
推荐系统算法详解
一、推荐系统详解
1. 基于人口统计学的推荐算法
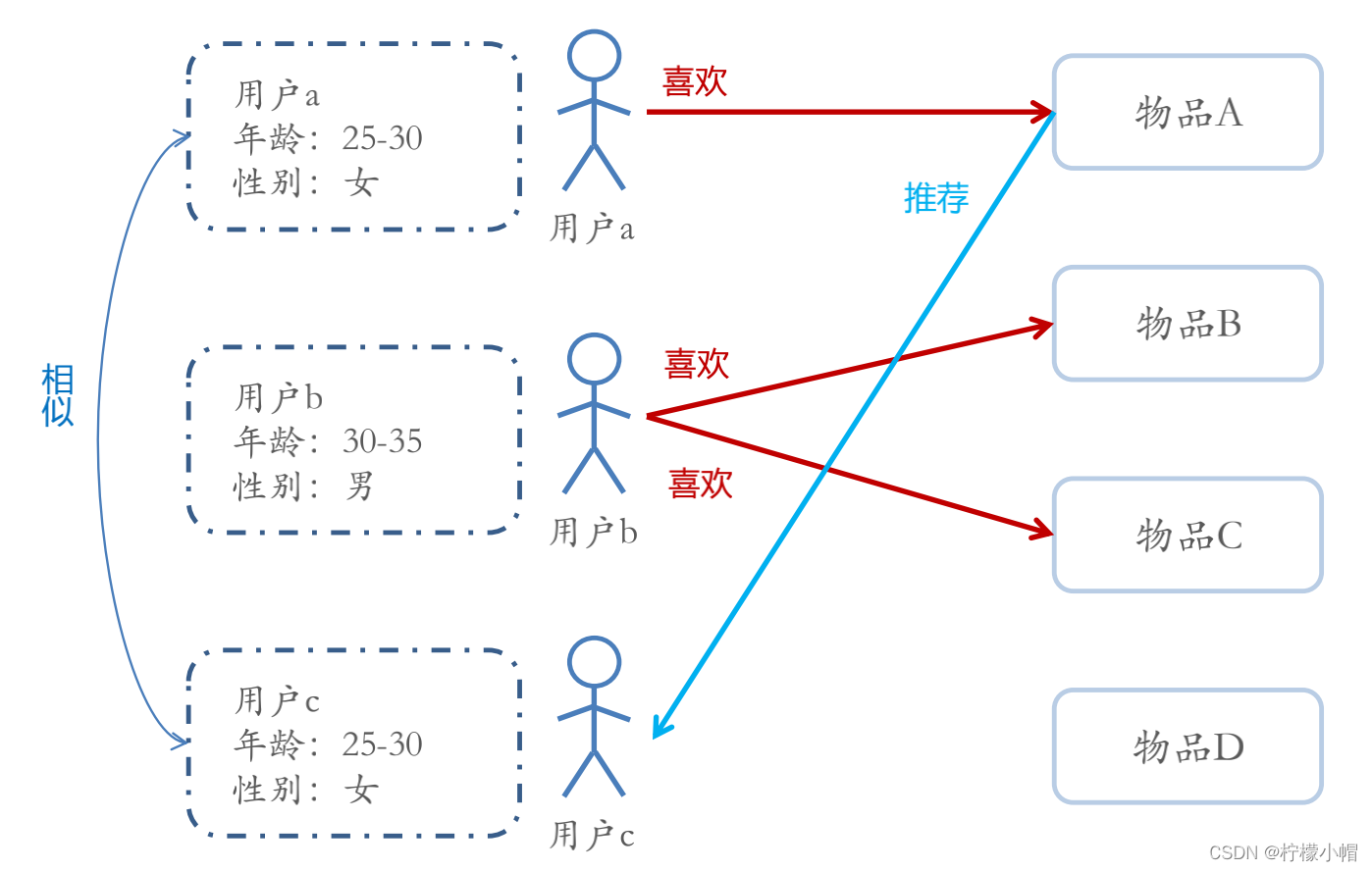
- 基于人口统计学的推荐机制(Demographic-based Recommendation)是一种最易于实现的推荐方法,它只是简单的根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户
- 对于没有明确含义的用户信息(比如登录时间、地域等上下文信息),可以通过聚类等手段,给用户打上分类标签
- 对于特定标签的用户,又可以根据预设的规则(知识)或者模型,推荐出对应的物品
- 用户信息标签化的过程一般又称为用户画像(User Profiling)
- 用户画像(User Profile)就是企业通过收集与分析消费者社会属性、生活习惯、消费行为等主要信息的数据之后,完美地抽象出一个用户的商业全貌作,是企业应用大数据技术的基本方式
- 用户画像为企业提供了足够的信息基础,能够帮助企业快速找到精准用户群体以及用户需求等更为广泛的反馈信息
- 作为大数据的根基,它完美地抽象出一个用户的信息全貌,为进一步精准、快速地分析用户行为习惯、消费习惯等重要信息,提供了足够的数据基础
2. 基于内容的推荐算法(Content based CB)
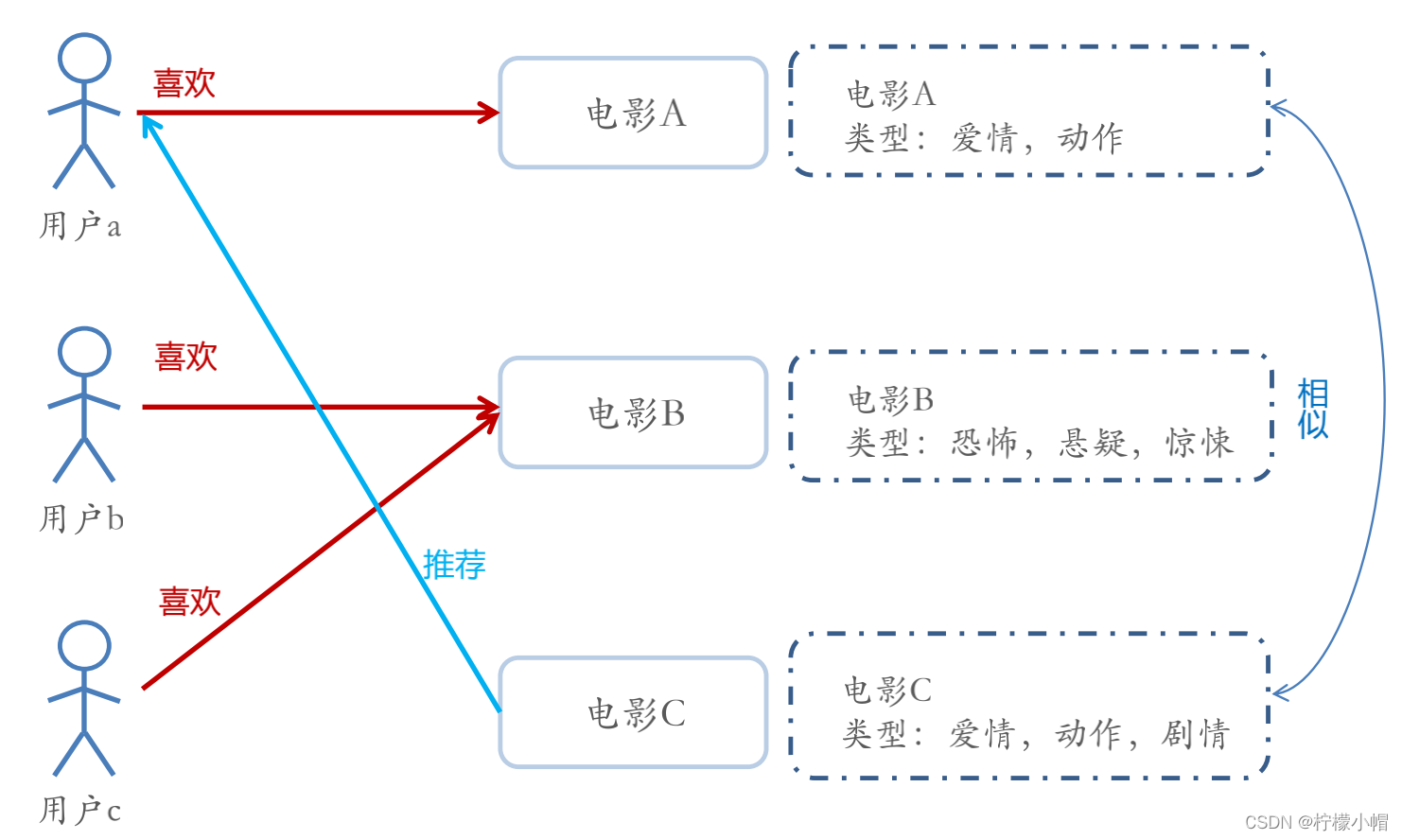
- Content-based Recommendations (CB)根据推荐物品或内容的元数据,发现物品的相关性,再基于用户过去的喜好记录,为用户推荐相似的物品。
- 通过抽取物品内在或者外在的特征值,实现相似度计算。 - 比如一个电影,有导演、演员、用户标签UGC、用户评论、时长、风格等等,都可以算是特征。
- 将用户(user)个人信息的特征(基于喜好记录或是预设兴趣标签),和物品(item)的特征相匹配,就能得到用户对物品感兴趣的程度 - 在一些电影、音乐、图书的社交网站有很成功的应用,有些网站还请专业的人员对物品进行基因编码/打标签(PGC)
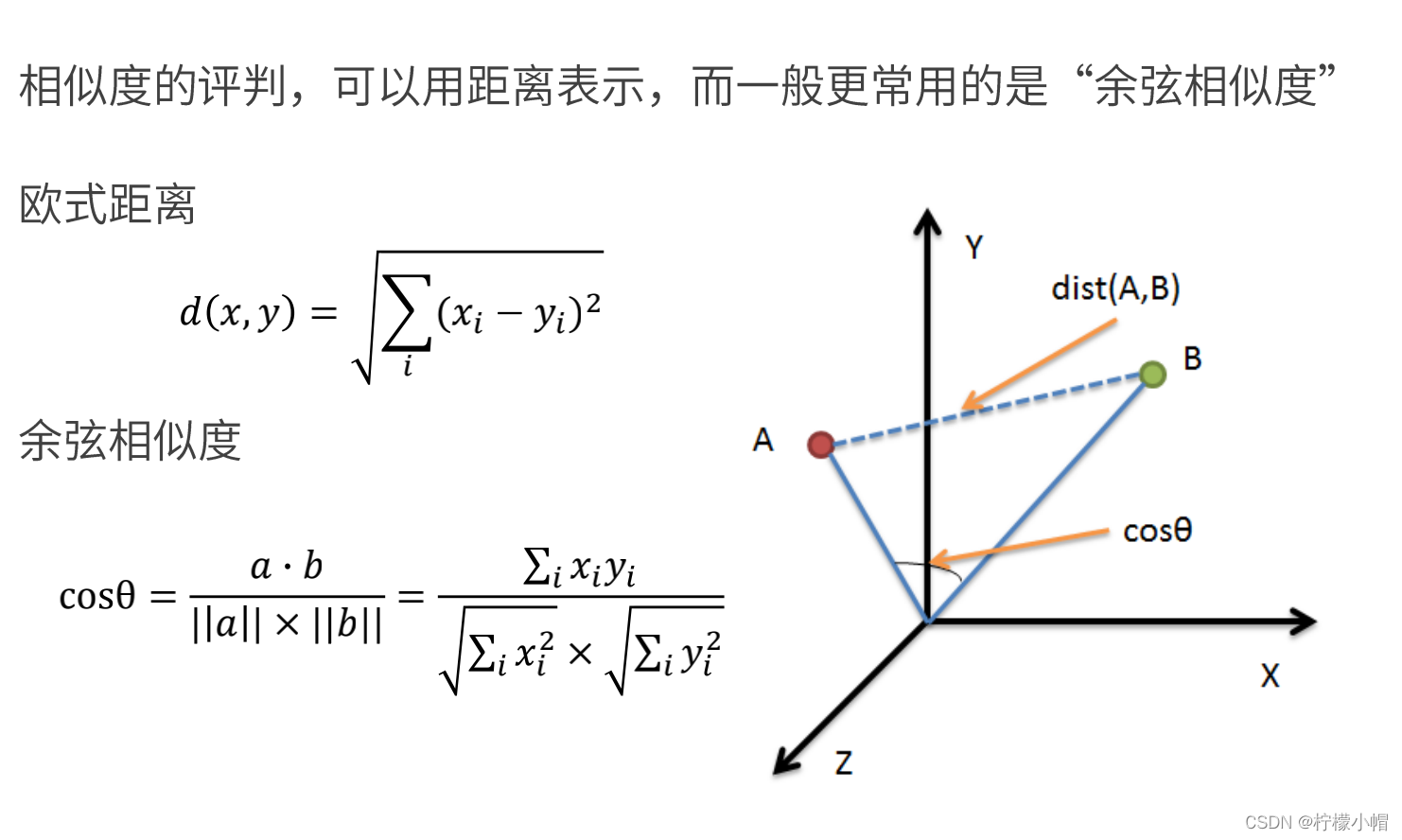
- 相似度计算
- 对于物品的特征提取 —— 打标签(tag) - 专家标签(PGC)- 用户自定义标签(UGC)- 降维分析数据,提取隐语义标签(LFM)
- 对于文本信息的特征提取——关键词 - 分词、语义处理和情感分析(NLP)- 潜在语义分析(LSA)
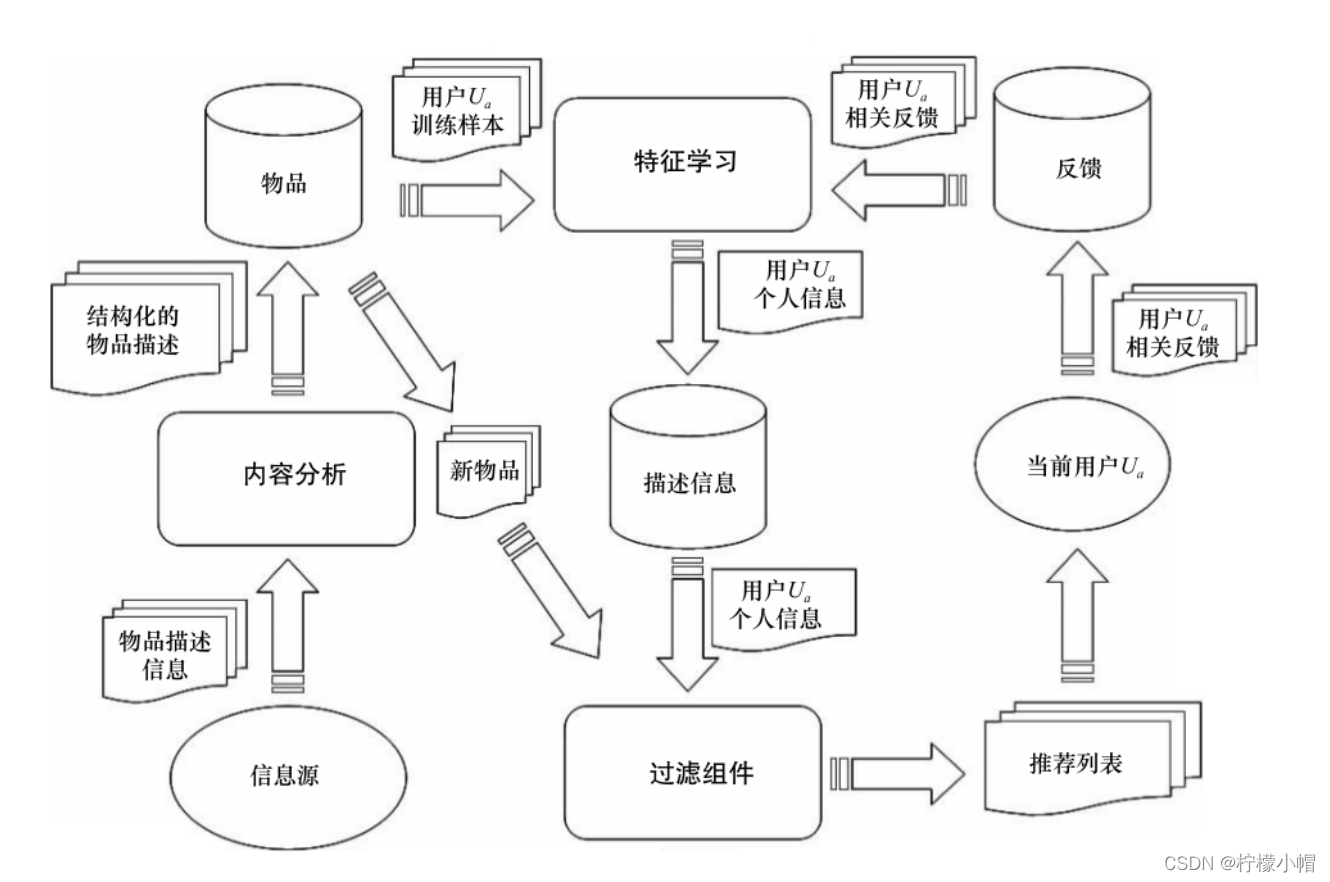
- 基于内容推荐系统的高层次结构
3. 特征工程

- 特征:作为判断条件的一组输入变量,是做出判断的依据
- 目标:判断和预测的目标,模型的输出变量,是特征所产生的结果
- 特征(feature):数据中抽取出来的对结果预测有用的信息。
- 特征的个数就是数据的观测维度
- 特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程
- 特征工程一般包括特征清洗(采样、清洗异常样本),特征处理和特征选择
- 特征按照不同的数据类型分类,有不同的特征处理方法 - 数值型- 类别型- 时间型- 统计型
