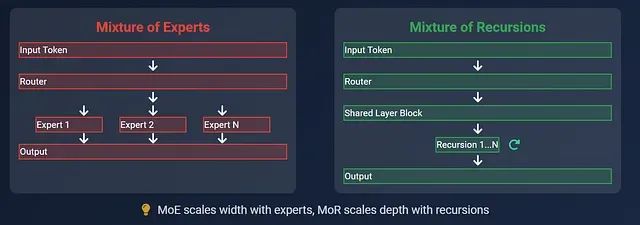
本文将深入分析递归混合(MoR)与专家混合(MoE)两种架构在大语言模型中的技术特性差异,探讨各自的适用场景和实现机制,并从架构设计、参数效率、推理性能等多个维度进行全面对比。
资讯同步
文章同步
公众号:deephub-imba
公众号:奕凯的技术栈