
1.安装ros2
这里使用小鱼的一键安装,根据自己的喜好安装,博主用的是ros2的foxy版本
wget http://fishros.com/install -O fishros && . fishros
2.下载代码(这里使用的是古月居的代码)
可以结合古月居的B站视频来自己一步一步操作,里面有讲解基础理论与一些环境的配置
https://www.bilibili.com/video/BV16B4y1Q7jQ?p=1&vd_source=7ab152ebd2f75f63466b8dc7d78d3cf2
3.下载yolov5的代码
https://github.com/fishros/yolov5_ros2/tree/main
将古月居下载的代码与yolov5的代码一起放入一个文件夹下
4.打开终端安装依赖
sudo apt update
sudo apt install python3-pip ros-<ros2-distro>-vision-msgs # <ros2-distro>替换为humble,foxy或galactic等ros2发行版
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple yolov5
注:如果pip3的安装命令出现报错如下:
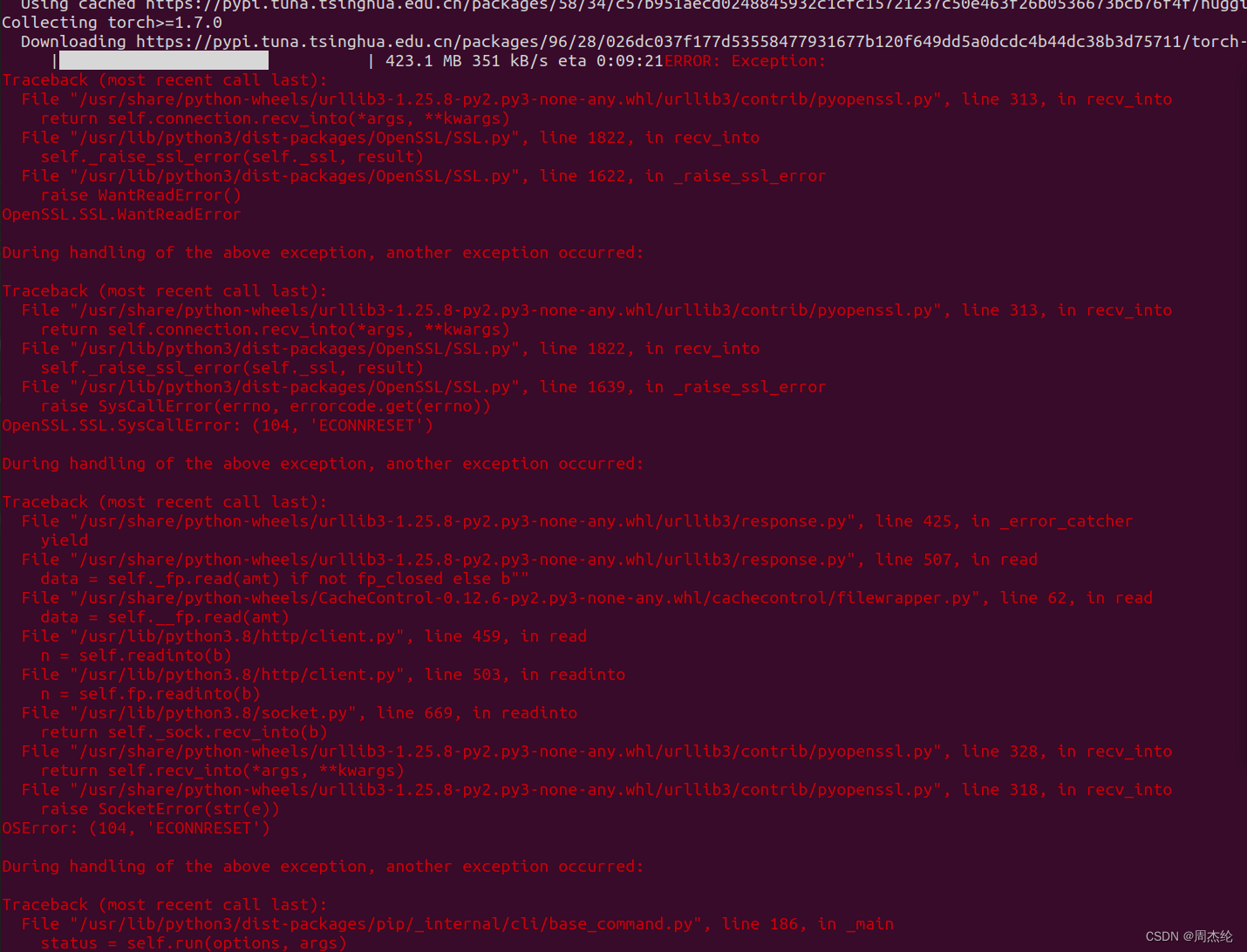
这里就代表下载torch时网速慢,需要换源下载,这里我用的是去下载了torch的离线包自己进行安装https://download.pytorch.org/whl/cu116,下载安装包之前自己要先安装cuda