4. 数值型特征处理
- 用连续数值表示当前维度特征,通常会对数值型特征进行数学上的处理,主要的做法是归一化和离散化
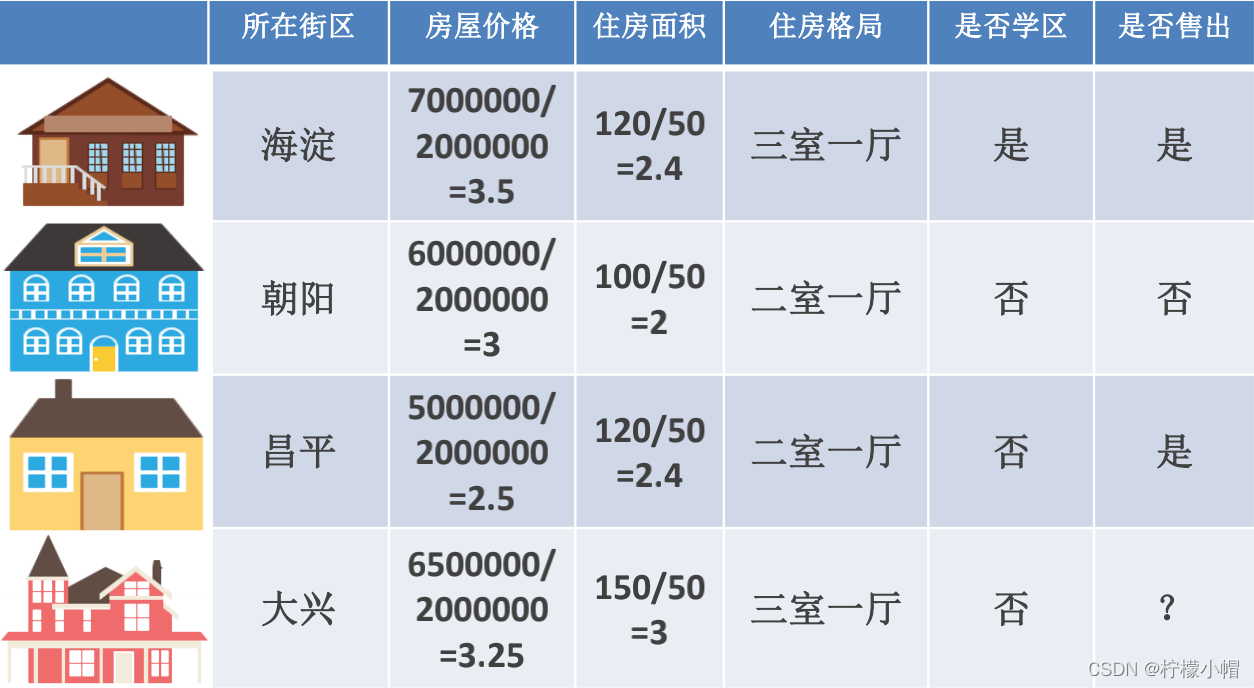
- 幅度调整/归一化
- 特征与特征之间应该是平等的,区别应该体现在特征内部
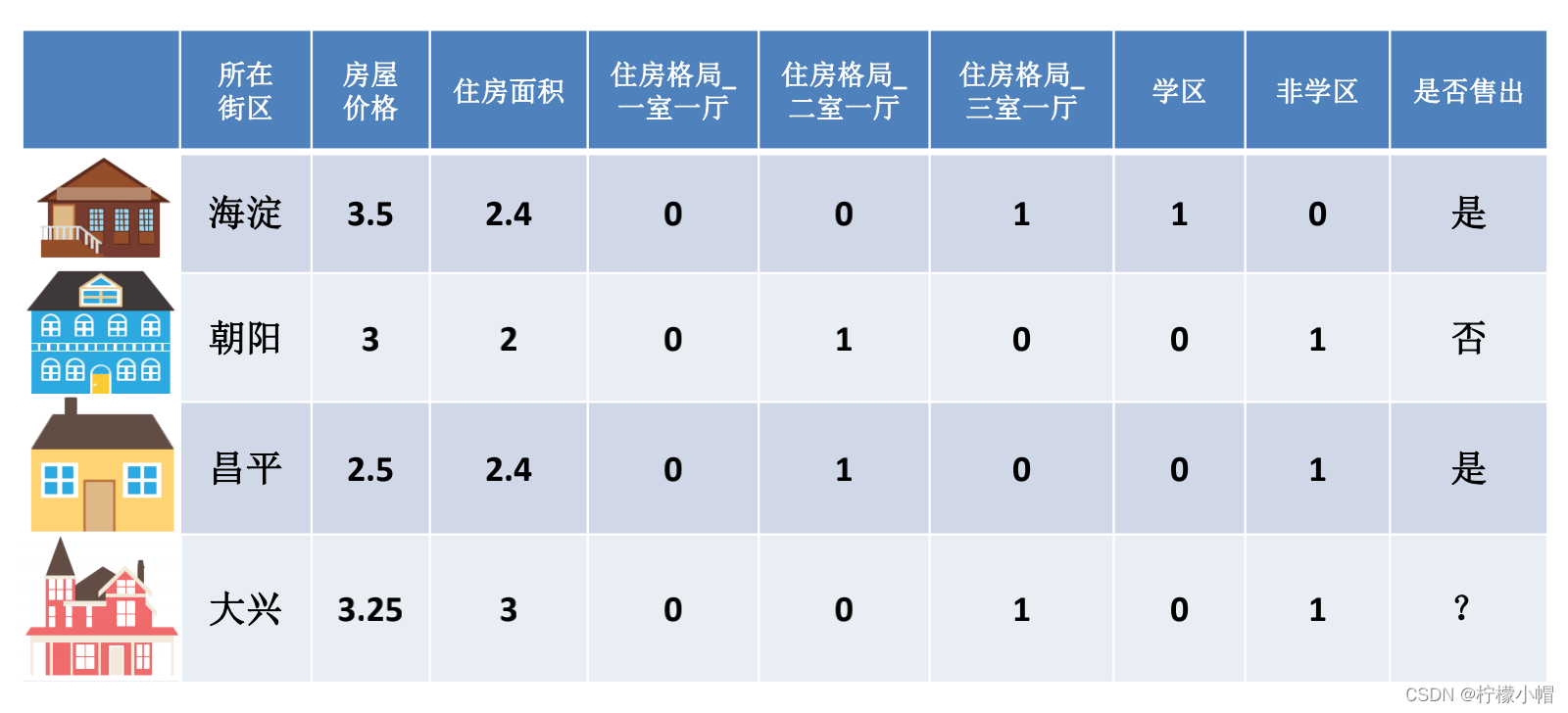
- 例如房屋价格和住房面积的幅度是不同的,房屋价格可能在3000000 ~ 15000000 (万)之间,而住房面积在40-300 (平方米)之间,那么明明是平等的两个特征,输入到相同的模型中后由于本身的幅值不同导致产生的效果不同,这是不合理的
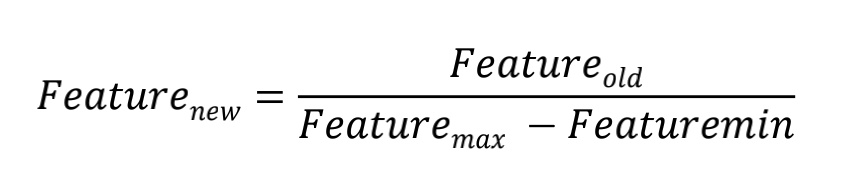
- 用之前的特征除以特征的最大值和最小值之差得出新的特征
5. 数值型特征处理(归一化)

6. 数值型特征处理(离散化)

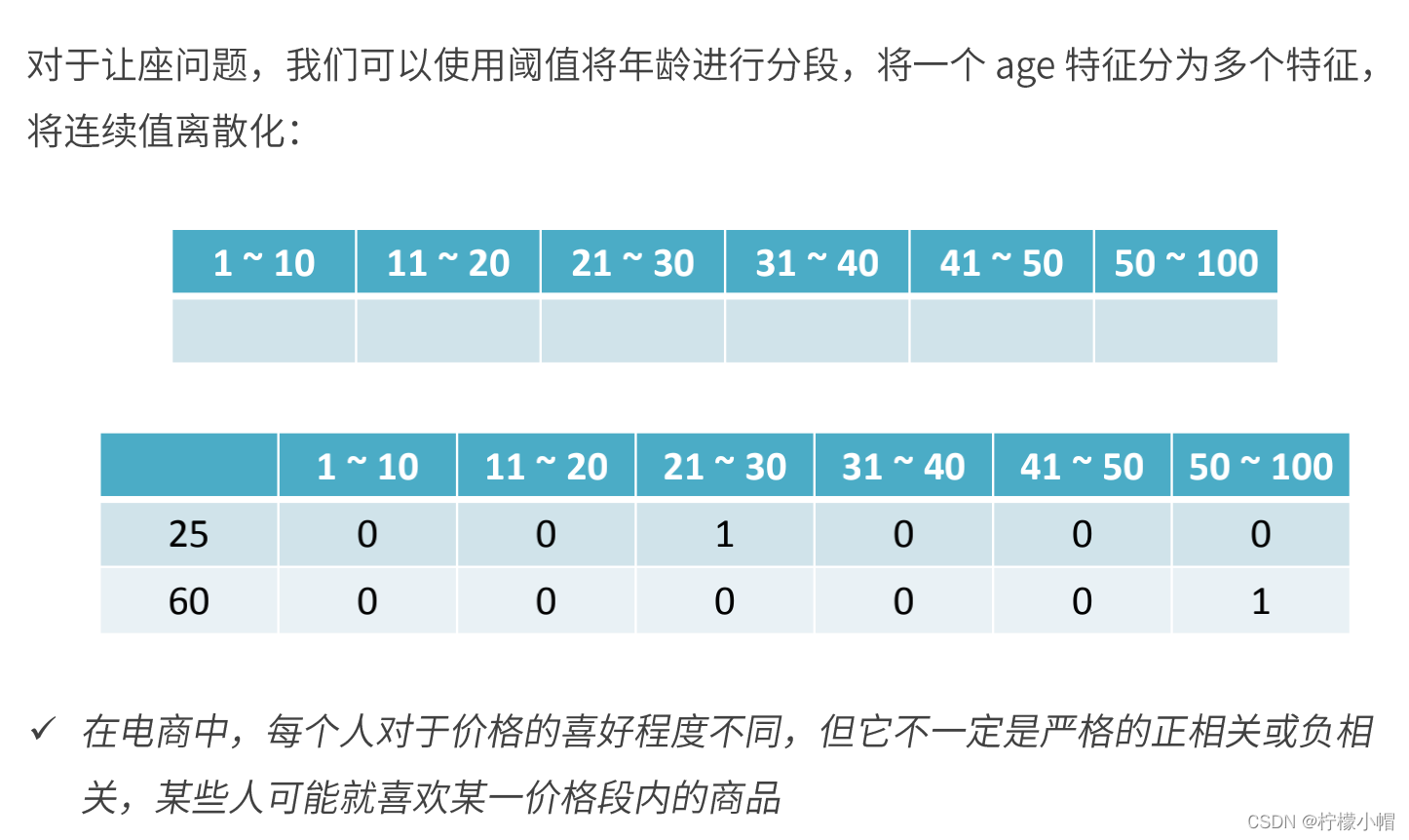
- 离散化的两种方式 - 等步长:简单但不一定有效- 等频:min -> 25% -> 75% -> max
- 两种方法对比 - 等频的离散化方法很精准,但需要每次都对数据分布进行一遍重新计算,因为昨天用户在淘宝上买东西的价格分布和今天不一定相同,因此昨天做等频的切分点可能并不适用, 而线上最需要避免的就是不固定,需要现场计算,所以昨天训练出的模型今天不一定能使用- 等频不固定,但很精准,等步长是固定的,非常简单,因此两者在工业上都有应用
7. 类别型特征处理
- 类别型数据本身没有大小关系,需要将它们编码为数字,但它们之间不能有预 先设定的大小关系,因此既要做到公平,又要区分开它们,那么直接开辟多个空间
- One-Hot编码/哑变量 - One-Hot编码/哑变量所做的就是将类别型数据平行地展开,也就是说,经过One-Hot编码/哑变量后,这个特征的空间会膨胀
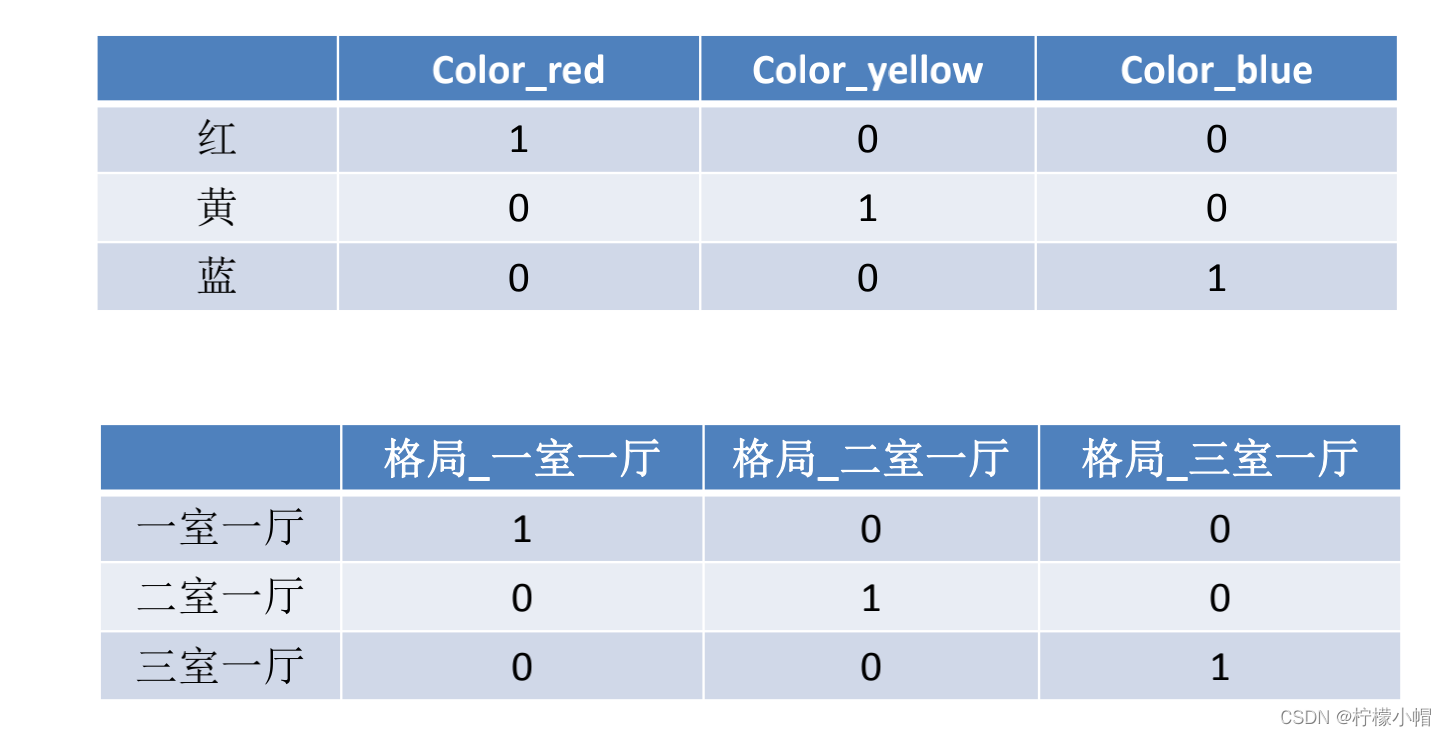
8. 时间型特征处理
- 时间型特征既可以做连续值,又可以看做离散值。
- 连续值 - 持续时间(网页浏览时长)- 间隔时间(上一次购买/点击离现在的时间间隔)
- 离散值 - 一天中哪个时间段- —周中的星期几- —年中哪个月/星期- 工作日/周末
9. 统计型特征处理
- 加减平均:商品价格高于平均价格多少,用户在某个品类下消费超过多少。
- 分位线:商品属于售出商品价格的分位线处。
- 次序性:商品处于热门商品第几位。
- 比例类:电商中商品的好/中/差评比例。
10. 推荐系统常见反馈数据
11. 基于 UGC 的推荐

- 问题 - 简单算法中直接将用户打出标签的次数和物品得到的标签次数相乘,可以简单地表现出用户对物品某个特征的兴趣- 这种方法倾向于给热门标签(谁都会给的标签,如“大片”、“搞笑”等)、热门物品(打标签人数最多)比较大的权重,如果一个热门物品同时对应着热门标签,那它就会“霸榜”,推荐的个性化、新颖度就会降低- 类似的问题,出现在新闻内容的关键字提取中。比如以下新闻中,哪个关键字应该获得更高的权重?

