LlamaIndex检索调优实战:七个能落地的技术细节
这篇文章整理了七个在LlamaIndex里实测有效的检索优化点,每个都带代码可以直接使用。
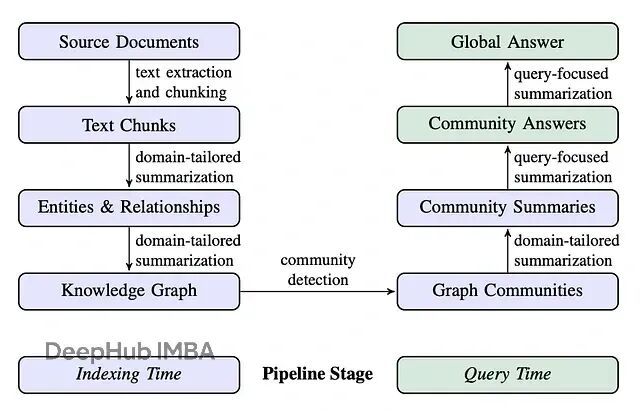
GraphRAG进阶:基于Neo4j与LlamaIndex的DRIFT搜索实现详解
本文的重点是DRIFT搜索:Dynamic Reasoning and Inference with Flexible Traversal,翻译过来就是"动态推理与灵活遍历"。这是一种相对较新的检索策略,兼具全局搜索和局部搜索的特点。
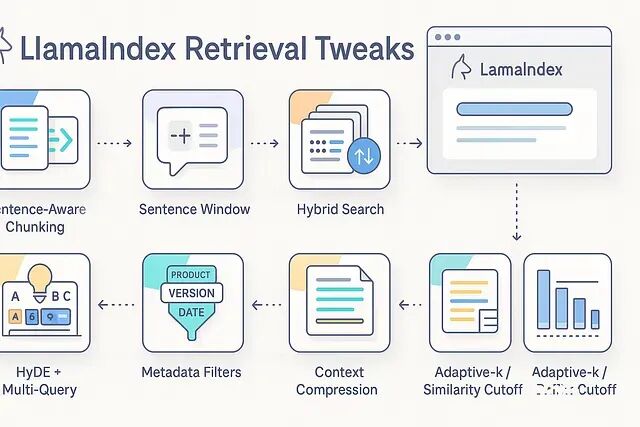
LlamaIndex检索调优实战:分块、HyDE、压缩等8个提效方法快速改善答案质量
分块策略、混合检索、重排序、HyDE、上下文压缩、元数据过滤、自适应k值——八个实用技巧快速改善检索质量
llamaindex 使用向量存储索引(VectorStoreIndex)
在实际应用中,结合不同的向量存储和自定义节点处理,可以实现更复杂和精细的检索需求。向量存储(Vector Stores)是检索增强生成(RAG)的关键组件,因此你几乎会在使用LlamaIndex构建的每个应用程序中直接或间接地使用它们。有关如何使用持久向量存储的更多信息,请参阅下面的“使用向量存储”
检索增强生成RAG系列9--RAG开源开发框架
当然还有许多优秀的框架没有介绍,有些可能也跟RAG相关比如open-webui等,这里就不一一列举。无论你使用较为底层Langchain或者LlamaIndex,还是使用dify较为低代码方式构建你的RAG,都是要根据你的业务场景来决定选择哪些开发框架。这里只是提供对于相关实践信息供大家参考,主要是