进入torch后使用Ctrl+f进行搜索,cuda对应的torch版本和你的python版本,一键安装ros2的时候会下载一个python2与python3,在终端输入python3就会得到python的版本
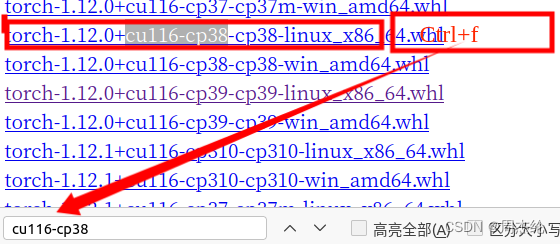
从网上自己搜索torch对应版本的torchvision版本

在这里右键打开终端进行安装,torchvision同理,要学会常用tab建去补全命令

然后重新下载依赖
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple yolov5
5.修改下载的yolov5_ros2下的yolo_detect_2d.py代码
from math import frexp
from traceback import print_tb
from torch import imag
from yolov5 import YOLOv5
import rclpy
from rclpy.node import Node
from ament_index_python.packages import get_package_share_directory
from rcl_interfaces.msg import ParameterDescriptor
from vision_msgs.msg import Detection2DArray, ObjectHypothesisWithPose, Detection2D
from sensor_msgs.msg import Image, CameraInfo
from cv_bridge import CvBridge
import cv2
import yaml
from yolov5_ros2.cv_tool import px2xy
package_share_directory = get_package_share_directory('yolov5_ros2')
# package_share_directory = "/home/mouse/code/github/yolov
#
# 5_test/src/yolov5_ros2"
class YoloV5Ros2(Node):
def __init__(self):
super().__init__('yolov5_ros2')
self.declare_parameter("device", "cuda", ParameterDescriptor(
name="device", description="calculate_device default:cpu optional:cuda:0"))
self.declare_parameter("model", "yolov5s", ParameterDescriptor(
name="model", description="default: yolov5s.pt"))
self.declare_parameter("image_topic", "/image_raw", ParameterDescriptor(
name="image_topic", description=f"default: /image_raw"))
# /camera/image_raw
self.declare_parameter("camera_info_topic", "/camera/camera_info", ParameterDescriptor(
name="camera_info_topic", description=f"default: /camera/camera_info"))
# 默认从camera_info中读取参数,如果可以从话题接收到参数则覆盖文件中的参数
self.declare_parameter("camera_info_file", f"{package_share_directory}/config/camera_info.yaml", ParameterDescriptor(
name="camera_info", description=f"{package_share_directory}/config/camera_info.yaml"))
# 默认显示识别结果
self.declare_parameter("show_result", True, ParameterDescriptor(
name="show_result", description=f"default: True"))
# 1.load model
model_path = package_share_directory + "/config/" + self.get_parameter('model').value + ".pt"
device = self.get_parameter('device').value
self.yolov5 = YOLOv5(model_path=model_path, device=device)
# 2.create publisher
self.yolo_result_pub = self.create_publisher(
Detection2DArray, "yolo_result", 10)
self.result_msg = Detection2DArray()
# 3.create sub image (if 3d, sub depth, if 2d load camera info)
image_topic = self.get_parameter('image_topic').value
self.image_sub = self.create_subscription(
Image, image_topic, self.image_callback, 10)
camera_info_topic = self.get_parameter('camera_info_topic').value
self.camera_info_sub = self.create_subscription(
CameraInfo, camera_info_topic, self.camera_info_callback, 1)
# get camera info
with open(self.get_parameter('camera_info_file').value) as f:
self.camera_info = yaml.full_load(f.read())
print(self.camera_info['k'], self.camera_info['d'])
# 4.convert cv2 (cvbridge)
self.bridge = CvBridge()
self.show_result = self.get_parameter('show_result').value