12. TF-IDF
- 词频-逆文档频率(Term Frequency-Inverse Document Frequency, TF-IDF)是一种用于资讯检索与文本挖掘的常用加权技术
- TF-IDF是一种统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降 - TFIDF = TF X IDF
- TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类
- TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级


13. TF-IDF算法代码实现
# 1.引入依赖import numpy as np
import pandas as pd
# 2.定义数据和预处理
docA ="The cat sat on my bed"
docB ="The dog sat on my knees"
bowA = docA.split(" ")
bowB = docB.split(" ")# 3.构建词库
wordSet =set(bowA).union(set(bowB))
wordSet # {'The', 'bed', 'cat', 'dog', 'knees', 'my', 'on', 'sat'}# 进行词数统计# 用统计字典来保存词出现的次数
wordDictA =dict.fromkeys(wordSet,0)
wordDictB =dict.fromkeys(wordSet,0)
wordDictA
# {'The': 0,# 'sat': 0,# 'cat': 0,# 'on': 0,# 'dog': 0,# 'my': 0,# 'bed': 0,# 'knees': 0}# 遍历文档,统计词数for word in bowA:
wordDictA[word]+=1for word in bowB:
wordDictB[word]+=1
pd.DataFrame([wordDictA, wordDictB])# The sat cat on dog my bed knees# 0 1 1 1 1 0 1 1 0# 1 1 1 0 1 1 1 0 1# 4.计算词频TFdefcomputeTF( wordDict, bow ):# 用一个字典对象记录tf,把所有的词对应在bow文档里的tf都算出来
tfDict ={}
nbowCount =len(bow)for word, count in wordDict.items():
tfDict[word]= count / nbowCount
return tfDict
tfA = computeTF(wordDictA, bowA)
tfB = computeTF(wordDictB, bowB)
tfA
# {'The': 0.16666666666666666,# 'sat': 0.16666666666666666,# 'cat': 0.16666666666666666,# 'on': 0.16666666666666666,# 'dog': 0.0,# 'my': 0.16666666666666666,# 'bed': 0.16666666666666666,# 'knees': 0.0}# 5.计算逆文档频率IDFdefcomputeIDF(wordDictList):# 用一个字典对象保存idf结果,每个词作为key,初始值为0
idfDict =dict.fromkeys(wordDictList[0],0)
N =len(wordDictList)import math
for wordDict in wordDictList:# 遍历字典中的每个词汇for word, count in wordDict.items():if count >0:# 先把Ni增加1,存入到idfDict
idfDict[word]+=1# 已经得到所有词汇i对应的Ni,现在根据公式把它替换成为idf值for word, ni in idfDict.items():
idfDict[word]= math.log10((N +1)/(ni +1))return idfDict
idfs = computeIDF([wordDictA, wordDictB])
idfs
# {'The': 0.0,# 'sat': 0.0,# 'cat': 0.17609125905568124,# 'on': 0.0,# 'dog': 0.17609125905568124,# 'my': 0.0,# 'bed': 0.17609125905568124,# 'knees': 0.17609125905568124}# 6.计算TF-IDFdefcomputeTFIDF(tf, idfs):
tfidf ={}for word, tfval in tf.items():
tfidf[word]= tfval * idfs[word]return tfidf
tfidfA = computeTFIDF(tfA, idfs)
tfidfB = computeTFIDF(tfB, idfs)
pd.DataFrame([tfidfA, tfidfB])# The sat cat on dog my bed knees# 0 0.0 0.0 0.029349 0.0 0.000000 0.0 0.029349 0.000000# 1 0.0 0.0 0.000000 0.0 0.029349 0.0 0.000000 0.029349
14. 基于协同过滤的推荐算法
- 协同过滤(Collaborative Filtering,CF)
- 基于近邻的协同过滤 - 基于用户(User-CF)- 基于物品(Item-CF)
- 基于模型的协同过滤 - 奇异值分解(SVD)- 潜在语义分析(LSA)- 支撑向量机(SVM)
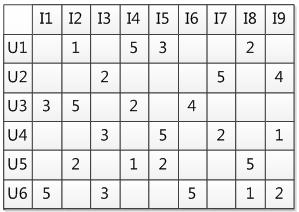
- 基于内容(Content based, CB)主要利用的是用户评价过的物品的内容特征,而CF方法还可以利用其他用户评分过的物品内容
- CF可以解决CB的一些局限 - 物品内容不完全或者难以获得时,依然可以通过其他用户的反馈给出推荐- CF基于用户之间对物品的评价质量,避免了CB仅依赖内容可能造成的对物品质量判断的干扰- CF推荐不受内容限制,只要其他类似用户给出了对不同物品的兴趣,CF就可以给用户推荐出内容差异很大的物品(但有某种内在联系)- 分为两类:基于近邻和基于模型
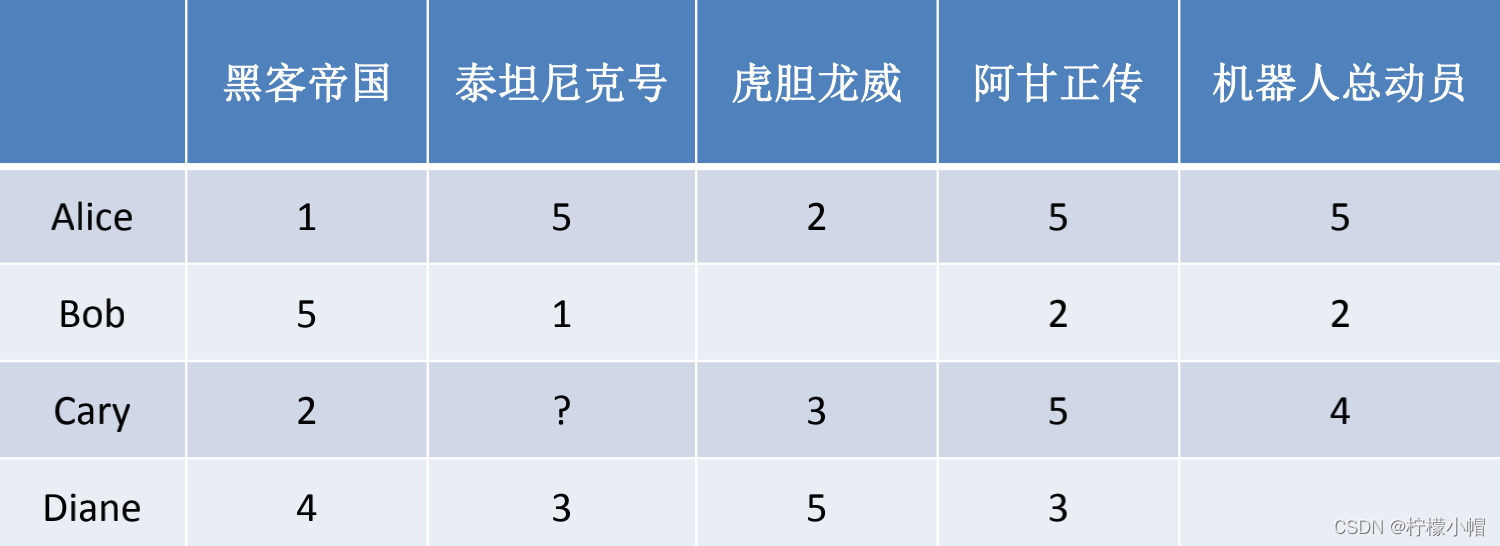
15. 基于近邻的推荐
- 基于近邻的推荐系统根据的是相同“口碑”准则
- 是否应该给Cary推荐《泰坦尼克号》?(应该)
16. 基于用户的协同过滤(User-CF)
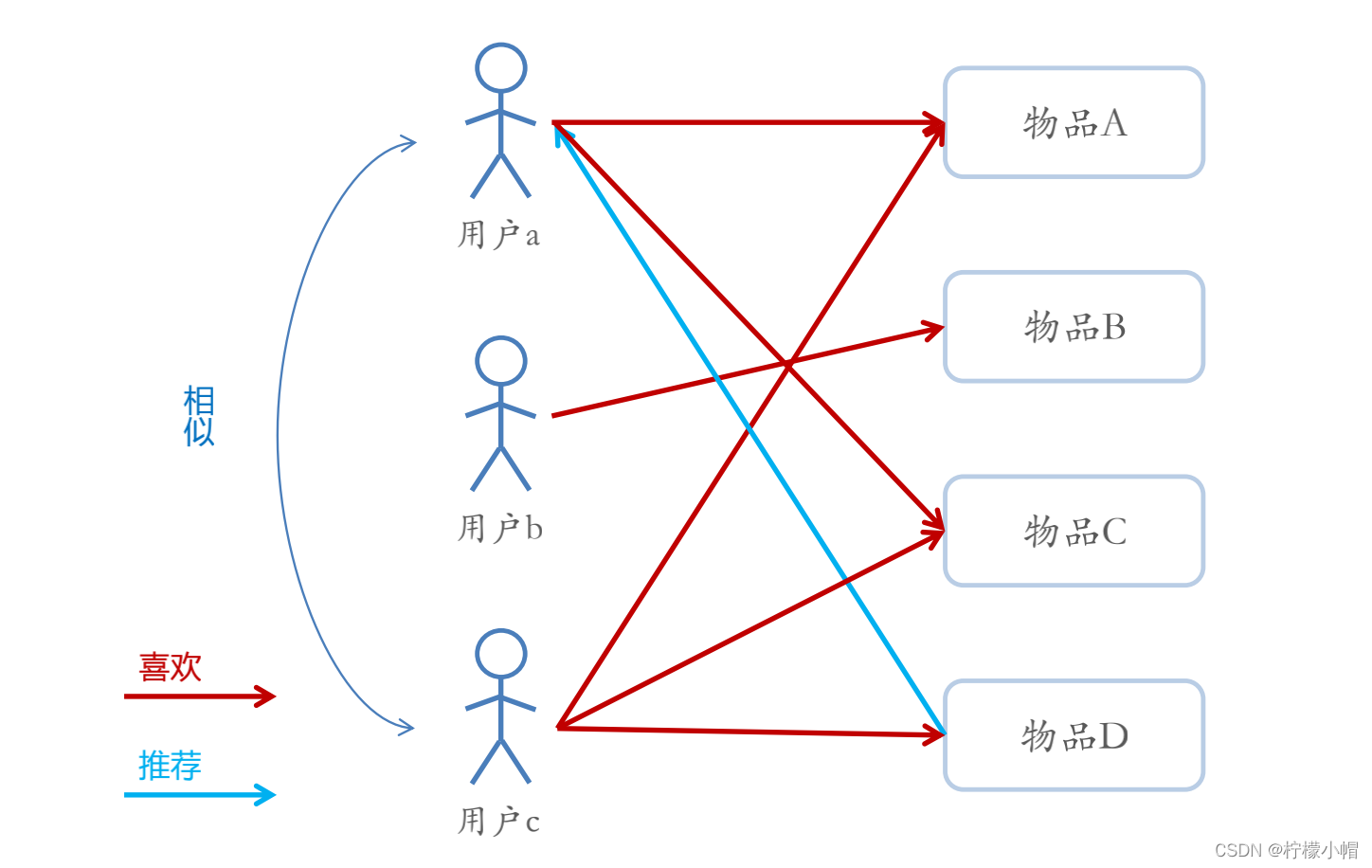
- 基于用户的协同过滤推荐的基本原理是,根据所有用户对物品的偏好,发现与当前用户口味和偏好相似的“邻居”用户群,并推荐近邻所偏好的物品
- 在一般的应用中是采用计算“K-近邻”的算法;基于这K个邻居的历史偏好 信息,为当前用户进行推荐
- User-CF和基于人口统计学的推荐机制 - 两者都是计算用户的相似度,并基于相似的“邻居”用户群计算推荐- 它们所不同的是如何计算用户的相似度:基于人口统计学的机制只考虑用户本身的特征,而基于用户的协同过滤机制可是在用户的历史偏好的数据上计算用户的相似度,它的基本假设是,喜欢类似物品的用户可能有相同或者相似的口味和偏好
17. 基于物品的协同过滤
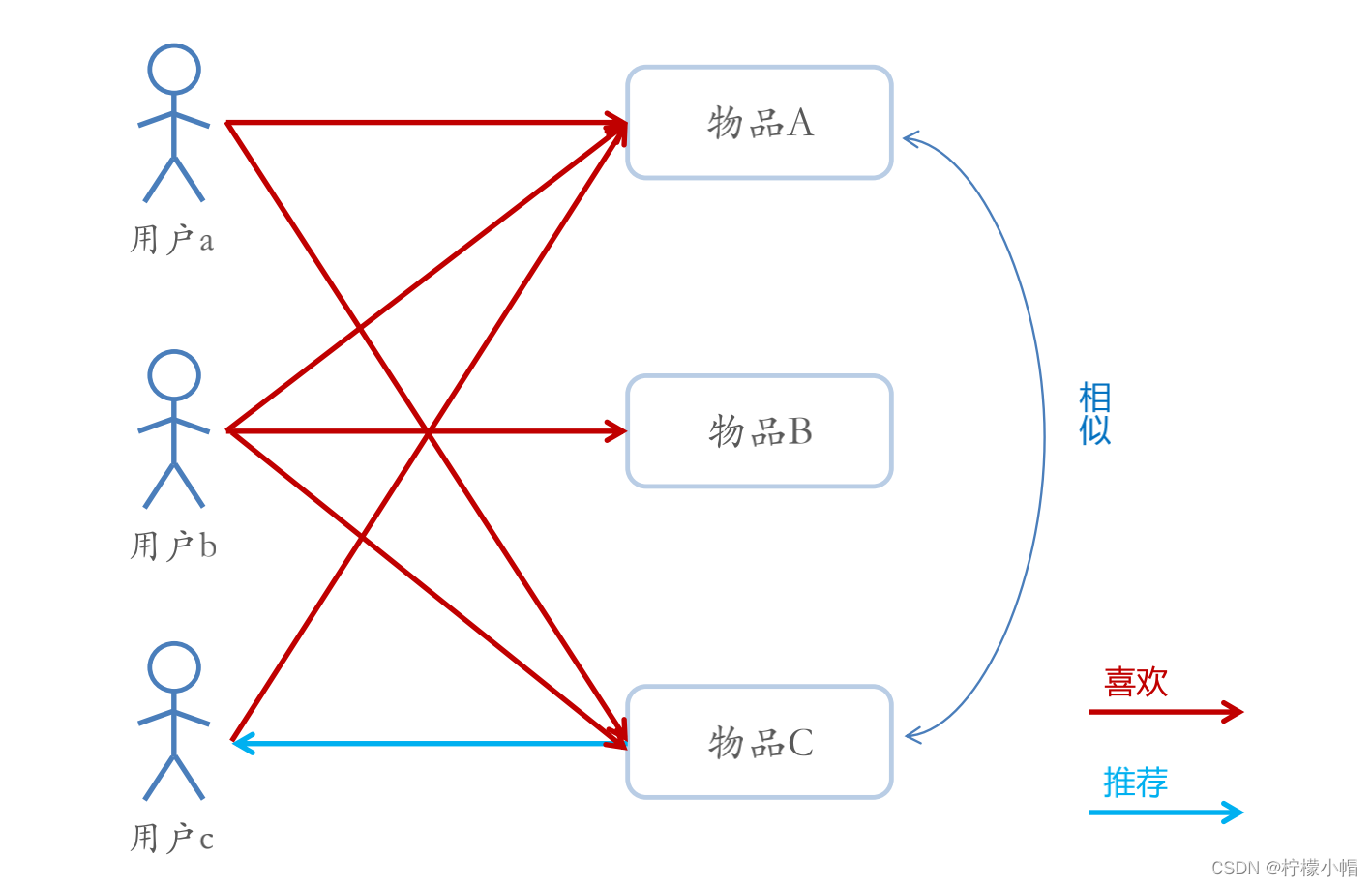
- 基于项目的协同过滤推荐的基本原理与基于用户的类似,只是使用所有用户对物品的偏好,发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户
- Item-CF和基于内容(CB)的推荐 - 其实都是基于物品相似度预测推荐,只是相似度计算的方法不一样,前者是从用户历史的偏好推断,而后者是基于物品本身的属性特征信息
- 同样是协同过滤,在基于用户和基于项目两个策略中应该如何选择呢? - 电商、电影、音乐网站,用户数量远大于物品数量- 新闻网站,物品(新闻文本)数量可能大于用户数量
18. User-CF 和 Item-CF 的比较
- 同样是协同过滤,在User-CF和Item-CF两个策略中应该如何选择呢?
