使用PyTorch实现GPT-2直接偏好优化训练:DPO方法改进及其与监督微调的效果对比
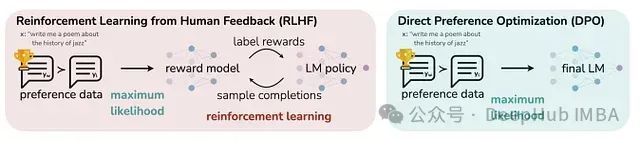
本文将探讨RLHF技术,特别聚焦于直接偏好优化(Direct Preference Optimization, DPO)方法,并详细阐述了一项实验研究:通过DPO对GPT-2 124M模型进行调优,同时与传统监督微调(Supervised Fine-tuning, SFT)方法进行对比分析。
本文将探讨RLHF技术,特别聚焦于直接偏好优化(Direct Preference Optimization, DPO)方法,并详细阐述了一项实验研究:通过DPO对GPT-2 124M模型进行调优,同时与传统监督微调(Supervised Fine-tuning, SFT)方法进行对比分析。



