一文彻底搞懂大模型参数高效微调(PEFT)
最近这一两周看到不少互联网公司都已经开始秋招提前批了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。。更多实战和面试交流,加入我们。
强化学习原理与代码实战案例讲解
1. 背景介绍1.1 问题的由来强化学习是机器学习的一个重要分支,它的目标是让机器通过与环境的交互,学习到一个策略,使得在未来的一段时间内,从环境中获得的奖励最大。这个问题的由来可以追溯到心理学中的操作性条件反射理论,也就是通过奖励和惩罚来改变行为的理论。1
7.2 Transformer:具有里程碑意义的新模型——自注意力模型
自此,不管是学术界,还是工业界均掀起了基于Transformer的预训练模型研究和应用的热潮,并且逐渐从NLP领域延伸到CV、语音等多项领域。Transformer模型是一个具有里程碑意义的模型,它的提出催生了众多基于Transformer网络结构的模型,特别是在2018年预训练模型BERT的提出,
一切皆是映射:元强化学习在DQN中的应用:前沿进展介绍
1. 背景介绍1.1 强化学习的崛起强化学习 (Reinforcement Learning, RL) 作为机器学习的一个重要分支,近年来取得了令人瞩目的成就。从 AlphaGo 击败世界围棋冠军到 OpenAI Five 在 Dota2 中战胜职业战队,强化学习展现出了其在解决复杂决策问题上的巨
深度 Qlearning:在智能城市构建中的应用
1. 背景介绍1.1 智能城市:未来都市的蓝图智能城市作为未来都市发展的蓝图,旨在利用先进的信息与通信技术 (ICT) 提升城市治理效率、改善居民生活质量、促进经济可持续发展。其核心在于将城市中的各个系统,包括交通、能源、水资源、公共安全等,整合为一个有机整体,并通过数据分析、人工智能等
App电商业务团队规划和人员规划与人员培养计划
App电商业务团队规划和人员规划与人员培养计划1.背景介绍1.1 电商行业概况随着互联网和移动互联网的飞速发展,电子商务行业正在蓬勃发展。电子商务(E-commerce)是指通过互联网、移动互联网等信息网络进行商品交易活动和
大模型参数——详细介绍
大模型参数——详细介绍
Neural Networks (NN) 原理与代码实战案例讲解
Neural Networks (NN) 原理与代码实战案例讲解1.背景介绍1.1 什么是神经网络神经网络(Neural Networks, NN)是一种受生物神经系统启发而设计的机器学习模型,旨在模拟人脑神
Qwen2-1___5B-Instruct 推理
Union[List[Dict[str, str]], List[List[Dict[str, str]]]], 一个字典列表,其中每个字典包含 'role' 和 'content' 键,表示至今的对话记录。Optional[List[Dict[str, str]]] = None, 一个字典列表,
多模态大模型:技术原理与实战 如何提高长文本阅读能力
1. 背景介绍1.1 大模型时代的信息挑战近年来,随着互联网的蓬勃发展,信息量呈爆炸式增长,文本、图像、视频等多模态数据成为信息的主要载体。如何高效地处理和理解这些海量多模态数据,成为人工智能领域亟待解决的难题。传统的单模态模型,例如自然语言处理(NLP)模型或计算机视觉(CV)模型,难