- Item-CF应用场景 - 基于物品的协同过滤(Item-CF)推荐机制是Amazon在基于用户的机制上改良的一种策略。因为在大部分的Web站点中,物品的个数是远远小于用户的数量的,而且物品的个数和相似 度相对比较稳定,同时基于物品的机制比基于用户的实时性更好一些,所以Item-CF成为了目 前推荐策略的主流
- User-CF应用场景 - 设想一下在一些新闻推荐系统中,也许物品一一也就是新闻的个数可能大于用户的个数,而且新闻的更新程度也有很快,所以它的相似度依然不稳定,这时用User-CF可能效果更好
- 所以,推荐策略的选择其实和具体的应用场景有很大的关系
17. 基于协同过滤的推荐优缺点
- 基于协同过滤的推荐机制的优点: - 它不需要对物品或者用户进行严格的建模,而且不要求对物品特征的描述是机器可理解的,所以这种方法也是领域无关的- 这种方法计算出来的推荐是开放的,可以共用他人的经验,很好的支持用户发现潜在的兴趣偏好
- 存在的问题: - 方法的核心是基于历史数据,所以对新物品和新用户都有“冷启动”的问题- 推荐的效果依赖于用户历史偏好数据的多少和准确性- 在大部分的实现中,用户历史偏好是用稀疏矩阵进行存储的,而稀疏矩阵上的计算有些明显的 问题,包括可能少部分人的错误偏好会对推荐的准确度有很大的影响等等- 对于一些特殊品味的用户不能给予很好的推荐
18. 基于模型的协同过滤思想
- 基本思想 - 用户具有一定的特征,决定着他的偏好选择;- 物品具有一定的特征,影响着用户需是否选择它;- 用户之所以选择某一个商品,是因为用户特征与物品特征相互匹配;
- 基于这种思想,模型的建立相当于从行为数据中提取特征,给用户和物品同时打上“标签”;这和基于人口统计学的用户标签、基于内容方法的物品标签本质是一样的,都是特征的提取和匹配
- 有显性特征时(比如用户标签、物品分类标签)我们可以直接匹配做出推荐; 没有时,可以根据已有的偏好数据,去发掘出隐藏的特征,这需要用到隐语义模型(LFM)
- 基于模型的协同过滤推荐,就是基于样本的用户偏好信息,训练一个推荐模型, 然后根据实时的用户喜好的信息进行预测新物品的得分,计算推荐
- 基于近邻的推荐和基于模型的推荐 - 基于近邻的推荐是在预测时直接使用已有的用户偏好数据,通过近邻数据来预测对新物品的偏好 (类似分类)- 而基于模型的方法,是要使用这些偏好数据来训练模型,找到内在规律,再用模型来做预测(类似回归)
- 训练模型时,可以基于标签内容来提取物品特征,也可以让模型去发掘物品的潜在特征;这样的模型被称为隐语义模型(Latent Factor Model, LFM)
19. 隐语义模型(LFM )
- 用隐语义模型来进行协同过滤的目标 - 揭示隐藏的特征,这些特征能够解释为什么给出对应的预测评分- 这类特征可能是无法直接用语言解释描述的,事实上我们并不需要知道,类似"玄学”
