。并且下面以一个图示的方法来展示在分割图中TP/TN/FP/FN等概念。
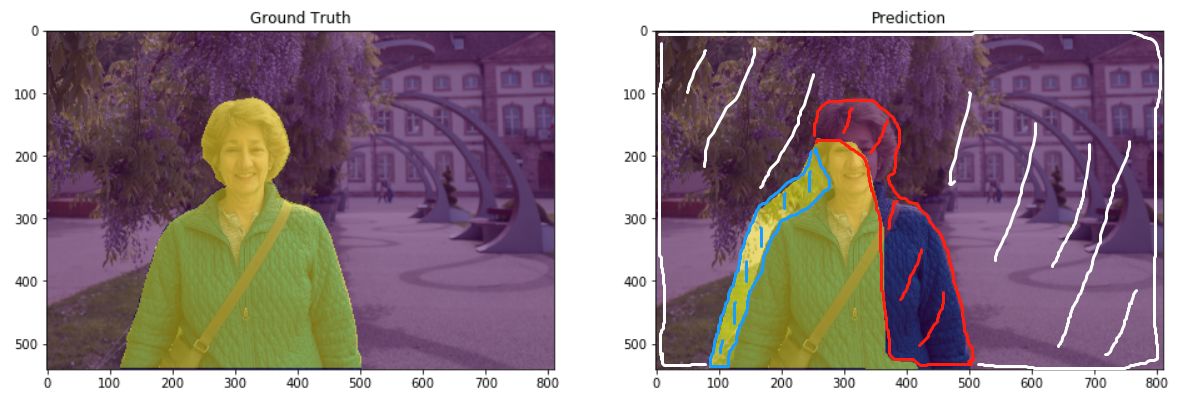
在上图中,左侧是GroundTruth,右侧是Prediction,即预测的掩码图。Prediction图被分成四个部分,其中大块的白色斜线标记的是true negative(TN,预测中真实的背景部分),红色线部分标记是false negative(FN,预测中被预测为背景,但实际上并不是背景的部分),蓝色的斜线是false positive(FP,预测中分割为某标签的部分,但是实际上并不是该标签所属的部分),中间荧光黄色块就是true positive(TP,预测的某标签部分,符合真值)。
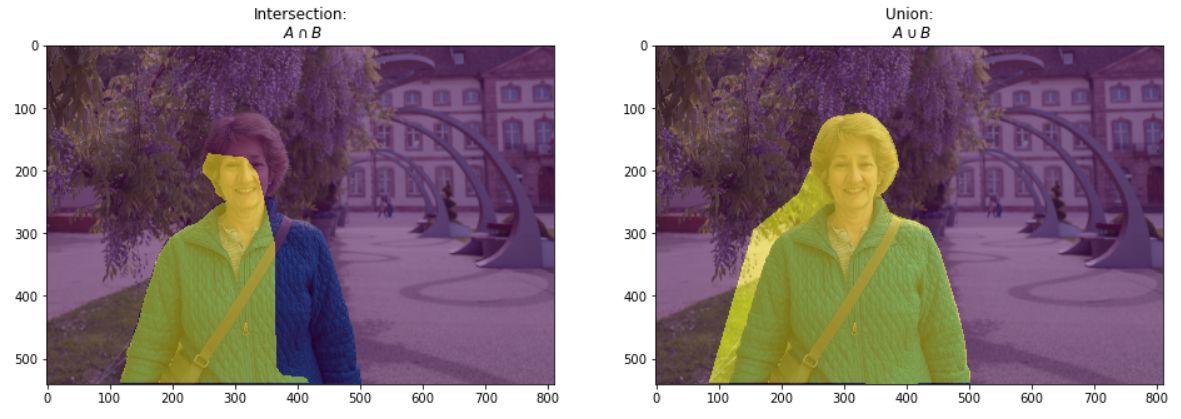
在上图中,左侧是GT,右侧是Prediction,即预测的掩码图。左侧是预测掩码图和真值掩码图的交集,右侧是预测掩码图和真值掩码图的并集。
3.2 像素准确率(Pixel Accuracy,PA)
像素准确率的含义是预测类别正确的像素数占总像素数的比例。它对应上述的准确率(Accuracy),计算公式如下:
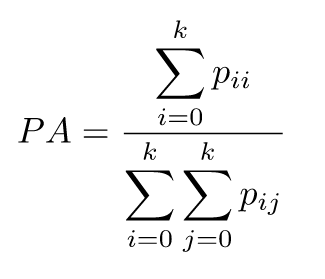
也可以做如下简化理解,它对应上述提及的准确率的计算公式:对角线元素之和 / 矩阵所有元素之和。

