社区首页
Pytorch
kaggle方案总结
AI科技日报
人工智能
大数据
竞赛
后端
前端
程序开发
分享探索
社区首页
偏好优化
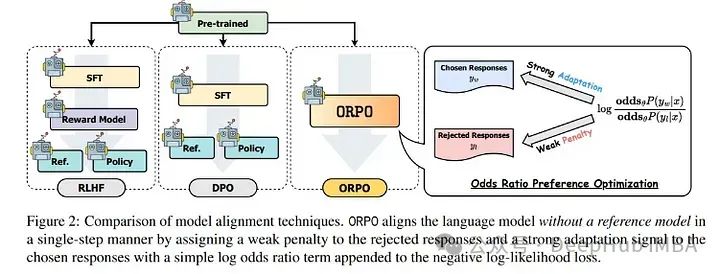
ORPO偏好优化:性能和DPO一样好并且更简单的对齐方法
ORPO是另一种新的LLM对齐方法,这种方法甚至不需要SFT模型。通过ORPO,LLM可以同时学习回答指令和满足人类偏好。
登录可以使用的更多功能哦!
登录
作者榜
资讯小助手
资讯同步
内容小助手
文章同步
Deephub
公众号:deephub-imba
奕凯
公众号:奕凯的技术栈