- 通过矩阵分解进行降维分析 - 协同过滤算法非常依赖历史数据,而一般的推荐系统中,偏好数据又往往是稀疏的;这就需要对原始数据做降维处理- 分解之后的矩阵,就代表了用户和物品的隐藏特征
- 隐语义模型的实例 - 基于概率的隐语义分析(pLSA)- 隐式迪利克雷分布模型(LDA)- 矩阵因子分解模型(基于奇异值分解的模型,SVD)
20. LFM 降维方法 —— 矩阵因子分解
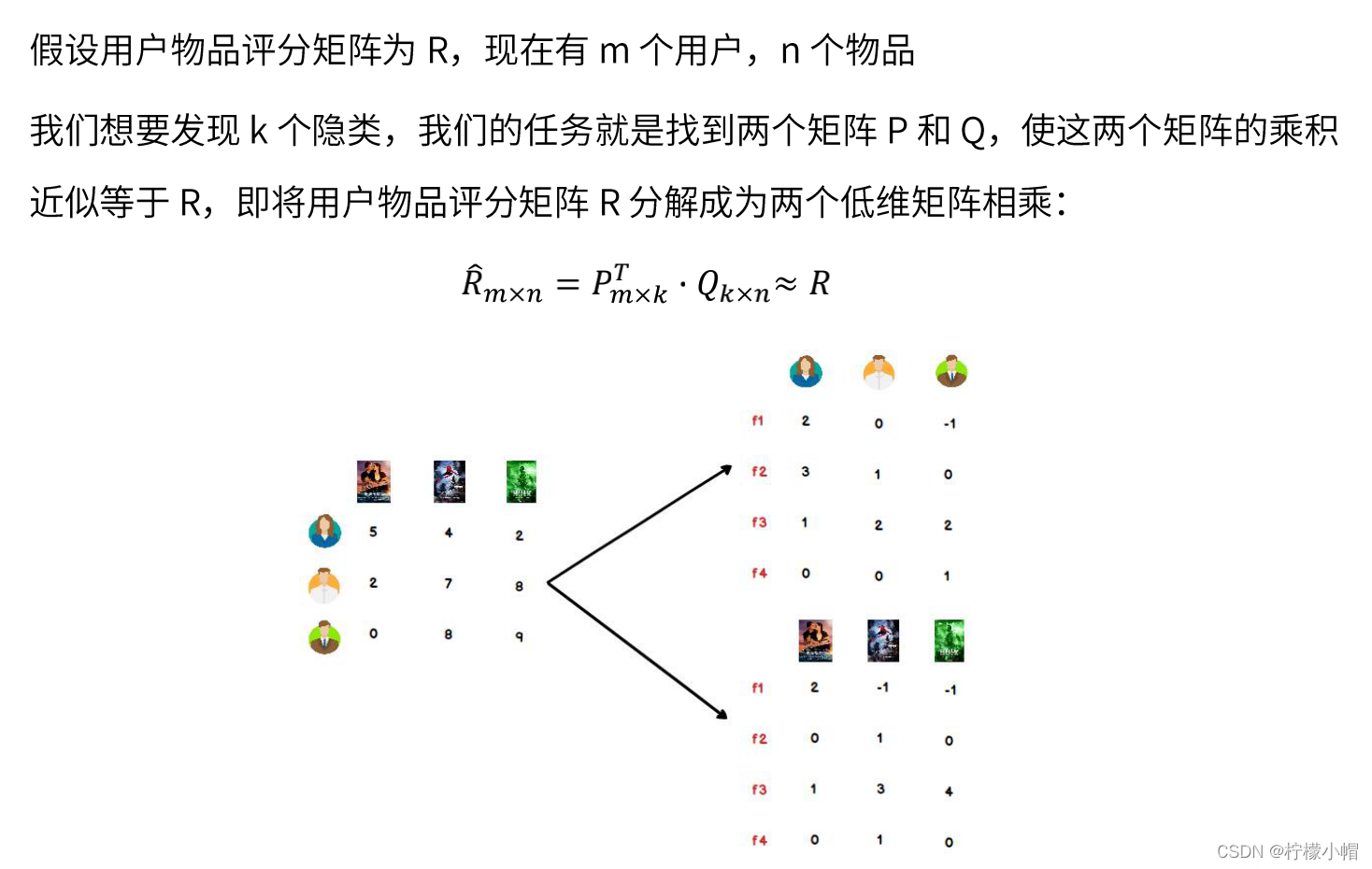
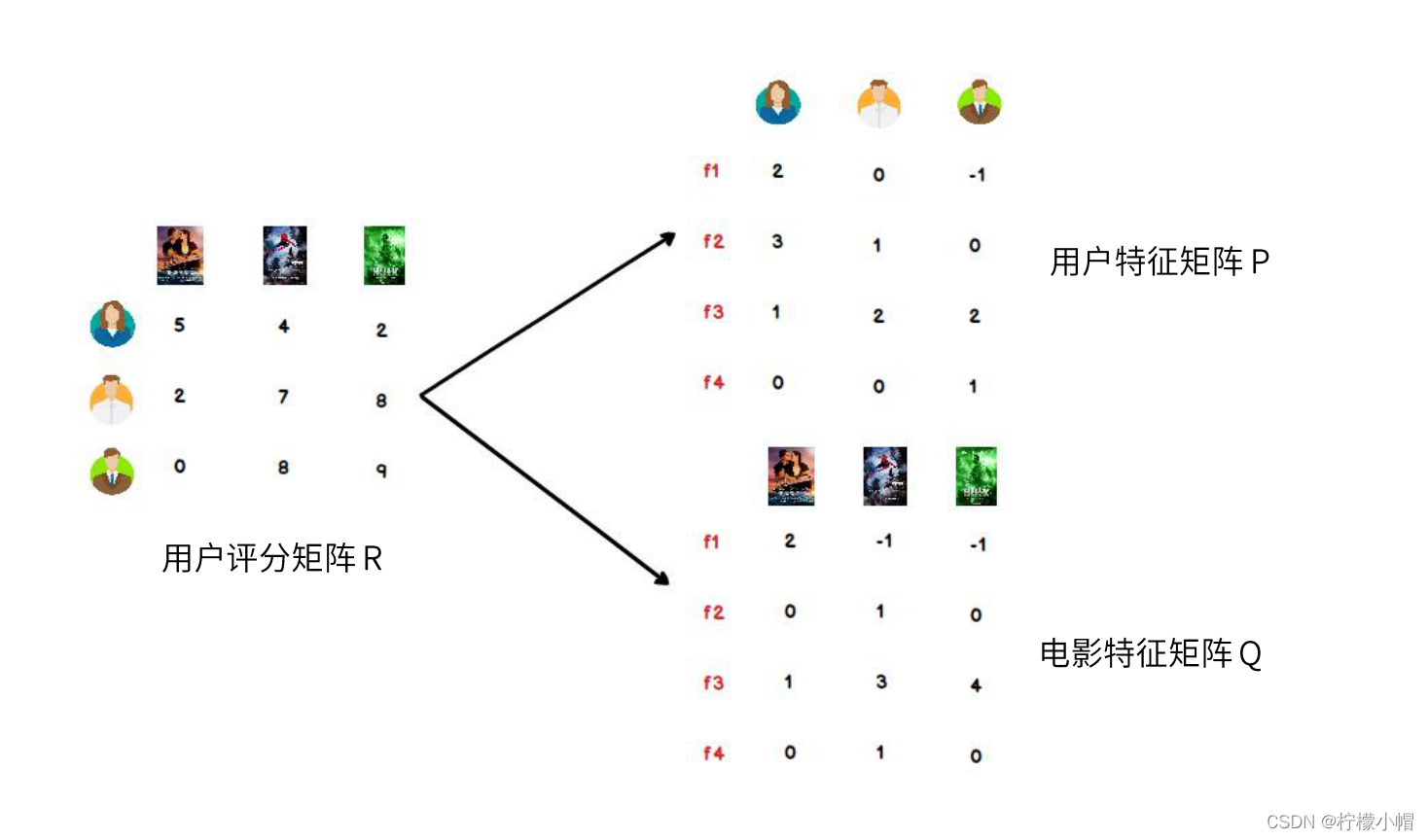
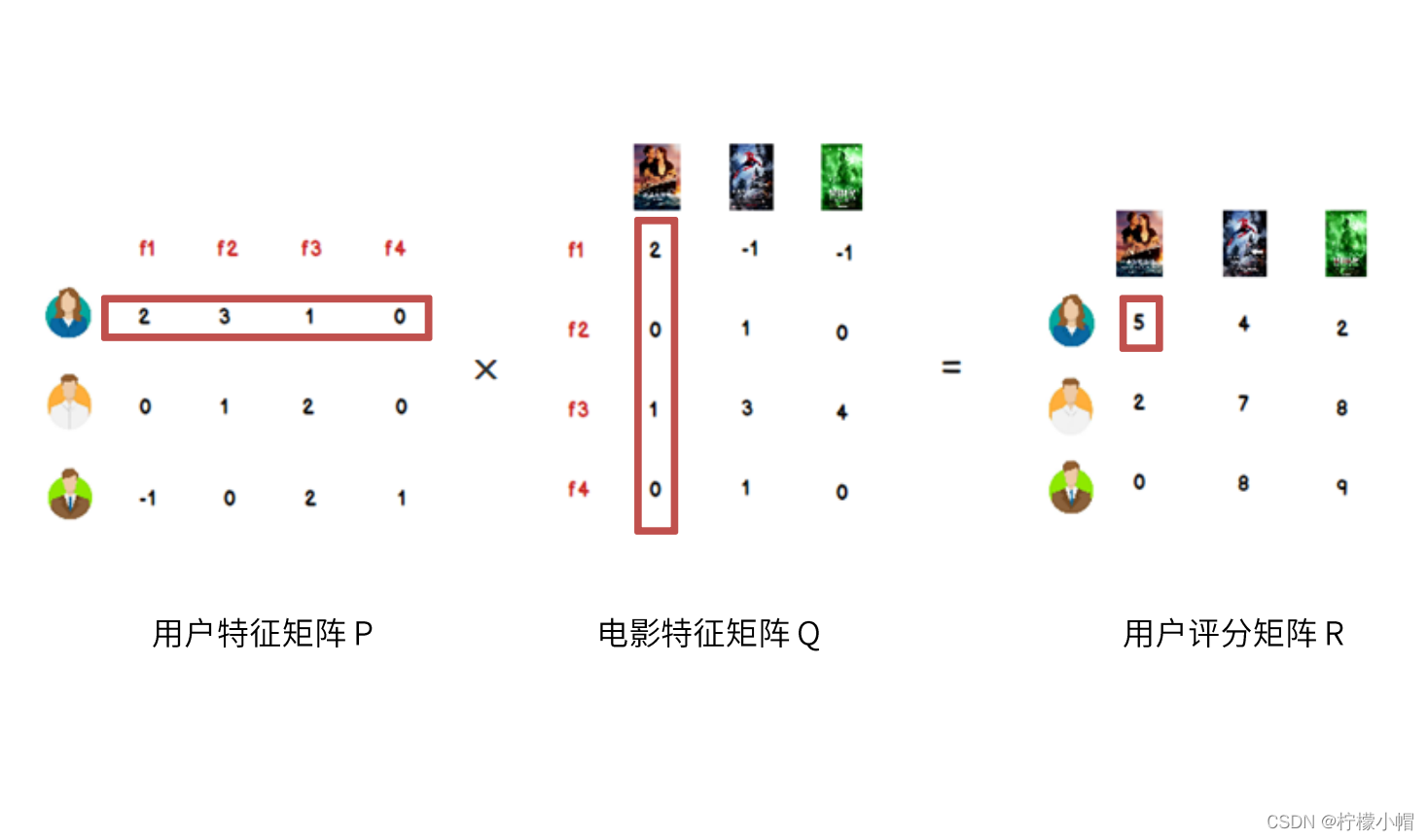
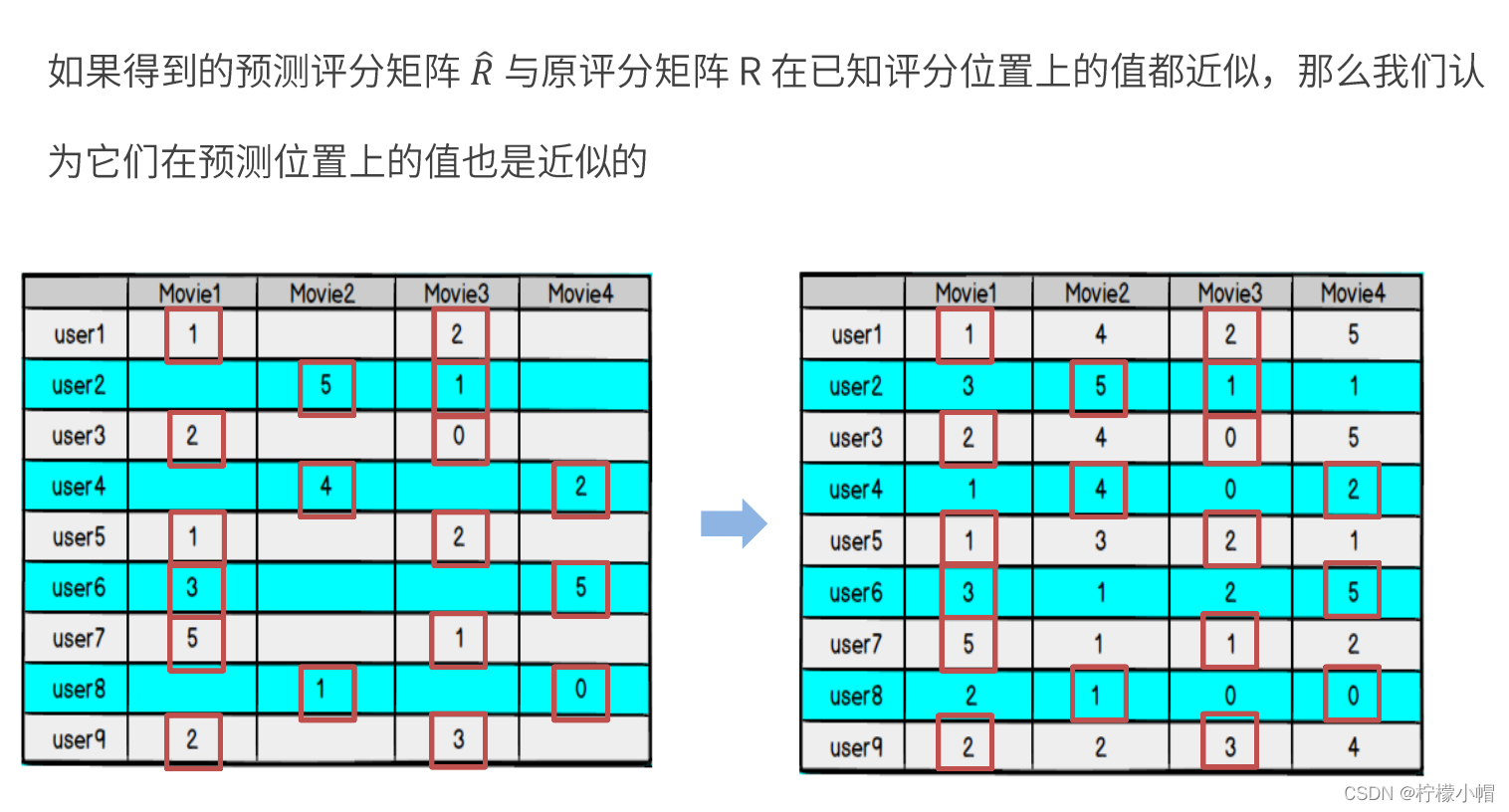
- 我们可以认为,用户之所以给电影打出这样的分数,是有内在原因的,我们可以挖掘出影响用户打分的隐藏因素,进而根据未评分电影与这些隐藏因素的关联度,决定此未评分电影的预测评分
- 应该有一些隐藏的因素,影响用户的打分,比如电影:演员、题材、年代…甚至不一定是人直接可以理解的隐藏因子
- 找到隐藏因子,可以对user和item进行关联(找到是由于什么使得user喜欢/不喜欢此item,什么会决定user喜欢/不喜欢此item),就可以推测用户是否会喜欢某一部未看过的电影
- 对于用户看过的电影,会有相应的打分,但一个用户不可能看过所有电影,对于用户没有看过的电影是没有评分的,因此用户评分矩阵大部分项都是空的,是一个稀疏矩阵
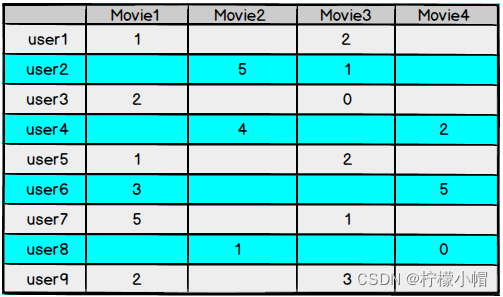
- 如果我们能够根据用户给已有电影的打分推测出用户会给没有看过的电影的打分,那么就可以根据预测结果给用户推荐他可能打高分的电影
21. 矩阵因子分解
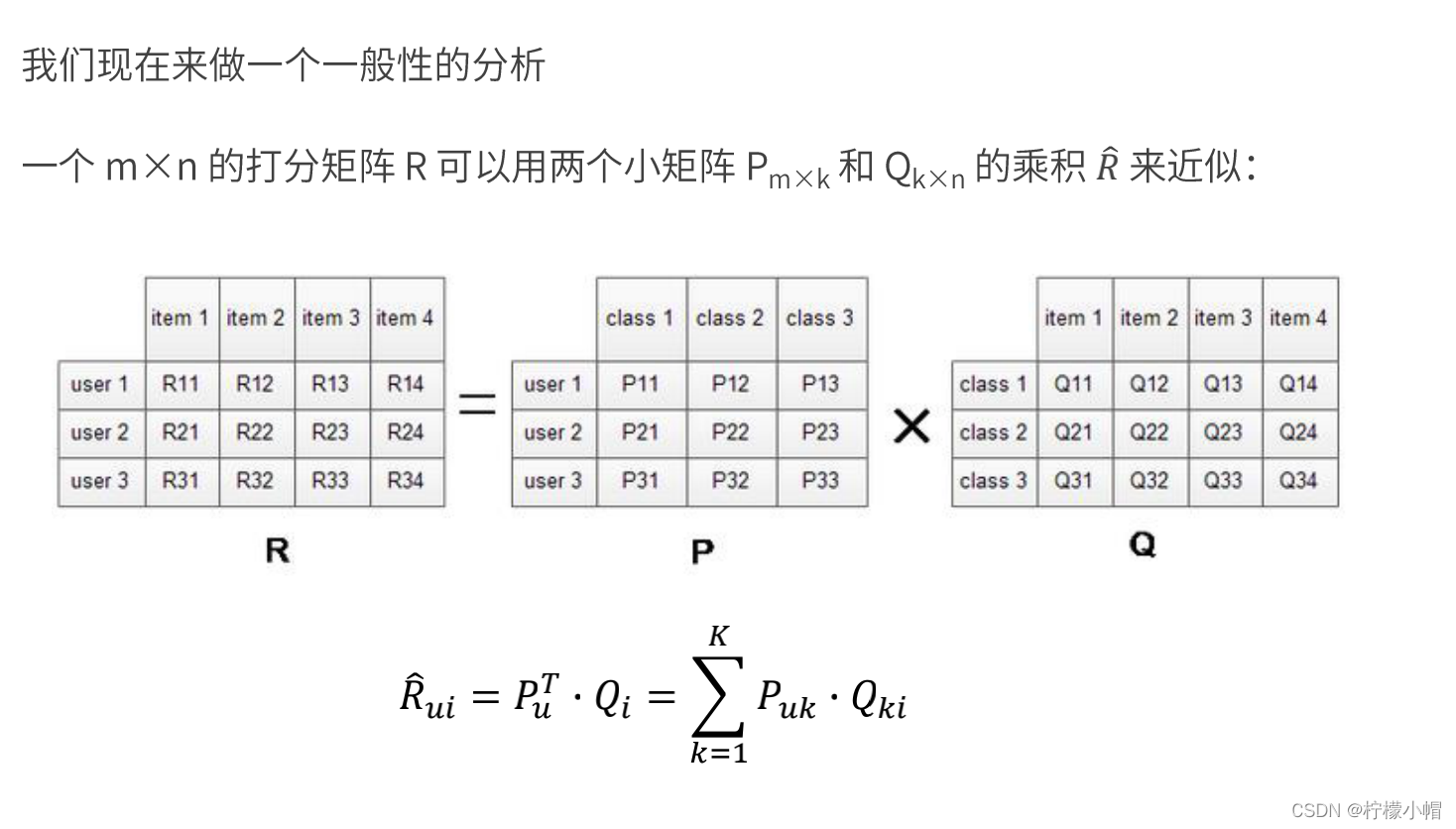
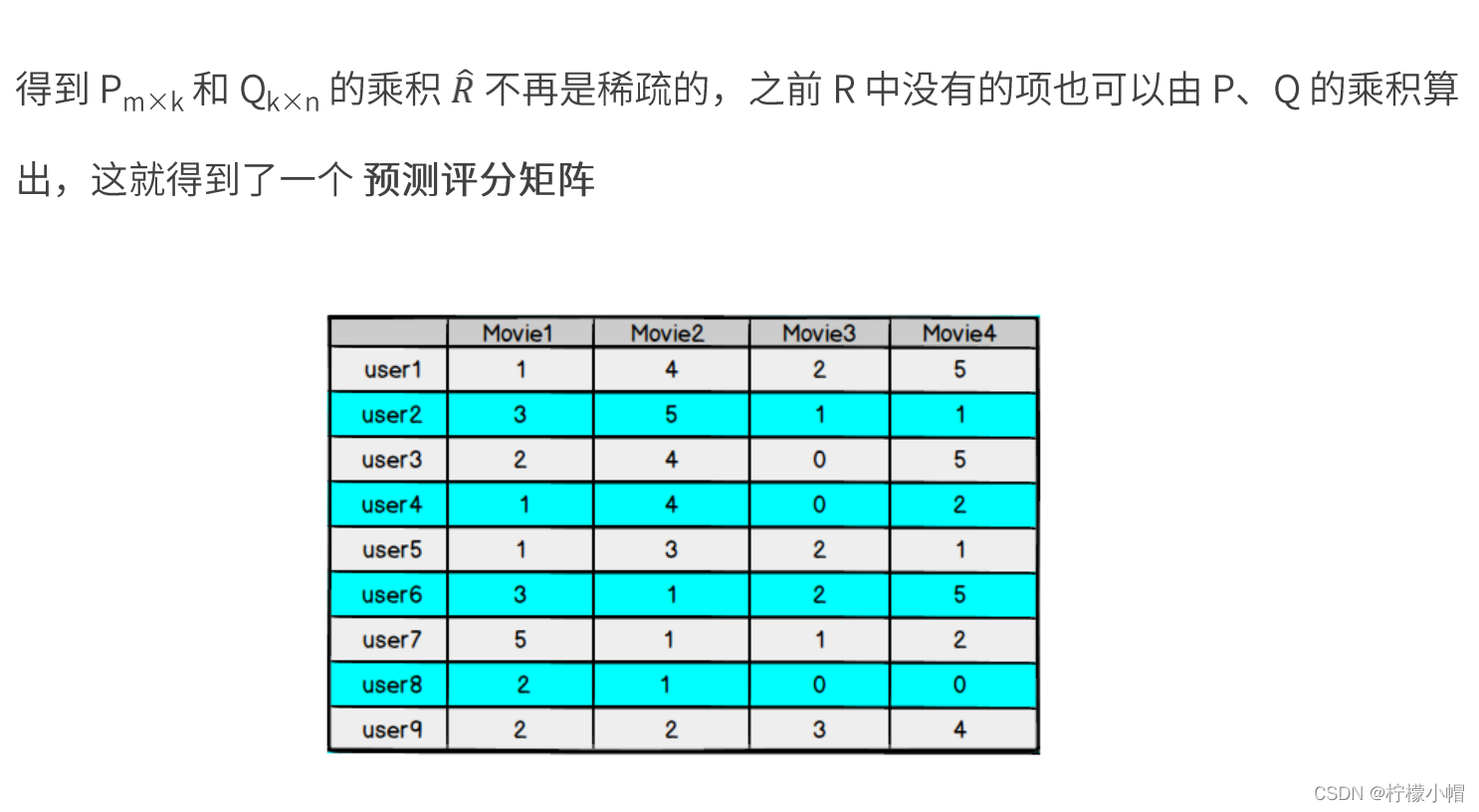
22. 模型的求解 —— 损失函数

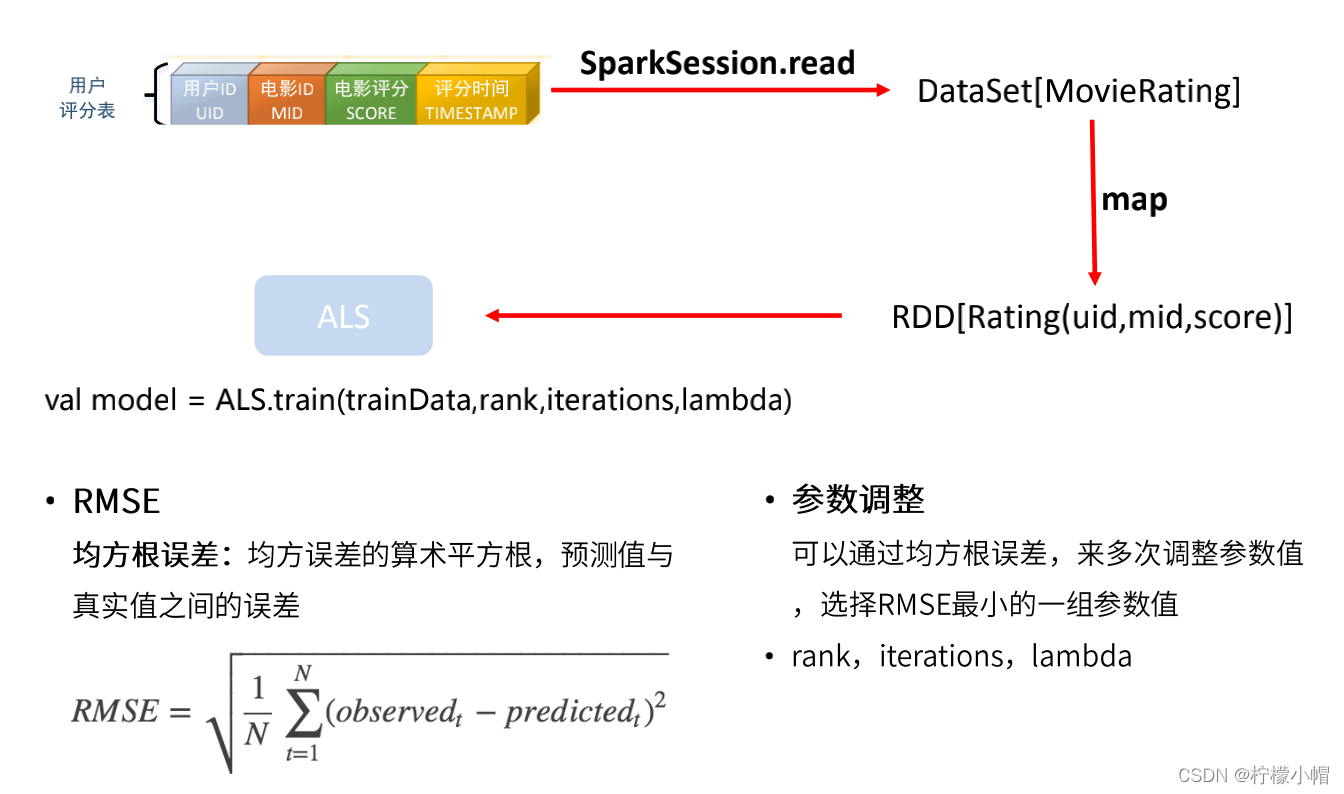
23. 模型的求解算法 —— ALS
- 现在,矩阵因子分解的问题已经转化成了一个标准的优化问题,需要求解P、Q,使目标损失函数取最小值
- 最小化过程的求解,一般采用随机梯度下降算法或者交替最小二乘法来实现 - 交替最小二乘法(Alternating Least Squares , ALS )
- ALS的思想是,由于两个矩阵P和Q都未知,且通过矩阵乘法耦合在一起,为了使它们解耦,可以先固定Q,把P当作变量,通过损失函数最小化求出P,这就是一个经典的最小二乘问题;再反过来固定求得的P,把Q当作变量,求解出Q:如此交替执行,直到误差满足阈值条件,或者到达迭代上限
24. ALS算法




25. 梯度下降算法