3.3 类别平均像素准确率(Mean Pixel Accuracy,MPA)
类别平均像素准确率(mean pixel accuracy)简称MPA,它表示的意义是分别计算每个类被正确分类像素数的比例,然后累加求平均。

3.4 交并比(Intersection over Union,IoU)
交并比表示的含义是模型对某一类别预测结果和真实值的交集与并集的比值。只不过对于目标检测而言是检测框和真实框之间的交并比,而对于图像分割而言是计算预测掩码和真实掩码之间的交并比。

计算公式:以计算二分类正例(类别1)的IoU为例。
交集为TP,并集为TP、FP、FN之和,那么IoU的计算公式如下。
IoU = TP / (TP + FP + FN)
3.5 平均交并比(Mean Intersection over Union,MIoU)
平均交并比(mean IOU)简称mIOU,即预测区域和实际区域交集除以预测区域和实际区域的并集,这样计算得到的是单个类别下的IoU,然后重复此算法计算其它类别的IoU,再计算它们的平均数即可。
它表示的含义是模型对每一类预测的结果和真实值的交集与并集的比值,之后求和再计算平均。

3.6 频权交并比(Frequency Weighted Intersection over Union)FWIoU
频权交并比FWIoU是MIoU的一种提升,这种方法根据每个类出现的频率为其设置权重。

在上述提及到的所有的度量标准中,MIoU由于其简洁、代表性强而成为最常用的度量标准,大多数研究人员都使用该标准报告其结果。
四、损失函数
4.1 Log loss
交叉熵,二分类交叉熵的公式如下:

pytorch代码实现:
#二值交叉熵,这里输入要经过sigmoid处理
import torch
import torch.nn as nn
import torch.nn.functional as F
nn.BCELoss(F.sigmoid(input), target)
#多分类交叉熵, 用这个 loss 前面不需要加 Softmax 层
nn.CrossEntropyLoss(input, target)
4.2 Dice loss
Dice loss是针对前景比例太小的问题提出的,dice系数源于二分类,本质上是衡量两个样本的重叠部分。公式如下:

Dice Loss = 1 - DSC,pytorch代码实现:
import torch
import torch.nn as nn
class DiceLoss(nn.Module):
def __init__(self):
super(DiceLoss, self).__init__()
def forward(self, input, target):
N = target.size(0)
smooth = 1
input_flat = input.view(N, -1)
target_flat = target.view(N, -1)
intersection = input_flat * target_flat
loss = 2 * (intersection.sum(1) + smooth) / (input_flat.sum(1) + target_flat.sum(1) + smooth)
loss = 1 - loss.sum() / N
return loss
class MulticlassDiceLoss(nn.Module):
"""
requires one hot encoded target. Applies DiceLoss on each class iteratively.
requires input.shape[0:1] and target.shape[0:1] to be (N, C) where N is
batch size and C is number of classes
"""
def __init__(self):
super(MulticlassDiceLoss, self).__init__()
def forward(self, input, target, weights=None):
C = target.shape[1]
# if weights is None:
# weights = torch.ones(C) #uniform weights for all classes
dice = DiceLoss()
totalLoss = 0
for i in range(C):
diceLoss = dice(input[:,i], target[:,i])
if weights is not None:
diceLoss *= weights[i]
totalLoss += diceLoss
return totalLoss
4.3 IOU loss
IOU loss和Dice loss有点类似,IOU表示如下:

Soft_IOU_loss pytorch代码实现:
#针对多分类问题,二分类问题更简单一点。
import torch
import torch.nn as nn
import torch.nn.functional as F
class SoftIoULoss(nn.Module):
def __init__(self, n_classes):
super(SoftIoULoss, self).__init__()
self.n_classes = n_classes
@staticmethod
def to_one_hot(tensor, n_classes):
n, h, w = tensor.size()
one_hot = torch.zeros(n, n_classes, h, w).scatter_(1, tensor.view(n, 1, h, w), 1)
return one_hot
def forward(self, input, target):
# logit => N x Classes x H x W
# target => N x H x W
N = len(input)
pred = F.softmax(input, dim=1)
target_onehot = self.to_one_hot(target, self.n_classes)
# Numerator Product
inter = pred * target_onehot
# Sum over all pixels N x C x H x W => N x C
inter = inter.view(N, self.n_classes, -1).sum(2)
# Denominator
union = pred + target_onehot - (pred * target_onehot)
# Sum over all pixels N x C x H x W => N x C
union = union.view(N, self.n_classes, -1).sum(2)
loss = inter / (union + 1e-16)
# Return average loss over classes and batch
return -loss.mean()
4.4 Lovasz-Softmax loss
Lovasz-Softmax loss是在CVPR2018提出的针对IOU优化设计的loss,比赛里用一下有奇效,数学推导已经超出笔者所知范围,有兴趣的可以围观一下论文。虽然理解起来比较难,但是用起来还是比较容易的。总的来说,就是对Jaccard loss 进行 Lovasz扩展,loss表现更好一点。
另外,作者在github答疑时表示由于该Lovasz softmax优化针对的是image-level mIoU,因此较小的batchsize训练对常用的dataset-level mIoU的性能表现会有损害。以及该loss适用于finetuning过程。将其与其它loss加权使用,会有比较好的效果。
作者给出了二分类和多分类的loss计算,个人觉得三步走:
- 计算每个像素errors,二分类里用的hinge算的errors,多分类直接计算预测值和真实值的差;
- 根据errors的排序,对labels排序,进而算Jaccard grad(代码里的lovasz_grad函数);
- 结合errors和Jaccard grad得到所求loss。
pytorch代码实现(摘自作者GitHub):
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import numpy as np
def lovasz_grad(gt_sorted):
"""
Computes gradient of the Lovasz extension w.r.t sorted errors
See Alg. 1 in paper
"""
p = len(gt_sorted)
gts = gt_sorted.sum()
intersection = gts - gt_sorted.float().cumsum(0)
union = gts + (1 - gt_sorted).float().cumsum(0)
jaccard = 1. - intersection / union
if p > 1: # cover 1-pixel case
jaccard[1:p] = jaccard[1:p] - jaccard[0:-1]
return jaccard
# --------------------------- BINARY LOSSES ---------------------------
def lovasz_hinge(logits, labels, per_image=True, ignore=None):
"""
Binary Lovasz hinge loss
logits: [B, H, W] Variable, logits at each pixel (between -\infty and +\infty)
labels: [B, H, W] Tensor, binary ground truth masks (0 or 1)
per_image: compute the loss per image instead of per batch
ignore: void class id
"""
if per_image:
loss = mean(lovasz_hinge_flat(*flatten_binary_scores(log.unsqueeze(0), lab.unsqueeze(0), ignore))
for log, lab in zip(logits, labels))
else:
loss = lovasz_hinge_flat(*flatten_binary_scores(logits, labels, ignore))
return loss
def lovasz_hinge_flat(logits, labels):
"""
Binary Lovasz hinge loss
logits: [P] Variable, logits at each prediction (between -\infty and +\infty)
labels: [P] Tensor, binary ground truth labels (0 or 1)
ignore: label to ignore
"""
if len(labels) == 0:
# only void pixels, the gradients should be 0
return logits.sum() * 0.
signs = 2. * labels.float() - 1.
errors = (1. - logits * Variable(signs))
errors_sorted, perm = torch.sort(errors, dim=0, descending=True)
perm = perm.data
gt_sorted = labels[perm]
grad = lovasz_grad(gt_sorted)
loss = torch.dot(F.relu(errors_sorted), Variable(grad))
return loss
def flatten_binary_scores(scores, labels, ignore=None):
"""
Flattens predictions in the batch (binary case)
Remove labels equal to 'ignore'
"""
scores = scores.view(-1)
labels = labels.view(-1)
if ignore is None:
return scores, labels
valid = (labels != ignore)
vscores = scores[valid]
vlabels = labels[valid]
return vscores, vlabels
# --------------------------- MULTICLASS LOSSES ---------------------------
def lovasz_softmax(probas, labels, classes='present', per_image=False, ignore=None):
"""
Multi-class Lovasz-Softmax loss
probas: [B, C, H, W] Variable, class probabilities at each prediction (between 0 and 1).
Interpreted as binary (sigmoid) output with outputs of size [B, H, W].
labels: [B, H, W] Tensor, ground truth labels (between 0 and C - 1)
classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.
per_image: compute the loss per image instead of per batch
ignore: void class labels
"""
if per_image:
loss = mean(lovasz_softmax_flat(*flatten_probas(prob.unsqueeze(0), lab.unsqueeze(0), ignore), classes=classes)
for prob, lab in zip(probas, labels))
else:
loss = lovasz_softmax_flat(*flatten_probas(probas, labels, ignore), classes=classes)
return loss
def lovasz_softmax_flat(probas, labels, classes='present'):
"""
Multi-class Lovasz-Softmax loss
probas: [P, C] Variable, class probabilities at each prediction (between 0 and 1)
labels: [P] Tensor, ground truth labels (between 0 and C - 1)
classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.
"""
if probas.numel() == 0:
# only void pixels, the gradients should be 0
return probas * 0.
C = probas.size(1)
losses = []
class_to_sum = list(range(C)) if classes in ['all', 'present'] else classes
for c in class_to_sum:
fg = (labels == c).float() # foreground for class c
if (classes is 'present' and fg.sum() == 0):
continue
if C == 1:
if len(classes) > 1:
raise ValueError('Sigmoid output possible only with 1 class')
class_pred = probas[:, 0]
else:
class_pred = probas[:, c]
errors = (Variable(fg) - class_pred).abs()
errors_sorted, perm = torch.sort(errors, 0, descending=True)
perm = perm.data
fg_sorted = fg[perm]
losses.append(torch.dot(errors_sorted, Variable(lovasz_grad(fg_sorted))))
return mean(losses)
def flatten_probas(probas, labels, ignore=None):
"""
Flattens predictions in the batch
"""
if probas.dim() == 3:
# assumes output of a sigmoid layer
B, H, W = probas.size()
probas = probas.view(B, 1, H, W)
B, C, H, W = probas.size()
probas = probas.permute(0, 2, 3, 1).contiguous().view(-1, C) # B * H * W, C = P, C
labels = labels.view(-1)
if ignore is None:
return probas, labels
valid = (labels != ignore)
vprobas = probas[valid.nonzero().squeeze()]
vlabels = labels[valid]
return vprobas, vlabels
4.5 Focal loss
Focal loss是何恺明针对训练样本不平衡提出的loss 函数。公式:

可以认为,focal loss是交叉熵上的变种,针对以下两个问题设计了两个参数α \alphaα、β \betaβ:
- 正负样本不平衡,比如负样本太多;
- 存在大量的简单易分类样本。
第一个问题,容易想到可以在loss函数中,给不同类别的样本loss加权重,正样本少,就加大正样本loss的权重,这就是focal loss里面参数 α \alphaα的作用;第二个问题,设计了参数β \betaβ,从公式里就可以看到,当样本预测值pt比较大时,也就是易分样本,(1-pt)^beta 会很小,这样易分样本的loss会显著减小,模型就会更关注难分样本loss的优化。
pytorch 代码实现:
import torch
import torch.nn as nn
# --------------------------- BINARY LOSSES ---------------------------
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=2, weight=None, ignore_index=255):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.weight = weight
self.ignore_index = ignore_index
self.bce_fn = nn.BCEWithLogitsLoss(weight=self.weight)
def forward(self, preds, labels):
if self.ignore_index is not None:
mask = labels != self.ignore
labels = labels[mask]
preds = preds[mask]
logpt = -self.bce_fn(preds, labels)
pt = torch.exp(logpt)
loss = -((1 - pt) ** self.gamma) * self.alpha * logpt
return loss
# --------------------------- MULTICLASS LOSSES ---------------------------
class FocalLoss(nn.Module):
def __init__(self, alpha=0.5, gamma=2, weight=None, ignore_index=255):
super().__init__()
self.alpha = alpha
self.gamma = gamma
self.weight = weight
self.ignore_index = ignore_index
self.ce_fn = nn.CrossEntropyLoss(weight=self.weight, ignore_index=self.ignore_index)
def forward(self, preds, labels):
logpt = -self.ce_fn(preds, labels)
pt = torch.exp(logpt)
loss = -((1 - pt) ** self.gamma) * self.alpha * logpt
return loss
五 激活函数
激活函数是用来加入非线性因素的,因为线性模型的表达能力不够。引入非线性激活函数,可使深层神经网络的表达能力更加强大。
5.1 sigmoid激活函数
Sigmoid又叫作 Logistic 激活函数,它将实数值压缩进 0 到 1 的区间内,还可以在预测概率的输出层中使用。该函数将大的负数转换成 0,将大的正数转换成 1。数学公式为:

下图展示了 Sigmoid 函数及其导数的图像:

一般来讲,在训练神经网络的过程中,对于求导、连续求导、处理二分类问题,一般使用Sigmoid激活函数,因为Sigmoid函数可以把实数域光滑的映射到[0,1]空间。函数值恰好可以解释为属于正类的概率(概率的取值范围是0~1)。
另外,Sigmoid函数单调递增,连续可导,导数形式非常简单。但是对于多分类问题,Sigmoid函数就显得心有余而力不足了。
此外,sigmoid函数的输出均大于0,使得输出不是0均值,这称为偏移现象,这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。
优点:
(1)Sigmoid函数的输出映射在(0,1)之间,单调连续,输出范围有限,优化稳定,可以用作输出层。
(2)求导容易。
缺点:
(1)由于其软饱和性,容易产生梯度消失,导致训练出现问题。
(2)其输出并不是以0为中心的。
5.2 tanh激活函数
tanh也是一种非常常见的激活函数。它实际上是sigmoid函数的一种变形。tanh函数由下列公式定义:

导数:


Tanh 激活函数又叫作双曲正切激活函数(hyperbolic tangent activation function)。它解决了Sigmoid函数的不是zero-centered输出问题。与 Sigmoid 函数类似,Tanh 函数也使用真值,但 Tanh 函数将其压缩至-1 到 1 的区间内。与 Sigmoid 不同,Tanh 函数的输出以零为中心,因为区间在-1 到 1 之间。你可以将 Tanh 函数想象成两个 Sigmoid 函数放在一起。在实践中,Tanh 函数的使用优先性高于 Sigmoid 函数。负数输入被当作负值,零输入值的映射接近零,正数输入被当作正值。唯一的缺点是:Tanh 函数也会有梯度消失的问题,因此在饱和时也会「杀死」梯度。
为了解决梯度消失问题,我们来讨论另一个非线性激活函数——修正线性单元(rectified linear unit,ReLU),该函数明显优于前面两个函数,是现在使用最广泛的函数。
5.3 ReLU激活函数
数学公式:

函数图像及其导数图像:


当输入 x<0 时,输出为 0,当 x> 0 时,输出为 x。该激活函数使网络更快速地收敛。它不会饱和,即它可以对抗梯度消失问题,至少在正区域(x> 0 时)可以这样,因此神经元至少在一半区域中不会把所有零进行反向传播。由于使用了简单的阈值化(thresholding),ReLU 计算效率很高。但是 ReLU 神经元也存在一些缺点:
- 不以零为中心:和 Sigmoid 激活函数类似,ReLU 函数的输出不以零为中心。
- 前向传导(forward pass)过程中,如果 x < 0,则神经元保持非激活状态,且在后向传导(backward pass)中「杀死」梯度。这样权重无法得到更新,网络无法学习。当 x = 0 时,该点的梯度未定义,但是这个问题在实现中得到了解决,通过采用左侧或右侧的梯度的方式。
为了解决 ReLU 激活函数中的梯度消失问题,当 x < 0 时,我们使用 Leaky ReLU——该函数试图修复 dead ReLU 问题。下面我们就来详细了解 Leaky ReLU。
5.4 Leaky ReLU激活函数
数学公式:

函数图像:

Leaky ReLU 的概念是:当 x < 0 时,它得到 0.1 的正梯度。该函数一定程度上缓解了 dead ReLU 问题,但是使用该函数的结果并不连贯。尽管它具备 ReLU 激活函数的所有特征,如计算高效、快速收敛、在正区域内不会饱和。
Leaky ReLU 可以得到更多扩展。不让 x 乘常数项,而是让 x 乘超参数,这看起来比 Leaky ReLU 效果要好。该扩展就是 Parametric ReLU。
5.5 Parametric ReLU激活函数

其中α是超参数。这里引入了一个随机的超参数,它可以被学习,因为你可以对它进行反向传播。这使神经元能够选择负区域最好的梯度,有了这种能力,它们可以变成 ReLU 或 Leaky ReLU。
总之,最好使用 ReLU,但是你可以使用 Leaky ReLU 或 Parametric ReLU 实验一下,看看它们是否更适合你的问题。
版权归原作者 Kili_66 所有, 如有侵权,请联系我们删除。