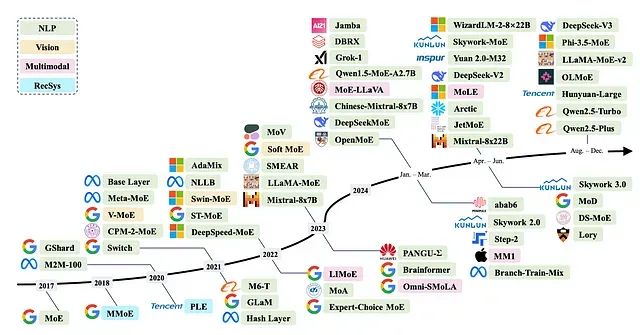
为什么混合专家模型(MoE)如此高效:从架构原理到技术实现全解析
本文将深入分析MoE架构的技术原理,探讨其在大型语言模型中被视为未来发展方向的原因,并详细介绍该架构在当前主要模型中的具体应用实现。
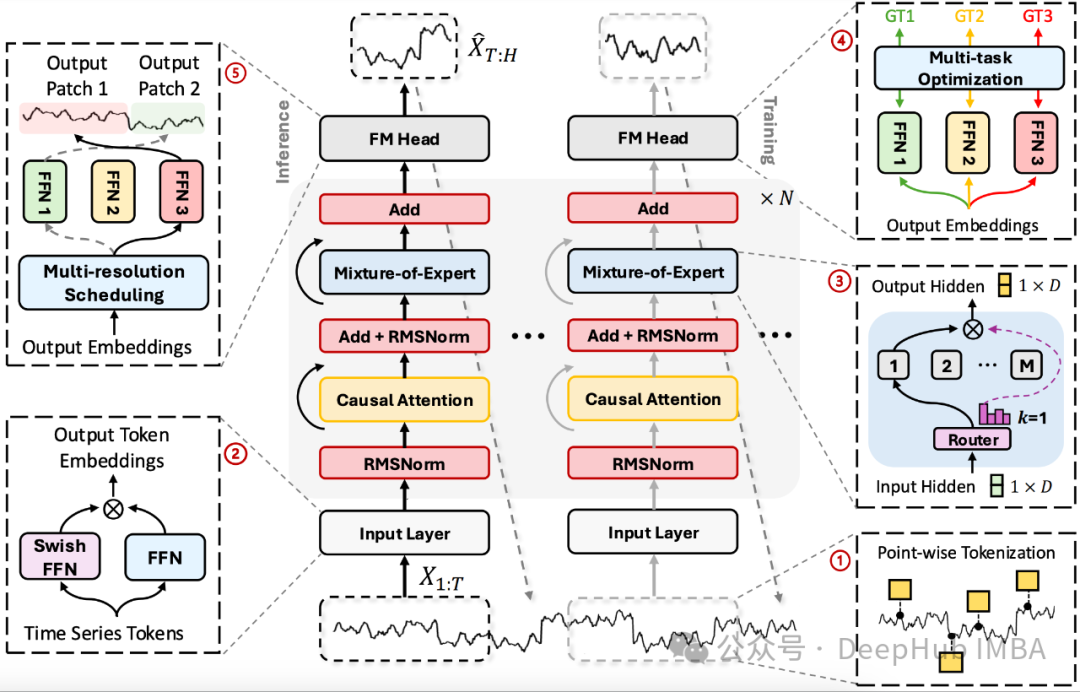
TimeMOE: 使用稀疏模型实现更大更好的时间序列预测
这是9月份刚刚发布的论文TimeMOE。它是一种新型的时间序列预测基础模型,"专家混合"(Mixture of Experts, MOE)在大语言模型中已经有了很大的发展,现在它已经来到了时间序列。
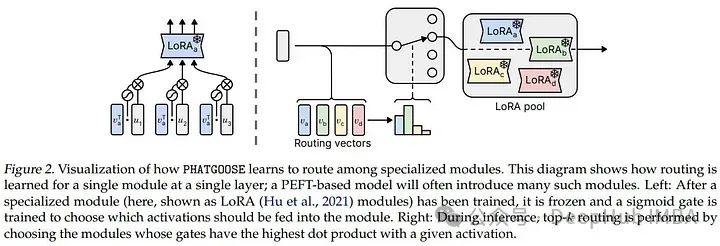
PHATGOOSE:使用LoRA Experts创建低成本混合专家模型实现零样本泛化