26. LFM 梯度下降算法代码实现
# 1 引入依赖import numpy as np
import pandas as pd
# 2 数据准备# 评分矩阵R
R = np.array([[4,0,2,0,1],[0,2,3,0,0],[1,0,2,4,0],[5,0,0,3,1],[0,0,1,5,1],[0,3,2,4,1]])len(R[0])# 5# 3 算法实现"""
输入参数:
R:M*N的评分矩阵
K:隐特征向量维度
max_iter:最大迭代次数
alpha:步长
lambda:正则化系数
输出:
分解之后的P,Q
P:初始化用户特征矩阵M*K
Q:初始化物品特征矩阵N*K
"""
# 给定超参数
K =2
max_iter =5000
alpha =0.0002
lamda =0.004
# 核心算法defLFM_grad_desc( R, K=2, max_iter=1000, alpha=0.0001, lamda=0.002):# 基本维度参数定义
M =len(R)
N =len(R[0])# P,Q初始值,随机生成M*K的矩阵
P = np.random.rand(M, K)
Q = np.random.rand(N, K)# 转置
Q = Q.T
# 开始迭代for step inrange(max_iter):# 对所有的用户u,物品i做遍历,对应的特征向量Pu、Qi梯度下降for u inrange(M):for i inrange(N):# 对于每一个大于0的评分,求出预测评分误差if R[u][i]>0:
eui = np.dot(P[u,:], Q[:, i])- R[u][i]# 代入公式,按照梯度下降算法更新当前的Pu、Qifor k inrange(K):
P[u][k]= P[u][k]- alpha *(2* eui * Q[k][i]+2* lamda * P[u][k])
Q[k][i]= Q[k][i]- alpha *(2* eui * P[u][k]+2* lamda * Q[k][i])# u、i遍历完成,所有特征向量更新完成,可以得到P、Q,可以计算预测评分矩阵
predR = np.dot( P,Q )# 计算当前损失函数
cost =0for u inrange(M):for i inrange(N):if R[u][i]>0:
cost +=(np.dot(P[u,:], Q[:, i])- R[u][i])**2# 加上正则化项for k inrange(K):
cost += lamda *(P[u][k]**2+ Q[k][i]**2)if cost <0.0001:breakreturn P, Q.T, cost
# 4 测试
P, Q, cost = LFM_grad_desc(R, K, max_iter, alpha, lamda)