def camera_info_callback(self, msg: CameraInfo):
"""
通过回调函数获取到相机的参数信息
"""
self.camera_info['k'] = msg.k
self.camera_info['p'] = msg.p
self.camera_info['d'] = msg.d
self.camera_info['r'] = msg.r
self.camera_info['roi'] = msg.roi
self.camera_info_sub.destroy()
def image_callback(self, msg: Image):
# 5.detect pub result
image = self.bridge.imgmsg_to_cv2(msg)
detect_result = self.yolov5.predict(image)
self.get_logger().info(str(detect_result))
self.result_msg.detections.clear()
self.result_msg.header.frame_id = "camera"
self.result_msg.header.stamp = self.get_clock().now().to_msg()
# parse results
predictions = detect_result.pred[0]
boxes = predictions[:, :4] # x1, y1, x2, y2
scores = predictions[:, 4]
categories = predictions[:, 5]
for index in range(len(categories)):
name = detect_result.names[int(categories[index])]
detection2d = Detection2D()
detection2d.tracking_id = name
# detection2d.bbox
x1, y1, x2, y2 = boxes[index]
x1 = int(x1)
y1 = int(y1)
x2 = int(x2)
y2 = int(y2)
center_x = (x1+x2)/2.0
center_y = (y1+y2)/2.0
# detection2d.bbox.center.position.x = center_x
# detection2d.bbox.center.position.y = center_y
# galactic使用如下center坐标,否则会报错:Pose2D object has no attribute position
# 其它版本未验证
# 参考http://docs.ros.org/en/api/vision_msgs/html/msg/BoundingBox2D.html 及 http://docs.ros.org/en/api/geometry_msgs/html/msg/Pose2D.html
detection2d.bbox.center.x = center_x
detection2d.bbox.center.y = center_y
detection2d.bbox.size_x = float(x2-x1)
detection2d.bbox.size_y = float(y2-y1)
obj_pose = ObjectHypothesisWithPose()
obj_pose.id = name
obj_pose.score = float(scores[index])
# px2xy
world_x, world_y = px2xy(
[center_x, center_y], self.camera_info["k"], self.camera_info["d"], 1)
obj_pose.pose.pose.position.x = world_x
obj_pose.pose.pose.position.y = world_y
# obj_pose.pose.pose.position.z = 1.0 #2D相机则显示,归一化后的结果,用户用时自行乘上深度z获取正确xy
detection2d.results.append(obj_pose)
self.result_msg.detections.append(detection2d)
# draw
if self.show_result:
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(image, name, (x1, y1),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 1)
cv2.imshow('result', image)
cv2.waitKey(1)
# if view or pub
if self.show_result:
cv2.imshow('result', image)
cv2.waitKey(1)
print("before publish out if")
if len(categories) > 0:
self.yolo_result_pub.publish(self.result_msg)
def main():
rclpy.init()
rclpy.spin(YoloV5Ros2())
rclpy.shutdown()
if __name__ == "__main__":
main()
6.编译工作空间
在src外打开终端进行编译
colcon build
使用colcon build进行编译src文件夹下的代码

搜寻本地编译
source install/local_setup.bash
如果想随时随地使用,打开主目录,使用ctrl+h打开隐藏文件找到.bashrc文件打开,插入一行

7.运行仿真建模
ros2 launch learning_gazebo load_mbot_camera_into_gazebo.launch.py
开启另一个终端
ros2 run yolov5_ros2 yolo_detect_2d --ros-args -p device:=cpu -p image_topic:=/camera/image_raw
注:image_topic:=后是相机发布的话题名,将话题名改为相机所发布的话题名一致就能实现目标检测了,效果如下

可以通过开启另一个终端下输入以下命令实现小车的移动
ros2 run teleop_twist_keyboard teleop_twist_keyboard

在上面终端中按i是前进,j是向左旋转视角,l是向右旋转,k是停止移动,,(逗号)为后退。
博客会不定期修改与更新,建议收藏!!!
版权归原作者 周杰纶 所有, 如有侵权,请联系我们删除。