Qwen VL架构及其原理[多模态大模型]、OpenCLIP
AnswerQwen-VL是一种多模态大模型,旨在同时处理和理解文本与图像信息。
中国模式识别与计算机视觉大会|多模态模型及图像安全的探索及成果
随着人工智能技术的不断演进,多模态大模型已是当下比较热的研究方向,它可以同时理解和生成多种输入和输出模态,如文本、图像、语音等,能够更好地模拟人类的多感知能力,给文档图像的分析处理带来了新的机遇和挑战!近期,中国模式识别与计算机视觉大会在厦门举办,是国内顶级的模式识别和计算机视觉领域学术盛会。大会汇
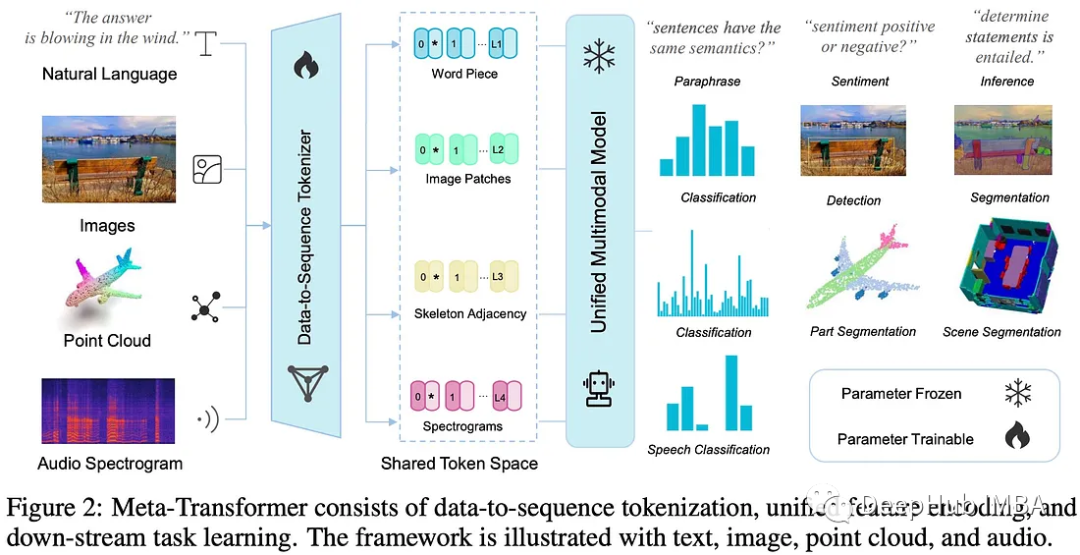
Meta-Transformer 多模态学习的统一框架
Meta-Transformer是一个用于多模态学习的新框架,用来处理和关联来自多种模态的信息