print(P)print(Q)print(cost)
print(R)
predR = P.dot(Q.T)
predR
"""
[[ 1.51434749 0.77443196]
[ 1.24971278 1.50631155]
[ 0.3242702 1.54690507]
[ 1.87077959 -0.08405844]
[ 1.71301986 0.71429246]
[ 1.74590798 0.55058081]]
[[2.60086925 0.1612641 ]
[1.39956377 0.38112632]
[0.59704728 1.20348814]
[1.77147573 2.1578591 ]
[0.56379486 0.07498884]]
2.1410251115602126
[[4 0 2 0 1]
[0 2 3 0 0]
[1 0 2 4 0]
[5 0 0 3 1]
[0 0 1 5 1]
[0 3 2 4 1]]
array([[4.06350791, 2.41458229, 1.83615673, 4.35374487, 0.91185508],
[3.49325351, 2.32314771, 2.55896571, 5.46424393, 0.81753819],
[1.09284464, 1.04340306, 2.05528654, 3.91243996, 0.29882248],
[4.85209752, 2.58623846, 1.01578053, 3.13265437, 1.04843247],
[4.57053041, 2.6697162 , 1.88239635, 4.57591558, 1.01935575],
[4.62966731, 2.65335041, 1.7050071 , 4.28090943, 1.02562136]])
"""
二、电影推荐系统设计
1. 主要内容
- 项目框架
- 数据源解析
- 统计推荐模块
- 离线推荐模块
- 实时推荐模块
- 基于内容的推荐模块
2. 项目框架
- 大数据处理流程
- 系统模块设计
- 项目系统架构
- 项目数据流图
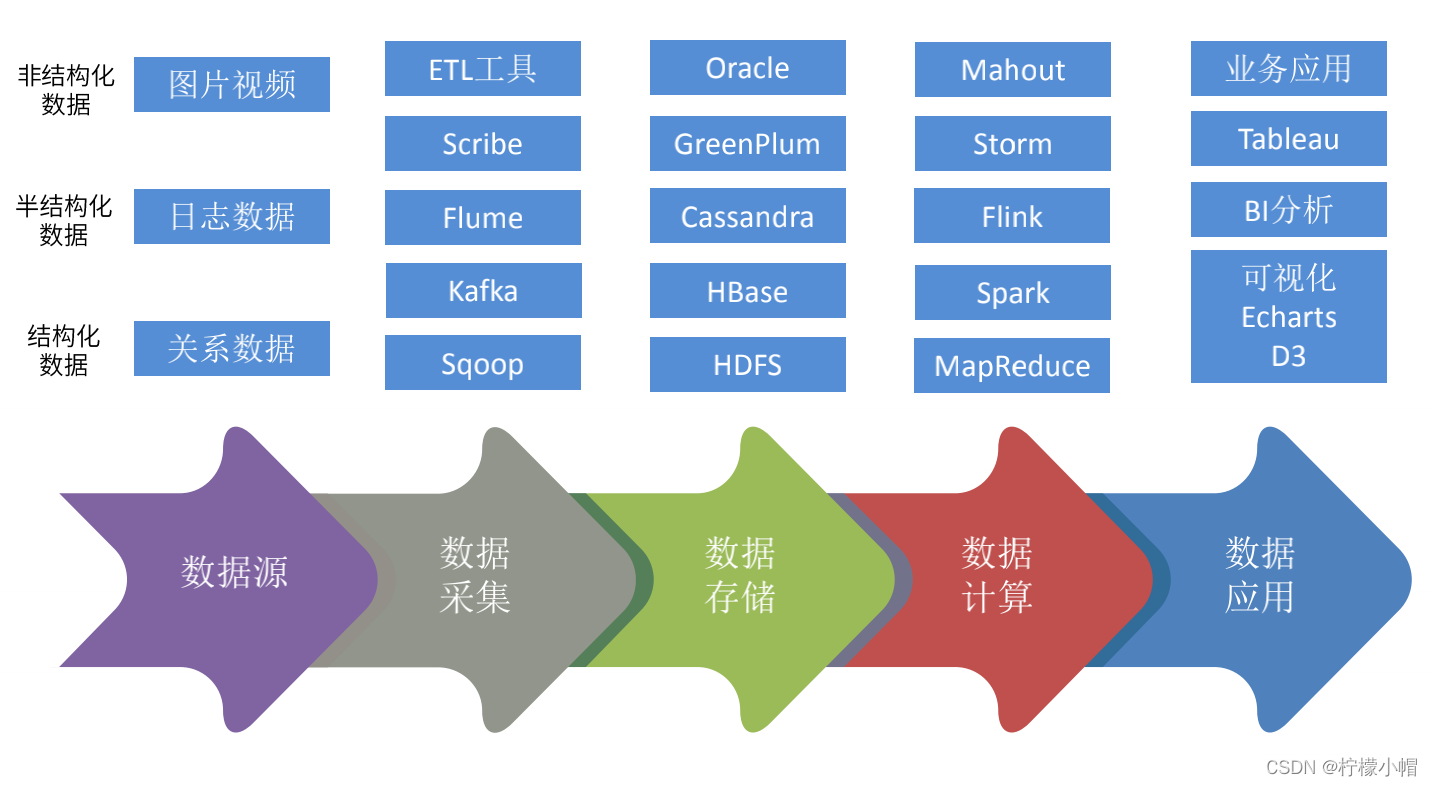
3. 数据生命周期
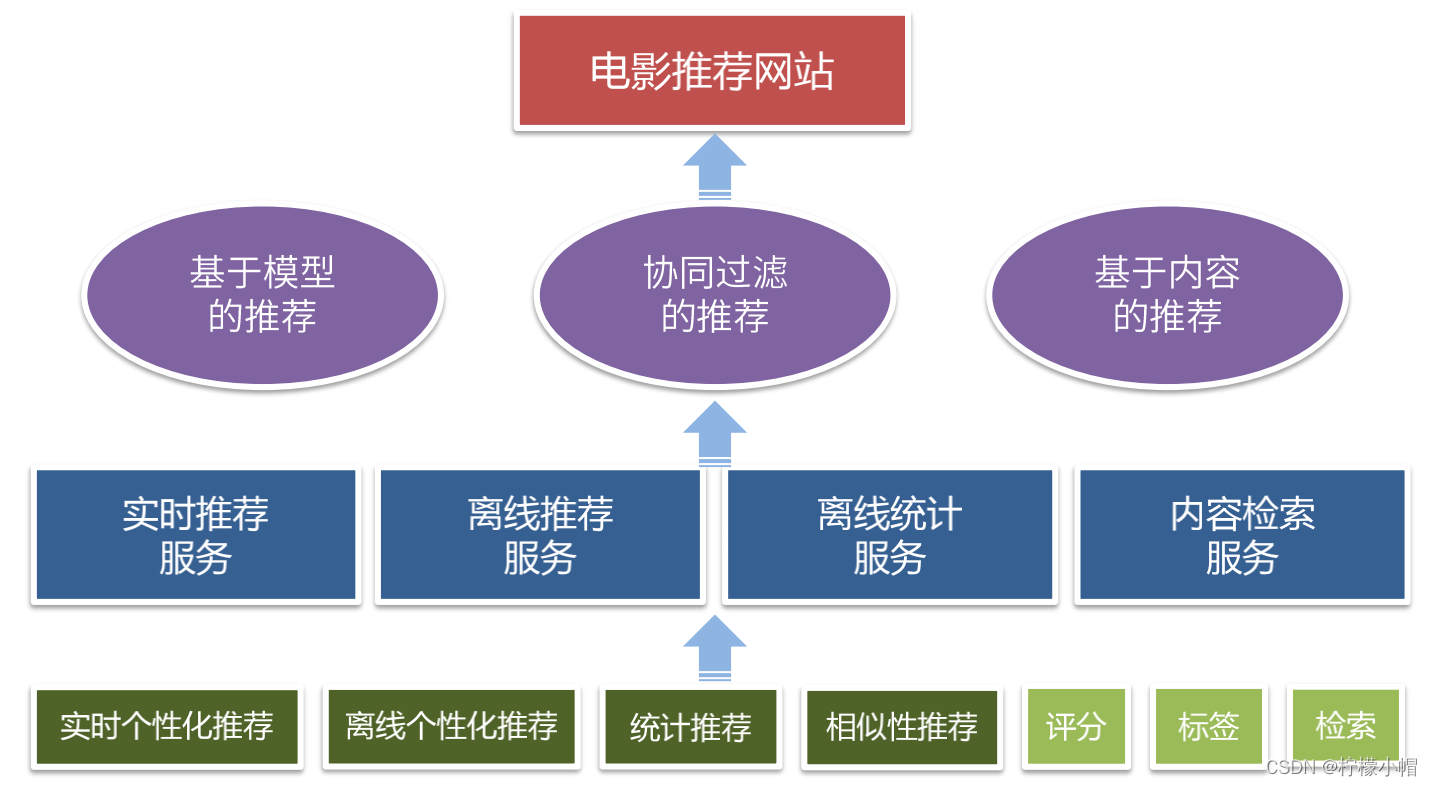
4. 系统模块设计
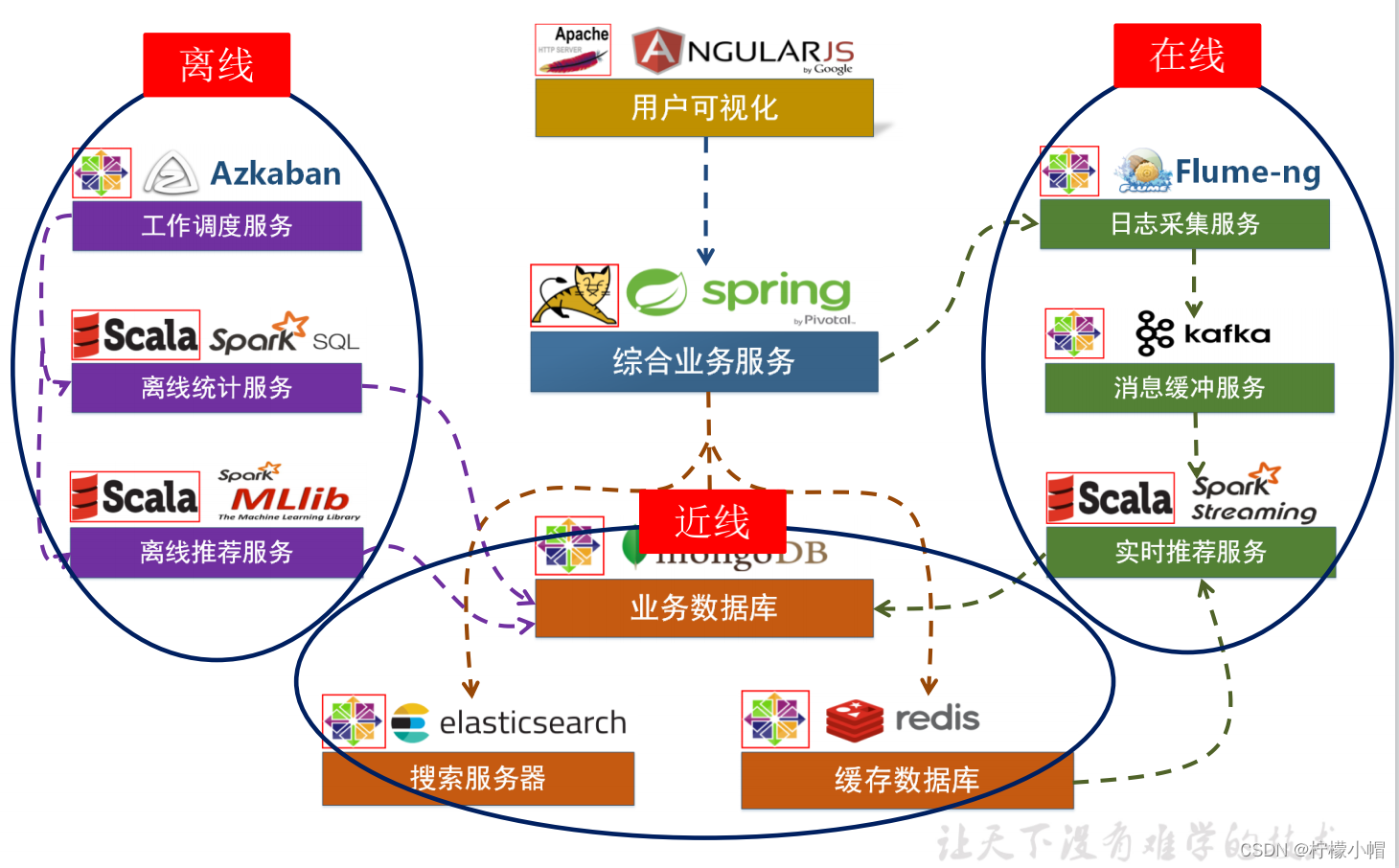
5. 项目系统架构
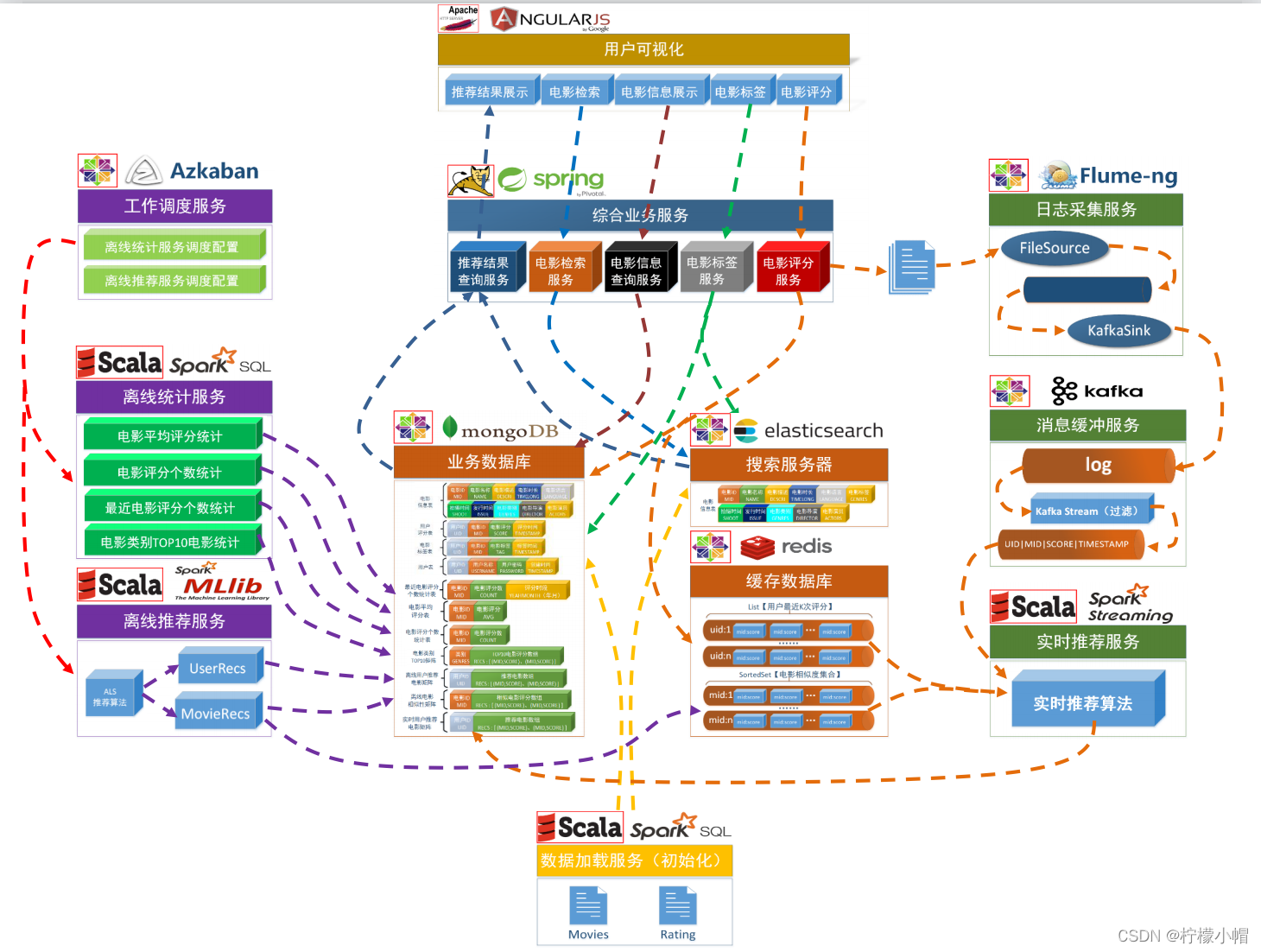
6. 系统数据流图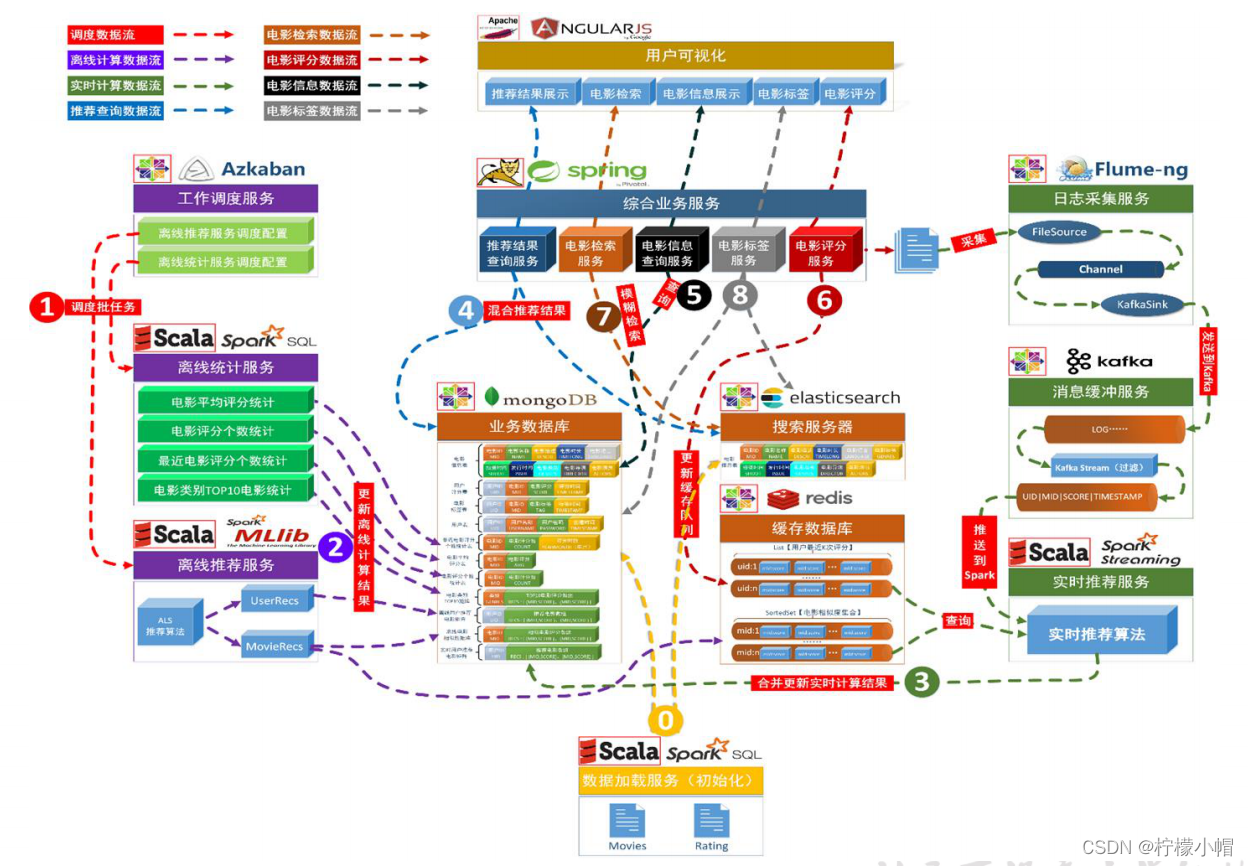
7. 数据源解析
- 电影信息
- 用户评分信息
- 电影标签信息
8. 统计推荐模块