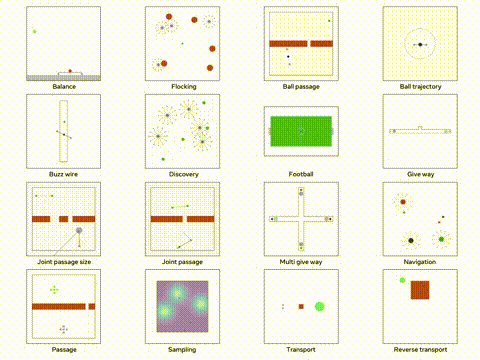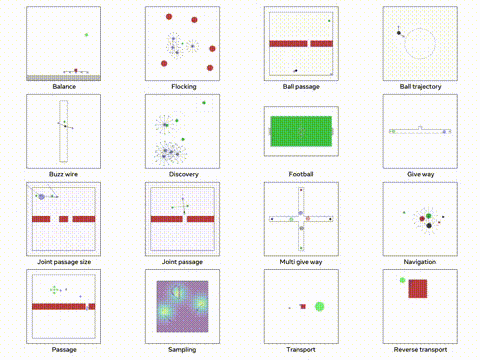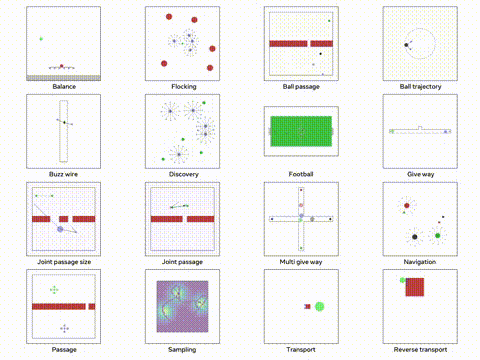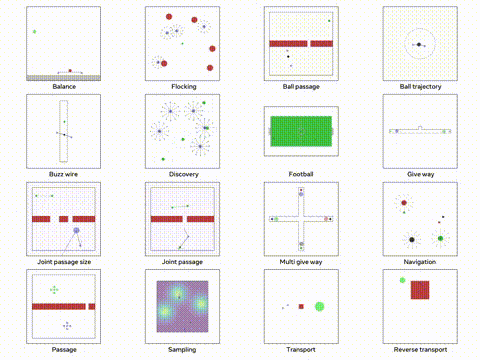
使用 Python TorchRL 进行多代理强化学习
本文将深入探讨如何使用 TorchRL 解决 MARL 问题,重点关注多代理环境中的近端策略优化(PPO)。
智能新时代:探索【人工智能】、【机器学习】与【深度学习】的前沿技术与应用
这篇文章深入探讨了人工智能、机器学习、深度学习、算法和计算机视觉的核心概念,并通过丰富的代码示例展示了这些技术在实际应用中的具体实现。通过理论与实践的结合,读者不仅能够理解这些复杂的技术概念,还能掌握在不同场景下如何有效地应用这些技术,进而为进一步的学习和研究奠定坚实的基础。
Yarn原理与代码实例讲解
Yarn原理与代码实例讲解作者:禅与计算机程序设计艺术 / Zen and the Art of Computer Programming1. 背景介绍1.1 问题的由来随着云计算和大数据技术的快速发展,分布式计算已经成为现代I
CUDA11.8+cudnn9.2.1 win10安装教程
由于目前NVIDIA官网已经将原来的使用压缩包安装cudnn修改为使用安装包安装,但是在网上搜索之后发现对于该问题的解决方案描述比较少,所以综合了一些以往教程,自己摸索出一套安装方法,供各位参考。一、安装包的下载CUDA下载在下载前大家需要在NVIDIA控制面板里查看本机显卡最高能够支持的CUDA版
教程向:如何提高多卡训练速度(附github代码+实验结果)
如何提高多卡训练速度(附github代码+实验结果)
揭秘LoRA:利用深度学习原理在Stable Diffusion中打造完美图像生成的秘密武器
LoRA作为一种创新的微调技术,通过低秩矩阵分解方法,实现了对大型生成模型的高效微调。在Stable Diffusion模型中,LoRA技术被广泛应用于角色、风格、概念、服装和物体等不同分类的图像生成中。通过结合多个同类型的LoRA模型,并利用AdditionNet调节权重,可以实现更为复杂和定制化
评估指标:精确率(Precision)、召回率(Recall)、F1分数(F1 Score)
人工智能、评估指标、精确率(Precision)、召回率(Recall)、F1分数(F1 Score)
Kafka存储机制:数据如何持久化深入解析存储机制
Kafka存储机制:数据如何持久化-深入解析存储机制1.背景介绍Apache Kafka是一个分布式流处理平台,被广泛应用于大数据领域。它能够可靠地在系统或应用程序之间传递消息。作为一个分布式系统,Kafka需要持久化数据以确保容错性和可靠性。本文将深入探讨Kafka
MobileNet原理与代码实例讲解
MobileNet原理与代码实例讲解作者:禅与计算机程序设计艺术 / Zen and the Art of Computer Programming1. 背景介绍1.1 问题的由来随着移动设备的普及,对计算效率的需求日
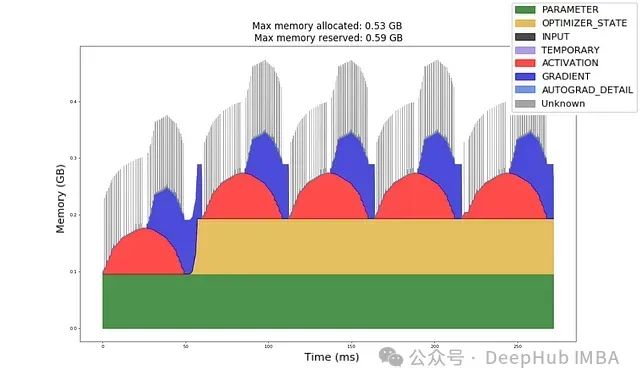
深入理解GPU内存分配:机器学习工程师的实用指南与实验
给定一个模型架构、数据类型、输入形状和优化器,你能否计算出前向传播和反向传播所需的GPU内存量?



