[医疗 AI ] 3D TransUNet:通过 Vision Transformer 推进医学图像分割
医学图像分割在推进医疗保健系统的疾病诊断和治疗计划中起着至关重要的作用。U 形架构,俗称 U-Net,已被证明在各种医学图像分割任务中非常成功。然而,U-Net 基于卷积的操作本身限制了其有效建模远程依赖关系的能力。为了解决这些限制,研究人员转向了以其全局自我注意机制而闻名的 Transformer
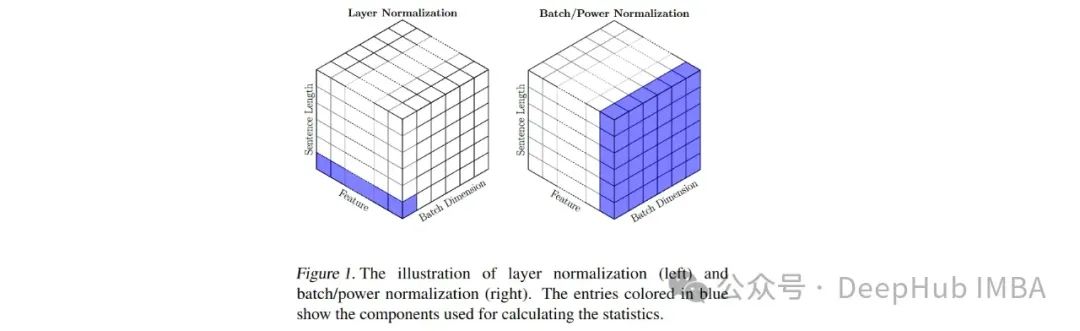
使用BatchNorm替代LayerNorm可以减少Vision Transformer训练时间和推理时间
本文我们将详细探讨ViT的一种修改,这将涉及用批量归一化(BatchNorm)替换层归一化(LayerNorm) - transformer的默认归一化技术。
8类CNN-Transformer混合架构魔改方案盘点,附23个配套模型&代码
为进一步提高模型的性能,我们将。目前,它已经成为我们研究视觉任务、发文章离不开的模型。针对CNN+transformer组合方向的研究也成为了当下计算机视觉领域研究中的大热主题。CNN-Transformer架构凭借众所周知的优势,在视觉任务上取得了令人瞩目的效果,它不仅可以提高模型在多种计算机视觉
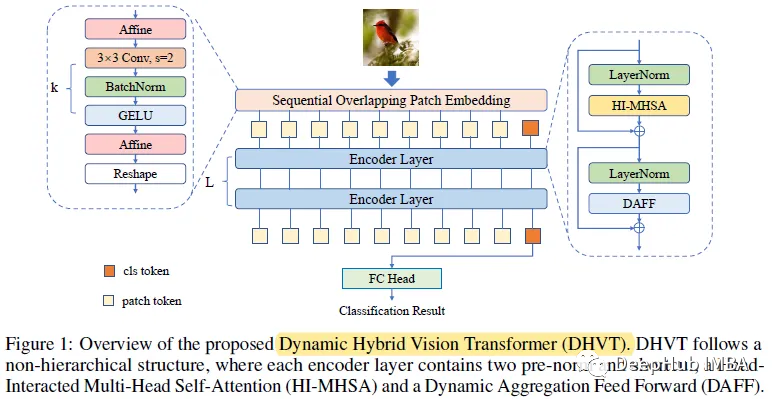
DHVT:在小数据集上降低VIT与卷积神经网络之间差距,解决从零开始训练的问题
VIT在归纳偏置方面存在空间相关性和信道表示的多样性两大缺陷。所以论文提出了动态混合视觉变压器(DHVT)来增强这两种感应偏差。
轻量级Visual Transformer模型——LeViT(ICCV2021)
LeViT是FAIR团队发表在ICCV2021上的成果,是轻量级ViT模型中的标杆,文章对ViT中多个部件进行的改进,如加速策略等,对很多工程化铺设ViT系列模型都是很有借鉴意义的。按说,近期出现的优质模型非常多,各种冲击SOTA的,详情可戳我整理的小综述《盘点2021-2022年出现的CV神经网络