这篇2月的新论文介绍了Post-Hoc Adaptive Tokenwise Gating Over an Ocean of Specialized Experts (PHATGOOSE),这是一种通过利用一组专门的PEFT模块(如LoRA)实现零样本泛化的新方法
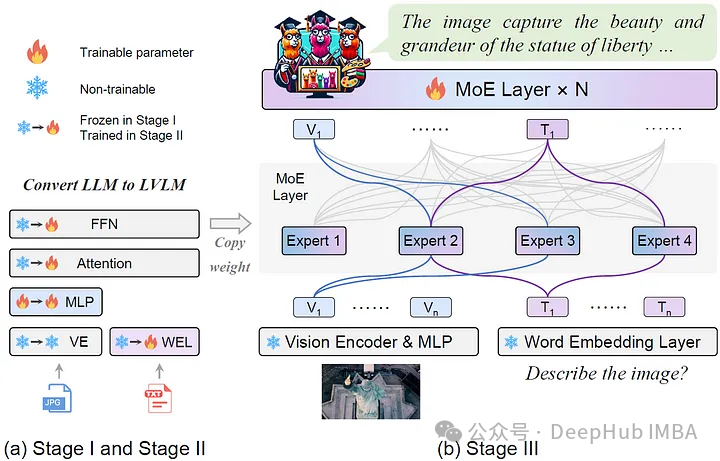
MoE-LLaVA:具有高效缩放和多模态专业知识的大型视觉语言模型
MoE-LLaVA利用了“专家混合”策略融合视觉和语言数据,实现对多媒体内容的复杂理解和交互。
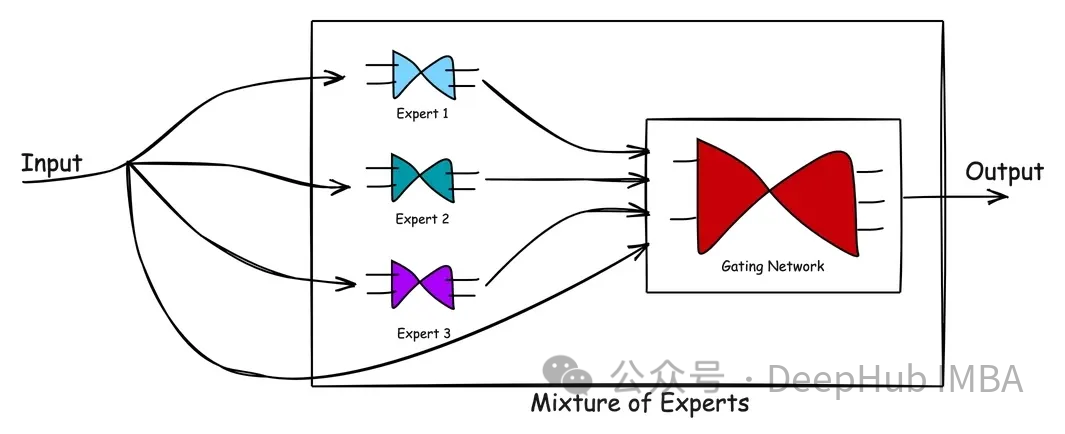
使用PyTorch实现混合专家(MoE)模型
在本文中,我将使用Pytorch来实现一个MoE模型。在具体代码之前,我们先简单介绍混合专家的体系结构。



