加速LLM大模型推理,KV缓存技术详解与PyTorch实现
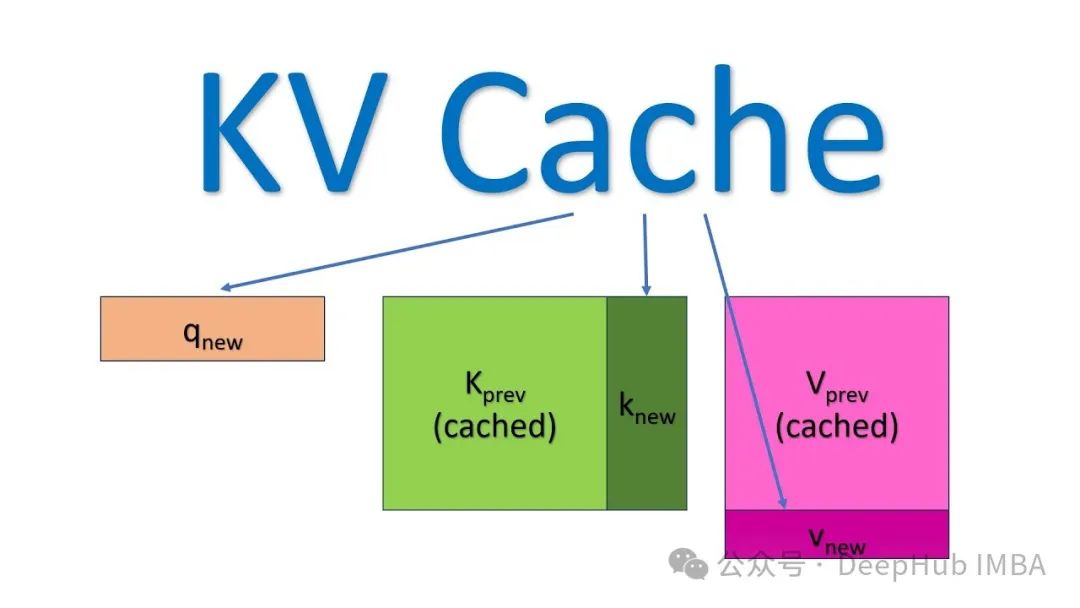
本文详细阐述了KV缓存的工作原理及其在大型语言模型推理优化中的应用,文章不仅从理论层面阐释了KV缓存的工作原理,还提供了完整的PyTorch实现代码,展示了缓存机制与Transformer自注意力模块的协同工作方式。
SCOPE:面向大语言模型长序列生成的双阶段KV缓存优化框架
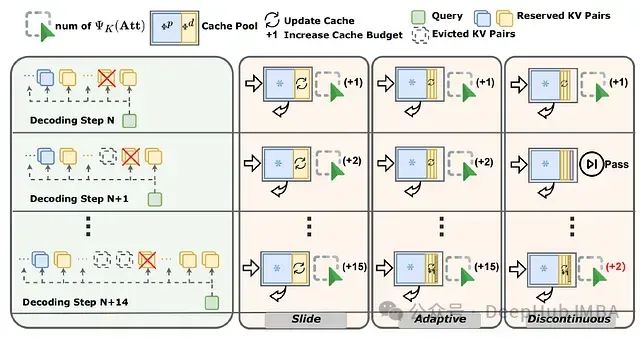
SCOPE框架通过分离预填充与解码阶段的KV缓存优化策略,实现了高效的缓存管理。该框架保留预填充阶段的关键KV缓存信息,并通过滑动窗口、自适应调整和不连续更新等策略,优化解码阶段的重要特征选取,显著提升了长语言模型长序列生成的性能。



