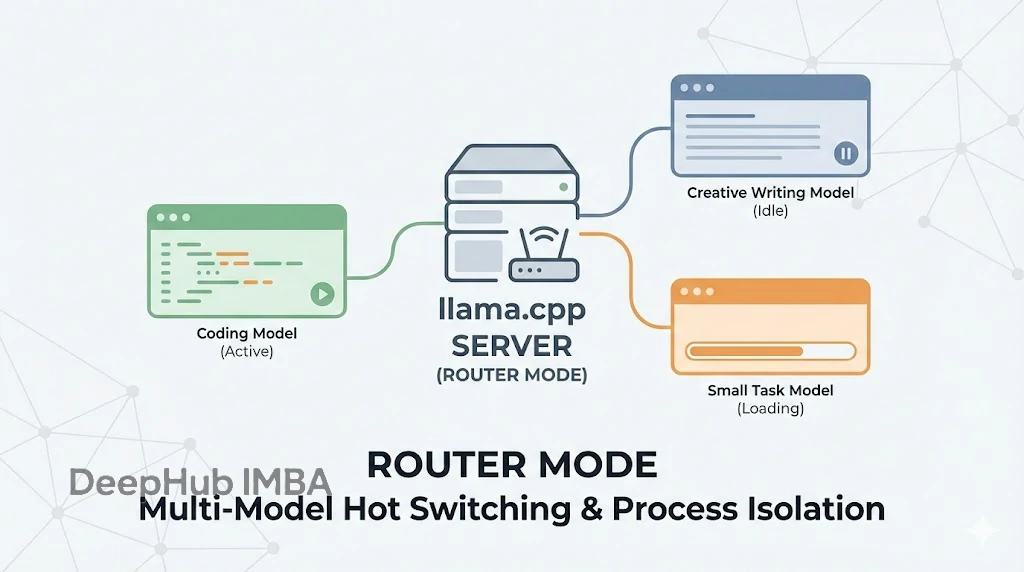
llama.cpp Server 引入路由模式:多模型热切换与进程隔离机制详解
Router mode 看似只是加了个多模型支持,实则是把 llama.cpp 从一个单纯的“推理工具”升级成了一个更成熟的“推理服务框架”。
本地运行 AI 有多慢 ? 大模型推理测速 (llama.cpp, Intel GPU A770)
通过llama.cpp运行 7B.q4 (4bit 量化), 7B.q8 (8bit 量化) 模型, 测量了生成式 AI 语言模型在多种硬件上的运行 (推理) 速度.根据上述测量结果, 可以得到以下初步结论:(1)显存 (内存) 大就是正义!大, 就是正义!!限制能够运行的模型规模的最主要因素, 就
【AI实战】llama.cpp 量化部署 llama-33B
llama.cpp 量化部署 llama-33B
【LLM】Windows本地CPU部署民间版中文羊驼模型踩坑记录
想必有小伙伴也想跟我一样体验下部署大语言模型, 但碍于经济实力, 不过民间上出现了大量的量化模型, 我们平民也能体验体验啦~, 该模型可以在笔记本电脑上部署, 确保你电脑至少有16G运行内存。