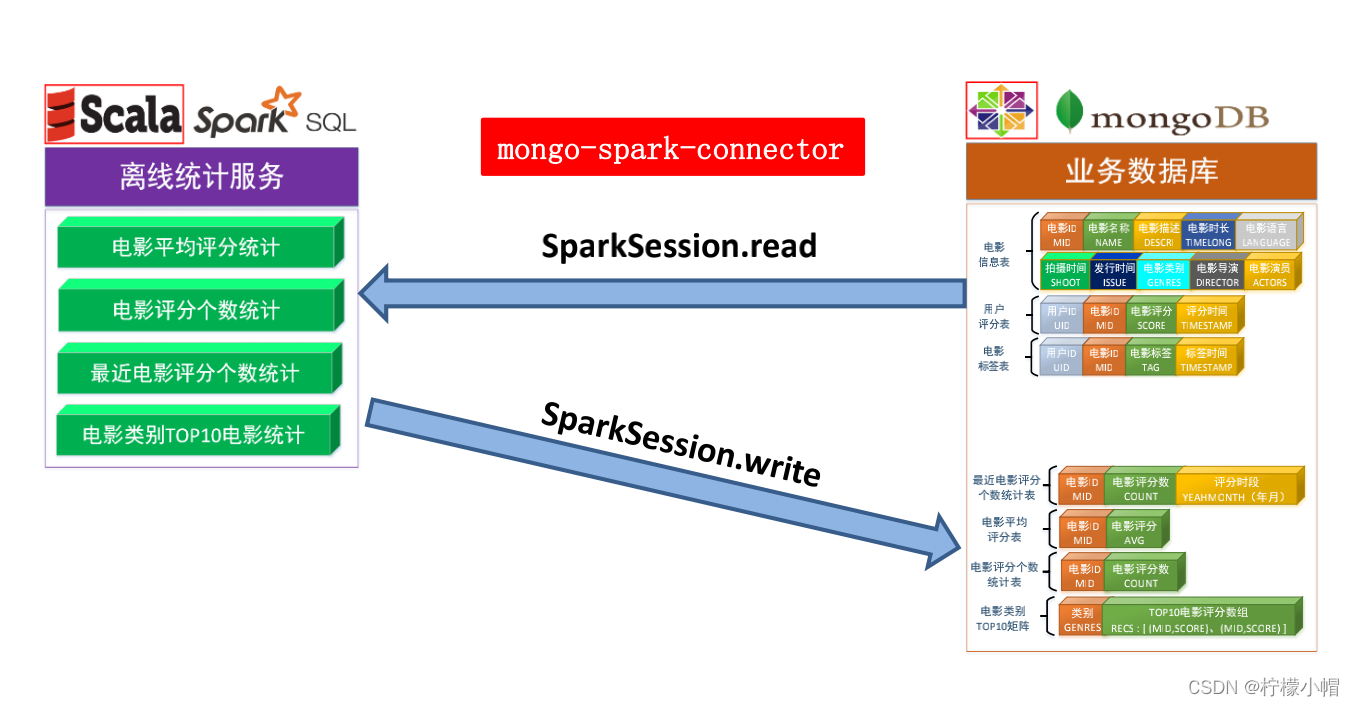
# 历史热门电影统计select mid,count(mid)as count from ratings groupby mid
# => RateMoreMovies# 近期热门电影统计select mid, score, changeDate(timestamp)as yearmonth from ratings
# => ratingOfMonthselect mid,count(mid)as count ,yearmonth from ratingOfMonth groupby yearmonth,mid orderby yearmonth desc,count desc# => RateMoreRecentlyMovies# 电影平均评分统计select mid,avg(score)as avg from ratings groupby mid
# => AverageMovies# 各类别 Top10 评分电影统计select a.mid, genres,if(isnull(b.avg),0,b.avg) score from movies a leftjoin averageMovies b on a.mid = b.mid
# => movieWithScore
spark.sql("select * from (select "+"mid,"+"gen,"+"score, "+"row_number() over(partition by gen order by score desc) rank "+"from "+"(select mid,score,explode(splitGe(genres)) gen from movieWithScore)
genresMovies) rankGenresMovies "+"where rank <= 10")
9. 离线推荐模块

10. ALS推荐模型训练
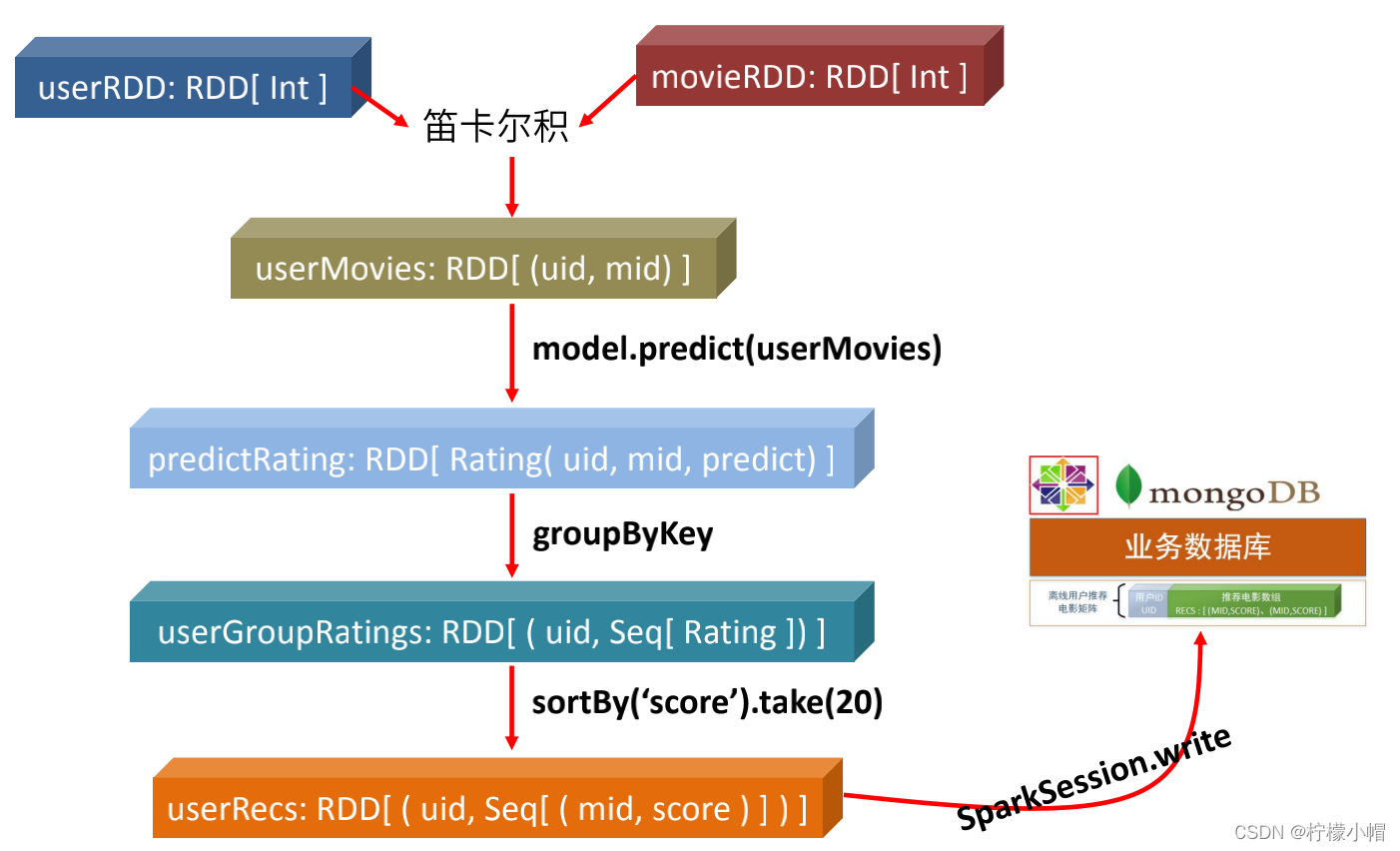
11. 计算用户推荐矩阵
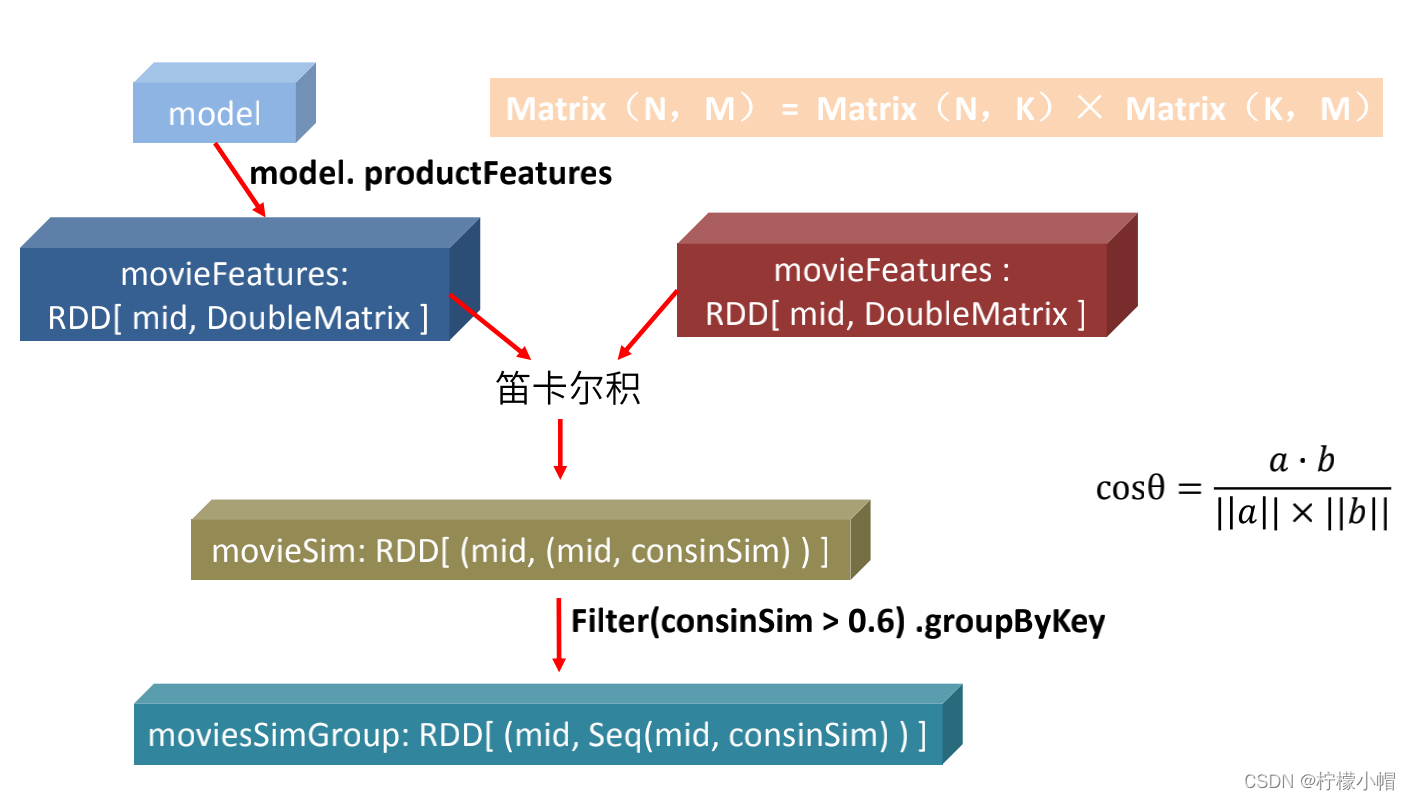
12. 计算电影相似度矩阵
13. 存储电影相似度矩阵

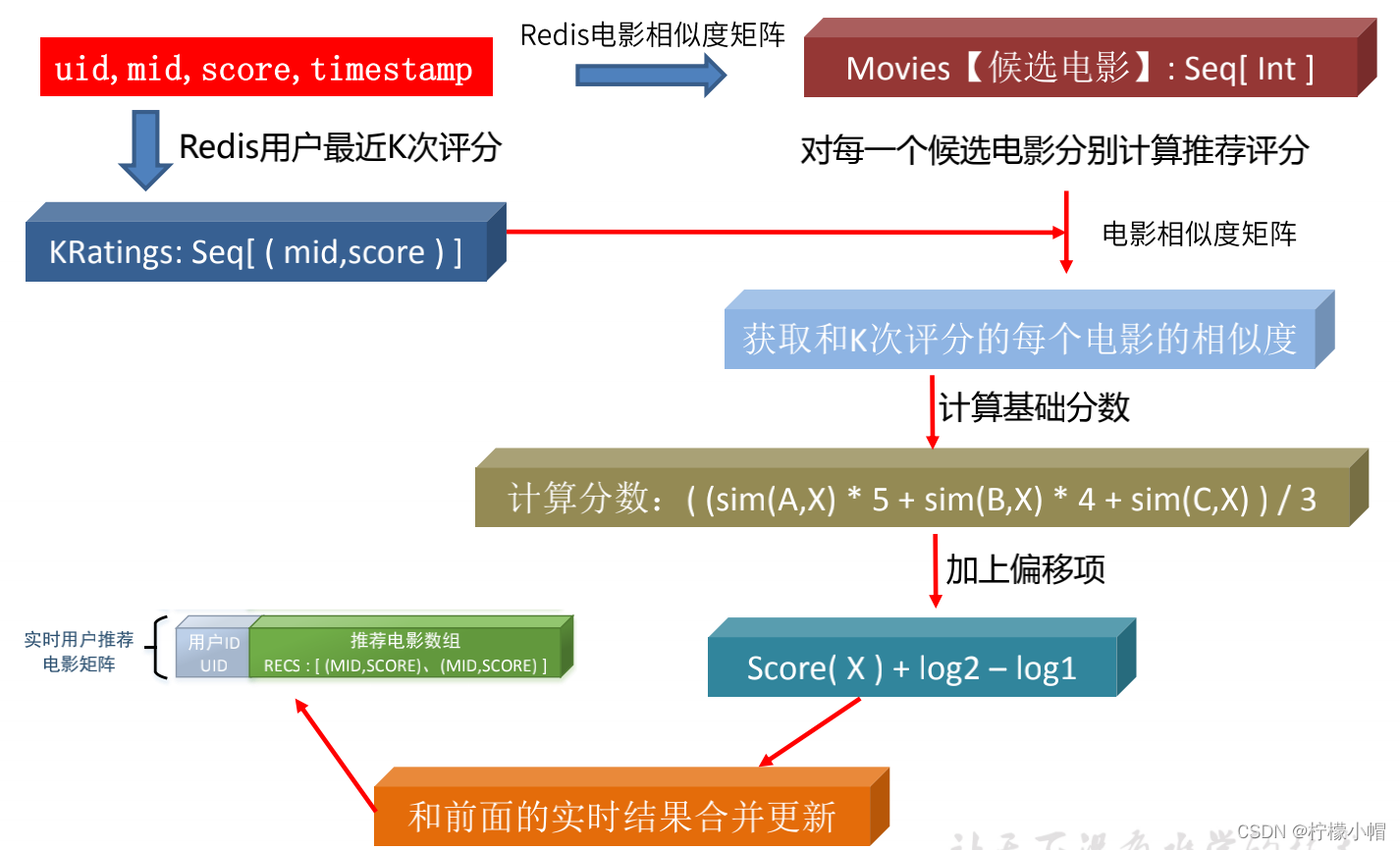
14. 基于模型的实时推荐模块

15. 推荐优先级计算

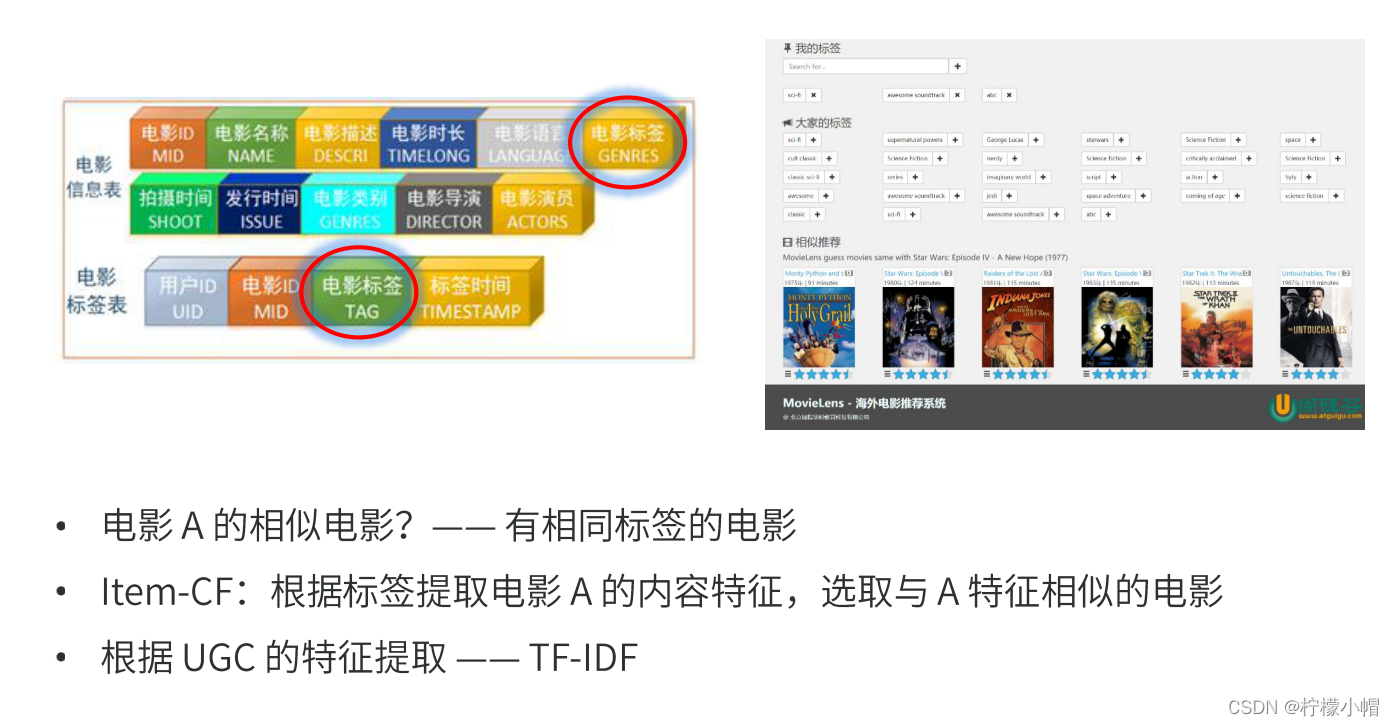
16. 基于内容的推荐
17. 混合推荐 - 分区混合
本文转载自: https://blog.csdn.net/sgsgkxkx/article/details/121776868
版权归原作者 柠檬小帽 所有, 如有侵权,请联系我们删除。
版权归原作者 柠檬小帽 所有, 如有侵权,请联系我们删除。