Proximal SFT:用PPO强化学习机制优化SFT,让大模型训练更稳定
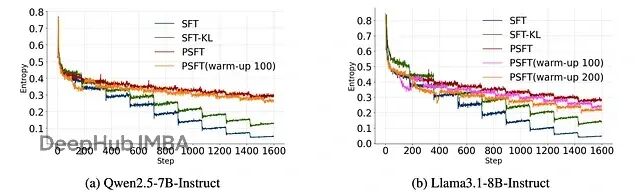
这篇论文提出了 Proximal Supervised Fine-Tuning (PSFT),本质上是把 PPO 的思路引入到 SFT 中。这个想法挺巧妙的:既然 PPO 能够稳定策略更新,那为什么不用类似的机制来稳定监督学习的参数更新呢?
从零开始的c语言日记day36——指针进阶
数组指针的概念和指针数组的概念
这篇论文提出了 Proximal Supervised Fine-Tuning (PSFT),本质上是把 PPO 的思路引入到 SFT 中。这个想法挺巧妙的:既然 PPO 能够稳定策略更新,那为什么不用类似的机制来稳定监督学习的参数更新呢?
数组指针的概念和指针数组的概念



